
Ruth Bader Ginsburg sobre la dificultad de llegar al sesgo inconsciente en nuestros tribunales (1)
El Notorious RBG tiene razón. Es difícil llegar al sesgo inconsciente en nuestro sistema legal. Sin embargo, a diferencia de la corte suprema, los científicos de datos tenemos nuevos conjuntos de herramientas de código abierto que facilitan la auditoría de nuestros modelos de aprendizaje automático en busca de sesgo y equidad. Si Waylan Jennings y Willie Nelson tuvieran que hacerlo de nuevo hoy, me gustaría pensar que su famoso dúo sería algo más como esto:
♪Mamas, no dejen que sus bebés crezcan para ser jueces de la Corte Suprema♪
♪Que sean analistas y científicos de datos y demás♪
♪No hay biblioteca de Python para hacer la ley más justa♪
♪Así que es más fácil ser un científico de datos que un juez♪ (2)
La Aequitas Fairness and Bias Toolkit (3) es un ejemplo de una de estas bibliotecas de Python. Decidí probarlo usando uno de los conjuntos de datos más populares disponibles. Probablemente ya estés familiarizado con el Titanic datos utilizados en el tutorial para principiantes de Kaggle. Este desafío consiste en predecir la supervivencia de los pasajeros en el Titanic. Construí un modelo de Clasificador de Bosque Aleatorio sencillo utilizando estos datos y lo introduje en el kit de herramientas de Aequitas.
Después de solo nueve líneas adicionales de código, estaba listo para ver si mi modelo inicial era justo para los niños. Me sorprendieron los resultados. Mi modelo inicial odia a los niños. Es razonablemente preciso cuando se predice que un adulto sobrevivirá. Pero es 2.9 veces más probable que se equivoque al predecir que un niño sobrevivirá. En el lenguaje estadístico de la ciencia de datos, la tasa de falsos positivos es 2.9 veces mayor para los niños que para los adultos. Es una disparidad significativa en la equidad. Peor aún mi modelo inicial también pone en desventaja a las mujeres y los pasajeros de la clase socioeconómica más baja al predecir la supervivencia.

El artículo en pocas palabras
¿Sabes si tus modelos de ML son justos? ¡Si no lo haces, deberías! Este artículo demostrará cómo auditar fácilmente la equidad de cualquier modelo de aprendizaje supervisado utilizando el kit de herramientas de código abierto Aequitas. También comentaremos sobre la tarea mucho más difícil de mejorar la equidad en su modelo.
Este proyecto está codificado en Python utilizando Google Colaboratory. El código base completo está disponible en mi Titanic-Justicia página de GitHub. Aquí está el flujo de trabajo a un alto nivel:
Flujo de trabajo de análisis
Empecemos por el final. Una vez que se completa el trabajo de construcción de un modelo, tenemos todo lo que necesitamos para formatear el marco de datos de entrada para el kit de herramientas Aequitas. Se requiere que el marco de datos de entrada contenga columnas etiquetadas como 'puntuación' y 'valor_de_etiqueta', así como al menos un atributo con el que medir la equidad. Aquí está la tabla de entrada para nuestro modelo Random Forest después de formatear.
