Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Aquí hay un secreto, los métodos de control sintético pueden resolver este problema con suma facilidad y sin pérdida de ingresos o clientes. Si esto fuera un experimento, la hipótesis sería: eliminar las tarjetas como método de pago no afectará los ingresos ni las ventas. La base de prueba estaría compuesta por clientes que no tienen tarjetas como opción de pago, y la base de control tendría tarjetas como opción de pago.
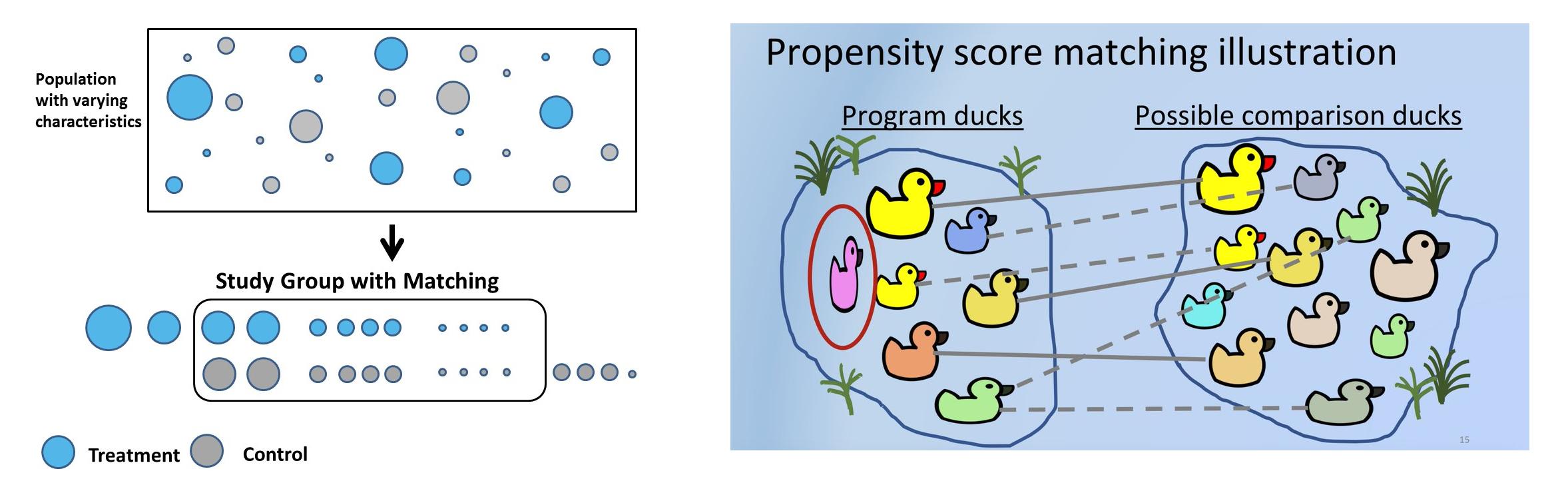
Método de control sintético: estudio de caso
Los métodos de control sintético (SCM), en palabras simples, elegirán para cada cliente de prueba un cliente de control similar utilizando un conjunto predefinido de características o covariables cuyas características previas al tratamiento son similares pero no se han sometido a tratamiento. En SCM, los clientes se denominan unidades, las intervenciones se denominan tratamientos y las características se denominan covariables. Las empresas utilizan SCM para muchos casos de uso práctico. Uber, por ejemplo, usó SCM para probar si proporcionar detalles de contacto del conductor antes de un viaje aumenta la satisfacción del cliente.
A veces, las hipótesis no se pueden probar en una configuración experimental debido a razones legales, comerciales o de plataforma. Por ejemplo: en Bangalore, el biryani de Meghana es uno de los mejores, y las plataformas de entrega en línea (Swiggy o Zomato) notaron que existe una alta probabilidad de que los clientes que gastan mucho también hagan pedidos a Meghana. La hipótesis es que los clientes de Meghana, en promedio, gastan más que el resto. Pero Swiggy o Zomato no pueden eliminar a Meghana de la plataforma para el 50 % de los clientes solo por el bien del experimento. Habría una reacción violenta de los clientes, así como del restaurante. Con SCM, se puede crear un control sintético donde los clientes de prueba y control tienen covariables previas al tratamiento similares, y se puede validar la hipótesis.
