
Imagen generada usando Difusión estable
El mundo de la IA ha cambiado drásticamente hacia el modelado generativo en los últimos años, tanto en visión artificial como en procesamiento de lenguaje natural. Dalle-2 y Midjourney han llamado la atención de la gente, llevándolos a reconocer el trabajo excepcional que se está realizando en el campo de la IA generativa.
La mayoría de las imágenes generadas por IA que se producen actualmente se basan en modelos de difusión como base. El objetivo de este artículo es aclarar algunos de los conceptos relacionados con la difusión estable y ofrecer una comprensión fundamental de la metodología empleada.
Este diagrama de flujo muestra la versión simplificada de una arquitectura de difusión estable. Lo revisaremos pieza por pieza para construir una mejor comprensión del funcionamiento interno. Desarrollaremos el proceso de entrenamiento para una mejor comprensión, con la inferencia teniendo solo algunos cambios sutiles.
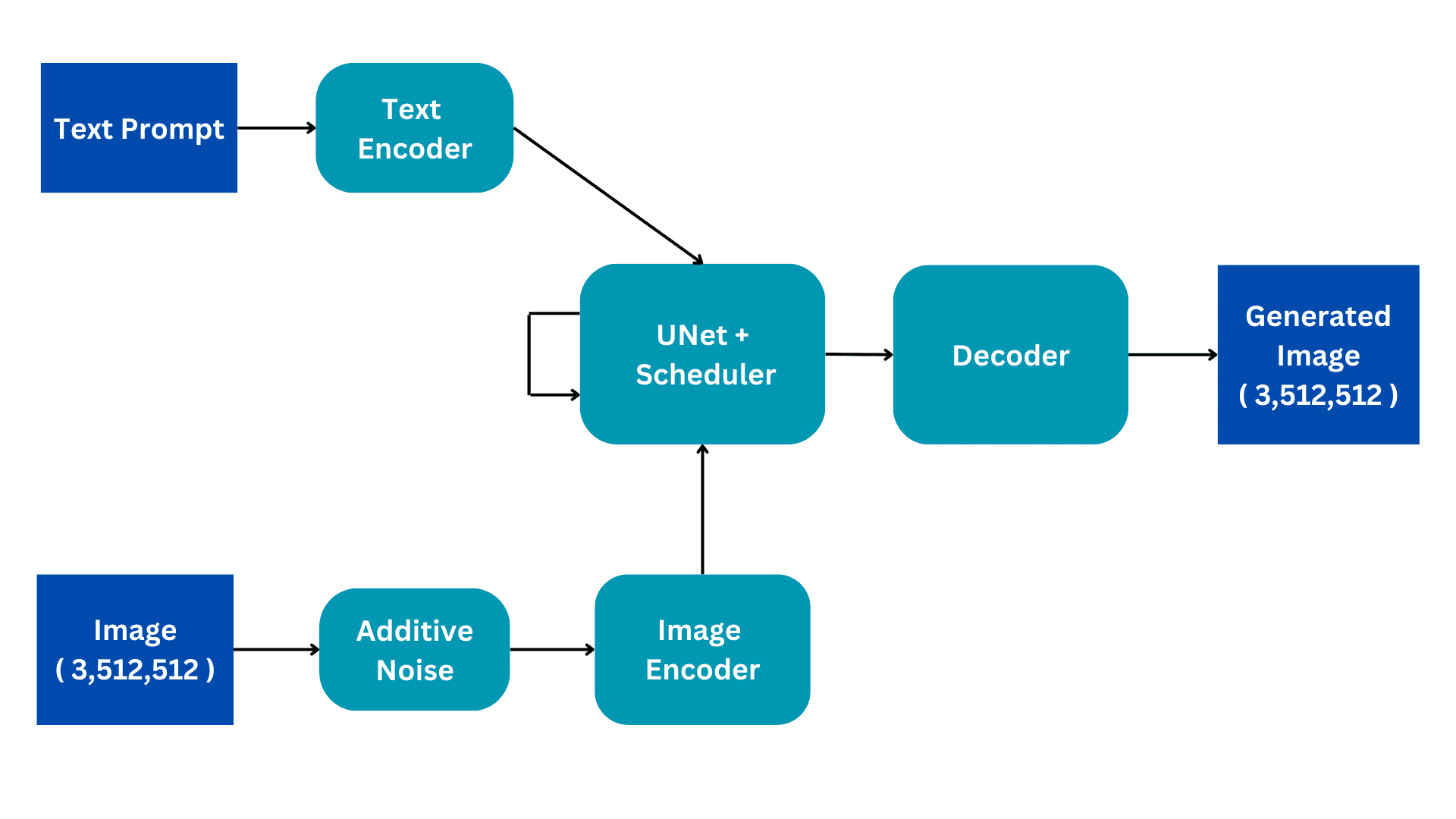
Imagen del autor
Ingresos
Los modelos de difusión estable se entrenan en conjuntos de datos de subtítulos de imagen donde cada imagen tiene un subtítulo o mensaje asociado que describe la imagen. Por lo tanto, hay dos entradas al modelo; un aviso textual en lenguaje natural y una imagen de tamaño (3,512,512) que tiene 3 canales de color y dimensiones de tamaño 512.
