
Imagen del autor
En los últimos meses, Modelos de lenguaje grande (LLM) han ganado una atención significativa, captando el interés de los desarrolladores de todo el planeta. Estos modelos han creado perspectivas interesantes, especialmente para los desarrolladores que trabajan en chatbots, asistentes personales y creación de contenido. Las posibilidades que los LLM traen a la mesa han despertado una ola de entusiasmo en el Desarrollador | IA | comunidad de PNL.
Los modelos de lenguaje extenso (LLM, por sus siglas en inglés) se refieren a modelos de aprendizaje automático capaces de producir texto que se parece mucho al lenguaje humano y comprender indicaciones de forma natural. Estos modelos se entrenan utilizando extensos conjuntos de datos que incluyen libros, artículos, sitios web y otras fuentes. Mediante el análisis de patrones estadísticos dentro de los datos, los LLM predicen las palabras o frases más probables que deberían seguir a una entrada determinada.
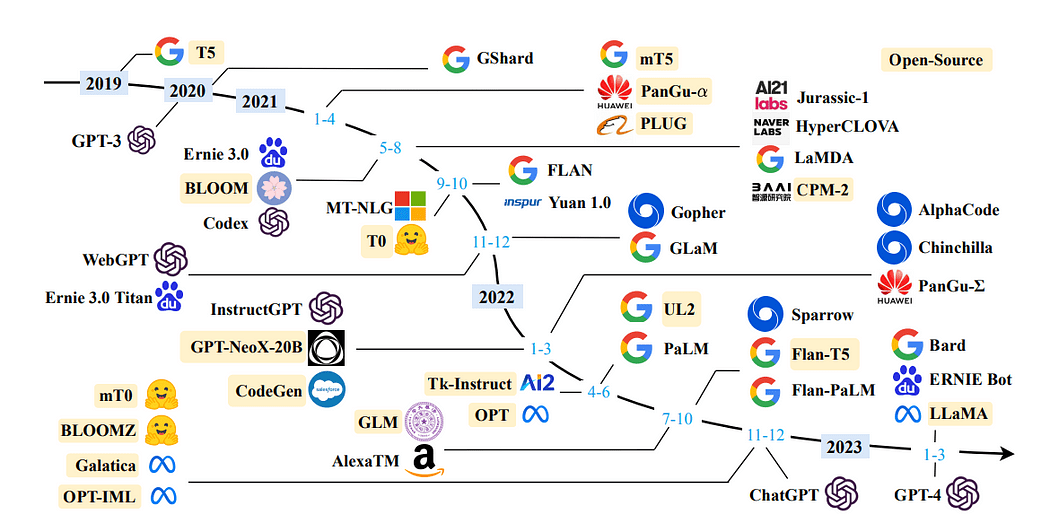
Una línea de tiempo de LLM en los últimos años: Una encuesta de modelos de lenguaje grande
Al utilizar Modelos de lenguaje extenso (LLM), podemos incorporar datos específicos del dominio para abordar las consultas de manera efectiva. Esto se vuelve especialmente ventajoso cuando se trata de información a la que el modelo no tenía acceso durante su formación inicial, como la documentación interna de una empresa o el repositorio de conocimientos.
La arquitectura empleada para este propósito se conoce como Generación de aumento de recuperación o, con menos frecuencia, Respuesta generativa a preguntas.
LangChain es un marco impresionante y de libre acceso diseñado meticulosamente para capacitar a los desarrolladores en la creación de aplicaciones impulsadas por el poder de los modelos de lenguaje, particularmente los modelos de lenguaje grandes (LLM).
LangChain revoluciona el proceso de desarrollo de una amplia gama de aplicaciones, incluidos chatbots, respuesta generativa a preguntas (GQA) y resúmenes. por perfectamente encadenamiento Juntando componentes provenientes de múltiples módulos, LangChain permite la creación de aplicaciones excepcionales adaptadas al poder de los LLM.
Leer más: Documentación oficial
Imagen del autor
En este artículo, demostraré el proceso de creación de su propio Asistente de documentos desde cero, utilizando LLaMA 7b y Langchain, una biblioteca de código abierto desarrollada específicamente para una integración perfecta con LLM.
Aquí hay una descripción general de la estructura del blog, que describe las secciones específicas que proporcionarán un desglose detallado del proceso:
Setting up the virtual environment and creating file structureGetting LLM on your local machineIntegrating LLM with LangChain and customizing PromptTemplateDocument Retrieval and Answer GenerationBuilding application using Streamlit
La configuración de un entorno virtual proporciona un entorno controlado y aislado para ejecutar la aplicación, lo que garantiza que sus dependencias estén separadas de otros paquetes de todo el sistema. Este enfoque simplifica la gestión de dependencias y ayuda a mantener la coherencia en diferentes entornos.
Para configurar el entorno virtual para esta aplicación, proporcionaré el archivo pip en mi repositorio de GitHub. Primero, creemos la estructura de archivos necesaria como se muestra en la figura. Alternativamente, puede simplemente clonar el repositorio para obtener los archivos requeridos.
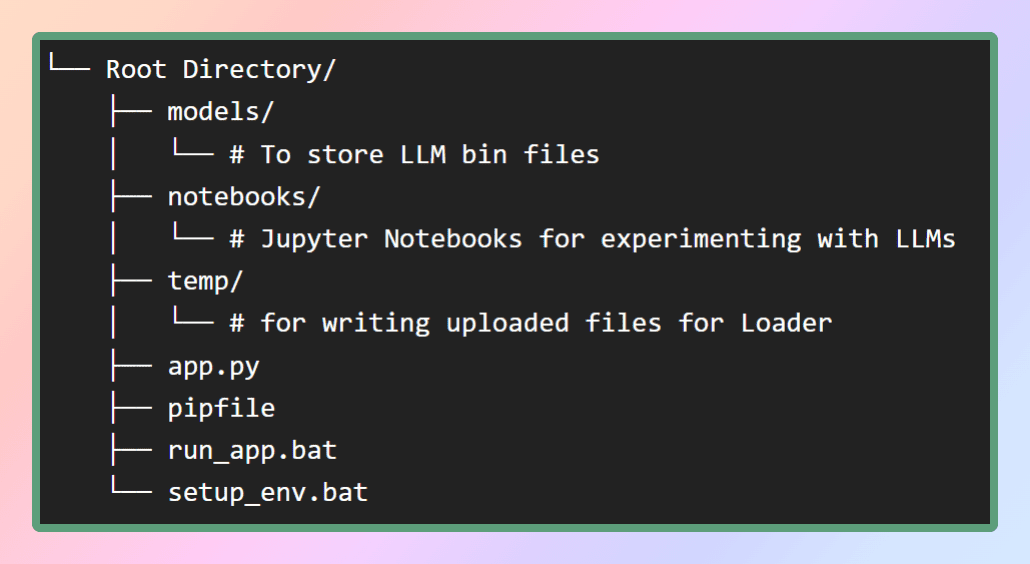
Imagen por autor: Estructura del archivo
Dentro de la carpeta de modelos, almacenaremos los LLM que descargaremos, mientras que el archivo pip se ubicará en el directorio raíz.
