
En el campo de la inteligencia artificial, que evoluciona rápidamente, el procesamiento del lenguaje natural se ha convertido en un punto central para investigadores y desarrolladores por igual. Construyendo sobre los cimientos de Arquitectura transformadora y Actualización bidireccional de BERT, han surgido varios modelos de lenguaje innovadores en los últimos años, ampliando los límites de lo que las máquinas pueden comprender y generar.
En este artículo, profundizaremos en los últimos avances en el mundo de los modelos de lenguaje a gran escala, explorando las mejoras introducidas por cada modelo, sus capacidades y aplicaciones potenciales. También analizaremos los modelos de lenguaje visual (VLM) que están capacitados para procesar no solo datos textuales sino también visuales.
Si desea saltear, estos son los modelos de lenguaje que presentamos:
- GPT-3 de OpenAI
- LaMDA de Google
- PaLM de Google
- Flamenco de DeepMind
- BLIP-2 de Salesforce
- LLaMA de Meta AI
- GPT-4 de OpenAI
Si este contenido educativo en profundidad es útil para usted, puede suscríbete a nuestra lista de correo de investigación de IA ser alertado cuando lancemos nuevo material.
Los modelos de lenguaje grande (LLM) y los modelos de lenguaje visual (VLM) más importantes en 2023
1. GPT-3 por OpenAI
Resumen
El equipo de OpenAI presentó GPT-3 como una alternativa a tener un conjunto de datos etiquetado para cada nueva tarea de idioma. Sugirieron que la ampliación de los modelos de lenguaje puede mejorar el rendimiento de pocos intentos independientes de la tarea. Para probar esta sugerencia, entrenaron un modelo de lenguaje autorregresivo de parámetros 175B, llamado GPT-3, y evaluó su desempeño en más de dos docenas de tareas de PNL. La evaluación bajo aprendizaje de pocos disparos, aprendizaje de un solo disparo y aprendizaje de disparo cero demostró que GPT-3 logró resultados prometedores e incluso superó ocasionalmente los resultados de vanguardia logrados por modelos ajustados.
Cual es el objetivo?
- Sugerir una solución alternativa al problema existente, cuando se necesita un conjunto de datos etiquetados para cada nueva tarea de lenguaje.
¿Cómo se aborda el problema?
- Los investigadores sugirieron ampliar los modelos de lenguaje para mejorar el rendimiento de pocos disparos independiente de la tarea.
- El GPT-3 model utiliza el mismo modelo y arquitectura que GPT-2, incluida la inicialización modificada, la normalización previa y la tokenización reversible.
- Sin embargo, en contraste con GPT-2, utiliza patrones de atención dispersos alternados densos y localizados en bandas en las capas del transformador, como en el Transformador escaso.
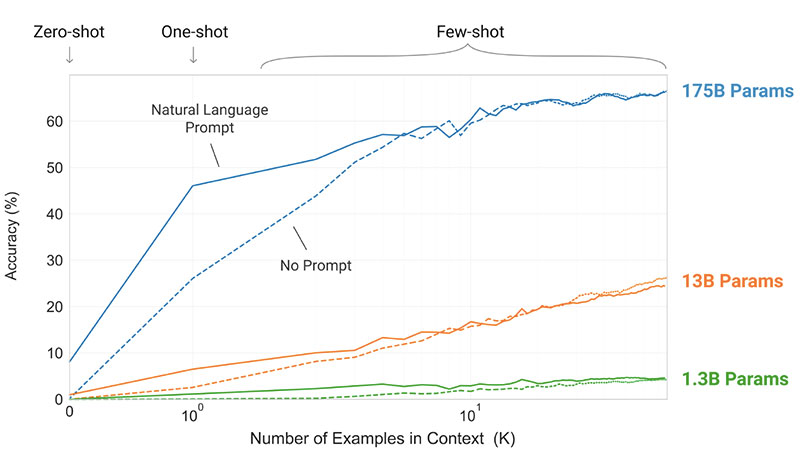
¿Cuáles son los resultados?
