Los grandes modelos de lenguaje (o LLM) se han convertido en un tema de conversación diaria. Su rápida adopción es evidente por la cantidad de tiempo necesaria para llegar a 100 millones de usuarios, que ha pasado de "4.5 años por Facebook" a un mínimo histórico de apenas "2 meses por ChatGPT". Un transformador generativo preentrenado (GPT) utiliza actualizaciones autorregresivas causales para hacer predicciones. Estas arquitecturas modelo demuestran que una variedad de tareas, como el reconocimiento de voz, la generación de texto y la respuesta a preguntas, tienen un rendimiento estupendo. Varios modelos recientes como NeoX, halcón, Llama Utilice la arquitectura GPT como columna vertebral. La formación de LLM requiere una cantidad colosal de tiempo de cálculo, que cuesta millones de dólares. En esta publicación, resumiremos el procedimiento de capacitación de GPT. NeoX on tren de AWS, un acelerador de aprendizaje automático (ML) especialmente diseñado y optimizado para la capacitación en aprendizaje profundo. Describiremos cómo entrenamos dichos modelos de manera rentable (3.2 millones de tokens/$) con AWS Trainium sin perder la calidad del modelo.
Resumen de la solución
Modelos GPT NeoX y Pythia
GPT NeoX y pitia son los modelos de lenguaje causal de código abierto de Eleuther-AI con aproximadamente 20 mil millones de parámetros en NeoX y 6.9 mil millones en Pythia. Ambos son modelos de decodificadores que siguen un diseño arquitectónico similar al Chat GPT3. Sin embargo, también tienen varias adiciones, que también son ampliamente adoptadas en modelos recientes como Llama. En particular, tienen incrustación posicional rotacional (ROPE) con rotación parcial a lo largo de las dimensiones de la cabeza. Los modelos originales (NeoX y Pythia 6.9B) están entrenados en disponibilidad abierta. Conjunto de datos de pila con deduplicación y utilizando backend Megatron y Deepspeed.
Demostramos el entrenamiento previo y el ajuste de estos modelos en instancias Trn1 basadas en AWS Trainium utilizando Neurona NeMo biblioteca. Para establecer la prueba de concepto y la reproducción rápida, utilizaremos un subconjunto de datos de Wikipedia más pequeño tokenizado mediante el tokenizador de codificación de pares de bytes (BPE) GPT2.
Tutorial
Descargue el conjunto de datos de Wikipedia previamente tokenizado como se muestra:
Tanto NeoX 20B como Pythia 6.9B utilizan CUERDA con rotación parcial, por ejemplo, rotando el 25% de las dimensiones del cabezal y manteniendo el resto sin girar. Para implementar eficientemente la rotación parcial en el acelerador AWS Trainium, en lugar de concatenar las dimensiones giratorias y no giratorias, agregamos frecuencias cero para las dimensiones no giratorias y luego rotamos el conjunto completo de dimensiones del cabezal. Este sencillo truco nos ayudó a mejorar el rendimiento (secuencias procesadas por segundo) en AWS Trainium.
Pasos de entrenamiento
Para ejecutar la capacitación, utilizamos Amazon Elastic Compute Cloud multinodo administrado por SLURM (Amazon EC2) Clúster Trn1, y cada nodo contiene una instancia trn1.32xl. Cada trn1.32xl Tiene 16 aceleradoras con dos trabajadores por acelerador. Después de descargar la última Neurona NeMo paquete, utilice el proporcionado neox y pitia scripts de preentrenamiento y ajuste con hiperparámetros optimizados y ejecute lo siguiente para un entrenamiento de cuatro nodos.
- Compilar: precompila el modelo con tres iteraciones del tren para generar y guardar los gráficos:
- Ejecutar: ejecute el entrenamiento cargando los gráficos almacenados en caché desde los primeros pasos
- Monitorear resultados
Se deben seguir los mismos pasos para ejecutar el modelo Pythia 6.9B con reemplazo neox_20B_slurm.sh by pythia_6.9B_slurm.sh.
Experimentos de preentrenamiento y ajuste fino.
