Introducción
Kubeflow es una plataforma de código abierto que facilita la implementación y administración de flujos de trabajo de aprendizaje automático (ML) en Kubernetes, un popular sistema de código abierto para automatizar la implementación, el escalado y la administración de aplicaciones en contenedores.
Kubeflow puede ayudarlo a ejecutar tareas de aprendizaje automático en su computadora al facilitar la configuración y administración de un grupo de computadoras para trabajar juntas en la tarea. Actúa como un "policía de tránsito" para el trabajo de su computadora, asegurando que todos los diferentes pasos de las tareas estén en el orden correcto y que todas las computadoras funcionen juntas correctamente. De esta forma, puede concentrarse en la tarea que tiene entre manos, como hacer predicciones o encontrar patrones en sus datos, y dejar que Kubefnderly intente la infraestructura.
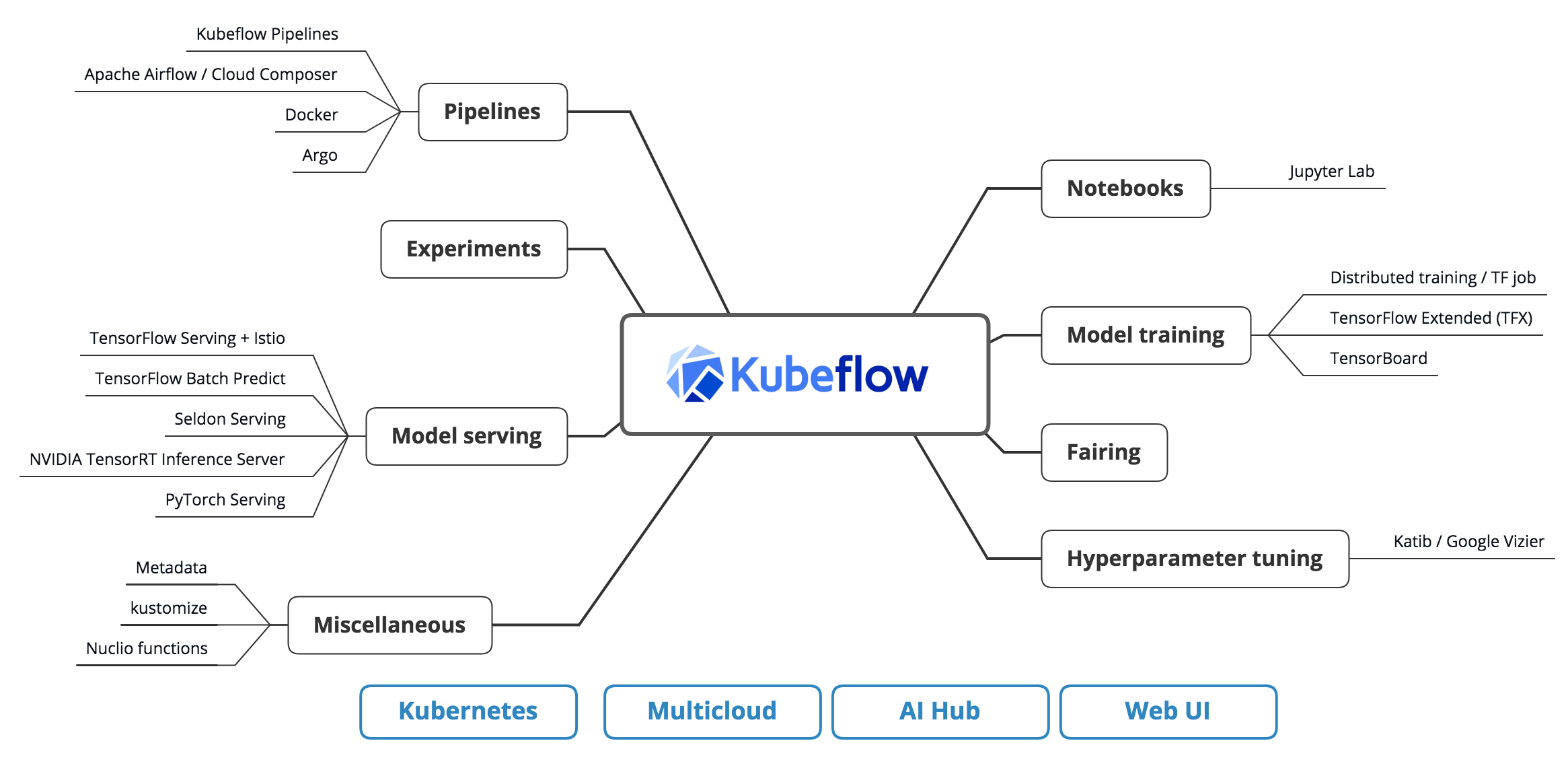
Imagina que tienes una gran caja de juguetes con muchos juguetes diferentes adentro. Kubeflow es como el organizador de la caja de juguetes. Le ayuda a rastrear todos los diferentes tipos de juguetes y asegurarse de que estén en el lugar correcto. Kubernetes es como la propia caja de juguetes. Mantiene todos los juguetes juntos y asegura que no se pierdan. También te ayuda a sacar fácilmente los juguetes con los que quieres jugar y volver a colocarlos cuando hayas terminado. En palabras simples, Kubeflow hace que sea fácil de ejecutar y administrar Flujos de trabajo de aprendizaje automático además de Kubernetes, que ayuda a administrar y escalar aplicaciones en contenedores.