- El modelo GPT-3 sin ajuste fino logra resultados prometedores en una serie de tareas de PNL, e incluso ocasionalmente supera los modelos más avanzados que se ajustaron para esa tarea específica:
- En CoQA punto de referencia, 81.5 F1 en la configuración de disparo cero, 84.0 F1 en la configuración de un disparo y 85.0 F1 en la configuración de pocos disparos, en comparación con la puntuación de 90.7 F1 lograda por el SOTA ajustado.
- En Trivia QA punto de referencia, 64.3% de precisión en el ajuste de disparo cero, 68.0% en el ajuste de disparo único y 71.2% en el ajuste de pocos disparos, superando el estado del arte (68%) en un 3.2%.
- En LAMBADA conjunto de datos, 76.2% de precisión en el ajuste de disparo cero, 72.5% en el ajuste de disparo único y 86.4% en el ajuste de disparo reducido, superando el estado del arte (68%) en un 18%.
- Los artículos de noticias generados por el modelo GPT-175 de parámetro 3B son difíciles de distinguir de los reales, según evaluaciones humanas (con una precisión apenas por encima del nivel de probabilidad de ~ 52%).
- A pesar del notable desempeño de GPT-3, recibió críticas mixtas de la comunidad de IA:
- “El bombo publicitario de GPT-3 es demasiado. Es impresionante (¡gracias por los bonitos cumplidos!), Pero todavía tiene serias debilidades y, a veces, comete errores muy tontos. La IA va a cambiar el mundo, pero GPT-3 es solo un primer vistazo. Todavía tenemos mucho que resolver ". - Sam Altman, director ejecutivo y cofundador de OpenAI.
- "Me sorprende lo difícil que es generar un texto sobre musulmanes a partir de GPT-3 que no tenga nada que ver con la violencia ... o ser asesinado ..." - Abubakar Abid, CEO y fundador de Gradio.
- "No. GPT-3 fundamentalmente no comprende el mundo del que habla. Aumentar aún más el corpus le permitirá generar un pastiche más creíble pero no solucionará su falta fundamental de comprensión del mundo. Las demostraciones de GPT-4 seguirán requiriendo una selección humana ". - Gary Marcus, director ejecutivo y fundador de Robust.ai.
- "Extrapolar el espectacular rendimiento de GPT3 al futuro sugiere que la respuesta a la vida, el universo y todo es solo 4.398 billones de parámetros". - Geoffrey Hinton, ganador del premio Turing.
¿Dónde obtener más información sobre esta investigación?
¿Dónde puede obtener el código de implementación?
- El código en sí no está disponible, pero algunas estadísticas de conjuntos de datos junto con muestras de 2048 tokens incondicionales y sin filtrar de GPT-3 se publican el GitHub.
2. LaMDA de Google
Resumen
Laidioma Mmodelos para Ddiálogo Aaplicaciones (LAMDA) se crearon a través del proceso de ajuste de un grupo de modelos de lenguaje neuronal basados en Transformer que están diseñados específicamente para diálogos. Estos modelos tienen un máximo de parámetros 137B y fueron entrenados para usar fuentes externas de conocimiento. Los desarrolladores de LaMDA tenían tres objetivos clave en mente: calidad, seguridad y conexión a tierra. Los resultados demostraron que el ajuste fino permite reducir la brecha de calidad a niveles humanos, pero el rendimiento del modelo se mantuvo por debajo de los niveles humanos con respecto a la seguridad y la conexión a tierra.
bardo de google, liberado recientemente como una alternativa a ChatGPT, funciona con LaMDA. A pesar de que Bard es a menudo etiquetado como aburrido, podría verse como una prueba del compromiso de Google de priorizar la seguridad, incluso en medio de la intensa rivalidad entre Google y Microsoft para establecer el dominio en el campo de la IA generativa.
Cual es el objetivo?
- Construir un modelo para aplicaciones de diálogo de dominio abierto, donde un agente de diálogo puede conversar sobre cualquier tema con respuestas sensatas, específicas para el contexto, basadas en fuentes confiables y éticas.
