Puede utilizar el EMR de Amazon API de pasos para enviar Apache Hive, Apache Spark y otros tipos de aplicaciones a un clúster de EMR. Puede invocar la API de pasos usando Apache Airflow, Funciones de pasos de AWS, el Interfaz de línea de comandos de AWS (AWS CLI), todos los SDK de AWS y el Consola de administración de AWS. Los trabajos enviados con la API de pasos utilizan el Nube informática elástica de Amazon (Amazon EC2) perfil de instancia para acceder a los recursos de AWS, como Servicio de almacenamiento simple de Amazon (Amazon S3) baldes, Pegamento AWS tablas, y Amazon DynamoDB tablas del clúster.
Anteriormente, si un paso necesitaba acceso a un depósito de S3 específico y otro paso necesitaba acceso a una tabla específica de DynamoDB, el Gestión de identidades y accesos de AWS (IAM) adjunta al perfil de la instancia tenía que permitir el acceso tanto al depósito S3 como a la tabla de DynamoDB. Esto significaba que las políticas de IAM que asignó al perfil de la instancia debían contener una unión de todos los permisos para cada paso que se ejecutaba en un clúster de EMR.
Nos complace presentar roles de tiempo de ejecución para los pasos de EMR. Un rol de tiempo de ejecución es un rol de IAM que asocia con un paso de EMR, y los trabajos usan este rol para acceder a los recursos de AWS. Con los roles de tiempo de ejecución para los pasos de EMR, ahora puede especificar diferentes roles de IAM para los trabajos de Spark y Hive, limitando así el acceso a nivel de trabajo. Esto le permite simplificar los controles de acceso en un solo clúster de EMR que se comparte entre múltiples inquilinos, donde cada inquilino se puede aislar fácilmente mediante roles de IAM.
La capacidad de especificar un rol de IAM con un trabajo también está disponible en Amazon EMR en EKS y Amazon EMR sin servidor. También puedes usar Formación del lago AWS para aplicar permisos de nivel de tabla y columna para trabajos de Apache Hive y Apache Spark que se envían con pasos de EMR. Para obtener más información, consulte Configurar roles de tiempo de ejecución para los pasos de Amazon EMR.
En esta publicación, profundizamos en los roles de tiempo de ejecución para los pasos de EMR, ayudándolo a comprender cómo funcionan juntas las distintas piezas y cómo se aísla cada paso en un clúster de EMR.
Resumen de la solución
En esta publicación, analizamos lo siguiente:
- Cree un clúster de EMR habilitado para usar el nuevo control de acceso basado en roles con pasos de EMR.
- Cree dos roles de IAM con diferentes permisos en términos de los datos de Amazon S3 y las tablas de Lake Formation a las que pueden acceder.
- Permita que la entidad principal de IAM envíe los pasos de EMR para usar estos dos roles de IAM.
- Vea cómo los pasos de EMR que se ejecutan con el mismo código y tratan de acceder a los mismos datos tienen diferentes permisos según el rol de tiempo de ejecución especificado en el momento del envío.
- Vea cómo monitorear y controlar acciones usando la propagación de identidad de origen.
Configurar la configuración de seguridad del clúster de EMR
Configuraciones de seguridad de Amazon EMR simplifique la aplicación de opciones coherentes de seguridad, autorización y autenticación en sus clústeres. Puede crear una configuración de seguridad en la consola de Amazon EMR o mediante la AWS CLI o el SDK de AWS. Cuando asocia una configuración de seguridad a un clúster, Amazon EMR aplica la configuración de la configuración de seguridad al clúster. Puede adjuntar una configuración de seguridad a varios clústeres en el momento de la creación, pero no puede aplicarlos a un clúster en ejecución.
Para habilitar los roles de tiempo de ejecución para los pasos de EMR, debemos crear una configuración de seguridad como se muestra en el siguiente código y habilitar la propiedad de roles de tiempo de ejecución (configurada a través de EnableApplicationScopedIAMRole). Además de los roles de tiempo de ejecución, estamos habilitando la propagación de la identidad de origen (configurada a través de PropagateSourceIdentity) y soporte para Lake Formation (configurado a través de LakeFormationConfiguration). La identidad de origen es un mecanismo para monitorear y controlar las acciones realizadas con los roles asumidos. Habilitación Propagar la identidad de la fuente le permite auditar las acciones realizadas con el rol de tiempo de ejecución. Lake Formation es un servicio de AWS para administrar de forma segura un lago de datos, lo que incluye definir y aplicar políticas de control de acceso central para su lago de datos.