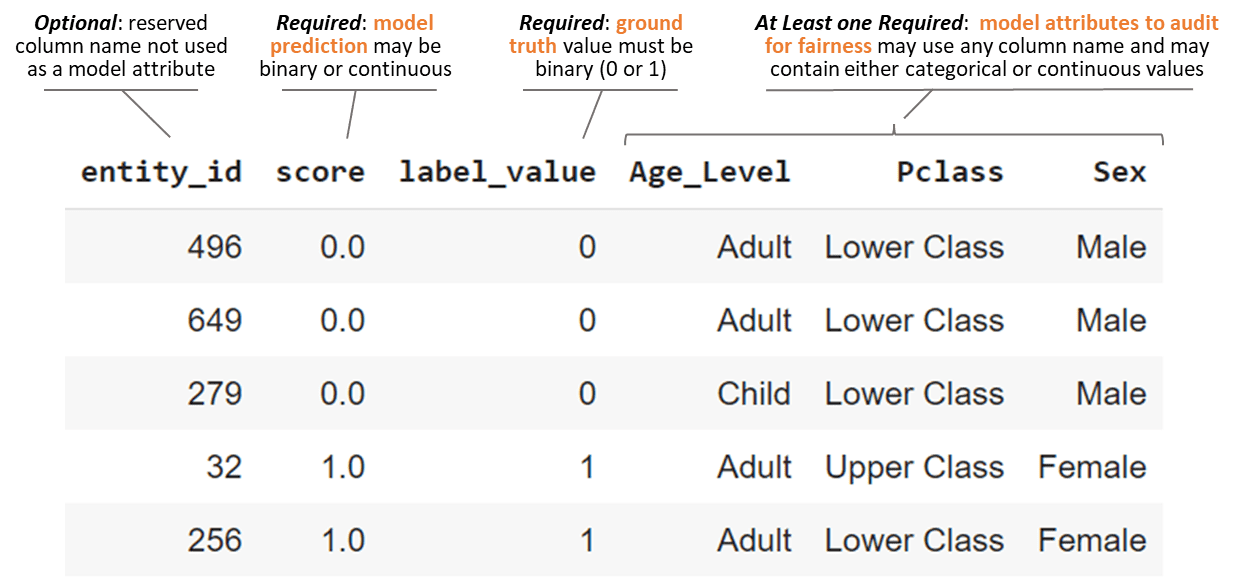
Modelo inicial de Titanic Survival ML formateado como datos de entrada de Aequitas
Las predicciones para nuestro modelo en la columna de 'puntuación' son binarias como 1 para supervivencia o 0 para no. Los valores de 'puntaje' también pueden ser una probabilidad entre 0 y 1 como en un modelo de regresión logística. En este caso, los umbrales deben definirse como se describe en el configuración documentación.
Usamos 'edad' del conjunto de datos original para diseñar un atributo categórico que separa a cada pasajero como 'Adulto' o 'Niño'. Aequitas también aceptará datos continuos. Si proporcionamos 'edad' como una variable continua, tal como existe en el conjunto de datos original, entonces Aequitas la transformará automáticamente en cuatro categorías basadas en cuartiles.
Definir la equidad es difícil. Hay muchas medidas de sesgo y equidad. Además, la perspectiva a menudo varía según el subgrupo del que provenga. ¿Cómo decidimos qué nos importa? El equipo de Aequitas proporciona un árbol de decisión imparcial eso puede ayudar Se basa en la comprensión del impacto asistencial o punitivo de las intervenciones asociadas. Fairlearn es otro conjunto de herramientas. La documentación de Fairlearn proporciona un excelente marco para realizar una evaluación de la equidad.
La equidad depende de los detalles del caso de uso. Por lo tanto, tendremos que definir un caso de uso artificial para el conjunto de datos de Kaggle Titanic. Para hacer eso, suspenda la realidad, retroceda en el tiempo e imagine que después del naufragio del Atlántico en 1873, la República en 1909 y el Titanic en 1912, White Star Line ha consultado con nosotros. Vamos a construir un modelo para predecir la supervivencia en caso de otra gran catástrofe en el mar. Proporcionaremos una predicción para cada posible pasajero del HMHS británico, la tercera y última clase olímpica de barcos de vapor de la compañía.

Postal británica de 1914 (4)
Pensando en nuestro ejemplo de caso artificial, nuestro modelo es punitivo cuando predecimos incorrectamente la supervivencia de un posible pasajero. Podrían estar muy confiados en caso de que el Britannic tenga un percance en el mar. Este tipo de error del modelo es un falso positivo.
Ahora consideremos la demografía de nuestros pasajeros. Nuestro conjunto de datos incluye etiquetas por sexo, edad y clase socioeconómica. Evaluaremos la equidad de cada grupo. Pero empecemos con los niños como nuestro principal objetivo de justicia.