Para crear el entorno virtual e instalar todas las dependencias dentro de él, podemos usar el pipenv installcomando desde el mismo directorio o simplemente ejecute setup_env.bat archivo por lotes, instalará todas las dependencias desde el pipfile. Esto asegurará que todos los paquetes y bibliotecas necesarios estén instalados en el entorno virtual. Una vez que las dependencias se hayan instalado correctamente, podemos continuar con el siguiente paso, que consiste en descargar los modelos deseados. Aquí está el repo.
¿Qué es LLaMA?
LLaMA es un nuevo modelo de lenguaje grande diseñado por Meta AI, que es la empresa matriz de Facebook. Con una colección diversa de modelos que van desde 7 mil millones a 65 mil millones de parámetros, LLaMA se destaca como uno de los modelos de lenguaje más completos disponibles. El 24 de febrero de 2023, Meta lanzó al público el modelo LLaMA, demostrando su dedicación a la ciencia abierta.
Fuente de imagen: Llama
Teniendo en cuenta las notables capacidades de LLaMA, hemos optado por utilizar este poderoso modelo de lenguaje para nuestros propósitos. Específicamente, emplearemos la versión más pequeña de LLaMA, conocida como LLaMA 7B. Incluso con este tamaño reducido, LLaMA 7B ofrece importantes capacidades de procesamiento del lenguaje, lo que nos permite lograr los resultados deseados de manera eficiente y efectiva.
Documento de investigación oficial :
LLaMA: Open and Efficient Foundation Language Models
Para ejecutar el LLM en una CPU local, necesitamos un modelo local en formato GGML. Varios métodos pueden lograr esto, pero el enfoque más simple es descargar el archivo bin directamente desde el Repositorio de Hugging Face Models. En nuestro caso, descargaremos el modelo Llama 7B. Estos modelos son de código abierto y están disponibles gratuitamente para su descarga.
Si está buscando ahorrar tiempo y esfuerzo, no se preocupe, lo tengo cubierto. Aquí te dejo el enlace directo para que descargues los modelos ?. Simplemente descargue cualquier versión y luego mueva el archivo al directorio de modelos dentro de nuestro directorio raíz. De esta manera, tendrá el modelo convenientemente accesible para su uso.
¿Qué es GGML? ¿Por qué GGML? ¿Cómo GGML? LLAMA CPP
GGML es una biblioteca de Tensor para aprendizaje automático, es solo una biblioteca de C++ que le permite ejecutar LLM solo en la CPU o CPU + GPU. Define un formato binario para distribuir modelos de lenguaje grandes (LLM). GGML hace uso de una técnica llamada cuantización que permite que los modelos de lenguaje grandes se ejecuten en hardware de consumo.
Ahora, ¿qué es la cuantización?
Los pesos LLM son números de coma flotante (decimales). Al igual que requiere más espacio para representar un número entero grande (p. ej., 1000) en comparación con un número entero pequeño (p. ej., 1), requiere más espacio para representar un número de coma flotante de alta precisión (p. ej., 0.0001) en comparación con un número flotante de baja precisión. (por ejemplo, 0.1). El proceso de cuantizando un modelo de lenguaje grande implica reducir la precisión con la que se representan los pesos para reducir los recursos necesarios para usar el modelo. GGML admite varias estrategias de cuantificación diferentes (por ejemplo, cuantificación de 4 bits, 5 bits y 8 bits), cada una de las cuales ofrece diferentes compensaciones entre eficiencia y rendimiento.
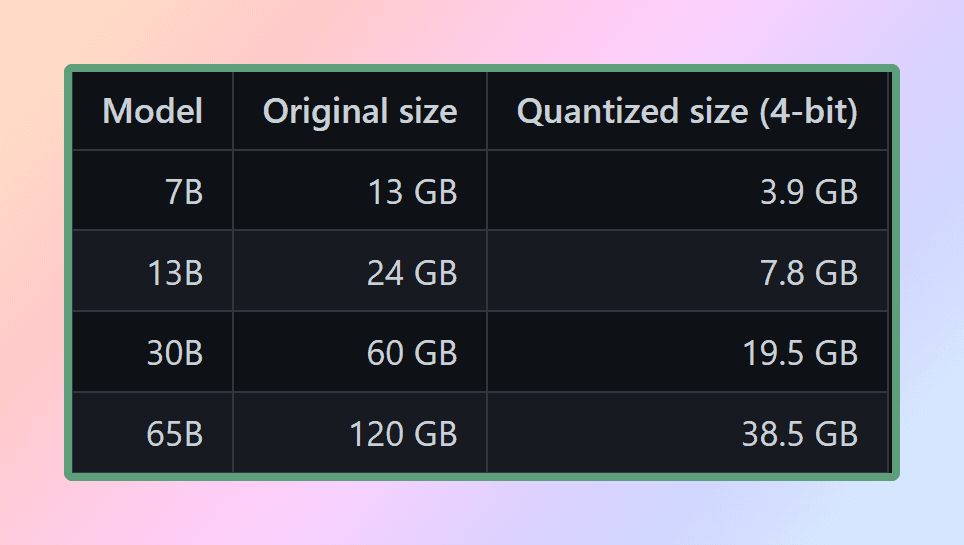
Tamaño cuantificado de llama
Para usar los modelos de manera efectiva, es esencial tener en cuenta los requisitos de memoria y disco. Dado que los modelos actualmente se cargan por completo en la memoria, necesitará suficiente espacio en disco para almacenarlos y suficiente RAM para cargarlos durante la ejecución. Cuando se trata del modelo 65B, incluso después de la cuantificación, se recomienda tener al menos 40 gigabytes de RAM disponibles. Vale la pena señalar que los requisitos de memoria y disco actualmente son equivalentes.
La cuantificación juega un papel crucial en la gestión de estas demandas de recursos. A menos que tenga acceso a recursos computacionales excepcionales
Al reducir la precisión de los parámetros del modelo y optimizar el uso de la memoria, la cuantificación permite utilizar los modelos en configuraciones de hardware más modestas. Esto garantiza que la ejecución de los modelos siga siendo factible y eficiente para una gama más amplia de configuraciones.
¿Cómo lo usamos en Python si es una biblioteca de C++?