Crea un archivo llamado step-runtime-roles-sec-cfg.json con el siguiente contenido:
Cree la configuración de seguridad de Amazon EMR:
También puede hacer lo mismo a través de la consola de Amazon:
- En la consola de Amazon EMR, elija Configuraciones de seguridad en el panel de navegación.
- Elige Crear.
- Elige Crear.

- Nombre de la configuración de seguridad, ingresa un nombre.
- Opciones de configuración de configuración de seguridad, seleccione Elija configuraciones personalizadas.

- Rol de IAM para aplicaciones, seleccione Rol de tiempo de ejecución.
- Seleccione Propagar la identidad de la fuente para auditar las acciones realizadas con el rol de tiempo de ejecución.
- Control de acceso detallado, seleccione Formación del lago AWS.
- Complete la configuración de seguridad.

La configuración de seguridad aparece en su lista de configuración de seguridad. También puede ver que el mecanismo de autorización que se muestra aquí es el rol de tiempo de ejecución en lugar del perfil de instancia.

Lanzar el clúster
Ahora lanzamos un clúster EMR y especificamos la configuración de seguridad que creamos. Para obtener más información, consulte Especificar una configuración de seguridad para un clúster.
El siguiente código proporciona el comando de la AWS CLI para lanzar un clúster de EMR con la configuración de seguridad adecuada. Tenga en cuenta que este clúster se lanza en la VPC predeterminada y la subred pública con los roles de IAM predeterminados. Además, el clúster se lanza con una instancia principal y una principal del tipo de instancia especificado. Para obtener más detalles sobre cómo personalizar los parámetros de lanzamiento, consulte crear-cluster.
Si los roles EMR predeterminados EMR_EC2_DefaultRole y EMR_DefaultRole no existen en IAM en su cuenta (esta es la primera vez que lanza un clúster de EMR con ellos), antes de lanzar el clúster, use el siguiente comando para crearlos:
Cree el clúster con el siguiente código:
Cuando el clúster está totalmente aprovisionado (Waiting estado), intentemos ejecutar un paso en él con roles de tiempo de ejecución para pasos de EMR habilitados:
Después de ejecutar el comando, recibimos lo siguiente como resultado:
El paso falló, pidiéndonos que proporcionemos un rol de tiempo de ejecución. En la siguiente sección, configuramos dos roles de IAM con diferentes permisos y los usamos como roles de tiempo de ejecución para los pasos de EMR.
Configurar roles de IAM como roles de tiempo de ejecución
Cualquier función de IAM que desee utilizar como función de tiempo de ejecución para los pasos de EMR debe tener una política de confianza que permita que el perfil de instancia EC2 del clúster de EMR la asuma. En nuestra configuración, usamos el rol de IAM predeterminado EMR_EC2_DefaultRole como rol de perfil de instancia. Además, creamos dos roles de IAM llamados test-emr-demo1 y test-emr-demo2 que usamos como roles de tiempo de ejecución para los pasos de EMR.
El siguiente código es la política de confianza para ambos roles de IAM, lo que permite que el rol de perfil de instancia EC2 del clúster de EMR, EMR_EC2_DefaultRole, asumir estos roles y establecer la identidad de origen y LakeFormationAuthorizedCaller etiqueta en las sesiones de rol. los TagSession se necesita permiso para que Amazon EMR pueda autorizar Lake Formation. los SetSourceIdentity Se necesita una declaración para la característica de identidad de fuente de propagación.
Crea un archivo llamado trust-policy.json con el siguiente contenido (reemplazar 123456789012 con su ID de cuenta de AWS):
Use esa política para crear los dos roles de IAM, test-emr-demo1 y test-emr-demo2:
Configurar permisos para el principal que envía los pasos de EMR con roles de tiempo de ejecución
La entidad principal de IAM que envía los pasos de EMR debe tener permisos para invocar el API AddJobFlowSteps. Además, puede utilizar la tecla Condición elasticmapreduce:ExecutionRoleArn para controlar el acceso a funciones específicas de IAM. Por ejemplo, la siguiente política permite que la entidad principal de IAM solo use roles de IAM test-emr-demo1 y test-emr-demo2 como los roles de tiempo de ejecución para los pasos de EMR.