¿Cómo se aborda el problema?
- LaMDA se basa en transformador, una arquitectura de red neuronal que Google Research inventó y abrió en código abierto en 2017.
- Al igual que otros modelos de lenguaje grandes, incluidos BERT y GPT-3, LaMDA se entrena en terabytes de datos de texto para aprender cómo se relacionan las palabras entre sí y luego predecir qué palabras es probable que aparezcan a continuación.
- Sin embargo, a diferencia de la mayoría de los modelos de lenguaje, LaMDA fue entrenado en diálogo para captar los matices que distinguen una conversación abierta de otras formas de lenguaje.
- El modelo también se ajusta para mejorar la sensatez, la seguridad y la especificidad de sus respuestas. Si bien frases como "eso está bien" y "no sé" pueden ser significativas en muchos escenarios de diálogo, es poco probable que conduzcan a conversaciones interesantes y atractivas.
- El generador de LaMDA primero genera varias respuestas candidatas, que se califican según su seguridad, sensibilidad, especificidad e interés. Las respuestas con puntajes de seguridad bajos se filtran y luego se selecciona el resultado mejor clasificado como respuesta.
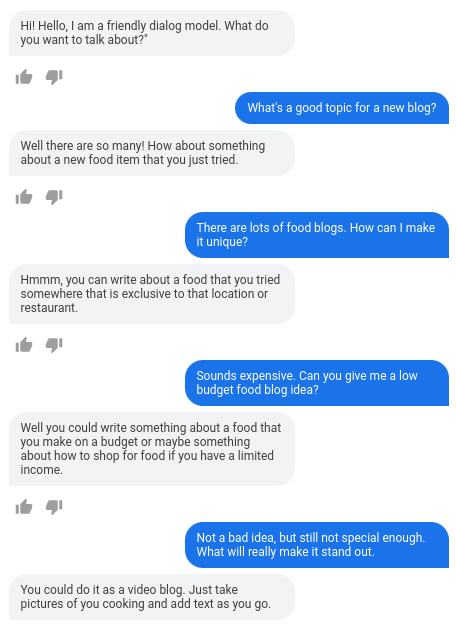
¿Cuáles son los resultados?
- Numerosos experimentos muestran que LaMDA puede participar en conversaciones abiertas sobre una variedad de temas.
- Una serie de evaluaciones cualitativas confirmaron que las respuestas del modelo tienden a ser sensatas, específicas, interesantes y basadas en fuentes externas confiables, pero aún hay margen de mejora.
- A pesar de todos los avances realizados hasta el momento, los autores reconocen que el modelo aún tiene muchas limitaciones que pueden generar respuestas inapropiadas o incluso dañinas.
¿Dónde obtener más información sobre esta investigación?
¿Dónde puede obtener el código de implementación?
- Una implementación PyTorch de código abierto para la arquitectura previa al entrenamiento de LaMDA está disponible en GitHub.
3. PaLM de Google
Resumen
Pade todos modos Lel idioma MModelo (Palmera) es un modelo de lenguaje basado en Transformer de 540 mil millones de parámetros. PaLM se capacitó en chips 6144 TPU v4 utilizando Pathways, un nuevo sistema ML para una capacitación eficiente en múltiples pods de TPU. El modelo demuestra los beneficios de escalar en el aprendizaje de pocos disparos, logrando resultados de vanguardia en cientos de puntos de referencia de comprensión y generación de idiomas. PaLM supera a los modelos de última generación en tareas de razonamiento de varios pasos y supera el rendimiento humano promedio en el punto de referencia de BIG-bench.
Cual es el objetivo?
- Para mejorar la comprensión de cómo la escala de modelos de lenguaje grandes afecta el aprendizaje de pocos intentos.
¿Cómo se aborda el problema?
- La idea clave es escalar el entrenamiento de un modelo de lenguaje de 540 mil millones de parámetros con el sistema Pathways:
- El equipo estaba usando el paralelismo de datos a nivel de pod en dos pods de Cloud TPU v4 mientras usaba datos estándar y paralelismo de modelos dentro de cada pod.