Ahí es donde entran en juego los enlaces de Python. La vinculación se refiere al proceso de crear un puente o interfaz entre dos lenguajes para nosotros, Python y C++. Usaremos llama-cpp-python que es un enlace de Python para llama.cpp que actúa como una Inferencia del modelo LLaMA en C/C++ puro. El objetivo principal de llama.cpp es ejecutar el modelo LLaMA usando cuantificación de enteros de 4 bits. Esta integración nos permite utilizar de manera efectiva el modelo LLaMA, aprovechando las ventajas de la implementación de C/C++ y los beneficios de la cuantificación de enteros de 4 bits.

Modelos soportados por llama.cpp : Fuente
Con el modelo GGML preparado y todas nuestras dependencias en su lugar (gracias al pipfile), es hora de embarcarse en nuestro viaje con LangChain. Pero antes de sumergirnos en el apasionante mundo de LangChain, comencemos con lo habitual "Hola Mundo" ritual: una tradición que seguimos cada vez que exploramos un nuevo lenguaje o marco, después de todo, LLM también es un modelo de lenguaje.

Imagen por autor: Interacción con LLM en CPU
Voila!!! Hemos ejecutado con éxito nuestro primer LLM en la CPU, completamente fuera de línea y de forma completamente aleatoria (puede jugar con el hiperparámetro temperatura).
Con este emocionante hito logrado, ahora estamos listos para embarcarnos en nuestro objetivo principal: responder preguntas de texto personalizado utilizando el marco LangChain.
En la última sección, inicializamos LLM usando llama cpp. Ahora, aprovechemos el marco LangChain para desarrollar aplicaciones usando LLM. La interfaz principal a través de la cual puede interactuar con ellos es a través del texto. Como una simplificación excesiva, muchos modelos son texto adentro, texto afuera. Por lo tanto, muchas de las interfaces de LangChain se centran en el texto.
El auge de la ingeniería inmediata