Este artículo analizará un ejemplo completo del uso de Kubeflow para crear, entrenar e implementar un modelo de ML, desde la preparación de datos hasta el servicio del modelo. Cubriremos los diversos componentes de Kubeflow y cómo funcionan juntos para hacer que el flujo de trabajo de ML sea más eficiente y optimizado. Al final de este artículo, comprenderá mejor cómo usar Kubeflow para administrar sus proyectos de ML y podrá aplicar los conceptos a sus propios proyectos.
Objetivos de aprendizaje:
- Comprender los conceptos básicos de Kubeflow y sus componentes.
- Comprender cómo usar Kubeflow para administrar flujos de trabajo de ML
- Aprenda a implementar Kubeflow en un clúster de Kubernetes
- Aprenda a usar Kubeflow para entrenar e implementar modelos ML
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Índice del contenido
- ¿Qué es Kubeflow?
- Implementación de Kubeflow en un clúster de Kubernetes
- Administrar flujos de trabajo de ML con Kubeflow
- Entrenamiento e implementación de modelos ML con Kubeflow
- Canalización de Kubeflow
- Realice un seguimiento del progreso y los resultados de las ejecuciones de canalización
- Evaluación modelo
- Implementación de modelos y ajuste de hiperparámetros en proceso
- Conclusión
¿Qué es Kubeflow?
Kubeflow se utiliza para simplificar la implementación y la gestión de flujos de trabajo de aprendizaje automático (ML) en Kubernetes. Proporciona un conjunto de herramientas y marcos que permiten a los científicos de datos y a los ingenieros de ML crear, entrenar e implementar fácilmente modelos de ML de forma escalable y repetible. Al aprovechar el poder de Kubernetes, Kubeflow puede administrar la infraestructura y las dependencias subyacentes, lo que facilita que los científicos e ingenieros de datos se centren en crear e implementar modelos de ML. Además, su capacidad para implementarse en cualquier clúster de Kubernetes y su arquitectura modular y extensible lo convierten en una herramienta poderosa y flexible para MLOps.
- Kubeflow es un proyecto de código abierto para administrar flujos de trabajo de aprendizaje automático en Kubernetes.
- Proporciona un conjunto de herramientas y marcos para que los científicos de datos y los ingenieros de ML creen, entrenen e implementen fácilmente modelos de ML.
- Aprovecha el poder de Kubernetes para administrar la infraestructura y las dependencias subyacentes.
Implementación de Kubeflow en un clúster de Kubernetes
Este artículo discutirá cómo implementar Kubeflow usando la CLI. Kubeflow se puede implementar en cualquier clúster de Kubernetes, ya sea en las instalaciones, en la nube o en el perímetro. Hay dos formas principales de implementar Kubeflow:
A. Interfaz de línea de comandos (CLI), o
B. La interfaz gráfica de usuario (GUI)
Administrar flujos de trabajo de ML con Kubeflow
- Kubeflow proporciona un conjunto de herramientas que buscan flujos de trabajo de ML, incluidos JupyterHub, TensorFlow Job y Katib.
- JupyterHub permite a los científicos de datos acceder y ejecutar portátiles Jupyter fácilmente
- TensorFlow Job y Katib brindan herramientas para ejecutar trabajos de capacitación distribuidos y ajuste de hiperparámetros, respectivamente.
Entrenamiento e implementación de modelos ML con Kubeflow
- Kubeflow proporciona un conjunto de herramientas para entrenar e implementar modelos ML, incluidos TensorFlow Training, TensorFlow Serving y Seldon.
- TensorFlow Training permite a los científicos de datos entrenar fácilmente modelos ML usando TensorFlow
- TensorFlow Serving y Seldon brindan herramientas para implementar modelos entrenados en producción
Canalización de Kubeflow
- Configurar un clúster de Kubernetes
- Instalar Kubeflow en el clúster
- Cree un script de Python que se usará como componente principal de la canalización
- Utilice el SDK de canalizaciones de Kubeflow para crear la canalización
- Ejecutar la canalización
- Realice un seguimiento del progreso y los resultados de las ejecuciones de canalización
¿Qué es el clúster de Kubernetes?