- Crea el
job-submitter-policy.jsonarchivo con el siguiente contenido (reemplazar 123456789012 con su ID de cuenta de AWS): - Cree la política de IAM con el siguiente código:
- Asigne esta política a la entidad principal de IAM (usuario de IAM o rol de IAM) que utilizará para enviar los pasos de EMR (reemplace 123456789012 con su ID de cuenta de AWS y reemplace
johncon el usuario de IAM que utiliza para enviar sus pasos de EMR):
Usuario de IAM john ahora puede enviar pasos usando arn:aws:iam::123456789012:role/test-emr-demo1 y arn:aws:iam::123456789012:role/test-emr-demo2 como los roles de tiempo de ejecución del paso.
Use roles de tiempo de ejecución con pasos de EMR
Ahora preparamos nuestra configuración para mostrar los roles de tiempo de ejecución para los pasos de EMR en acción.
Configurar Amazon S3
Para preparar sus datos de Amazon S3, complete los siguientes pasos:
- Cree un archivo CSV llamado
test.csvcon el siguiente contenido: - Suba el archivo a Amazon S3 en tres ubicaciones diferentes:
Para nuestra prueba inicial, usamos una aplicación PySpark llamada
test.pycon los siguientes contenidos:En la secuencia de comandos, intentamos acceder al archivo CSV presente en tres prefijos diferentes en el depósito de prueba.
- Cargue la aplicación Spark dentro del mismo depósito S3 donde colocamos el
test.csvarchivo pero en una ubicación diferente:
Configurar permisos de roles de tiempo de ejecución
Para mostrar cómo funcionan los roles de tiempo de ejecución para los pasos de EMR, asignamos a los roles que creamos diferentes permisos de IAM para acceder a Amazon S3. La siguiente tabla resume las subvenciones que otorgamos a cada rol (emr-steps-roles-new-us-east-1 es el depósito que configuró en la sección anterior).
| Funciones de IAM de las ubicaciones de S3 | prueba-emr-demo1 | prueba-emr-demo2 |
| s3://emr-steps-roles-nuevo-este-de-ee-uu-1/* | Sin acceso | Sin acceso |
| s3://emr-steps-roles-new-us-east-1/demo1/* | Acceso Completo | Sin acceso |
| s3://emr-steps-roles-new-us-east-1/demo2/* | Sin acceso | Acceso Completo |
| s3://emr-steps-roles-new-us-east-1/scripts/* | Leer acceso | Leer acceso |
- Crea el archivo
demo1-policy.jsoncon el siguiente contenido (sustituiremr-steps-roles-new-us-east-1con el nombre de su cubo): - Crea el archivo
demo2-policy.jsoncon el siguiente contenido (sustituiremr-steps-roles-new-us-east-1con el nombre de su cubo): - Crea nuestras políticas de IAM:
- Asigne a cada rol la política relacionada (reemplazar 123456789012 con su ID de cuenta de AWS):
Para usar roles de tiempo de ejecución con los pasos de Amazon EMR, debemos agregar la siguiente política al perfil de instancia EC2 de nuestro clúster de EMR (en este ejemplo
EMR_EC2_DefaultRole). Con esta política, las instancias EC2 subyacentes para el clúster de EMR pueden asumir el rol de tiempo de ejecución y aplicar una etiqueta a ese rol de tiempo de ejecución. - Crea el archivo
runtime-roles-policy.jsoncon el siguiente contenido (reemplazar 123456789012 con su ID de cuenta de AWS): - Cree la política de IAM:
- Asigne la política creada al perfil de instancia EC2 del clúster de EMR, en este ejemplo
EMR_EC2_DefaultRole:
Probar permisos con roles de tiempo de ejecución
Ahora estamos listos para realizar nuestra primera prueba. ejecutamos el test.py script, previamente cargado en Amazon S3, dos veces como pasos de Spark: primero usando el test-emr-demo1 rol y luego usando el test-emr-demo2 rol como los roles de tiempo de ejecución.
Para ejecutar un paso de EMR que especifique un rol de tiempo de ejecución, necesita la versión más reciente de la CLI de AWS. Para obtener más detalles sobre la actualización de la CLI de AWS, consulte Instalación o actualización de la última versión de la AWS CLI.