- Pudieron escalar la capacitación a 6144 chips TPU v4, la configuración de sistema basada en TPU más grande utilizada para la capacitación hasta la fecha.
- El modelo logró una eficiencia de entrenamiento del 57.8 % de uso de FLOP de hardware, que, como afirman los autores, es la eficiencia de entrenamiento más alta hasta ahora lograda para modelos de lenguaje grande a esta escala.
- Los datos de entrenamiento para el modelo PaLM incluyeron una combinación de conjuntos de datos en inglés y multilingües que contenían documentos web de alta calidad, libros, Wikipedia, conversaciones y código GitHub.
¿Cuáles son los resultados?
- Numerosos experimentos demuestran que el rendimiento del modelo aumentó considerablemente a medida que el equipo escaló a su modelo más grande.
- PaLM 540B logró un rendimiento innovador en múltiples tareas muy difíciles:
- Comprensión y generación del lenguaje.. El modelo introducido superó el rendimiento de pocos disparos de los modelos grandes anteriores en 28 de 29 tareas que incluyen tareas de preguntas y respuestas, tareas de finalización de oraciones y cloze, tareas de comprensión de lectura en contexto, tareas de razonamiento de sentido común, tareas SuperGLUE y más. El desempeño de PaLM en las tareas de BIG-bench demostró que podía distinguir causa y efecto, así como comprender combinaciones conceptuales en contextos apropiados.
- Razonamiento. Con indicaciones de 8 disparos, PaLM resuelve el 58 % de los problemas en GSM8K, un punto de referencia de miles de preguntas matemáticas desafiantes de nivel escolar, superando el puntaje máximo anterior del 55 % logrado al ajustar el modelo GPT-3 175B. PaLM también demuestra la capacidad de generar explicaciones explícitas en situaciones que requieren una combinación compleja de inferencia lógica de varios pasos, conocimiento del mundo y comprensión profunda del lenguaje.
- Codigo de GENERACION. PaLM funciona a la par con el Codex 12B perfeccionado mientras usa 50 veces menos código Python para el entrenamiento, lo que confirma que los modelos de lenguaje grandes transfieren el aprendizaje de otros lenguajes de programación y datos de lenguaje natural de manera más efectiva.
¿Dónde obtener más información sobre esta investigación?
¿Dónde puede obtener el código de implementación?
- Una implementación no oficial de PyTorch de la arquitectura Transformer específica del trabajo de investigación de PaLM está disponible en GitHub. No se escalará y se publica solo con fines educativos.
4. Flamenco de DeepMind
Resumen
Flamingo es una familia de modelos de lenguaje visual (VLM) de vanguardia, formada en corpus web multimodal a gran escala con texto e imágenes mixtos. Con esta capacitación, los modelos pueden adaptarse a nuevas tareas utilizando ejemplos mínimos anotados, proporcionados como un aviso. Flamingo incorpora avances arquitectónicos clave diseñados para fusionar las fortalezas de los modelos de solo visión y solo de lenguaje preentrenados, procesar secuencias de datos visuales y textuales intercalados de forma variable y acomodar imágenes o videos como entradas sin problemas. Los modelos demuestran una adaptabilidad impresionante a una variedad de tareas de imágenes y videos, como respuestas a preguntas visuales, tareas de subtítulos y respuestas a preguntas visuales de opción múltiple, lo que establece nuevos estándares de rendimiento utilizando indicaciones específicas de tareas en el aprendizaje de pocas tomas.
Cual es el objetivo?
- Para avanzar hacia la habilitación de modelos multimodales para aprender y realizar rápidamente nuevas tareas basadas en instrucciones breves:
- El paradigma ampliamente utilizado de entrenar previamente un modelo en una gran cantidad de datos supervisados, y luego ajustarlo para la tarea específica, consume muchos recursos y requiere miles de puntos de datos anotados junto con un ajuste cuidadoso de hiperparámetros por tarea.