Resolver el sesgo de selección y usar las heurísticas comerciales correctas mientras se elige el control correcto se vuelve muy importante e incluso puede revertir el resultado de los experimentos. Por ejemplo, la prueba será un conjunto de clientes que ordenaron Meghana's. Para el control, se pueden elegir clientes vegetarianos. Pero intrínsecamente, la prueba y el control son diferentes en el sentido de que el control nunca ha probado la cocina no vegetariana. Otra forma de controlar son los clientes que nunca pidieron biryani, pero este no sería un control apropiado, ya que Meghana's es un restaurante que sirve biryani en gran medida. Otra forma de controlar es usando geografías. Como Meghana's no está presente en Delhi, los clientes de Delhi pueden usarse como control. Pero los hábitos alimentarios de los usuarios de Delhi son diferentes a los de los usuarios del sur de la India y esto provocará un sesgo si el experimento se divide en varias dimensiones, como el grupo de edad, el género y la cocina. La heurística comercial correcta se convierte así en una parte esencial al resolver el control sintético.
Tabla de Contenido
Los controles sintéticos se pueden crear utilizando coincidencias. La coincidencia de puntaje de propensión es el método más común que se usa para crear SC porque es fácil, requiere menos tiempo, ahorra mucho dinero y se puede escalar a una gran base de usuarios. El proceso se puede repetir N veces hasta que la prueba y el control sean más similares. las cohortes están emparejadas.
Pasos involucrados en la coincidencia de puntuación de propensión:
- Seleccione un gran grupo de clientes: edad, sexo, ventas, unidades, etc. Estas son covariables que pueden causar sesgos.
- El objetivo principal es hacer coincidir las covariables antes de la intervención. Para cada cliente que pagó con una tarjeta de crédito (cliente de prueba, en control), debe haber un cliente cuyas covariables de pretratamiento sean similares a las de la prueba pero que no pagó con una tarjeta sino que usó UPI o banca por Internet en su lugar.
- Ajuste el modelo de clasificación para obtener puntajes de propensión. La precisión no es importante ya que las probabilidades predichas se utilizan para hacer coincidir diferentes usuarios. Se puede utilizar la regresión basada en árboles o logística. La ventaja del método basado en árboles es que se pueden ignorar los supuestos de regresión logística.
- Usando el puntaje de probabilidad, digamos que 0.6 y 0.61 pueden coincidir usando k vecino más cercano. La coincidencia puede ser 1:1 o 1:muchos, que utiliza duplicados.
- Ahora investigue cómo el tratamiento ha afectado el resultado. El tratamiento es binario, 1 ó 0. Ordenó o no Meghana, usó tarjeta o no. Pero el resultado puede ser continuo (ingresos futuros o binarios), batido o no, etc.
Planteamiento del problema
El conjunto de datos utilizado aquí se basa en historial de pago del cliente. Desglosémoslo siguiendo el ejemplo del enunciado del problema de la tarjeta de débito.
Hipótesis: H0: Los clientes que pagan con tarjetas tienen mayores ingresos por correo. Hipótesis alternativa: H1: los clientes que pagan con tarjetas no tienen ingresos posteriores más altos (de ahí el experimento para eliminar los pagos con tarjeta por completo de la plataforma). Si P<0.05, podemos rechazar la hipótesis nula y decir de manera concluyente que los clientes que pagan con tarjetas no tienen mayores ingresos por correo.
Aquí hay tres períodos de tiempo: Pre-período, en el que se basan las características/covariables. Período de tratamiento, donde los clientes pagan con tarjetas. Período posterior donde se mide el resultado, en este caso, los ingresos posteriores. Es importante elegir estos períodos con cuidado para evitar el sesgo de eventos, asegurando que no se planeó ni ejecutó ningún evento promocional durante este tiempo. Por ejemplo, durante octubre y noviembre, debido a las festividades y el reembolso de los socios bancarios, los usuarios prefieren las tarjetas de crédito, ya que ofrecen descuentos de 500 a 5000. Considerar este período para el análisis claramente sesgaría los resultados.
En aras de este análisis, supongamos que el período previo fue del 21 de enero al 21 de junio, y las covariables utilizadas para entrenar el modelo se derivan de este período. El tratamiento utiliza tarjetas de débito/crédito durante el período de tratamiento y es la variable dependiente del modelo. Consideremos que el período de tratamiento fue la primera semana de julio y el resultado posterior al período fueron los siguientes 30 días.
Se ha actualizado el análisis de datos exploratorios de este conjunto de datos. esta página.