En el campo de la programación, en constante evolución, ha surgido un paradigma fascinante: Incitación. La incitación implica proporcionar una entrada específica a un modelo de lenguaje para obtener una respuesta deseada. Este enfoque innovador nos permite dar forma a la salida del modelo en función de la entrada que proporcionamos.
Es notable cómo los matices en la forma en que expresamos un mensaje pueden afectar significativamente la naturaleza y la sustancia de la respuesta del modelo. El resultado puede variar fundamentalmente según la redacción, lo que destaca la importancia de una consideración cuidadosa al formular indicaciones.
Para proporcionar una interacción fluida con los LLM, LangChain proporciona varias clases y funciones para facilitar la construcción y el trabajo con avisos usando una plantilla de aviso. Es una forma reproducible de generar un aviso. Contiene una cadena de texto. la plantilla, que puede recibir un conjunto de parámetros del usuario final y genera un aviso. Tomemos algunos ejemplos.
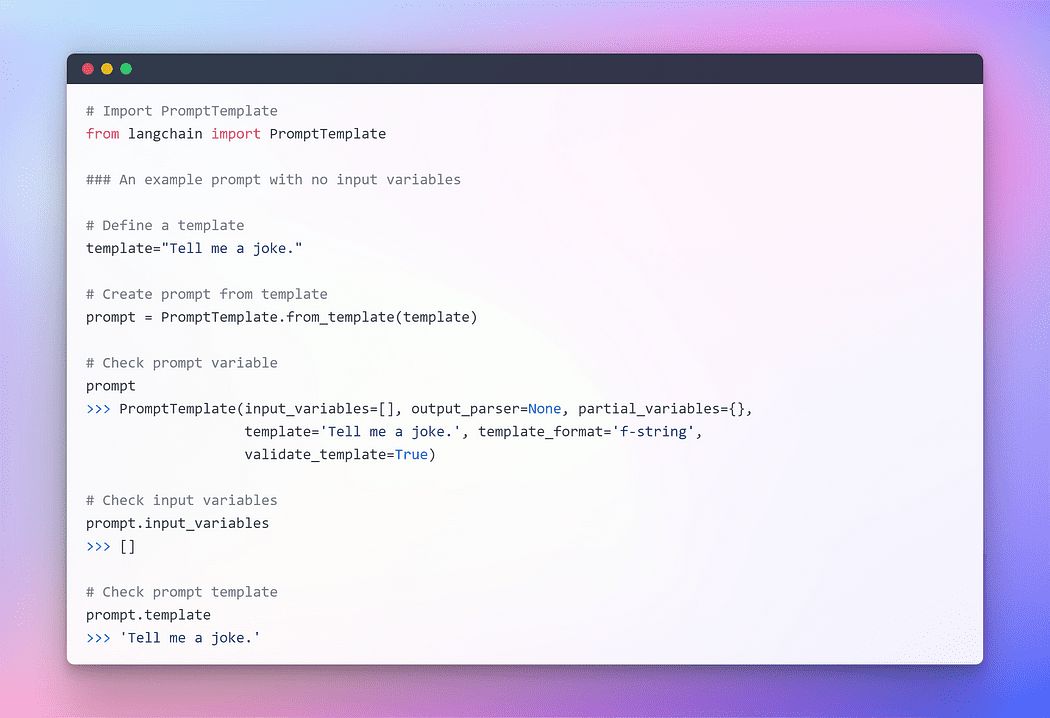
Imagen por autor: solicitud sin variables de entrada
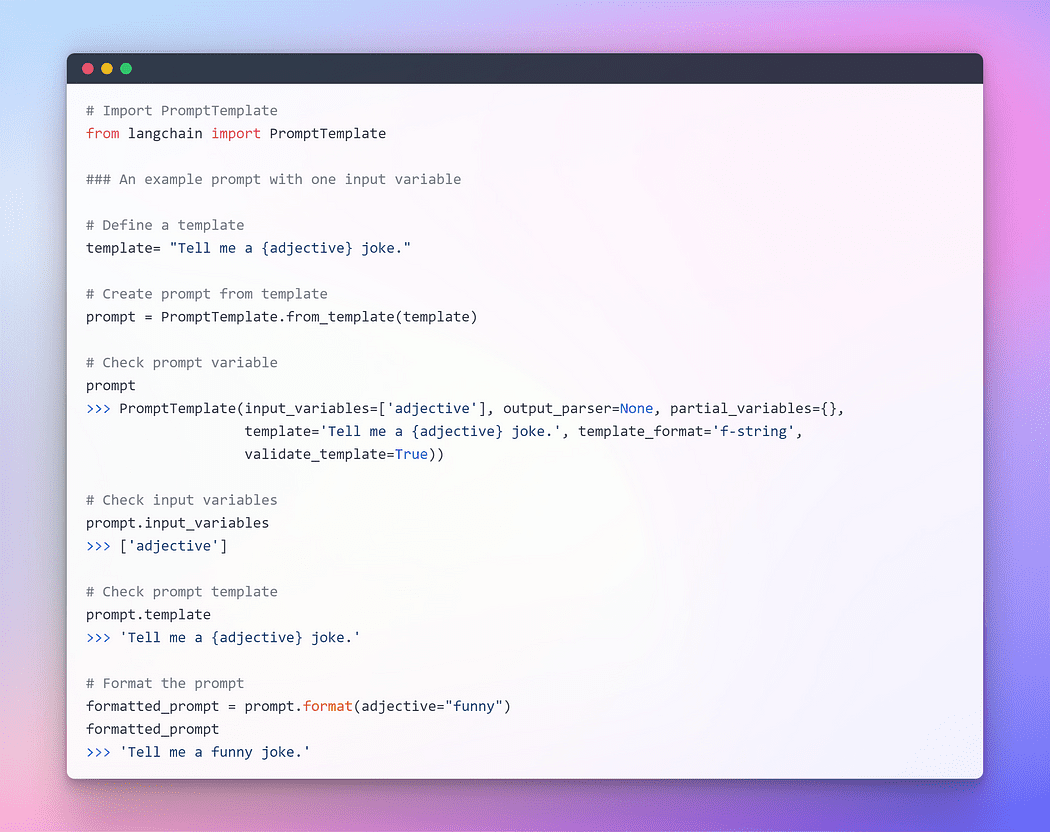
Imagen por autor: solicitud con una variable de entrada
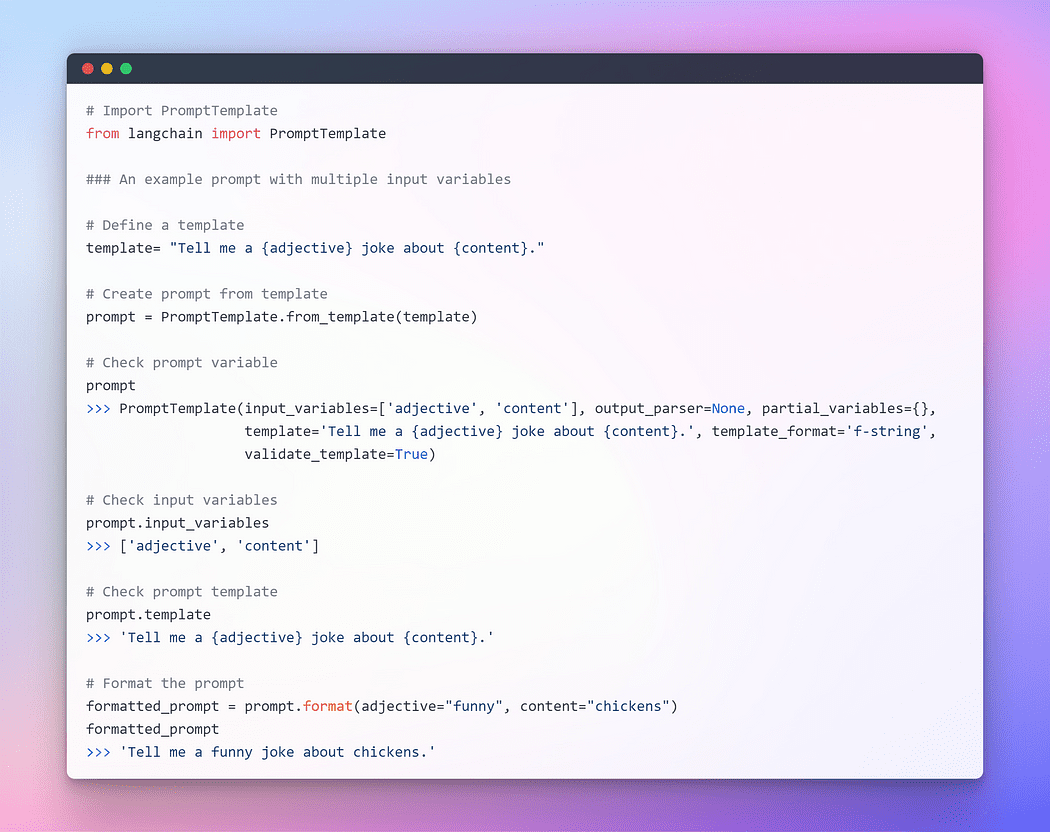
Imagen por autor: Solicitud con múltiples variables de entrada
Espero que la explicación anterior haya proporcionado una comprensión más clara del concepto de incitación. Ahora, procedamos a solicitar el LLM.
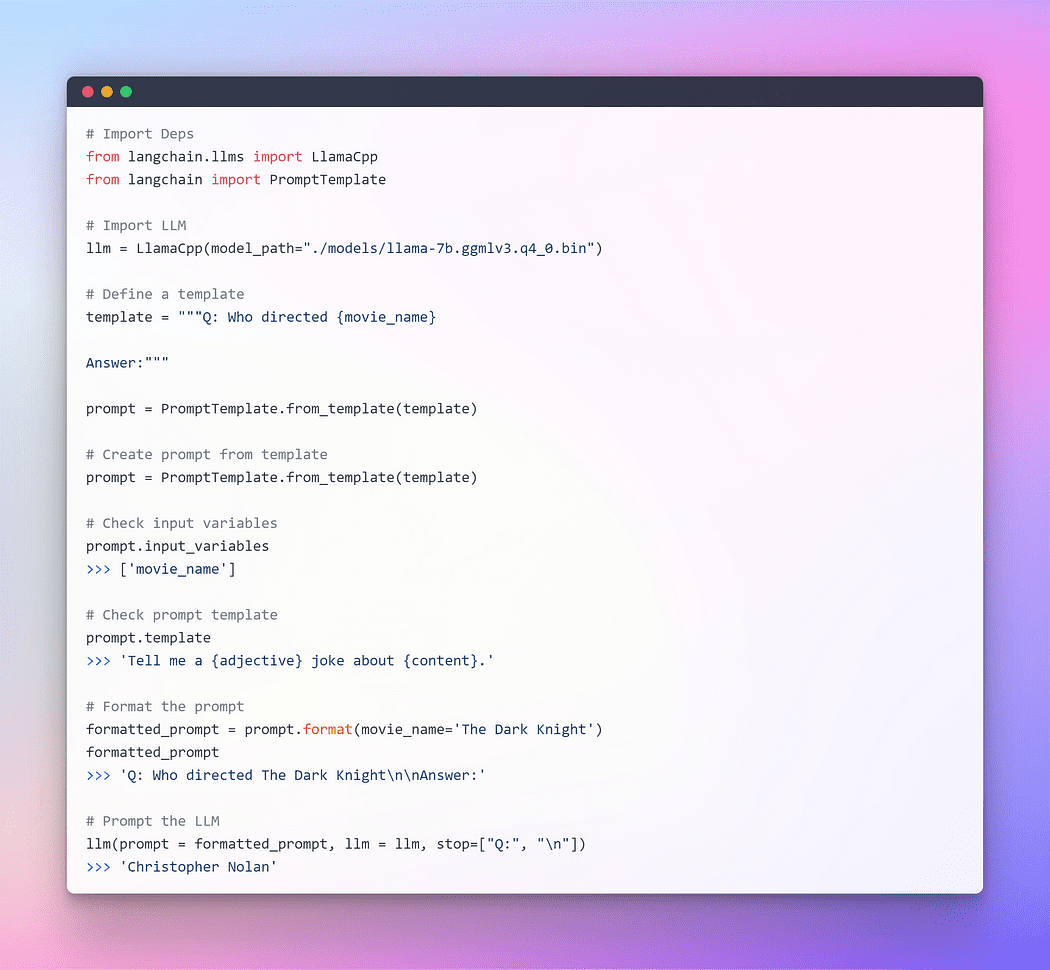
Imagen del autor: Incitación a través de Langchain LLM
Esto funcionó perfectamente bien, pero esta no es la utilización óptima de LangChain. Hasta ahora hemos utilizado componentes individuales. Tomamos la plantilla de solicitud y la formateamos, luego tomamos el llm y luego pasamos esos parámetros dentro de llm para generar la respuesta. Usar un LLM de forma aislada está bien para aplicaciones simples, pero las aplicaciones más complejas requieren LLM encadenados, ya sea entre sí o con otros componentes.