- Los modelos actuales que utilizan un objetivo contrastivo permiten una adaptación de tiro cero a nuevas tareas, pero se quedan cortos en tareas más abiertas como subtítulos o respuesta visual a preguntas porque carecen de capacidades de generación de lenguaje.
- Esta investigación tiene como objetivo introducir un nuevo modelo que aborde de manera efectiva estos problemas y demuestre un rendimiento superior en regímenes de datos bajos.
¿Cómo se aborda el problema?
- DeepMind presentó Flamingo, VLM diseñados para el aprendizaje de pocas tomas en varias tareas de lenguaje y visión abiertas, usando solo unos pocos ejemplos de entrada/salida.
- Los modelos Flamingo son modelos de generación de texto autorregresivos acondicionados visualmente que pueden procesar tokens de texto mezclados con imágenes y/o videos y generar texto como salida.
- La arquitectura de Flamingo incorpora dos modelos preentrenados y congelados complementarios:
- Un modelo de visión capaz de “percibir” escenas visuales.
- Un gran modelo de lenguaje encargado de realizar un razonamiento básico.
- Los nuevos componentes de arquitectura integran estos modelos de una manera que retiene el conocimiento adquirido durante su pre-entrenamiento computacionalmente intensivo.
- Además, los modelos Flamingo cuentan con una arquitectura basada en Perceiver, lo que les permite ingerir imágenes o videos de alta resolución. Esta arquitectura puede generar una cantidad fija de tokens visuales por imagen/video a partir de una variedad amplia y variable de funciones de entrada visual.
¿Cuáles son los resultados?
- La investigación muestra que, de manera similar a los LLM, que son buenos estudiantes de pocas tomas, los VLM pueden aprender de algunos ejemplos de entrada/salida para tareas de comprensión de imágenes y videos, como clasificación, subtítulos o respuesta a preguntas.
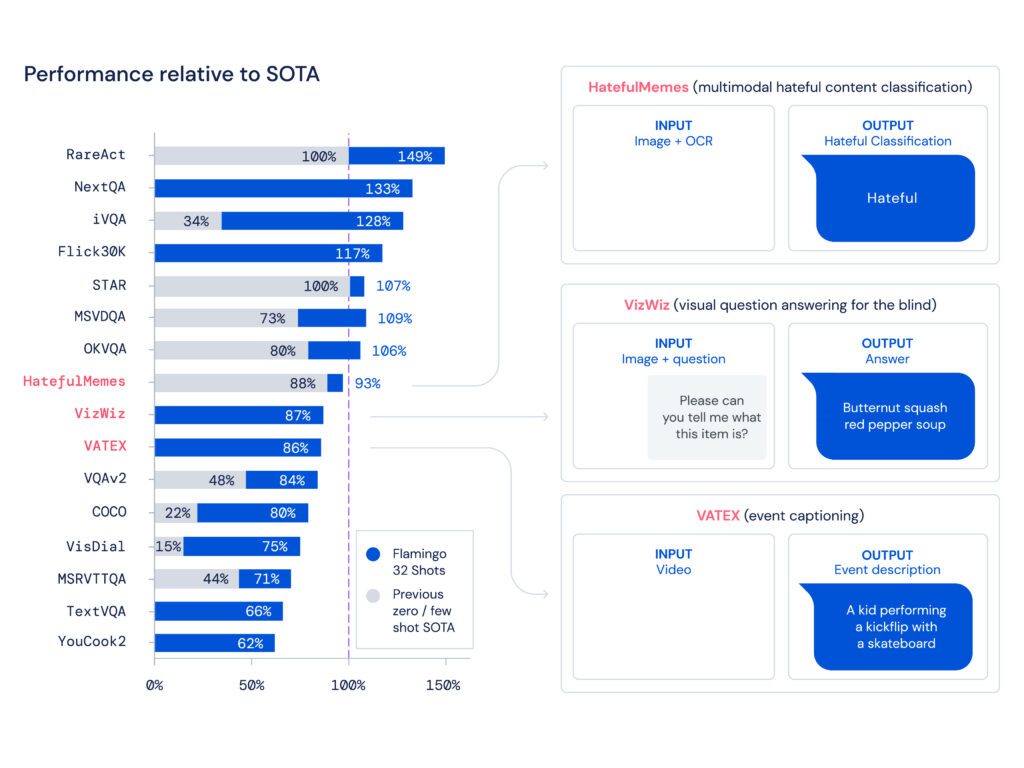
- Flamingo establece un nuevo punto de referencia en el aprendizaje de pocas tomas, demostrando un rendimiento superior en una amplia gama de 16 tareas multimodales de comprensión de idiomas e imágenes/videos.