Vamos a enviar un paso especificando test-emr-demo1 como el rol de tiempo de ejecución:
Este comando devuelve un ID de paso de EMR. Para verificar nuestros registros de salida de pasos, podemos proceder de dos maneras diferentes:
- Desde la consola de Amazon EMR - Sobre el pasos pestaña, elija el Ver los registros enlace relacionado con el ID de paso específico y seleccione
stdout. - Desde Amazon S3 – Al lanzar nuestro clúster, configuramos una ubicación S3 para iniciar sesión. Podemos encontrar nuestros registros de pasos en
$(LOG_URI)/steps//stdout.gz.
Los registros pueden tardar un par de minutos en completarse después de marcar el paso como Completed.
El siguiente es el resultado del paso EMR con test-emr-demo1 como el rol de tiempo de ejecución:
Como podemos ver, sólo el demo1 Nuestra aplicación pudo acceder a la carpeta.
Profundizando en el paso stderr logs, podemos ver que la aplicación YARN relacionada application_1656350436159_0017 fue lanzado con el usuario 6GC64F33KUW4Q2JY6LKR7UAHWETKKXYL. Podemos confirmar esto por conectarse a la instancia principal de EMR mediante SSH y usando el HILO CLI:
Tenga en cuenta que, en su caso, la identificación de la aplicación YARN y el usuario serán diferentes.
Ahora volvemos a enviar el mismo script como un nuevo paso de EMR, pero esta vez con el rol test-emr-demo2 como el rol de tiempo de ejecución:
El siguiente es el resultado del paso EMR con test-emr-demo2 como el rol de tiempo de ejecución:
Como podemos ver, sólo el demo2 Nuestra aplicación pudo acceder a la carpeta.
Profundizando en el paso stderr logs, podemos ver que la aplicación YARN relacionada application_1656350436159_0018 fue lanzado con un usuario diferente 7T2ORHE6Z4Q7PHLN725C2CVWILZWYOLE. Podemos confirmar esto usando la CLI de YARN:
Cada paso solo pudo acceder al archivo CSV permitido por el rol de tiempo de ejecución, por lo que el primer paso solo pudo acceder s3://emr-steps-roles-new-us-east-1/demo1/test.csv y el segundo paso solo fue capaz de acceder s3://emr-steps-roles-new-us-east-1/demo2/test.csv. Además, observamos que Amazon EMR creó un usuario único para los pasos y utilizó al usuario para ejecutar los trabajos. Tenga en cuenta que ambos roles necesitan al menos acceso de lectura a la ubicación de S3 donde se encuentran los scripts de pasos (por ejemplo, s3://emr-steps-roles-demo-bucket/scripts/test.py).
Ahora que hemos visto cómo funcionan los roles de tiempo de ejecución para los pasos de EMR, veamos cómo podemos usar Lake Formation para aplicar controles de acceso detallados con pasos de EMR.
Use el control de acceso basado en Lake Formation con pasos de EMR
Puede usar Lake Formation para aplicar permisos de nivel de tabla y columna con trabajos de Apache Spark y Apache Hive enviados como pasos de EMR. Primero, el administrador del lago de datos en Lake Formation debe registrarse Amazon EMR como el AuthorizedSessionTagValue para hacer cumplir los permisos de Lake Formation en EMR. Lake Formation usa esta etiqueta de sesión para autorizar a las personas que llaman y proporcionar acceso al lago de datos. los Amazon EMR se hace referencia al valor dentro del step-runtime-roles-sec-cfg.json que usamos anteriormente cuando creamos la configuración de seguridad de EMR, y dentro del trust-policy.json archivo que usamos para crear los dos roles de tiempo de ejecución test-emr-demo1 y test-emr-demo2.
Podemos hacerlo en la consola de Lake Formation en el Filtrado de datos externos sección (reemplazar 123456789012 con su ID de cuenta de AWS).