Preprocesamiento de datos
- Lea el conjunto de datos y elimine características irrelevantes. pago con tarjeta es la variable dependiente:
df_fintec = pd.read_csv("https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/07_cred/Analytics%20Assignment/data_for_churn_analysis.csv") cols_basic_model = ['número_de_tarjetas', 'pagos_iniciados', 'pagos_fallidos', ' payments_completed', 'payments_completed_amount_first_7days', 'reward_purchase_count_first_7days', 'coins_redeemed_first_7days', 'is_referral', 'visits_feature_1', 'visits_feature_2', 'given_permission_1', 'given_permission_2'] df_fintec_LR = df_fintec[cols_basic_model] df_fintec_LR["is_referral"] = df_fintec_LR[ "is_referral"].astype(int) df_fintec_LR.fillna(0, inplace = True) oh_cols = ["is_referral","given_permission_1","given_permission_2"] df_fintec_LR.drop(columns = oh_cols, inplace = True)
Presiona Ejecutar para ver la salida
- Prepare funciones de división y escala de prueba de tren (catboost también funciona sin estandarización de funciones):
df_fintec = df_fintec.rename(columns={'is_churned': 'card_payment'}) X_train, X_test, y_train, y_test = train_test_split(df_fintec_LR, df_fintec[["card_payment"]],random_state = 70, test_size=0.30) scaler = StandardScaler () scaler.fit(X_train) X_train_Scaled = scaler.transform(X_train) X_test_Scaled = scaler.transform(X_test) X, y =X_train_Scaled ,y_train
Modelado
- Use un modelo simple, ya que estamos más interesados en el puntaje de propensión:
clf = CatBoostClassifier( iteraciones=5, tasa_de_aprendizaje=0.1, #función_de_pérdida='Entropía cruzada' ) clf.fit(X_tren, y_tren, detallado=Falso) y_pred = clf.predict(X_prueba, tipo_predicción='Probabilidad') y_pred y_pred_df = pd. DataFrame(y_pred,columns = ["zero","one"]) y_pred_df.head() df_test = pd.concat([X_test.reset_index(drop=True), y_test.reset_index(drop=True)], axis=1 ) df_test = pd.concat([df_test.reset_index(drop=True), y_pred_df[["one"]].reset_index(drop=True)], axis=1) df_test['revenue'] = np.random.randint (0,50000, size=len(df_test)) display(df_test.head()) sns.histplot(data=df_test, x='one', hue='card_payment') # multiple="dodge" for
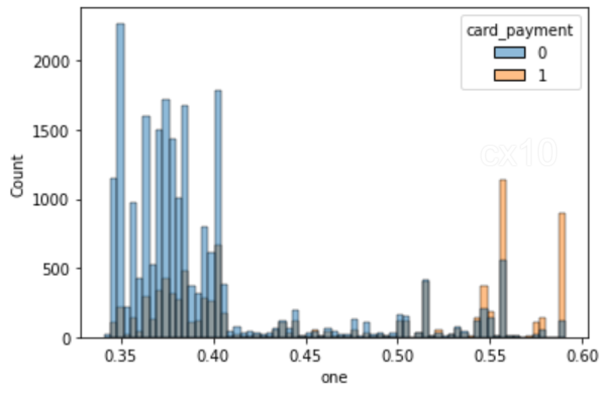
Como se observa en el histograma, existen áreas claras de superposición, por lo que se pueden obtener unidades similares usando PSM. Si no hubo general entre ellos, no es posible encontrar coincidencias.
Coincidencia usando NearestNeighbors
- Coincidencia usando NearestNeighbors.