Un clúster de Kubernetes es como un grupo de computadoras que trabajan juntas para garantizar que sus programas funcionen sin problemas. El grupo comprende dos tipos de computadoras, el maestro y el trabajador. La computadora maestra es como el jefe y se asegura de que todo funcione como debe ser, y las computadoras de los trabajadores son como los ayudantes y hacen el trabajo real de ejecutar sus programas. Las computadoras maestra y trabajadora se comunican entre sí para garantizar que todo funcione correctamente. Kubernetes lo ayuda a ejecutar, administrar y escalar sus programas informáticos de manera fácil y eficiente, al igual que un buen jefe y un equipo de ayudantes pueden facilitar su trabajo.
- Nodos maestros
- Nodos trabajadores
- Networking
Kubernetes se puede instalar en las instalaciones, en proveedores de la nube como AWS, GCP o Azure, o mediante servicios administrados de Kubernetes como EKS, GKE y AKS.
Nodos maestros son como los líderes del grupo de computadoras en un clúster de Kubernetes. Se aseguran de que todo funcione bien y deciden qué computadora debe hacer qué trabajo. Usan herramientas especiales como el servidor API y el kube-scheduler para hacer esto. Piense en ello como los líderes de un grupo haciendo un plan y dando trabajo a los demás miembros del grupo.
Nodos trabajadores son como ayudantes en un grupo de computadoras en un clúster de Kubernetes. Hacen el trabajo real de ejecutar programas y se aseguran de que funcionen correctamente. Usan herramientas especiales como kubelet y kube-proxy para hacer esto. También hablan con los nodos maestros para informarles cómo van las cosas. Piense en ello como ayudantes en un grupo que hacen las tareas y les dicen a los líderes cómo les va.
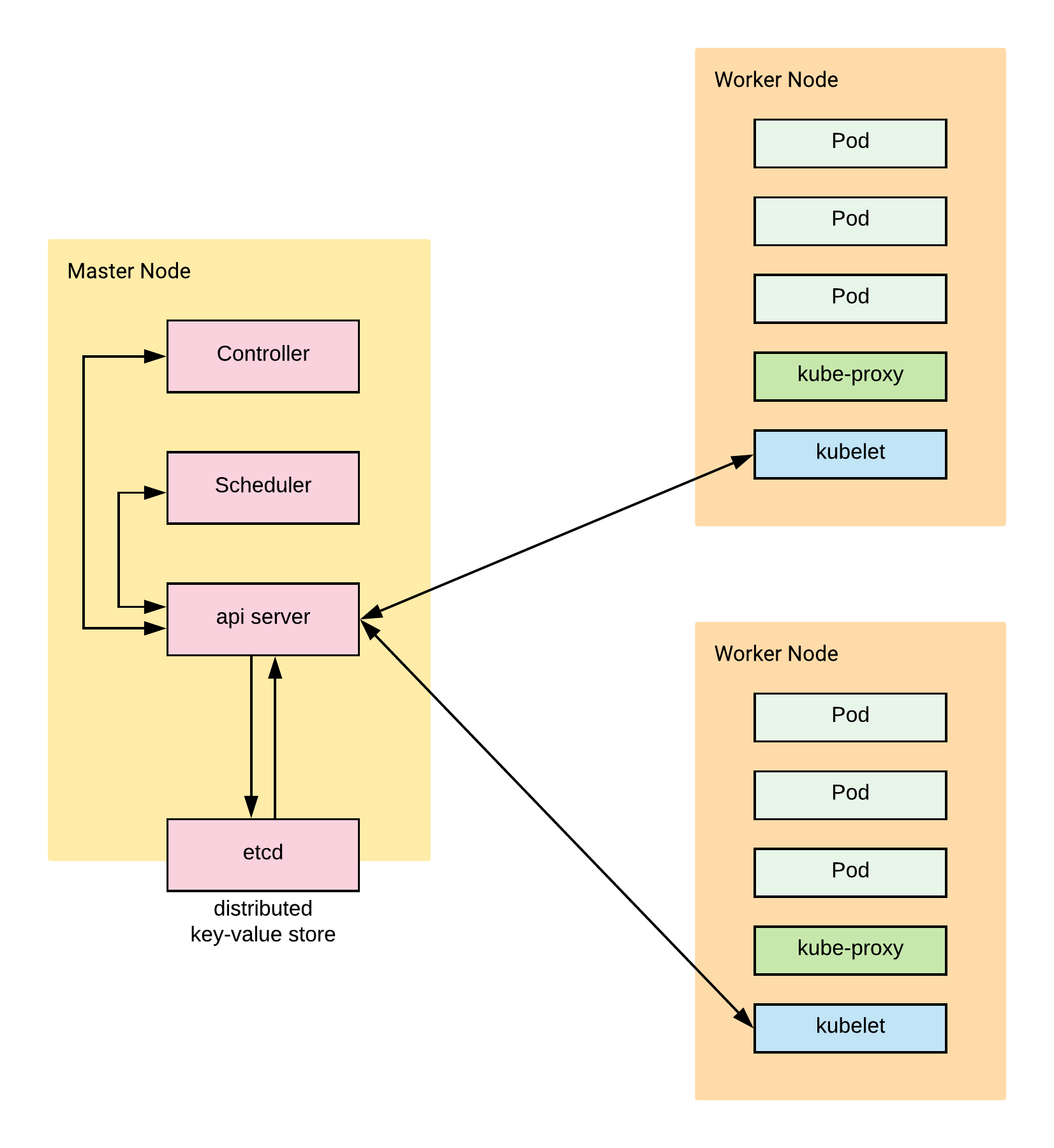