Ahora necesitamos traducir nuestro objetivo en términos que sean compatibles con Aequitas. Podemos definir el objetivo de equidad de nuestro modelo como minimizar la disparidad en la tasa de falsos positivos (fpr) de niños versus adultos (grupo de referencia). La disparidad es simplemente la relación entre la tasa de falsos positivos de los niños y la del grupo de referencia. También definiremos una política de tolerancia de que la disparidad entre grupos no puede ser superior al 30 %.
Finalmente terminamos por el principio. Para comenzar nuestra auditoría, necesitamos instalar Aequitas, importar las bibliotecas necesarias e inicializar las clases de Aequitas. Aquí está el código de Python para hacer eso:

Instalar Aequitas e Inicializar
La clase Group( ) se utiliza para realizar cálculos de matriz de confusión y métricas relacionadas para cada subgrupo. Cosas como recuento de falsos positivos, recuento de verdaderos positivos, tamaño del grupo, etc. para cada subgrupo de niños, adultos, mujeres, etc. Y la clase Bias() se utiliza para realizar cálculos de disparidad entre grupos. Por ejemplo, la relación entre la tasa de falsos positivos para niños y la tasa de falsos positivos del grupo de referencia (adultos).
A continuación, especificamos que queremos auditar el atributo 'Age_Level' y usar 'Adult' como grupo de referencia. Este es un diccionario de Python y puede incluir más de una sola entrada.

Especifique 'Age_Level' como el atributo para evaluar la imparcialidad
Las dos últimas cosas a especificar son las métricas que deseamos visualizar y nuestra tolerancia a la disparidad. Estamos interesados en las tasas de falsos positivos (fpr). La tolerancia se utiliza como referencia en la visualización.

Especificar métricas de imparcialidad y tolerancia
Ahora llamamos al método get_crosstabs( ) utilizando nuestro marco de datos de entrada previamente formateado (dfAequitas) y configurando las columnas de atributos en la lista de atributos_para_auditar que definimos. La segunda línea crea nuestro marco de datos de sesgo (bdf) utilizando el método get_disparity_predefined_groups(). Y la tercera línea traza las métricas de disparidad utilizando el gráfico Aequitas (ap).

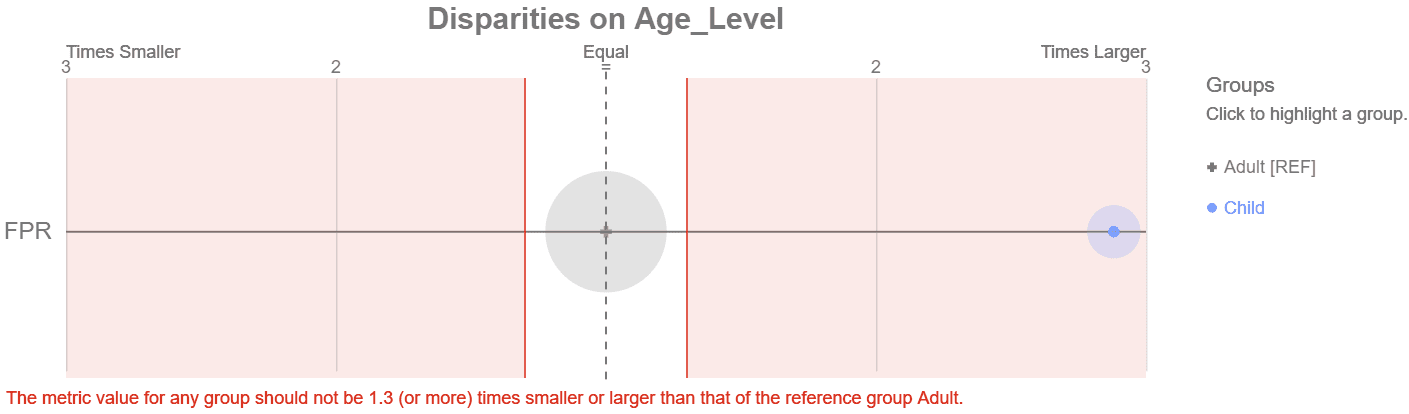
Visualización de disparidad de Aequitas con desplazamiento del cursor
Inmediatamente vemos que el subgrupo de niños está en números rojos, fuera de nuestro 30 % de tolerancia a la disparidad. Con seis líneas de código para instalación/configuración y tres más para crear la trama, tenemos una visualización clara de cómo funciona nuestro modelo frente a nuestro objetivo de equidad. Al hacer clic en el grupo, se revela que hay 36 niños en los datos de la prueba con una tasa de falsos positivos (fpr) del 17 %. Esto es 2.88 veces mayor que el grupo de referencia. La ventana emergente para el grupo de referencia revela 187 adultos con una tasa de falsos positivos del 6 %.