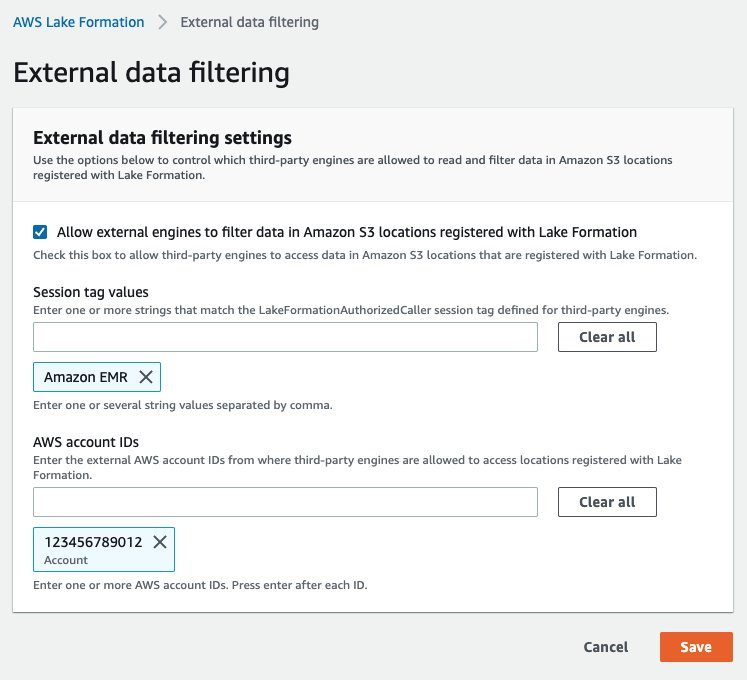
En la política de confianza de los roles de tiempo de ejecución de IAM, ya tenemos la sts:TagSession permiso con la condición “aws:RequestTag/LakeFormationAuthorizedCaller": "Amazon EMR". Así que estamos listos para continuar.
Para demostrar cómo funciona Lake Formation con los pasos de EMR, creamos una base de datos llamada entities con dos tablas nombradas users y products, y asignamos en Formación Lago las mercedes resumidas en la siguiente tabla.
| Tablas de roles de IAM | entidades (DB) |
|
| usuarios (Mesa) |
productos (Mesa) |
|
| prueba-emr-demo1 | Acceso de lectura completo | Sin acceso |
| prueba-emr-demo2 | Acceso de lectura en columnas: uid, estado | Acceso de lectura completo |
Preparar archivos de Amazon S3
Primero preparamos nuestros archivos de Amazon S3.
- Crea el
users.csvArchivo con el siguiente contenido: - Cree el archivo products.csv con el siguiente contenido:
- Cargue estos archivos en Amazon S3 en dos ubicaciones diferentes:
Preparar la base de datos y las tablas.
Podemos crear nuestro entities base de datos utilizando el API de pegamento de AWS.
- Crea el
entities-db.jsonarchivo con el siguiente contenido (sustituiremr-steps-roles-new-us-east-1 con el nombre de su depósito): - Con un usuario administrador de Lake Formation, ejecute el siguiente comando para crear nuestra base de datos:
También utilizamos las API de AWS Glue para crear las tablas de usuarios y productos.
- Crea el
users-table.jsonarchivo con el siguiente contenido (sustituiremr-steps-roles-new-us-east-1con el nombre de su cubo): - Crea el
products-table.jsonarchivo con el siguiente contenido (sustituiremr-steps-roles-new-us-east-1con el nombre de su cubo): - Con un usuario administrador de Lake Formation, cree nuestras tablas con los siguientes comandos:
Configurar las ubicaciones del lago de datos de Lake Formation
Para acceder a los datos de nuestras tablas en Amazon S3, Lake Formation necesita acceso de lectura/escritura. Para lograrlo, debemos registrar las ubicaciones de Amazon S3 donde residen nuestros datos y especificarles de qué rol de IAM obtener las credenciales.
Vamos a crear nuestro rol de IAM para el acceso a los datos.
- Crea un archivo llamado
trust-policy-data-access-role.jsoncon el siguiente contenido: - Utilice la política para crear el IAM
role emr-demo-lf-data-access-role: - Crea el archivo
data-access-role-policy.jsoncon el siguiente contenido (sustituiremr-steps-roles-new-us-east-1con el nombre de su cubo): - Crea nuestra política de IAM:
- Asignar a nuestro
emr-demo-lf-data-access-rolela política creada (reemplazar 123456789012 con su ID de cuenta de AWS):Ahora podemos registrar nuestra ubicación de datos en Lake Formation.
- En la consola de Lake Formation, elija Ubicaciones de data lake en el panel de navegación.