Etc. Un almacén de clave-valor distribuido utilizado por el plano de control de Kubernetes para almacenar los datos de configuración del clúster. Es como un gran cuaderno donde los líderes del grupo de computadoras en un clúster de Kubernetes mantienen información de los participantes sobre cómo se debe configurar todo. Lo usan para asegurarse de que todo funcione como debería y se comparte entre todas las computadoras del grupo, por lo que todos tienen la misma información. Piense en ello como un cuaderno compartido que todos en el grupo pueden ver y usar para asegurarse de que todos estén en la misma página.
Networking en un clúster de Kubernetes es configurar cómo los diferentes componentes del clúster se comunican entre sí, incluidos los pods, los servicios y los nodos. Los pods son las unidades implementables más pequeñas y tienen sus propias direcciones IP, y los servicios se utilizan para acceder a los pods y proporcionar un punto final estable. Se les asigna una dirección IP llamada ClusterIP a la que solo se puede acceder dentro del clúster. Para permitir la comunicación entre pods y servicios en diferentes nodos, Kubernetes utiliza un complemento de red llamado Container Network Interface (CNI), que es responsable de crear y administrar los puentes de red y las interfaces virtuales que conectan los pods y los servicios. Para la comunicación externa, Kubernetes usa Ingress, una colección de reglas que permite que el tráfico externo acceda a los servicios dentro del clúster, generalmente asociado con un servicio LoadBalancer o NodePort que proporciona un punto final estable para la comunicación externa.
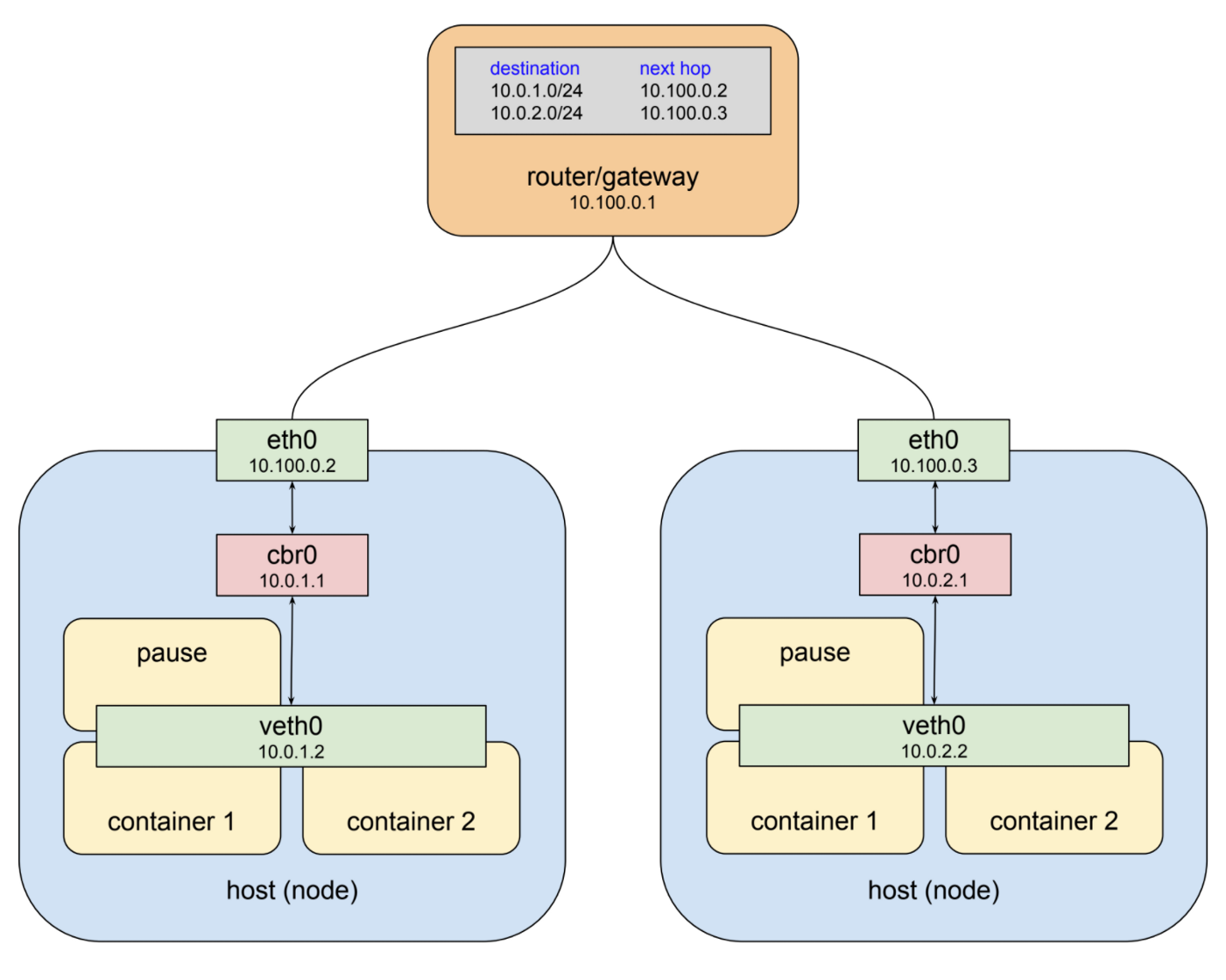
Este es un ejemplo de cómo puede configurar un clúster de Knetes con la herramienta de línea de comandos kubeadm y algunas secuencias de comandos adicionales. Este ejemplo asume que ya tiene un grupo de máquinas (VM, bare-metal, etc.) que desea usar como su clúster y que todas tienen Ubuntu 18.04 instalado.