Mejorar la equidad del modelo puede ser significativamente más desafiante que identificarlo. Pero hay una cantidad creciente de investigaciones serias sobre este tema. A continuación se muestra una tabla, adaptada de la documentación de Aequitas, que resume cómo mejorar la equidad del modelo.

Adaptado de Aequitas Documentation (5,6)
Cuando se trabaja para mejorar los datos de entrada, un error común es pensar que un modelo no puede estar sesgado si ni siquiera tiene datos sobre edad, raza, sexo u otros datos demográficos. Esto es una falacia. 'No hay equidad a través de la inconsciencia. Un modelo ciego demográfico puede discriminar.' (7) NO elimine atributos sensibles de su modelo sin considerar el impacto. Esto impedirá la capacidad de auditar la equidad y puede empeorar el sesgo.
Hay kits de herramientas disponibles que pueden ayudar a mitigar el sesgo en los modelos de ML. Dos de los más destacados son IA Fairness 360 por IBM y Aprendizaje justo por Microsoft Estos son kits de herramientas de código abierto robustos y bien documentados. Cuando lo use, tenga en cuenta las compensaciones resultantes con el rendimiento del modelo.
Para nuestro ejemplo, mitigaremos el sesgo con la tercera viñeta mediante el uso de métricas de equidad en la selección de nuestro modelo. Así que construimos algunos modelos de clasificación más en nuestra búsqueda de equidad. La siguiente tabla resume nuestras métricas para cada modelo candidato. Recuerde que nuestro modelo inicial es la Clasificación aleatoria de bosques.

Modelo de clasificación Métricas de equidad para niños en comparación con adultos
Y aquí está el diagrama de Aequitas para el modelo XGBoost de umbral del 30 % resaltado que cumple con nuestro objetivo de equidad.
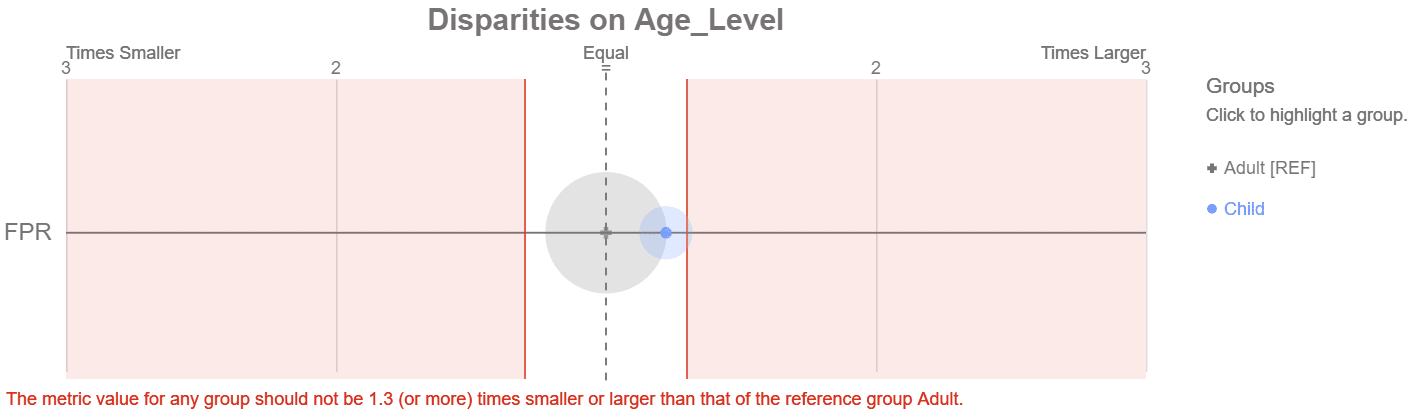
XGBoost con un umbral del 30 % cumple con nuestro objetivo de equidad
¿Éxito? El grupo de niños está fuera del área sombreada en rojo. ¿Pero es este realmente el mejor modelo? Comparemos los dos modelos XGBoost. Ambos modelos predicen una probabilidad continua de supervivencia de 0 a 100%. A continuación, se utiliza un valor de umbral para convertir la probabilidad en una salida binaria de 1 para supervivencia o 0 para no. El valor predeterminado es 50%. Cuando bajamos el umbral al 30%, el modelo predice que sobrevivirán más pasajeros. Por ejemplo, un pasajero con un 35 % de probabilidad alcanza el nuevo umbral y la predicción ahora es 'supervivencia'. Esto también crea más errores de falsos positivos. En nuestros datos de prueba, mover el umbral al 30% agrega 13 falsos positivos más al grupo de referencia más grande que contiene adultos y solo 1 falso positivo más al grupo de niños. Esto los acerca a la paridad.