LangChain proporciona la interfaz Chain para tales encadenadoaplicaciones Definimos una Cadena de forma muy genérica como una secuencia de llamadas a componentes, que pueden incluir otras cadenas. Las cadenas nos permiten combinar varios componentes para crear una aplicación única y coherente. Por ejemplo, podemos crear una cadena que tome la entrada del usuario, la formatee con una plantilla de solicitud y luego pase la respuesta formateada a un LLM. Podemos construir cadenas más complejas combinando varias cadenas juntas o combinando cadenas con otros componentes.
Para entender uno vamos a crear uno muy simple cadena eso tomará la entrada del usuario, formateará el indicador con él y luego lo enviará al LLM usando los componentes individuales anteriores que ya hemos creado.
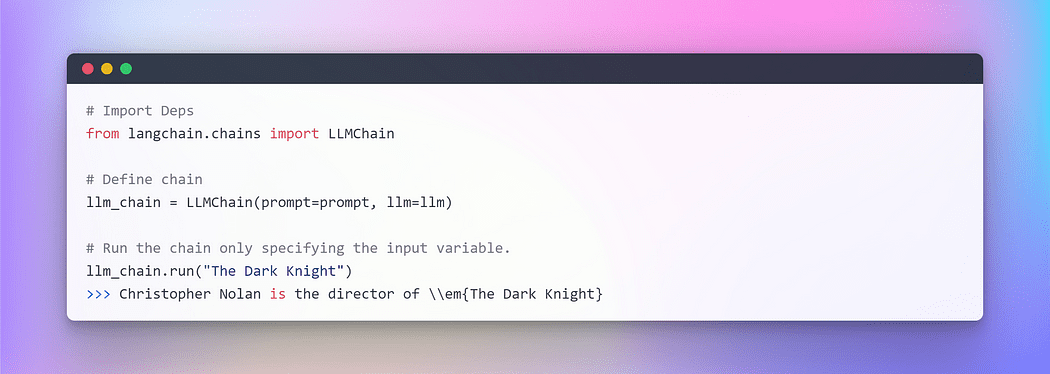
Imagen por autor: Encadenamiento en LangChain
Cuando se trata de múltiples variables, tiene la opción de ingresarlas colectivamente utilizando un diccionario. Eso concluye esta sección. Ahora, profundicemos en la parte principal donde incorporaremos texto externo como un recuperador para propósitos de preguntas y respuestas.
En numerosas aplicaciones LLM, existe la necesidad de datos específicos del usuario que no están incluidos en el conjunto de entrenamiento del modelo. LangChain le proporciona los componentes esenciales para cargar, transformar, almacenar y consultar sus datos.
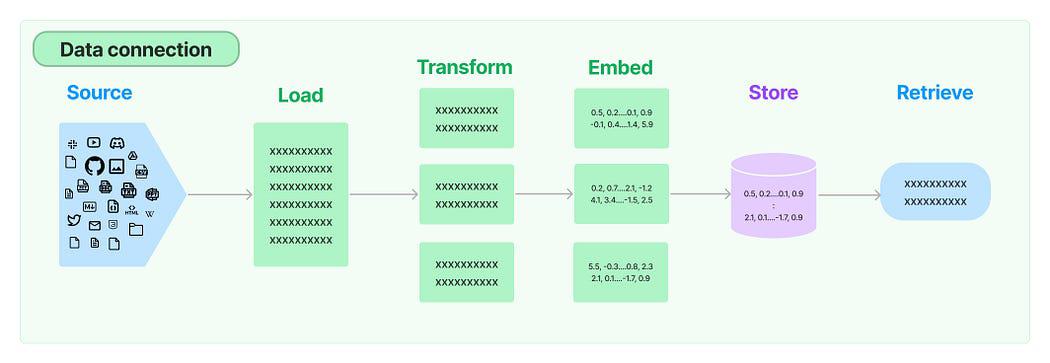
Conexión de datos en LangChain: Fuente
Las cinco etapas son:
- Cargador de documentos: Se utiliza para cargar datos como documentos.
- Transformador de documentos: Dividía el documento en partes más pequeñas.
- Incrustaciones: Transforma los fragmentos en representaciones vectoriales, también conocidas como incrustaciones.
- Tiendas de vectores: Se utiliza para almacenar los vectores de fragmentos anteriores en una base de datos de vectores.
- Perros perdigueros: Se utiliza para recuperar un conjunto de vectores que son más similares a una consulta en forma de un vector que está incrustado en el mismo espacio latente.