Demostramos el entrenamiento previo de los modelos GPT-NeoX y Pythia en AWS Trainium utilizando Neurona NeMo biblioteca para iteraciones de 10k y también muestra el ajuste fino de estos modelos para pasos de 1k. Para el entrenamiento previo, utilizamos el tokenizador GPT2 BPE dentro del NeMo y seguimos lo mismo config como se utiliza en el modelo original. El ajuste fino en AWS Trainium requiere el cambio de algunos parámetros (como factor de división del tamaño del vocabulario), que se proporcionan en los scripts de ajuste para adaptarse a las diferencias entre Megatron y NeMo y los cambios de GPU frente a AWS Trainium. El rendimiento del entrenamiento distribuido de múltiples nodos con un número variable de nodos se muestra en la Tabla 1.
| Modelo | tensor paralelo | Pipeline Paralelo | Numero de instancias | Costo ($/hora) | Longitud de la secuencia | Tamaño de lote global | Rendimiento (seg/seg) | Relación costo-rendimiento (tokens/$) |
| Pitia 6.9B | 8 | 1 | 1 | 7.59 | 2048 | 256 | 10.4 | 10,102,387 |
| 8 | 1 | 4 | 30.36 | 2048 | 256 | 35.8 | 8,693,881 | |
| NeoX 20B | 8 | 4 | 4 | 30.36 | 2048 | 16384 | 13.60 | 3,302,704 |
| 8 | 4 | 8 | 60.72 | 2048 | 16384 | 26.80 | 3,254,134 | |
| 8 | 4 | 16 | 121.44 | 2048 | 16384 | 54.30 | 3,296,632 | |
| 8 | 4 | 32 | 242.88 | 2048 | 16384 | 107.50 | 3,263,241 | |
| 8 | 4 | 64 | 485.76 | 2048 | 16384 | 212.00 | 3,217,708 |
Tabla 1. Comparación del rendimiento medio de los modelos GPT NeoX y Pythia para entrenar hasta 500 pasos con un número variable de nodos. El precio de trn1.32xl se basa en la tarifa por hora reservada efectiva de 3 años.
A continuación, también evaluamos la trayectoria de pérdida del entrenamiento del modelo en AWS Trainium y la comparamos con la ejecución correspondiente en un clúster P4d (núcleos de GPU Nvidia A100). Junto con la pérdida de entrenamiento, también comparamos indicadores útiles como la norma de gradiente, que es la norma 2 de los gradientes del modelo calculados en cada iteración de entrenamiento para monitorear el progreso del entrenamiento. Los resultados del entrenamiento se muestran en las Figuras 1, 2 y el ajuste fino de NeoX 20B en la Figura 3.
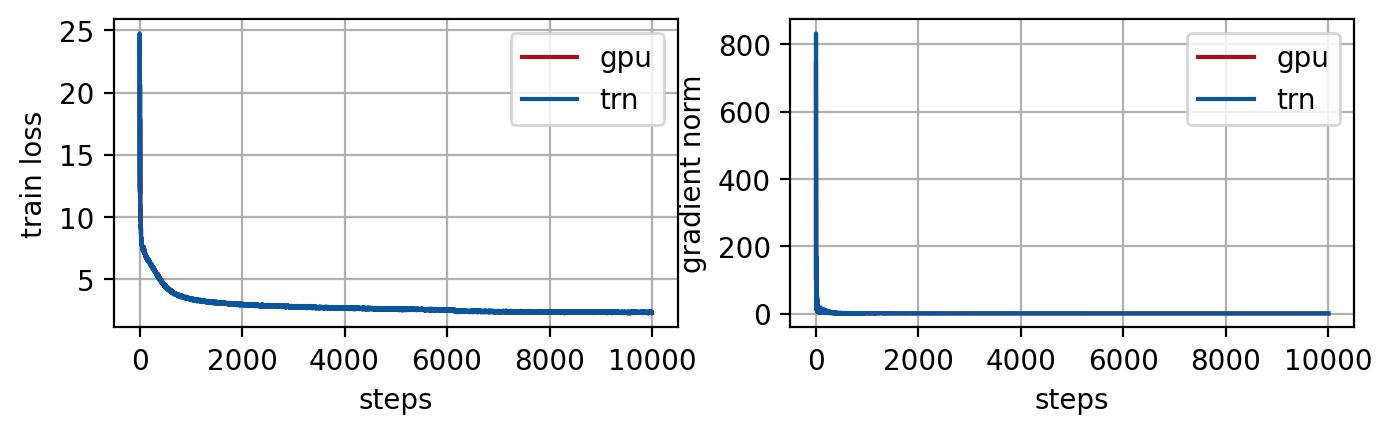
Figura 1. Pérdida de entrenamiento promediada entre todos los trabajadores (izquierda) y norma de gradiente (derecha) en el entrenamiento de cada paso. NeoX 20B está entrenado en 4 nodos con un pequeño conjunto de datos wiki en GPU y Trainium con los mismos hiperparámetros de entrenamiento (tamaño de lote global = 256). La GPU usa BF16 y precisión mixta predeterminada, mientras que AWS Trainium usa BF16 completo con redondeo estocástico. Las trayectorias de las normas de pérdida y gradiente coinciden para GPU y AWS Trainium.