Por lo tanto, el modelo XGBoost del 30 % cumple con nuestro objetivo de equidad de una manera que no es preferible. En lugar de elevar el rendimiento del modelo para nuestro grupo protegido, bajamos el rendimiento del grupo de referencia para lograr la paridad dentro de nuestra tolerancia. Esta no es una solución deseable, pero es representativa de las difíciles compensaciones en un caso de uso del mundo real.
El gráfico de tolerancia de disparidad es solo un ejemplo de las visualizaciones integradas de Aequitas. Esta sección demostrará otras opciones. Todos los siguientes datos están asociados con nuestro modelo Random Forest inicial. El código para producir cada uno de los ejemplos también está incluido en mi Titanic-Justicia Página de GitHub.
El primer ejemplo es un diagrama de árbol de disparidad en las tasas de falsos positivos en todos los atributos.
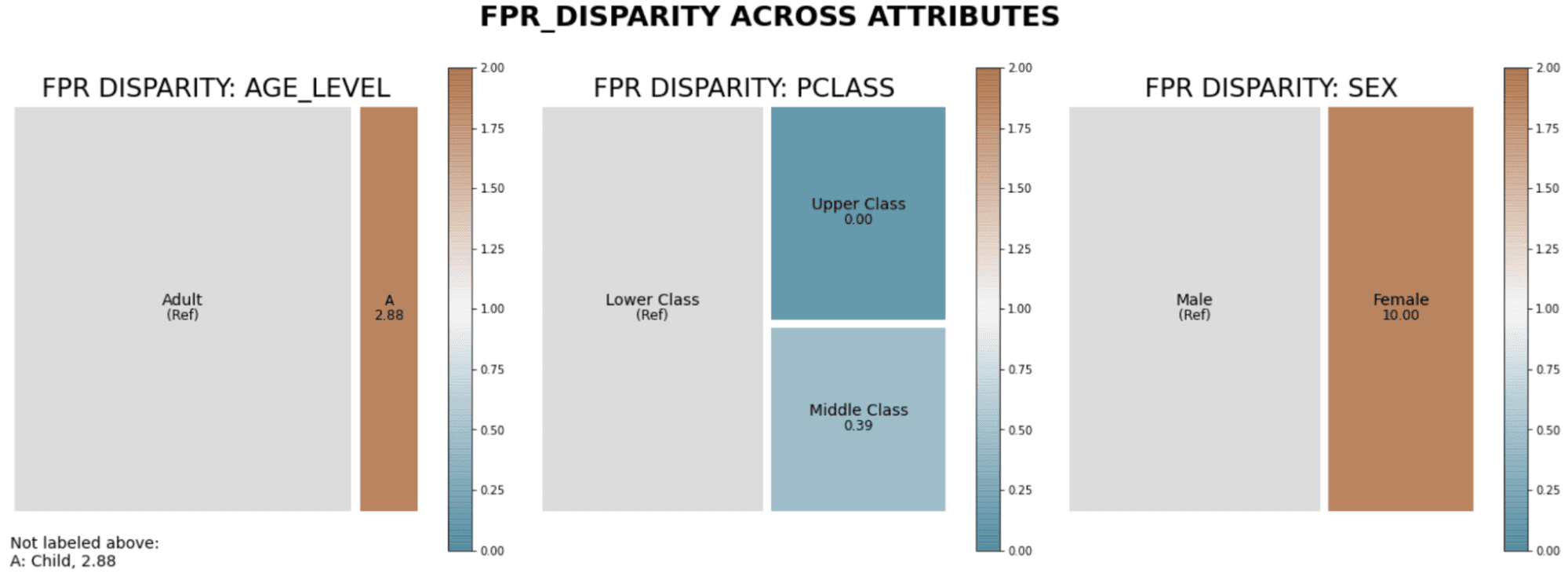
Diagrama de árbol de la disparidad en las tasas de falsos positivos en todos los atributos
El tamaño relativo de cada grupo lo proporciona el área. Cuanto más oscuro es el color, mayor es la disparidad. Marrón significa una tasa de falsos positivos más alta que la referencia y verde azulado significa más baja. El grupo de referencia se selecciona automáticamente como el grupo con mayor población. Entonces, el gráfico anterior, de izquierda a derecha, se interpreta como:
- Los niños tienen una tasa de falsos positivos mucho más alta que los adultos,
- Los pasajeros de clase alta tienen una tasa de falsos positivos mucho más baja que la clase baja, y
- Las mujeres tienen una tasa de falsos positivos mucho más alta que los hombres.
De manera más concisa, el diagrama de árbol indica que nuestro modelo inicial es injusto para los niños, los pasajeros de clase baja y las mujeres. El siguiente gráfico muestra información similar a la de un gráfico de barras más tradicional. Pero en este ejemplo vemos la tasa absoluta de falsos positivos en lugar de la disparidad (o proporción) con el grupo de referencia.
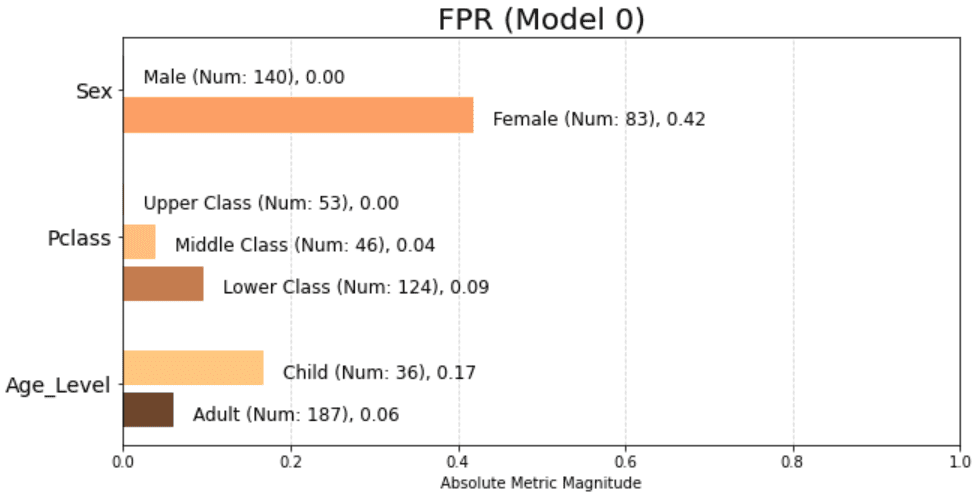
Gráfico de barras de tasas de falsos positivos como valores absolutos en todos los atributos
Este gráfico de barras señala un gran problema con las mujeres que tienen una tasa de falsos positivos del 42 %. Podemos producir gráficos de barras similares para cualquiera de las siguientes métricas:
- Disparidad de tasa de grupo positiva pronosticada (pprev),
- Disparidad de tasa positiva pronosticada (ppr),
- Tasa de descubrimiento falso (fdr),
- Tasa de omisión falsa (para),
- Tasa de falsos positivos (fpr), y
- Tasa de falsos negativos (fnr).