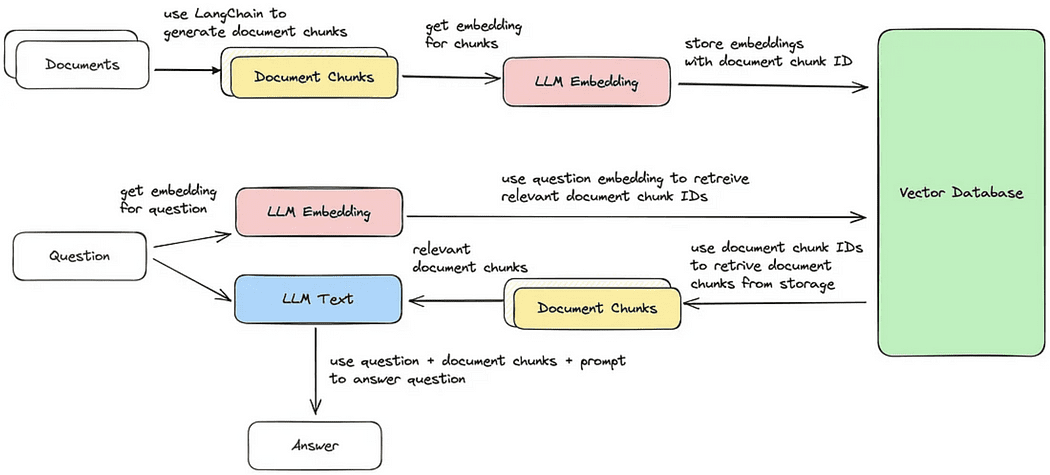
Recuperación de Documentos / Ciclo de Preguntas y Respuestas
Ahora, recorreremos cada uno de los cinco pasos para realizar una recuperación de fragmentos de documentos que son más similares a la consulta. Después de eso, podemos generar una respuesta basada en el fragmento de vector recuperado, como se ilustra en la imagen provista.
Sin embargo, antes de continuar, necesitaremos preparar un texto para ejecutar las tareas antes mencionadas. A los efectos de esta prueba ficticia, he copiado un texto de Wikipedia sobre algunos superhéroes de DC populares. Aquí está el texto:

Imagen por autor: texto sin procesar para pruebas
Cargar y transformar documentos
Para comenzar, creemos un objeto de documento. En este ejemplo, utilizaremos el cargador de texto. Sin embargo, la cadena Lang ofrece soporte para múltiples documentos, por lo que dependiendo de su documento específico, puede emplear diferentes cargadores. A continuación, emplearemos el load para recuperar datos y cargarlos como documentos desde una fuente preconfigurada.
Una vez que se carga el documento, podemos continuar con el proceso de transformación dividiéndolo en partes más pequeñas. Para lograr esto, utilizaremos TextSplitter. De forma predeterminada, el separador separa el documento en el separador 'nn'. Sin embargo, si establece el separador en nulo y define un tamaño de fragmento específico, cada fragmento tendrá esa longitud especificada. En consecuencia, la longitud de la lista resultante será igual a la longitud del documento dividida por el tamaño del fragmento. En resumen, se parecerá a algo como esto: list length = length of doc / chunk size. Vamos a caminar la charla.
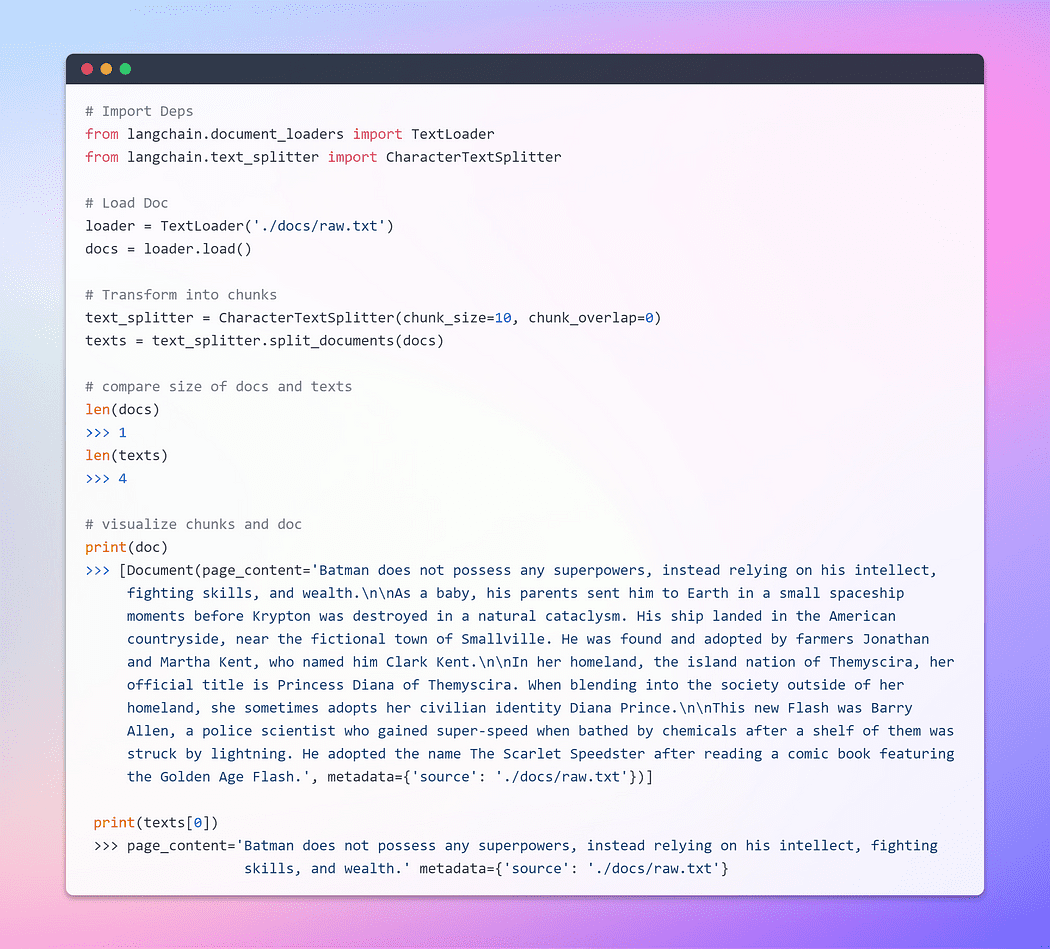
Imagen por autor: Cargando y transformando Doc
¡¡¡Parte del viaje son las Embeddings!!!
Éste es el paso más importante. Las incrustaciones generan una representación vectorizada del contenido textual. Esto tiene un significado práctico ya que nos permite conceptualizar texto dentro de un espacio vectorial.
La incrustación de palabras es simplemente una representación vectorial de una palabra, con el vector que contiene números reales. Dado que los idiomas suelen contener al menos decenas de miles de palabras, los vectores de palabras binarios simples pueden volverse poco prácticos debido a la gran cantidad de dimensiones. Las incrustaciones de palabras resuelven este problema al proporcionar representaciones densas de palabras en un espacio vectorial de baja dimensión.
Cuando hablamos de recuperación, nos referimos a recuperar un conjunto de vectores que son más similares a una consulta en forma de vector que está incrustado en el mismo espacio latente.
La clase básica Embeddings en LangChain expone dos métodos: uno para incrustar documentos y otro para incrustar una consulta. El primero toma como entrada múltiples textos, mientras que el segundo toma un solo texto.