from sklearn.neighbors import NearestNeighbors calibre = np.std(df_test.one) * 0.25 print(f'caliper (radius) is: {caliper:.4f}') n_neighbors = 10 # setup knn knn = NearestNeighbors(n_neighbors=n_neighbors, radius=caliper) ps = df_test[['one']] # corchetes dobles como marco de datos knn.fit(ps)
# distancias e índices distancias, índices_vecinos = knn.kneighbors(ps) print(índices_vecinos.forma) # los 10 puntos más cercanos al primer punto print(distancias[0]) print(índices_vecinos[0])
# para cada punto en el tratamiento, encontramos un punto coincidente en el control sin reemplazo # tenga en cuenta que los 10 vecinos pueden incluir tanto puntos en el tratamiento como en el control matched_control = [] # realizar un seguimiento de las observaciones coincidentes en el control del índice_actual, fila en df_test.iterrows (): # iterar sobre el marco de datos si fila.pago_tarjeta == 0: # la fila actual está en el grupo de control df_test.loc[índice_actual, 'coincidencia'] = np.nan # establecer coincidencia con nan else: para idx en índices_vecinos [índice_actual, :): # para cada fila en tratamiento, encuentre los k vecinos # asegúrese de que la fila actual no sea el idx - no coincida consigo mismo # y el vecino está en el control si (índice_actual!= idx) y (df_test.loc[idx].card_payment == 0): si idx no está en matched_control: # este control aún no ha sido emparejado df_test.loc[current_index, 'matched'] = idx # registra el matched_control.append(idx) # añadir la coincidencia al salto de lista
# intente aumentar el número de vecinos y/o calibre para obtener más coincidencias print('total de observaciones en tratamiento:', len(df_test[df_test.card_payment==1])) print('total de observaciones coincidentes en control:', len(control_emparejado))
total observaciones en tratamiento: 8988
total de observaciones emparejadas en control: 1296
# el control no tiene coincidencias tratamiento_coincidente = df_test.dropna(subconjunto=['coincidencia']) # gota no coincidente # índices de observación de control coincidentes control_coincidente_idx = tratamiento_coincidente.coincidente control_coincidente_idx = control_coincidente_idx.astype(int) # cambio a int control_coincidente = df_test.loc [control_matched_idx, :] # seleccionar observaciones de control emparejadas # combinar el tratamiento y el control emparejados df_matched = pd.concat([tratamiento_matched, control_matched]) df_matched.card_payment.value_counts()
1 1296
0 1296
Nombre: pago con tarjeta, tipo de d: int64
sns.histplot(data=df_matched, x='número_de_tarjetas', hue='pago_con_tarjeta') sns.histplot(data=df_matched, x='pagos_completados_cantidad_primeros_7días', hue='pago_con_tarjeta')
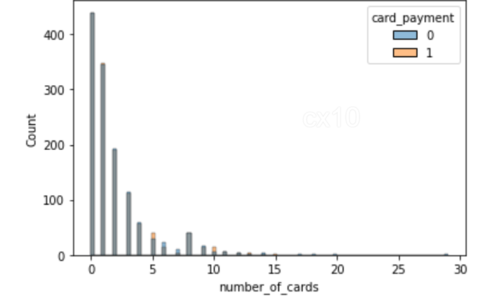
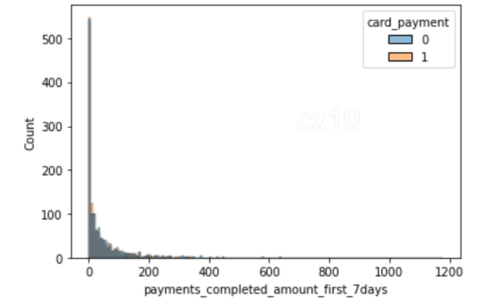
A partir de los 2 histogramas, está claro que la distribución de covariables después de la coincidencia de propensión es casi la misma para 2 características: la cantidad de tarjetas y el monto de los pagos completados en los primeros siete días. Lo mismo se puede trazar para otras características también.
Antes y después
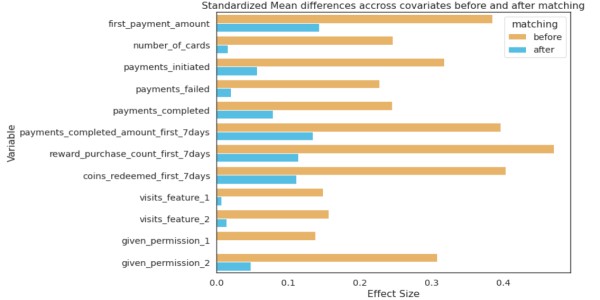
La distribución de las covariables antes y después debería mostrar diferencias significativas en SD; solo entonces se puede concluir que el emparejamiento ha sido efectivo.