Y finalmente, también hay métodos para imprimir los datos sin procesar utilizados en los gráficos. A continuación se muestra un ejemplo de los recuentos básicos para cada grupo del modelo Random Forest inicial.

Tabla de recuentos brutos para matriz de confusión por grupo
Como se destacó anteriormente, hay 3 niños calificados como falsos positivos de un total de 18 que se predijo que sobrevivirían. 3 dividido por 18 nos da una tasa de falsos positivos del 17%. La siguiente tabla proporciona estas métricas como porcentajes. En la siguiente tabla, observe que la tasa de falsos positivos resaltada para los niños es del 17 %, como se esperaba.

Tabla de matriz de confusión expresada como porcentajes por grupo
La relación entre la tasa de falsos positivos de niños y adultos es de 2.88, calculada a partir de los puntos destacados anteriores como 0.167 dividido por 0.0579. Esta es la disparidad de los niños en relación con el grupo de referencia. Aequitas proporciona un método para imprimir directamente todos los valores de disparidad.

Tabla de recuentos brutos para matriz de confusión por grupo
La importancia de la equidad en el aprendizaje automático es evidente cuando trabajamos en políticas públicas o toma de decisiones crediticias. Incluso si no trabaja en estas áreas, tiene sentido incorporar una auditoría de equidad en su flujo de trabajo de aprendizaje automático base. Por ejemplo, puede ser útil saber si sus modelos son desventajosos para sus clientes más grandes, más rentables o más antiguos. Las auditorías de imparcialidad son fáciles de hacer y proporcionarán información sobre las áreas en las que su modelo se desempeña tanto por encima como por debajo.
Un último consejo: las auditorías de equidad también deben incorporarse a los esfuerzos de diligencia debida. Si adquiere una empresa con modelos de aprendizaje automático, realice una auditoría de equidad. Todo lo que se requiere son datos de prueba con las predicciones y etiquetas de atributos de esos modelos. Esto ayuda a comprender el riesgo de que los modelos discriminen a un grupo en particular, lo que podría generar problemas legales o daños a la reputación.
Referencia
- Parodia de la letra de la canción original de Waylon Jennings y Willie Nelson
- Imagen de postal británica del sitio de dominio público wikimedia publicada originalmente en ibiblio.org por Frederic Logghe. Enlace: https://commons.wikimedia.org/wiki/File:Britannic_postcard.jpg
- Pedro Saleiro, Benedict Kuester, Loren Hinkson, Jesse London, Abby Stevens, Ari Anisfeld, Kit T. Rodolfa, Rayid Ghani, 'Aequitas: A Bias and Fairness Audit Toolkit' Enlace: https://arxiv.org/abs/1811.05577
- Imagen de postal británica del sitio de dominio público wikimedia publicada originalmente en ibiblio.org por Frederic Logghe. Enlace: https://commons.wikimedia.org/wiki/File:Britannic_postcard.jpg
- Muhammad Bilal Zafar, Isabel Valera, Manuel Gómez Rodríguez, Krishna P. Gummadi, 'Restricciones de equidad: mecanismos para una clasificación equitativa' Enlace: http://proceedings.mlr.press/v54/zafar17a/zafar17a.pdf
- Hardt, Moritz y Price, Eric y Srebro, Nathan, 'Igualdad de oportunidades en el aprendizaje supervisado' Enlace: https://arxiv.org/abs/1610.02413
- Rayid Ghani, Kit T Rodolfa, Pedro Saleiro, 'Lidiando con el sesgo y la equidad en AI/ML/Data Science Systems' Diapositiva 65. Enlace: https://dssg.github.io/aequitas/examples/compas_demo.html#Putting-Aequitas-to-the-task
matt semrad es líder en análisis con más de 20 años de experiencia en el desarrollo de capacidades organizacionales en empresas de tecnología de alto crecimiento.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/01/fast-effective-way-audit-ml-fairness.html?utm_source=rss&utm_medium=rss&utm_campaign=the-fast-and-effective-way-to-audit-ml-for-fairness