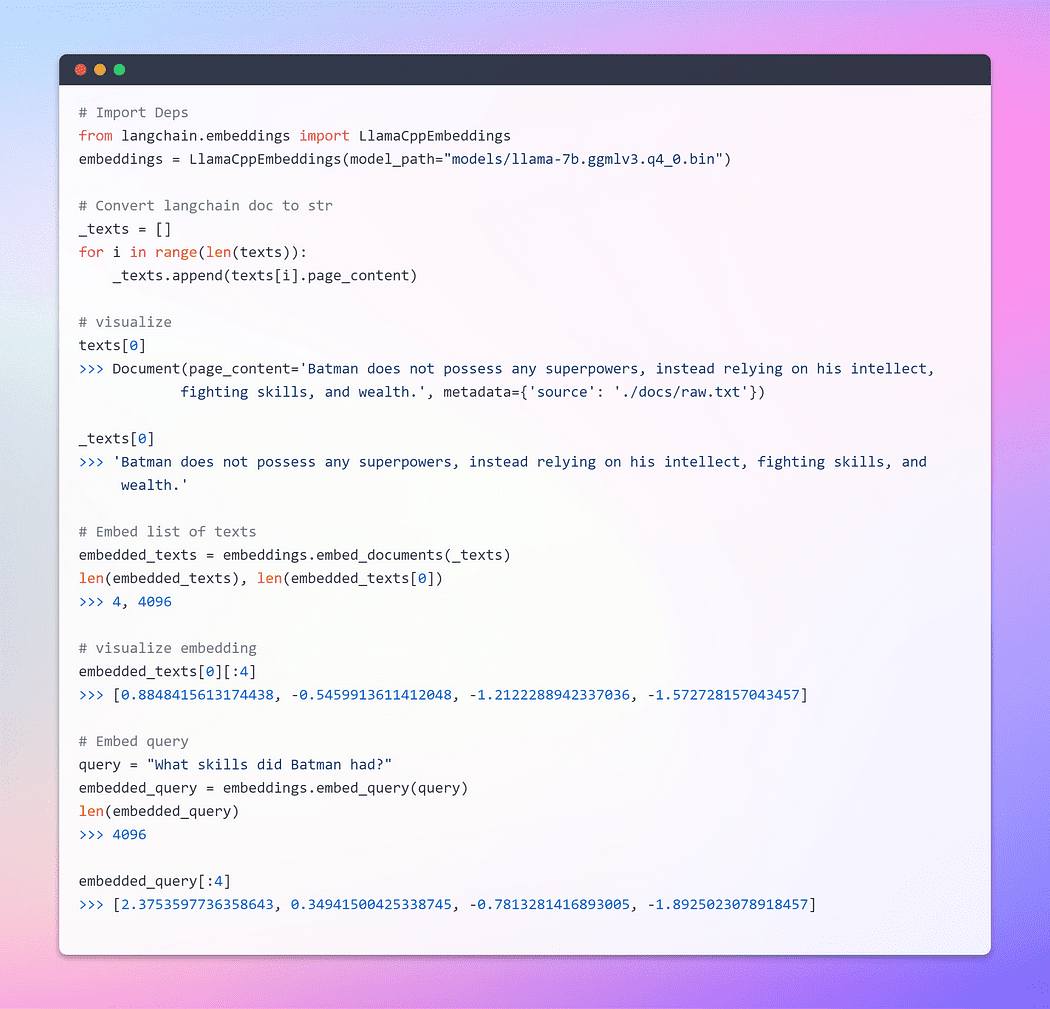
Imagen por autor: incrustaciones
Para una comprensión integral de las incrustaciones, recomiendo profundizar en los fundamentos, ya que forman el núcleo de cómo las redes neuronales manejan los datos textuales. He cubierto extensamente este tema en uno de mis blogs utilizando TensorFlow. Aqui esta el link.
Incrustaciones de palabras: representación de texto para redes neuronales
Creación de una tienda de vectores y recuperación de documentos
Una tienda de vectores administra de manera eficiente el almacenamiento de datos incrustados y facilita las operaciones de búsqueda de vectores en su nombre. Incrustar y almacenar los vectores de incrustación resultantes es un método predominante para almacenar y buscar datos no estructurados. Durante el tiempo de consulta, la consulta no estructurada también se incrusta y se recuperan los vectores de incrustación que muestran la mayor similitud con la consulta incrustada. Este enfoque permite la recuperación efectiva de información relevante del almacén de vectores.
Aquí, utilizaremos Chroma, una base de datos de incrustaciones y una tienda de vectores diseñada específicamente para simplificar el desarrollo de aplicaciones de IA que incorporan incrustaciones. Ofrece un conjunto integral de herramientas y funcionalidades integradas para facilitar su configuración inicial, todas las cuales pueden instalarse convenientemente en su máquina local ejecutando un simple pip install chromadb mando.

Imagen por autor: Creación de una tienda de vectores
Hasta ahora, hemos sido testigos de la notable capacidad de incrustaciones y almacenes de vectores para recuperar fragmentos relevantes de extensas colecciones de documentos. Ahora, ha llegado el momento de presentar este fragmento recuperado como un contexto junto con nuestra consulta, al LLM. Con un movimiento de su varita mágica, suplicaremos al LLM que genere una respuesta basada en la información que le proporcionamos. La parte importante es la estructura rápida.
Sin embargo, es crucial enfatizar la importancia de un mensaje bien estructurado. Al formular un aviso bien elaborado, podemos mitigar el potencial de que el LLM participe en alucinación — donde podría inventar hechos cuando se enfrenta a la incertidumbre.
Sin alargar más la espera, pasemos ahora a la fase final y descubramos si nuestro LLM es capaz de generar una respuesta convincente. Ha llegado el momento de presenciar la culminación de nuestros esfuerzos y revelar el resultado. ¿Aquí vamos?