Paso 1: instale los paquetes necesarios:
sudo apt-get update && sudo apt-get install -y apt-transport-https curlcurl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key agregar -cat
Este es un ejemplo de cómo puede configurar un clúster de Kubernetes con la herramienta de línea de comandos kubeadm y algunas secuencias de comandos adicionales. Este ejemplo asume que ya tiene un grupo de máquinas (VM, bare-metal, etc.) que desea usar como su clúster y que todas tienen Ubuntu 18.04 instalado.
Para hacer que un grupo de computadoras funcionen juntas como un clúster de Kubernetes, usamos una herramienta especial llamada kubeadm. Primero colocamos programas de computadora especiales llamados paquetes en todas las computadoras del grupo. Luego, elegimos una computadora para que sea la líder y le decimos cómo queremos que el grupo trabaje en conjunto usando kubeadm. También nos aseguramos de que todas las computadoras puedan comunicarse entre sí. curl curl le dice a todas las otras computadoras del grupo que escuchen al líder. Podemos comprobar si todo funciona bien preguntando a kubectl, otro programa informático especial.
Inicialice el clúster en el nodo principal:
sudo kubeadm init --pod-red-cidr=10.244.0.0/16
Este comando configurará el nodo maestro y creará un archivo de configuración predeterminado en /etc/kubernetes/admin.conf
En los nodos trabajadores, únase al clúster con el comando:
sudo kubeadm unirse: --token --discovery-token-ca-cert-hash sha256:
Este comando se puede encontrar en la salida del comando kubeadm init en el nodo principal.
Una vez que los nodos de trabajo se han unido al clúster, puede verificar el estado de los nodos con el comando:
kubectl obtener nodos
Debería ver los nodos maestro y trabajador en la lista.