- Para 6 de estas 16 tareas, Flamingo supera el rendimiento del estado del arte perfeccionado, a pesar de que utiliza solo 32 ejemplos específicos de tareas, aproximadamente 1000 veces menos datos de capacitación específicos de tareas que los modelos actuales de mayor rendimiento.
¿Dónde obtener más información sobre esta investigación?
¿Dónde puede obtener el código de implementación?
- DeepMind no publicó la implementación oficial de Flamingo.
- Puede encontrar una implementación de código abierto del enfoque presentado en el Repositorio OpenFlamingo Github.
- La implementación alternativa de PyTorch está disponible esta página.
5. BLIP-2 de Salesforce
Resumen
BLIP-2 es un marco de preentrenamiento eficiente y genérico para modelos de visión y lenguaje, diseñado para eludir el costo cada vez más prohibitivo del preentrenamiento de modelos a gran escala. BLIP-2 aprovecha los codificadores de imagen preentrenados congelados listos para usar y los modelos de lenguaje grande congelados para iniciar el entrenamiento previo de visión-lenguaje, incorporando un transformador de consulta liviano preentrenado en dos etapas. La primera etapa inicia el aprendizaje de representación de visión-lenguaje a partir de un codificador de imagen congelado, y la segunda etapa impulsa el aprendizaje generativo de visión a lenguaje a partir de un modelo de lenguaje congelado. A pesar de tener significativamente menos parámetros entrenables, BLIP-2 supera a los métodos más avanzados, superando a Flamingo80B de DeepMind en un 8.7 % en VQAv2 de disparo cero con 54 veces menos parámetros entrenables. El modelo también exhibe prometedoras capacidades de generación de imagen a texto sin disparo siguiendo instrucciones en lenguaje natural.
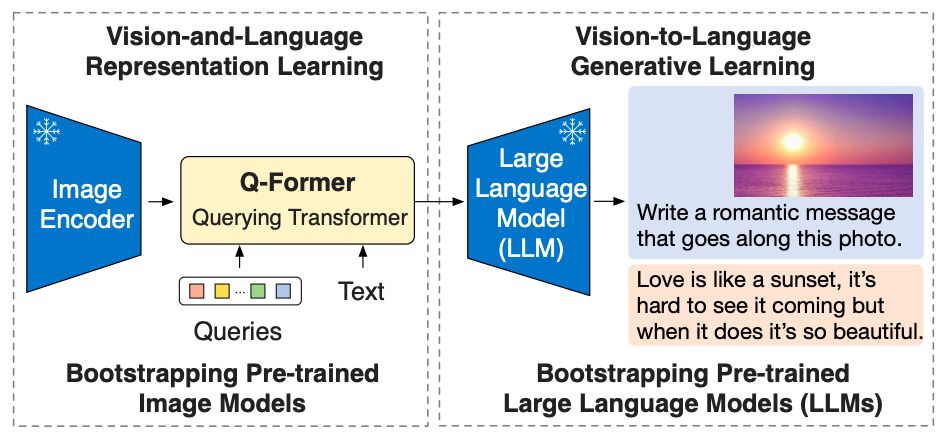
Cual es el objetivo?
- Para obtener un rendimiento de última generación en tareas de lenguaje de visión, al tiempo que reduce los costos de cómputo.
¿Cómo se aborda el problema?