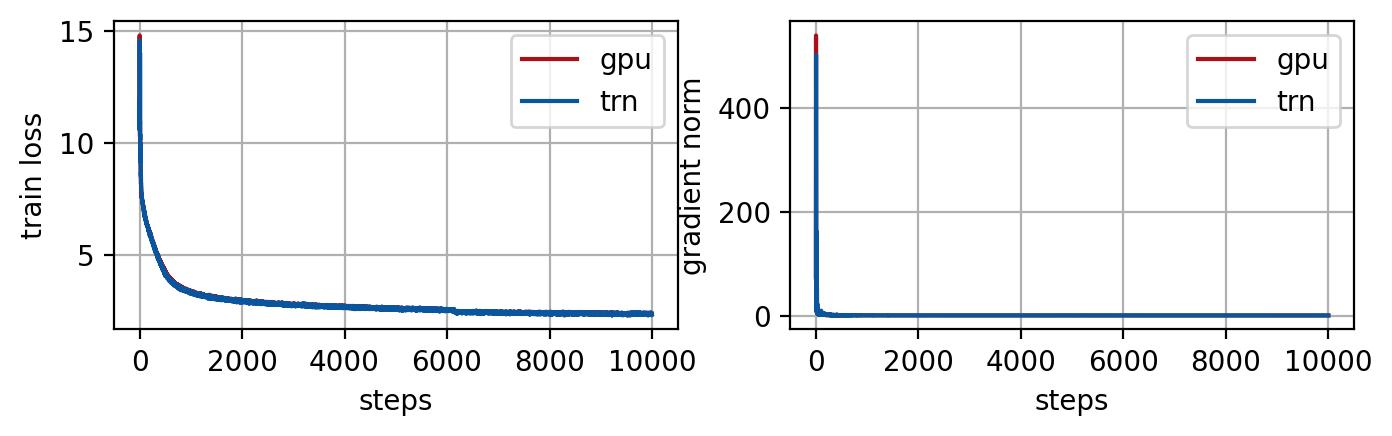
Figura 2. Pérdida de entrenamiento promediada entre todos los trabajadores (izquierda) y norma de gradiente (derecha) en el entrenamiento de cada paso. De manera similar a GPT NeoX en la Figura 1, Pythia 6.9B se entrena en 4 nodos con un pequeño conjunto de datos wiki en GPU y Trainium con los mismos hiperparámetros de entrenamiento (tamaño de lote global = 256). Las trayectorias de las normas de pérdida y gradiente coinciden con GPU y Trainium.