from numpy import mean from numpy import var from math import sqrt # función para calcular la d de Cohen para muestras independientes def cohen_d(d1, d2): # calcular el tamaño de las muestras n1, n2 = len(d1), len(d2) # calcular la varianza de las muestras s1, s2 = var(d1, ddof=1), var(d2, ddof=1) # calcular la desviación estándar agrupada s = sqrt(((n1 - 1) * s1 + (n2 - 1) * s2) / (n1 + n2 - 2)) # calcular las medias de las muestras u1, u2 = media(d1), media(d2) # calcular el retorno del tamaño del efecto (u1 - u2) / s
effect_sizes = [] cols = list(X_train.columns) # control y tratamiento separados para la prueba t df_control = df_fintec[df_fintec.card_payment==0] df_treatment = df_fintec[df_fintec.card_payment==1] for cl in cols: _, p_antes = tprueba_ind(df_control[cl], df_tratamiento[cl]) _, p_después = tprueba_ind(df_control_emparejado[cl], df_tratamiento_emparejado[cl]) cohen_d_antes = cohen_d(df_tratamiento[cl], df_control[cl]) cohen_d_después = cohen_d(df_tratamiento_emparejado[ cl], df_matched_control[cl]) effect_sizes.append([cl,'before', cohen_d_before, p_before]) effect_sizes.append([cl,'after', cohen_d_after, p_after])
df_effect_sizes = pd.DataFrame(effect_sizes, column=['feature', 'matching', 'effect_size', 'p-value']) fig, ax = plt.subplots(figsize=(15, 5)) sns.barplot( data=df_effect_sizes, x='effect_size', y='feature', hue='matching', orient='h')
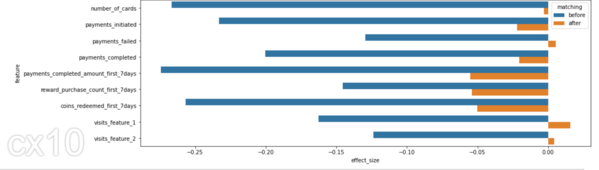
La D de Cohen, o diferencia de medias estandarizada, es una de las formas más comunes de medir el tamaño del efecto. Antes de emparejar, la diferencia en SD es mayor entre la prueba y el control (barras azules). Después de igualar la diferencia SD es menor, la prueba y el control tienen distribuciones similares antes del período de tratamiento.
Prueba estadística para medir el impacto del tratamiento
Pruebas T de Student para comparar las medias de dos grupos. Si se trataba de retención o abandono posterior al período, se podría usar la prueba de chi-cuadrado.
# prueba t del estudiante para ingresos (variable dependiente) después de hacer coincidir # el valor p no es significativo ahora de scipy.stats import ttest_ind print(df_matched_control.revenue.mean(), df_matched_treatment.revenue.mean()) # comparar muestras _, p = ttest_ind(df_matched_control.revenue, df_matched_treatment.revenue) print(f'p={p:.3f}') # interpretar alfa = 0.05 # nivel de significancia si p > alfa: print('mismas distribuciones/misma media de grupo (no rechazar H0 - no tenemos suficiente evidencia para rechazar H0)') else: print('distribuciones diferentes/media de grupo diferente (rechazar H0)')
25105.91898148148 24040.162037037036
p = 0.062
Mismas distribuciones/misma media de grupo (no se puede rechazar H0; no tenemos suficiente evidencia para rechazar H0)
Como P-value > 0.05, no podemos rechazar la hipótesis nula, por lo tanto, los clientes que pagan con tarjetas tienen mayores ingresos por correo. Por lo tanto, se ahorra tiempo y recursos que se habrían invertido en la creación de esta nueva función.
Otra forma de hacer coincidir usando NearestNeighbors
Además de PSM, también existen otros métodos de coincidencia. Un fragmento de código para el mismo.