- Aquí podemos registrar nuestra ubicación S3 que contiene datos para nuestras dos tablas y elegir la creada
emr-demo-lf-data-access-roleRol de IAM, que tiene acceso de lectura/escritura a esa ubicación.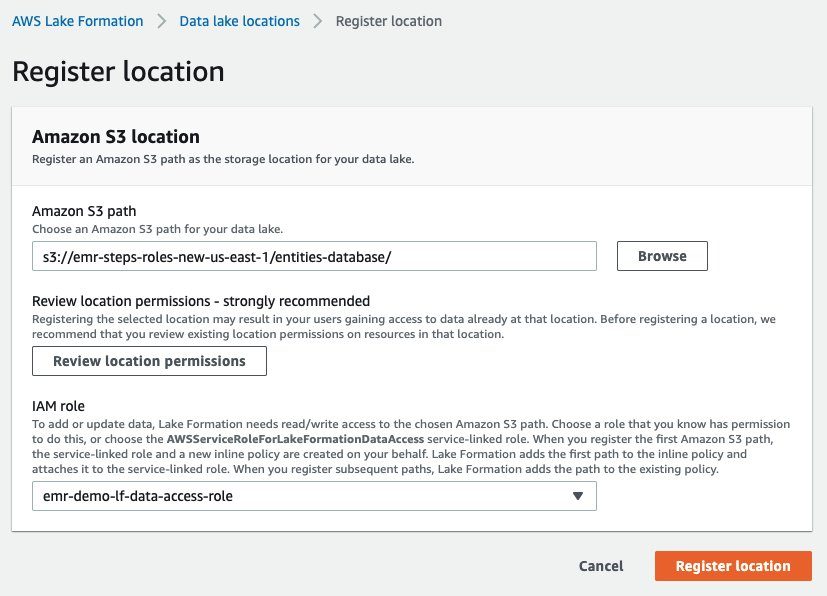
Para obtener más detalles sobre cómo agregar una ubicación de Amazon S3 a su lago de datos y configurar sus funciones de acceso a datos de IAM, consulte Agregar una ubicación de Amazon S3 a su lago de datos.
Hacer cumplir los permisos de formación de lagos
Para asegurarnos de que estamos usando los permisos de Lake Formation, debemos confirmar que no tenemos ninguna concesión configurada para el director IAMAllowedPrincipals. IAMAllowedPrincipals El grupo incluye todos los usuarios y funciones de IAM a los que sus políticas de IAM permiten el acceso a los recursos de Data Catalog y se utiliza para mantener la compatibilidad con versiones anteriores de AWS Glue.
Para confirmar que se aplican los permisos de Lake Formations, vaya a la consola de Lake Formations y elija Permisos del lago de datos en el panel de navegación. Filtrar permisos por “Database”:“entities” y eliminar todos los permisos otorgados al principal IAMAllowedPrincipals.
Para más detalles sobre IAMAllowedPrincipals y compatibilidad con versiones anteriores de AWS Glue, consulte Cambiar la configuración de seguridad predeterminada para su lago de datos.
Configurar concesiones de AWS Glue y Lake Formation para roles de tiempo de ejecución de IAM
Para permitir que nuestros roles de tiempo de ejecución de IAM interactúen correctamente con Lake Formation, debemos proporcionarles la lakeformation:GetDataAccess y glue:Get* subsidios.
Los permisos de Lake Formation controlan el acceso a los recursos de Data Catalog, las ubicaciones de Amazon S3 y los datos subyacentes en esas ubicaciones. Los permisos de IAM controlan el acceso a las API y los recursos de Lake Formation y AWS Glue. Por lo tanto, aunque es posible que tenga el permiso de Lake Formation para acceder a una tabla en Data Catalog (SELECT), su operación falla si no tiene el permiso de IAM en el glue:Get* API.
Para obtener más detalles sobre el control de acceso de Lake Formation, consulte Descripción general del control de acceso de Lake Formation.
- Crea el
emr-runtime-roles-lake-formation-policy.jsonArchivo con el siguiente contenido: - Cree la política de IAM relacionada:
- Asigne esta política a ambos roles de tiempo de ejecución de IAM (reemplace 123456789012 con su ID de cuenta de AWS):
Configurar permisos de formación de lagos
Ahora configuramos el permiso en Lake Formation para los dos roles de tiempo de ejecución.