Para usar el clúster, debe configurar kubectl para usar el archivo admin.conf que se creó en el paso 2:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernet
Paso 2: Instale Kubeflow en el clúster
Instale la herramienta de línea de comandos kfctl, que es una utilidad de línea de comandos utilizada para implementar y administrar Kubeflow; puede descargar la última versión usando este comando:
curl -LO https://github.com/kubeflow/kfctl/releases/download/v1.3.0/kfctl_v1.3.0_linux.tar.gz
Extraiga el archivo tar descargado
tar xzf kfctl_v1.3.0_linux.tar.gz
Un directorio para su configuración de Kubeflow:
mkdir kubeflow-configcd kubeflow-config
Descargue el archivo de configuración de Kubeflow. Al usar este comando, podrá descargar el archivo de configuración de kubeflow
curl -O https://raw.githubusercontent.com/kubeflow/kubeflow/v1.3-branch/bootstrap/config/kfctl_k8s_istio.v1.3.0.yaml
Utilice la herramienta de línea de comandos kfctl para instalar Kubeflow:
./kKubernetesly -V -f kfctl_k8s_istio.v1.3.0.yaml
Este comando implementará los componentes de Kubeflow en el clúster; puede verificar el estado de la implementación ejecutando kubectl get pods -n kubeflow
Una vez que todos los pods se están ejecutando y en estado En ejecución, puede acceder a la interfaz de usuario de Kubeflow ejecutando el panel de kubeflow
Nota: Los comandos y ejemplos de código proporcionados deben ejecutarse en una ventana de terminal o símbolo del sistema, que es una interfaz de línea de comandos que le permite interactuar con el sistema operativo. Puede abrir una terminal presionando la combinación de teclas Ctrl + Alt + T o buscando "terminal" en el menú de aplicaciones. Una vez que la terminal está abierta, puede escribir los comandos y presionar la tecla Intro para ejecutarlos. Se recomienda usar una aplicación de terminal como ssh para conectarse a cada máquina, ya que le permite ejecutar comandos en máquinas remotas como si estuviera sentado frente a ellas. Tenga en cuenta que estos comandos realizarán cambios en el sistema y pueden requerir acceso de superusuario o raíz, por lo que es importante ejecutarlos con los permisos adecuados, comenzando con el nodo maestro en cada máquina del clúster.
Paso 3: cree una secuencia de comandos de Python que se usará como el componente principal de la canalización
!pip instalar kfp
importar kfp de kfp importar GME@dhr-rgv.com( name='My Pipeline', description='Una canalización simple que realiza el preprocesamiento de datos y el entrenamiento del modelo')def my_pipeline( input_data: str, output_data: str, model_path: str): preprocessing = dsl.ContainerOp( name='preprocessing' , image='python:3.8', command=['python', 'preprocessing.py'], arguments=[ input_data, output_data ] ) formación = dsl.ContainerOp( nombre='formación', imagen='python:3.8' , command=['python', 'training.py'], arguments=[ output_data, model_path ] ) training.after(preprocessing)if __name__ == '__main__': kfp.compiler.Compiler().compile(my_pipeline, ' mi_tubería.tar.gz')
Paso 4: utilice el SDK de canalizaciones de Kubeflow para crear la canalización
El ejemplo de cómo utilizar el SDK de Pipelines de Kubeflow para crear el pipeline definido en el ejemplo anterior:
SDK de Python
importar cliente kfp = kfp.Cliente()
Compile el compilador DSL de canalización
pipeline_func = my_pipeline pipeline_filename = 'my_pipeline.py' compiler = kfp.compiler.Compiler() compiler.compile(pipeline_func, pipeline_filename)
Crear la canalización en Kubeflow
experiment_name = 'Mi experimento' run_name = 'Mi ejecución' arguments = {'input_data':'gs://my-bucket/input/', 'output_data':'gs://my-bucket/output/', ' model_path':'gs://my-bucket/models/'}
"experiment_name" es como darle un nombre a su proyecto, como "Mi proyecto de ciencia". "run_name" es como dar un nombre a un momento específico en el que hiciste tu proyecto, como "Mi proyecto de ciencia: primer intento". "argumentos" es como una lista de cosas que necesita para su proyecto, como los materiales que necesita para un experimento científico, como "input_data", "output_data" y "model_path" son como diferentes tipos de materiales que necesita para el proyecto y donde puedes encontrarlos. Por ejemplo, "input_data" es como las cosas que necesita para comenzar su proyecto, "output_data" es como las cosas que hace mientras hace su proyecto, y "model_path" es como las instrucciones que necesita seguir para hacer su proyecto.
Paso 5: envíe una ejecución de canalización
run_result = client.create_run_from_pipeline_func(pipeline_func,
nombre_experimento=nombre_experimento, nombre_ejecución=nombre_ejecución, argumentos=argumentos)
En este ejemplo, la canalización se compila primero con la clase kfp.compiler.Compiler() y se guarda en el archivo 'my_pipeline.py'. Luego, se crea una instancia de la clase kfp.Client() y se usa para crear la canalización en Kubeflow llamando al método create_run_from_pipeline_func. El método toma la función de canalización, el nombre del experimento, el nombre de la ejecución y un diccionario de argumentos que se pasarán a la canalización. Después de enviar la ejecución de la canalización, la canalización se ejecutará y los resultados de la ejecución se pueden ver en la interfaz de usuario de Kubeflow Pipelines.