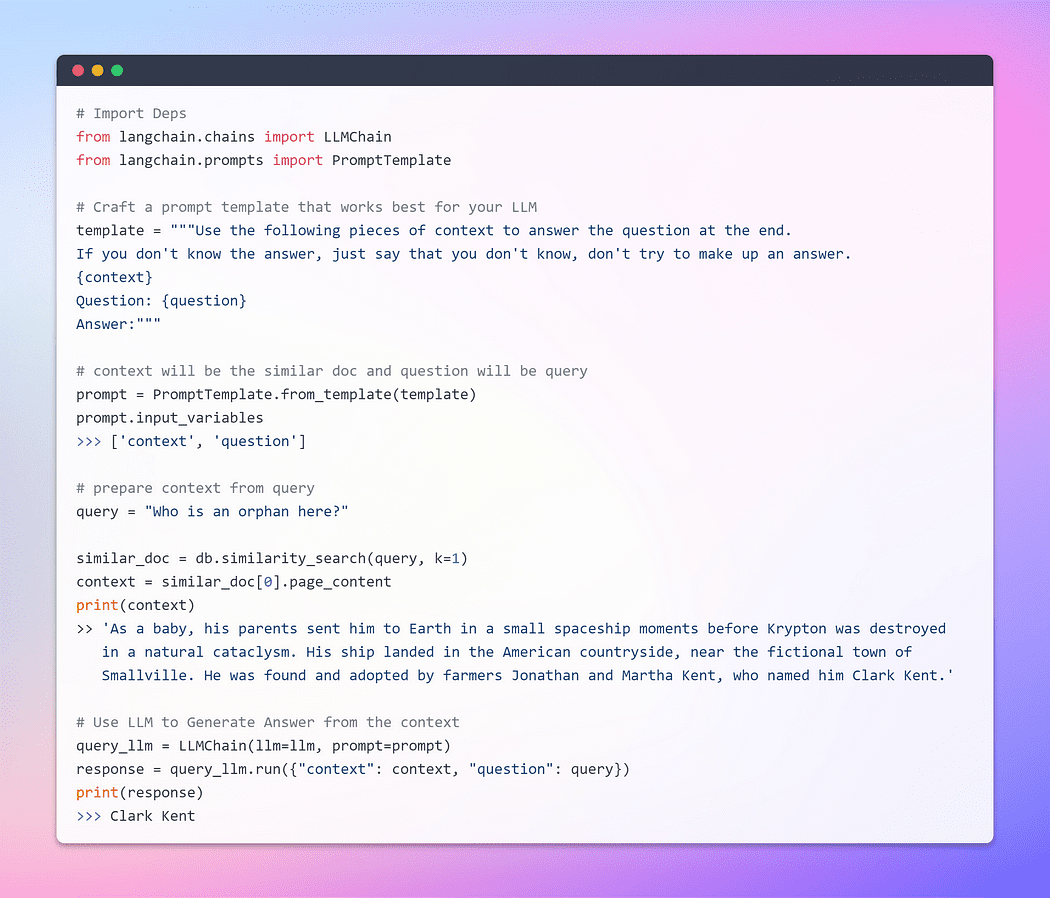
Imagen por autor: Q/A con el Doc
¡Este es el momento que hemos estado esperando! ¡Lo hemos logrado! Acabamos de construir nuestro propio bot de respuesta a preguntas utilizando el LLM que se ejecuta localmente.
Esta sección es completamente opcional ya que no sirve como una guía completa de Streamlit. No profundizaré en esta parte; en su lugar, presentaré una aplicación básica que permite a los usuarios cargar cualquier documento de texto. Luego tendrán la opción de hacer preguntas a través de la entrada de texto. Detrás de escena, la funcionalidad seguirá siendo consistente con lo que cubrimos en la sección anterior.
Sin embargo, hay una advertencia cuando se trata de cargar archivos en Streamlit. Para evitar posibles errores de falta de memoria, particularmente considerando la naturaleza de uso intensivo de memoria de los LLM, simplemente leeré el documento y lo escribiré en la carpeta temporal dentro de nuestra estructura de archivos, nombrándolo raw.txt. De esta forma, independientemente del nombre original del documento, Textloader lo procesará sin problemas en el futuro.
Actualmente, la aplicación está diseñada para archivos de texto, pero puedes adaptarla para PDF, CSV u otros formatos. El concepto subyacente sigue siendo el mismo, ya que los LLM están diseñados principalmente para la entrada y salida de texto. Además, puede experimentar con diferentes LLM compatibles con los enlaces de Llama C++.
Sin profundizar más en detalles intrincados, presento el código de la aplicación. Siéntase libre de personalizarlo para que se adapte a su caso de uso específico.
Así es como se verá la aplicación streamlit.
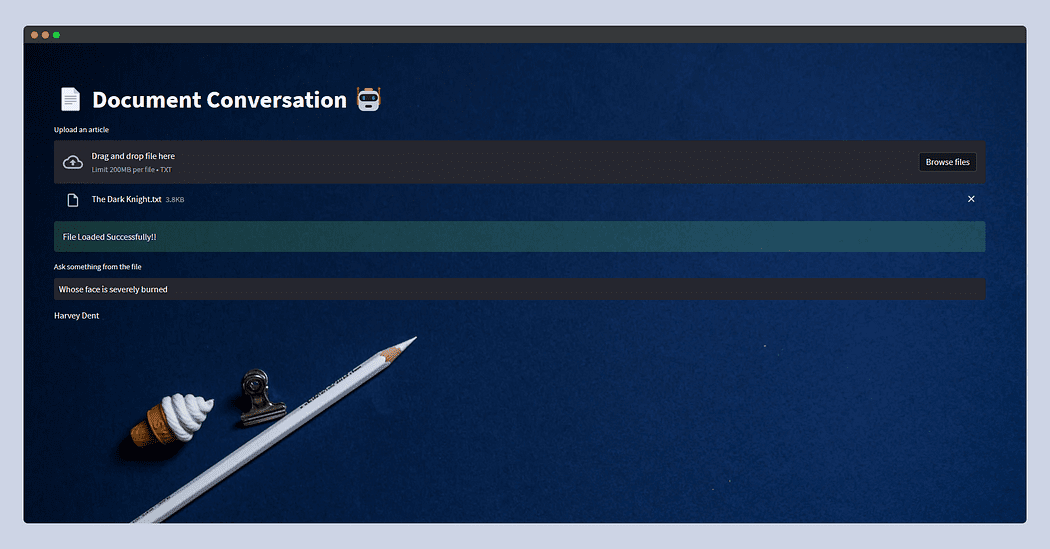
Esta vez alimenté la trama de El caballero oscuro copiado de Wiki y solo preguntó ¿De quién es la cara gravemente quemada? y el LLM respondió: Harvey Dent.
¡Está bien, está bien, está bien! Con esto llegamos al final de este blog.
¡Espero que hayas disfrutado este artículo! y lo encontró informativo y atractivo. Puede Sígueme Afaque Umer para más, tales artículos
intentaré sacar más Maprendizaje automático/conceptos de ciencia de datos y tratará de dividir los términos y conceptos que suenan sofisticados en otros más simples.
Afaque Umer es un ingeniero de aprendizaje automático apasionado. Le encanta enfrentar nuevos desafíos utilizando la última tecnología para encontrar soluciones eficientes. ¡Superemos los límites de la IA juntos!
Original. Publicado de nuevo con permiso.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/08/langchain-streamlit-llama-bringing-conversational-ai-local-machine.html?utm_source=rss&utm_medium=rss&utm_campaign=langchain-streamlit-llama-bringing-conversational-ai-to-your-local-machine