from sklearn.preprocessing import StandardScaler from sklearn.neighbors import NearestNeighbors def get_matching_pairs(ected_df, no_tratado_df, escalador=Verdadero): tratado_x = tratado_df.valores no_tratado_x = no_tratado_df.valores if escalador == True: escalador = StandardScaler() if escalador: escalador. ajuste (tratado_x) tratado_x = escalador.transformar(tratado_x) no_tratado_x = escalador.transformar(no_tratado_x) nbrs = Vecinos más cercanos(n_vecinos=1, algoritmo='bola_árbol').ajuste(no_tratado_x) distancias, índices = nbrs.kneighbors(tratados_x) índices = indices.reshape(indices.shape[0]) coincidentes = non_ected_df.iloc[indices] devuelven coincidentes
importar pandas como pd importar numpy como np importar matplotlib.pyplot como plt tratado_df = pd.DataFrame() np.random.seed(1) tamaño_1 = 200 tamaño_2 = 1000 tratado_df['x'] = np.random.normal(0,1, 1,tamaño=tamaño_50,20) tratado_df['y'] = np.aleatorio.normal(1,tamaño=tamaño_0,100) tratado_df['z'] = np.aleatorio.normal(1,tamaño=tamaño_0,3) no_tratado_df = pd. DataFrame() # dos poblaciones diferentes no_tratadas_df['x'] = list(np.random.normal(2,size=size_1,2)) + list(np.random.normal(-2,size=2*size_50,30 )) no_tratado_df['y'] = lista(np.aleatorio.normal(2,tamaño=tamaño_100,2)) + lista(np.aleatorio.normal(-2,tamaño=2*tamaño_0,200)) no_tratado_df[' z'] = list(np.random.normal(2,size=size_13,200)) + list(np.random.normal(2,size=2*size_6,6)) matched_df = get_matching_pairs(tratado_df, no_tratado_df) fig, ax = plt .subplots(figsize=(0.3)) plt.scatter(df_no_tratado['x'], df_no_tratado['y'], alpha=1,2, label='Todos los no tratados') plt.scatter(df_tratado['x '], tratado_df['y'], label='Tratado') plt.scatter(matched_df['x'], matched_df['y'], marcador='x' , etiqueta='coincidencia') plt.leyenda() plt.xlim(-XNUMX)
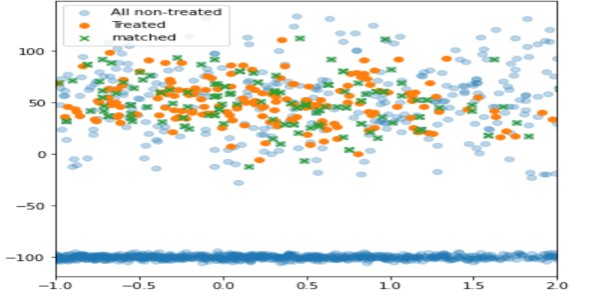
Con esta técnica, solo se emparejan (en verde) las unidades no tratadas con proximidad a la tratada, mientras que el resto se ha dejado fuera (azul claro).
psmpy – Biblioteca de emparejamiento de puntuación de propensión de Python
PSMPY simplifica PSM, reduciéndolo efectivamente a solo 10 líneas de código. El marco se ocupa de la construcción, la coincidencia y el escalado del modelo. Una desventaja es que se escala mal para más de 50 XNUMX unidades.
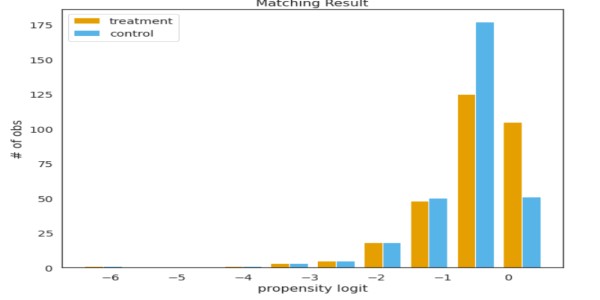
from psmpy import PsmPy from psmpy.plotting import * df_fintec.fillna(0, inplace = True) psm = PsmPy(df_fintec, tratamiento='pago_tarjeta', indx='id_usuario', excluir = ['es_referencia', 'edad', ' city', 'device']) # igual que mi código usando balance=False psm.logistic_ps(balance=False) psm.predicted_data psm.knn_matched(matcher='propensity_logit', replace=False, caliper=Ninguno) psm.plot_match( Título='Resultado coincidente', Ylabel='# de obs', Xlabel= 'logit de propensión', nombres = ['tratamiento', 'control']) display(psm.effect_size) psm.effect_size_plot()
Desventajas de
Los valores de sus covariables no serán idénticos para dos individuos con puntajes de propensión idénticos. PSM equilibra efectivamente los valores promedio de las covariables entre cohortes. Básicamente, si el promedio de la cantidad de tarjetas en la prueba y el control es el mismo, pero si se eligen dos usuarios con los mismos valores de propensión, sus covariables serán diferentes.
A medida que crece el número de covariables, la maldición de la dimensionalidad afecta la coincidencia, reduciendo las posibilidades a casi cero.
Conclusión
- Controlar el sesgo inherente puede conducir a buenos resultados.
- Elija las covariables previas al período adecuadas en función del problema en cuestión.
- La hipótesis debe estar respaldada por la perspicacia comercial y los datos.
Hágame saber los otros casos de uso de PSM en la sección de comentarios a continuación.
¡Buena suerte! Aquí está mi LinkedIn perfil si quieres conectar conmigo o quieres ayudar a mejorar el artículo. Consulte mis otros artículos sobre ciencia de datos y análisis esta página.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2022/12/introduction-to-synthetic-control-using-propensity-score-matching/