Ruido aditivo
La imagen se convierte en ruido completo agregando ruido gaussiano a la imagen original. Esto se hace en pasos consecuentes, por ejemplo, se agrega una pequeña cantidad de ruido a la imagen durante 50 pasos consecutivos hasta que la imagen es completamente ruidosa. El proceso de difusión tendrá como objetivo eliminar este ruido y reproducir la imagen original. Cómo se hace esto se explicará más adelante.
Codificador de imagen
El codificador de imagen funciona como un componente de un codificador automático variacional, convirtiendo la imagen en un "espacio latente" y redimensionándola a dimensiones más pequeñas, como (4, 64, 64), al tiempo que incluye una dimensión de lote adicional. Este proceso reduce los requisitos computacionales y mejora el rendimiento. A diferencia de los modelos de difusión originales, Stable Diffusion incorpora el paso de codificación en la dimensión latente, lo que da como resultado un cálculo reducido, así como una disminución del tiempo de entrenamiento e inferencia.
Codificador de texto
El indicador de lenguaje natural se transforma en una incrustación vectorizada por el codificador de texto. Este proceso emplea un modelo de lenguaje de transformación, como los modelos de texto CLIP basados en BERT o GPT. Los modelos de codificador de texto mejorados mejoran significativamente la calidad de las imágenes generadas. La salida resultante del codificador de texto consiste en una matriz de vectores de incrustación de 768 dimensiones para cada palabra. Para controlar la duración de la solicitud, se establece un límite máximo de 77. Como resultado, el codificador de texto produce un tensor con dimensiones de (77, 768).
Unet
Esta es la parte más costosa desde el punto de vista computacional de la arquitectura y aquí se produce el procesamiento de difusión principal. Recibe codificación de texto e imagen latente ruidosa como entrada. Este módulo tiene como objetivo reproducir la imagen original a partir de la imagen ruidosa que recibe. Lo hace a través de varios pasos de inferencia que se pueden configurar como un hiperparámetro. Normalmente, 50 pasos de inferencia son suficientes.
Considere un escenario simple en el que una imagen de entrada sufre una transformación en ruido al introducir gradualmente pequeñas cantidades de ruido en 50 pasos consecutivos. Esta adición acumulativa de ruido eventualmente transforma la imagen original en ruido completo. El objetivo de UNet es revertir este proceso mediante la predicción del ruido agregado en el paso de tiempo anterior. Durante el proceso de eliminación de ruido, UNet comienza prediciendo el ruido agregado en el paso de tiempo 50 para el paso de tiempo inicial. Luego resta este ruido predicho de la imagen de entrada y repite el proceso. En cada paso de tiempo subsiguiente, UNet predice el ruido agregado en el paso de tiempo anterior, restaurando gradualmente la imagen de entrada original a partir del ruido completo. A lo largo de este proceso, la UNet se apoya internamente en el vector de incrustación textual como factor condicionante.
El UNet genera un tensor de tamaño (4, 64, 64) que se pasa a la parte del decodificador del AutoEncoder Variacional.
Descifrador
El decodificador invierte la conversión de representación latente realizada por el codificador. Toma una representación latente y la vuelve a convertir en espacio de imagen. Por lo tanto, genera una imagen (3,512,512), del mismo tamaño que el espacio de entrada original. Durante el entrenamiento, nuestro objetivo es minimizar la pérdida entre la imagen original y la imagen generada. Dado que, dado un aviso textual, podemos generar una imagen relacionada con el aviso a partir de una imagen completamente ruidosa.
Durante la inferencia, no tenemos ninguna imagen de entrada. Trabajamos solo en modo texto a imagen. Eliminamos la parte Additive Noise y en su lugar usamos un tensor generado aleatoriamente del tamaño requerido. El resto de la arquitectura sigue siendo la misma.
UNet ha recibido capacitación para generar una imagen a partir de ruido completo, aprovechando la incrustación de avisos de texto. Esta entrada específica se utiliza durante la etapa de inferencia, lo que nos permite generar con éxito imágenes sintéticas a partir del ruido. Este concepto general sirve como la intuición fundamental detrás de todos los modelos generativos de visión por computadora.
muhammad arham es un ingeniero de aprendizaje profundo que trabaja en visión artificial y procesamiento de lenguaje natural. Ha trabajado en la implementación y optimización de varias aplicaciones de IA generativa que alcanzaron las listas de éxitos mundiales en Vyro.AI. Está interesado en construir y optimizar modelos de aprendizaje automático para sistemas inteligentes y cree en la mejora continua.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/06/stable-diffusion-basic-intuition-behind-generative-ai.html?utm_source=rss&utm_medium=rss&utm_campaign=stable-diffusion-basic-intuition-behind-generative-ai