Nota: El primer ejemplo de código define la canalización mediante el SDK de KFP, mientras que el segundo ejemplo de código utiliza el SDK de KFP para crear y ejecutar la canalización en Kubeflow. El primer script se enfoca en la estructura de la canalización, los pasos y las entradas/salidas, mientras que el segundo script se enfoca en la interacción con el servicio Kubeflow para crear, compilar y ejecutar la canalización.
Con el conocimiento que hemos adquirido sobre las canalizaciones de Kubeflow, ahora estamos listos para crear nuestra primera canalización utilizando el conjunto de datos de Iris.
de kfp importar dsl de sklearn importar conjuntos de datos de sklearn.model_selection importar train_test_split de sklearn.metrics importar precision_score de sklearn.svm importar SVC
Esta canalización utiliza el conjunto de datos de Iris y entrena un clasificador de vectores de soporte (SVC) modelo con un núcleo específico y una tasa de aprendizaje. Luego evalúa la precisión del modelo en un conjunto de prueba e imprime la puntuación de precisión.
Ejecute la canalización mediante el SDK de canalizaciones de Kubeflow
from kfp import Client client = Client() EXPERIMENT_NAME = 'Clasificación de iris' run_result = client.create_run_from_pipeline_func(iris_classification_pipeline_func, experiment_name=EXPERIMENT_NAME)
Paso 6: Realice un seguimiento del progreso y los resultados de las ejecuciones de canalización
- Ahora que tenemos una idea clara de cómo crear una canalización de Kubeflow con el conjunto de datos de Iris, podemos comenzar a realizar un seguimiento del progreso y los resultados de nuestras ejecuciones de canalización.
- Esto se puede hacer monitoreando el estado de la canalización, viendo los resultados de cada paso de la canalización y analizando los resultados de la ejecución de la canalización como un todo.
- Esto nos permite asegurarnos de que la canalización funcione sin problemas, identificar cualquier problema que pueda surgir y realizar los ajustes necesarios para mejorar el rendimiento de la canalización.
Además, podemos utilizar esta información para evaluar la eficacia de nuestros modelos de aprendizaje automático y optimizar su rendimiento.
Evaluación del modelo
Para evaluar el rendimiento de un modelo dentro de una canalización de Kubeflow, puede utilizar el componente "Evaluador". Este componente toma el modelo entrenado y un conjunto de datos y genera métricas como exactitud, precisión, recuperación y puntaje F1. Para utilizar el componente Evaluador.
-
- modelo_entrenado: el modelo entrenado que desea evaluar
-
- test_data: el conjunto de datos que desea utilizar para la evaluación
- Salidas:
-
- Métricas: las métricas de evaluación
-
- parámetros:
-
- metric_names: los nombres de las métricas que desea calcular (por ejemplo, "exactitud", "precisión", "recuperación")
desde el evaluador de componentes de importación de kfp = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/v0.5.1/components/evaluator/component.yaml') @dsl.pipeline( name='Canalización de clasificación de iris' , description='Una tubería para entrenar y evaluar un modelo en el conjunto de datos de Iris' ) def iris_classification_pipeline(): #define los pasos de la tubería aquí... eval_results = evaluador(trained_model=train_step.outputs['model'], test_data=load_data_step. outputs['data'], metric_names=['accuracy', 'precision', 'recall', 'f1_score'] ).outputs['metrics'] ...
En este ejemplo, el componente evaluador toma la salida del componente train_step, que es el modelo entrenado, y la salida del componente load_data_step, que es la salida del componente evaluador es un diccionario de métricas, al que se puede acceder a través de las métricas llave.
Ahora podemos agregar un nuevo componente llamado 'evaluate_step' después del componente 'train_step' en nuestra canalización. Este componente tomará la salida del componente 'train_step', que es el modelo entrenado, y la salida del componente 'load_data_step', que es el conjunto de datos de prueba.
En el componente 'evaluate_step', haremos lo siguiente:
- Utilice la biblioteca de aprendizaje de sci-kit para crear un matriz de confusión
- Usando el modelo entrenado y el conjunto de datos de prueba,
- dándonos una representación visual del número de predicciones correctas e incorrectas hechas por el modelo.
- El Curva ROC nos ayudará a evaluar el desempeño del modelo trazando la tasa positiva verdadera contra la falsos positivos tarifa.
from sklearn.metrics import confusion_matrix, roc_curve from sklearn.metrics import auc def evaluar_paso(modelo, datos_de_prueba): # hacer predicciones sobre los datos de prueba test_predictions = model.predict(test_data.data) # crear matriz de confusión confusion_mat = confusion_matrix(test_data.target, test_predictions) print("Confusion Matrix:",confusion_mat) # calcula la tasa de verdaderos positivos y la tasa de falsos positivos fpr, tpr, umbrales = roc_curve(test_data.target, test_predictions) roc_auc = auc(fpr, tpr) return {"fpr": fpr , "tpr": tpr, "roc_auc": roc_auc}
Este componente le dará un diccionario con FPR, tpr y roc_auc, que puede utilizar para trazar el curva ROC.