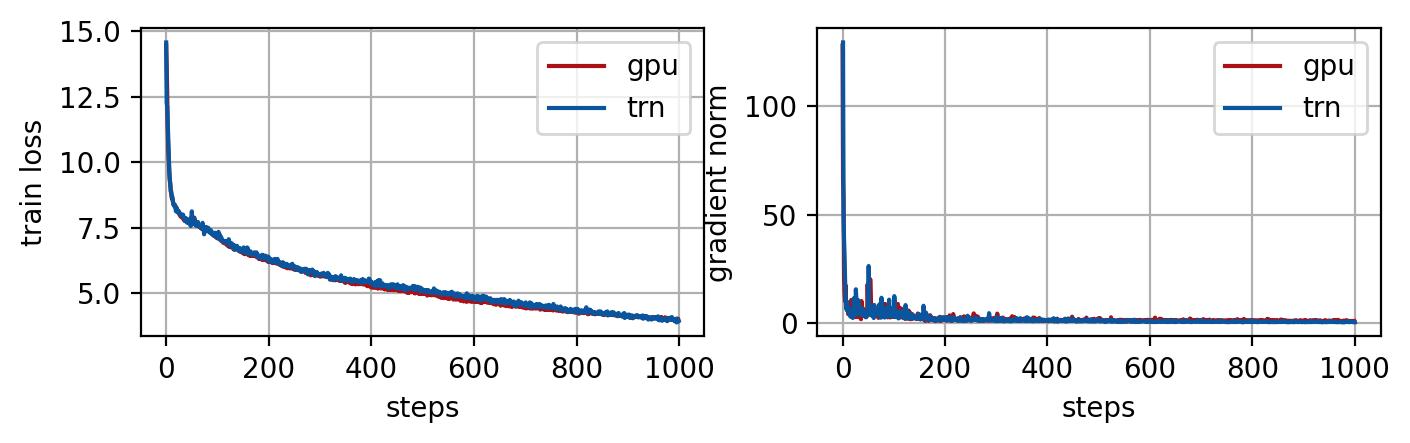
Figura 3. Ajuste del modelo GPT NeoX 20B en GPU y AWS Trainium con pérdida de entrenamiento promediada entre todos los trabajadores (izquierda) y norma de gradiente (derecha). Se utiliza un pequeño conjunto de datos wiki para la demostración de ajuste. Las trayectorias de las normas de pérdida y gradiente coinciden para GPU y AWS Trainium.
En esta publicación, mostramos una capacitación rentable para LLM en hardware de aprendizaje profundo de AWS. Entrenamos los modelos GPT NeoX 20B y Pythia 6.9B en AWS Trn1 con la biblioteca Neuron NeMo. El rendimiento normalizado del costo para 20 mil millones de modelos con AWS Trainium es de aproximadamente 3.2 millones de tokens por dólar gastado. Junto con una capacitación rentable en AWS Trainium, obtenemos una precisión del modelo similar, que es evidente a partir de la pérdida de pasos de capacitación y la trayectoria de la norma de gradiente. También ajustamos los puntos de control disponibles para el modelo NeoX 20B en AWS Trainium. Para obtener información adicional sobre la capacitación distribuida con NeMo Megatron en AWS Trainium, consulte Referencia de neuronas de AWS para NeMo Megatron. Puede encontrar un buen recurso para comenzar a ajustar el modelo Llama aquí. Llama2 afinando. Para comenzar con AWS Trainium administrado en Amazon SageMaker, consulte nuestra página, Entrene sus modelos de aprendizaje automático con AWS Trainium y Amazon SageMaker.
Acerca de los autores
 Gaurav Gupta Actualmente es científico aplicado en los laboratorios de inteligencia artificial de Amazon Web Services (AWS). El Dr. Gupta completó su doctorado en la USC Viterbi. Sus intereses de investigación abarcan el dominio del modelado de datos secuenciales, el aprendizaje de ecuaciones diferenciales parciales, la teoría de la información para el aprendizaje automático, los modelos dinámicos fraccionarios y las redes complejas. Actualmente trabaja en problemas matemáticos y aplicados sobre comportamiento de entrenamiento de LLM, modelos de visión con PDE y modelos multimodales de teoría de la información. El Dr. Gupta tiene publicaciones en las principales revistas y conferencias como Neurips, ICLR, ICML, Nature, IEEE Control Society y ACM cyber-physical society.