- Crea el archivo
users-grants-test-emr-demo1.jsoncon el siguiente contenido para otorgar acceso SELECT a todas las columnas en elentities.usersmesa paratest-emr-demo1: - Crea el archivo
users-grants-test-emr-demo2.jsoncon el siguiente contenido para otorgar acceso SELECT a lauidystatecolumnas en elentities.usersmesa paratest-emr-demo2: - Crea el archivo
products-grants-test-emr-demo2.jsoncon el siguiente contenido para otorgar acceso SELECT a todas las columnas en elentities.productsmesa paratest-emr-demo2: - Configuremos nuestros permisos en Lake Formation:
- Verifique los permisos que definimos en la consola de Lake Formation en el Permisos del lago de datos página filtrando por
“Database”:“entities”.

Probar los permisos de Lake Formation con roles de tiempo de ejecución
Para nuestra prueba, usamos una aplicación PySpark llamada test-lake-formation.py con el siguiente contenido:
En el script, estamos tratando de acceder a las tablas. users y products. Carguemos nuestra aplicación Spark en el mismo depósito S3 que usamos anteriormente:
Ahora estamos listos para realizar nuestra prueba. ejecutamos el test-lake-formation.py script primero usando el test-emr-demo1 rol y luego usando el test-emr-demo2 rol como los roles de tiempo de ejecución.
Vamos a enviar un paso especificando test-emr-demo1 como el rol de tiempo de ejecución:
El siguiente es el resultado del paso EMR con test-emr-demo1 como el rol de tiempo de ejecución:
Como podemos ver, nuestra aplicación solo pudo acceder a la users mesa.
Vuelva a enviar el mismo script como un nuevo paso de EMR, pero esta vez con el rol test-emr-demo2 como el rol de tiempo de ejecución:
El siguiente es el resultado del paso EMR con test-emr-demo2 como el rol de tiempo de ejecución:
Como podemos ver, nuestra aplicación pudo acceder a un subconjunto de columnas para el users tabla y todas las columnas para el products mesa.
Podemos concluir que los permisos al acceder al catálogo de datos se aplican en función del rol de tiempo de ejecución utilizado con el paso EMR.
Auditoría utilizando la identidad de origen
El proyecto identidad de origen es un mecanismo para monitorear y controlar las acciones realizadas con los roles asumidos. los Propagar la identidad de la fuente La función le permite monitorear y controlar las acciones realizadas mediante roles de tiempo de ejecución por los trabajos enviados con los pasos de EMR.
ya lo configuramos EMR_EC2_defaultRole "sts:SetSourceIdentity" en nuestros dos roles de tiempo de ejecución. Además, ambos roles de tiempo de ejecución permiten EMR_EC2_DefaultRole a SetSourceIdentity en su política de confianza. Así que estamos listos para continuar.
Ahora vemos el Propagar la identidad de la fuente característica en acción con un ejemplo simple.
Configure el rol de IAM que se asume para enviar los pasos de EMR
Configuramos el rol de IAM job-submitter-1, que se supone que especifica la identidad de origen y que se utiliza para enviar los pasos de EMR. En este ejemplo, permitimos que el usuario de IAM paul para asumir este rol y establecer la identidad de origen. Tenga en cuenta que puede utilizar cualquier principal de IAM aquí.
- Crea un archivo llamado
trust-policy-2.jsoncon el siguiente contenido (reemplazar 123456789012 con su ID de cuenta de AWS): - Úselo como política de confianza para crear el rol de IAM
job-submitter-1:Usamos ahora lo mismo
emr-runtime-roles-submitter-policypolítica que definimos antes para permitir que el rol envíe pasos de EMR usando eltest-emr-demo1ytest-emr-demo2roles de tiempo de ejecución. - Asigne esta política al rol de IAM
job-submitter-1(reemplazar 123456789012 con su ID de cuenta de AWS):
Pruebe la identidad de origen con AWS CloudTrail
Para mostrar cómo funciona la propagación de la identidad de origen con Amazon EMR, generamos una sesión de rol con la identidad de origen test-ad-user.