Implementación de modelos y ajuste de hiperparámetros en la canalización
# definir canalización y pasos de canalización @dsl.pipeline(name="Iris pipeline") def kfpipeline(): # entrenar con hiperparámetros train = mlrun.import_function('hub://sklearn_classifier').as_step( name="train ", parama s={"sample": -1, "label_column": y, "test_size": 0.10, 'model_pkg_class': "sklearthe n.ensemble.RandomForestClassifier", 'n_estimators': 10, # hiperparámetro agregado 'max_ depth' : 3, # hiperparámetro agregado 'random_state': 42}, # hiperparámetro agregado input={"dataset" : X}, outputs=['model', 'test_set']) # implementar nuestro modelo como una función sin servidor, podemos pasar una lista de modelos para servir deployment = mlrun.import_function('hub://v2_model_server').deploy_step( models=[{"key": "iris_model:v1", "model_path": train.outputs['model']} ]) # probar el nuevo servidor modelo (a través de llamadas API REST) tester = mlrun.import_function('hub://v2_model_tester').as_step( name='model-tester', params={'addr': deployment.outputs[ 'punto final'], 'modelo': "iris_model:v1"}, entradas={'tabla': tren.salidas['conjunto_prueba']})
En este ejemplo, he añadido hiperparámetros para el clasificador de bosque aleatorio, como n_estimators, max_ depth y random_state, y establezca valores para ellos.
Además, cambié label_column a y, que es la variable de destino del conjunto de datos de Iris, y la entrada del conjunto de datos a X, que es la variable característica del conjunto de datos Iris. Además, he cambiado el nombre del modelo a iris_model:v1.
Kubeflow se puede configurar usando el GUI (que solo es compatible con Google Cloud) o CLI. Si solo quiere experimentar con Kubeflow, le aconsejo usar la GUI, si desea realizar una implementación permanente real, use el CLI.
CLI
- CLI proporciona una interfaz basada en texto para interactuar con una computadora o aplicación de software
- Permite a los usuarios ingresar comandos y recibir resultados a través de un indicador de línea de comandos.
- CLI se usa comúnmente en tareas de administración, programación y automatización del sistema
- Algunos ejemplos de CLI incluyen el símbolo del sistema de Windows, la terminal de Linux y la terminal de MacOS.

Elegí la implementación de la CLI porque la implementación de la GUI omitió algunos elementos. Inicialmente, se usaron computadoras ordinarias en el despliegue, aunque tenía la intención de operar todo el entorno con preferenciales. Los preventivos son máquinas con un tiempo de desactivación de 24 horas que es un 20 % más económico que las instancias normales.
La compatibilidad con dispositivos alimentados por GPU era otra inclusión que realmente deseaba (y sí, adivinó correctamente, también es preferencial porque me encantan nuestras cosas baratas).
Conclusión
Kubeflow es una poderosa herramienta para administrar flujos de trabajo de aprendizaje automático en Kubernetes. Kubeflow es un proyecto de código abierto que simplifica la implementación y la gestión de flujos de trabajo de aprendizaje automático en Kubernetes. Proporciona un conjunto de herramientas y marcos que permiten a los científicos de datos y a los ingenieros de IL crear, entrenar e implementar fácilmente modelos de ML de forma escalable y repetible.
Además, los casos de uso de Kubeflow no se limitan a industrias específicas y se pueden aplicar en varios campos, como la atención médica y las finanzas, donde la escalabilidad, la confiabilidad y la seguridad son cruciales. La naturaleza impulsada por la comunidad del proyecto garantiza que esté en constante evolución y mejora, con nuevas funciones y correcciones de errores que se agregan regularmente.
Al seguir los pasos descritos en este artículo, ahora debería comprender mejor cómo usar Kubeflow para administrar sus proyectos de ML y poder aplicar los conceptos a sus propios proyectos.
Puntos clave:
- Kubeflow es una herramienta de código abierto para automatizar y administrar flujos de trabajo de aprendizaje automático en Kubernetes.
- Proporciona un conjunto de herramientas y marcos para que los científicos de datos y los ingenieros de ML creen, entrenen e implementen fácilmente modelos de ML.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/01/kubeflow-streamlining-mlops-with-efficient-ml-workflow-management/