Gaurav Gupta Actualmente es científico aplicado en los laboratorios de inteligencia artificial de Amazon Web Services (AWS). El Dr. Gupta completó su doctorado en la USC Viterbi. Sus intereses de investigación abarcan el dominio del modelado de datos secuenciales, el aprendizaje de ecuaciones diferenciales parciales, la teoría de la información para el aprendizaje automático, los modelos dinámicos fraccionarios y las redes complejas. Actualmente trabaja en problemas matemáticos y aplicados sobre comportamiento de entrenamiento de LLM, modelos de visión con PDE y modelos multimodales de teoría de la información. El Dr. Gupta tiene publicaciones en las principales revistas y conferencias como Neurips, ICLR, ICML, Nature, IEEE Control Society y ACM cyber-physical society.
 ben snyder es un científico aplicado en AWS Deep Learning. Sus intereses de investigación incluyen modelos fundamentales, aprendizaje por refuerzo y optimización asincrónica. Fuera del trabajo, le gusta andar en bicicleta y acampar en zonas rurales.
ben snyder es un científico aplicado en AWS Deep Learning. Sus intereses de investigación incluyen modelos fundamentales, aprendizaje por refuerzo y optimización asincrónica. Fuera del trabajo, le gusta andar en bicicleta y acampar en zonas rurales.
 Amith (R) Mamidala es el ingeniero senior de aplicaciones de aprendizaje automático en AWS Annapurna Labs. El Dr. Mamidala completó su doctorado en comunicación y computación de alto rendimiento en la Universidad Estatal de Ohio. Durante su estancia en la investigación de IBM, el Dr. Mamidala contribuyó a la clase de computadoras BlueGene que a menudo encabezaban el ranking Top500 de las supercomputadoras más poderosas y eficientes energéticamente. El proyecto recibió en 2009 la Medalla Nacional de Tecnología e Innovación. Después de un breve período como ingeniero de inteligencia artificial en un fondo de cobertura financiero, el Dr. Mamidala se unió a los laboratorios de Annapurna y se centró en la capacitación de modelos de lenguaje grande.
Amith (R) Mamidala es el ingeniero senior de aplicaciones de aprendizaje automático en AWS Annapurna Labs. El Dr. Mamidala completó su doctorado en comunicación y computación de alto rendimiento en la Universidad Estatal de Ohio. Durante su estancia en la investigación de IBM, el Dr. Mamidala contribuyó a la clase de computadoras BlueGene que a menudo encabezaban el ranking Top500 de las supercomputadoras más poderosas y eficientes energéticamente. El proyecto recibió en 2009 la Medalla Nacional de Tecnología e Innovación. Después de un breve período como ingeniero de inteligencia artificial en un fondo de cobertura financiero, el Dr. Mamidala se unió a los laboratorios de Annapurna y se centró en la capacitación de modelos de lenguaje grande.
 Jun (Lucas) Huan es científico principal de AWS AI Labs. El Dr. Huan trabaja en IA y ciencia de datos. Ha publicado más de 180 artículos revisados por pares en congresos y revistas líderes. Recibió el premio NSF Faculty Early Career Development Award en 2009. Antes de unirse a AWS, trabajó en Baidu Research como científico distinguido y director del Baidu Big Data Laboratory. Fundó StylingAI Inc., una nueva empresa de inteligencia artificial, y trabajó como director ejecutivo y científico jefe en 2019-2021. Antes de incorporarse a la industria, fue profesor Charles E. y Mary Jane Spahr en el Departamento EECS de la Universidad de Kansas.
Jun (Lucas) Huan es científico principal de AWS AI Labs. El Dr. Huan trabaja en IA y ciencia de datos. Ha publicado más de 180 artículos revisados por pares en congresos y revistas líderes. Recibió el premio NSF Faculty Early Career Development Award en 2009. Antes de unirse a AWS, trabajó en Baidu Research como científico distinguido y director del Baidu Big Data Laboratory. Fundó StylingAI Inc., una nueva empresa de inteligencia artificial, y trabajó como director ejecutivo y científico jefe en 2019-2021. Antes de incorporarse a la industria, fue profesor Charles E. y Mary Jane Spahr en el Departamento EECS de la Universidad de Kansas.
 Sruti Koparkar es gerente sénior de marketing de productos en AWS. Ayuda a los clientes a explorar, evaluar y adoptar la infraestructura informática acelerada de Amazon EC2 para sus necesidades de aprendizaje automático.
Sruti Koparkar es gerente sénior de marketing de productos en AWS. Ayuda a los clientes a explorar, evaluar y adoptar la infraestructura informática acelerada de Amazon EC2 para sus necesidades de aprendizaje automático.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/frugality-meets-accuracy-cost-efficient-training-of-gpt-neox-and-pythia-models-with-aws-trainium/