Con el usuario de IAM paul (o con el principal de IAM que configuró), primero realizamos la suplantación (reemplazar 123456789012 con su ID de cuenta de AWS):
El siguiente código es el resultado recibido:
Usamos las credenciales de seguridad temporales de AWS de la sesión de rol para enviar un paso de EMR junto con el rol de tiempo de ejecución. test-emr-demo1:
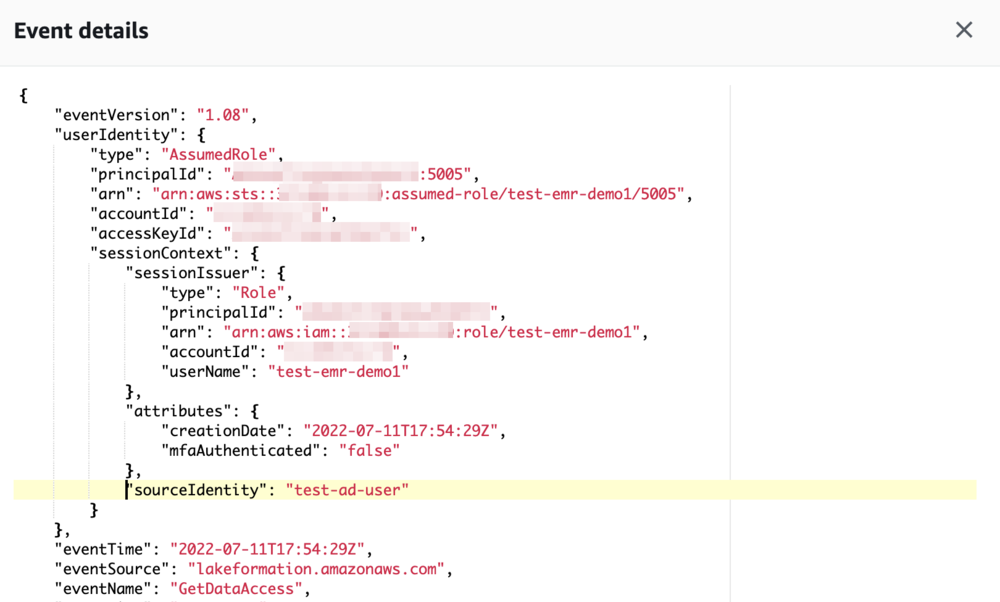
En unos minutos, podemos ver los eventos que aparecen en el Seguimiento de la nube de AWS archivo de registro. Podemos ver todas las API de AWS que invocaron los trabajos mediante el rol de tiempo de ejecución. En el siguiente fragmento, podemos ver que el paso realizó el sts:AssumeRole y lakeformation:GetDataAccess comportamiento. Vale la pena señalar cómo la identidad de origen test-ad-user se ha conservado en los acontecimientos.
Limpiar
Ahora puede eliminar el clúster de EMR que creó.
- En la consola de Amazon EMR, elija Clusters en el panel de navegación.
- Seleccione el clúster
iam-passthrough-cluster, A continuación, elija Terminar. - Elige Terminar de nuevo para confirmar
Como alternativa, puede eliminar el clúster mediante la CLI de Amazon EMR con el siguiente comando (reemplace el ID del clúster de EMR con el que devolvió la ejecución anterior). aws emr create-cluster mando):
Conclusión
En esta publicación, discutimos cómo puede controlar el acceso a los datos en Amazon EMR en clústeres de EC2 mediante el uso de roles de tiempo de ejecución con pasos de EMR. Discutimos cómo funciona la función, cómo puede usar Lake Formation para aplicar controles de acceso detallados y cómo monitorear y controlar acciones usando una identidad de origen. Para obtener más información sobre esta característica, consulte Configurar roles de tiempo de ejecución para los pasos de Amazon EMR.
Sobre los autores
 Stefano Sandona es un arquitecto de soluciones especialista en análisis con AWS. Le encantan los datos, los sistemas distribuidos y la seguridad. Ayuda a clientes de todo el mundo a diseñar sus plataformas de datos. Tiene un fuerte enfoque en Amazon EMR y todos los aspectos de seguridad que lo rodean.
Stefano Sandona es un arquitecto de soluciones especialista en análisis con AWS. Le encantan los datos, los sistemas distribuidos y la seguridad. Ayuda a clientes de todo el mundo a diseñar sus plataformas de datos. Tiene un fuerte enfoque en Amazon EMR y todos los aspectos de seguridad que lo rodean.
 sharad kala es un ingeniero sénior en AWS que trabaja con el equipo de EMR. Se centra en los aspectos de seguridad de las aplicaciones que se ejecutan en EMR. Tiene un gran interés en trabajar y aprender sobre sistemas distribuidos.
sharad kala es un ingeniero sénior en AWS que trabaja con el equipo de EMR. Se centra en los aspectos de seguridad de las aplicaciones que se ejecutan en EMR. Tiene un gran interés en trabajar y aprender sobre sistemas distribuidos.