- El equipo de Salesforce presentó un nuevo marco de precapacitación de lenguaje de visión denominado BLIP-2, Barrancando Lidioma-Imago Preentrenamiento con modelos unimodales congelados:
- Los modelos unimodales preentrenados permanecen congelados durante el preentrenamiento para reducir el costo de cómputo y evitar el problema del olvido catastrófico.
- Para facilitar la alineación intermodal y cerrar la brecha de modalidad entre los modelos de visión preentrenados y los modelos de lenguaje preentrenados, el equipo propone un transformador de consulta liviano (Q-Former) que actúa como un cuello de botella de información entre el codificador de imágenes congeladas y el congelador. LLM.
- Q-former está pre-entrenado con una nueva estrategia de dos etapas:
- La primera etapa de pre-entrenamiento realiza el aprendizaje de la representación visión-lenguaje. Esto obliga al Q-Former a aprender la representación visual más relevante para el texto.
- La segunda etapa de pre-entrenamiento lleva a cabo un aprendizaje generativo de visión a lenguaje al conectar la salida del Q-Former a un LLM congelado. El Q-Former está entrenado para que su representación visual de salida pueda ser interpretada por el LLM.
¿Cuáles son los resultados?
- BLIP-2 ofrece resultados excepcionales y de última generación en una variedad de tareas de visión y lenguaje, que abarcan respuestas visuales a preguntas, subtítulos de imágenes y recuperación de texto de imágenes.
- Por ejemplo, supera a Flamingo en un 8.7 % en VQAv2 de disparo cero.
- Además, este excelente rendimiento se logra con una eficiencia informática significativamente mayor:
- BLIP-2 supera a Flamingo-80B mientras usa 54 veces menos parámetros entrenables.
- BLIP-2 tiene la capacidad de realizar una generación de imagen a texto sin disparo en respuesta a instrucciones en lenguaje natural, allanando así el camino para desarrollar habilidades como el razonamiento del conocimiento visual y la conversación visual, entre otras.
- Finalmente, es importante tener en cuenta que BLIP-2 es un enfoque versátil que puede aprovechar modelos unimodales más sofisticados para mejorar aún más el rendimiento del preentrenamiento de visión y lenguaje.
¿Dónde obtener más información sobre esta investigación?
¿Dónde puede obtener el código de implementación?
La implementación oficial de BLIP-2 está disponible en GitHub.
6. LLaMA por Meta AI
Resumen
El equipo de Meta AI afirma que los modelos más pequeños entrenados en más tokens son más fáciles de volver a entrenar y ajustar para aplicaciones de productos específicos. Por lo tanto, introducen Llama (Large Laidioma MModelo Meta AI), una colección de modelos de lenguaje fundamentales con parámetros 7B a 65B. LLaMA 33B y 65B se entrenaron con 1.4 billones de tokens, mientras que el modelo más pequeño, LLaMA 7B, se entrenó con un billón de tokens. Utilizaron exclusivamente conjuntos de datos disponibles públicamente, sin depender de datos propietarios o restringidos. El equipo también implementó mejoras arquitectónicas clave y técnicas de optimización de la velocidad de entrenamiento. En consecuencia, LLaMA-13B superó a GPT-3, siendo 10 veces más pequeño, y LLaMA-65B exhibió un rendimiento competitivo con PaLM-540B.
Cual es el objetivo?
- Demostrar la viabilidad de entrenar modelos de alto rendimiento únicamente en conjuntos de datos de acceso público, sin depender de fuentes de datos propietarias o restringidas.
- Proporcionar a la comunidad de investigación modelos más pequeños y de mayor rendimiento y, por lo tanto, permitir que aquellos que no tienen acceso a grandes cantidades de infraestructura estudien modelos de lenguaje grandes.
¿Cómo se aborda el problema?
- Para entrenar el modelo LLaMA, los investigadores solo usaron datos que están disponibles públicamente y son compatibles con el código abierto.
- También han introducido algunas mejoras en la arquitectura estándar de Transformer:
- Al adoptar la metodología GPT-3, se mejoró la estabilidad del entrenamiento al normalizar la entrada para cada subcapa del transformador, en lugar de normalizar la salida.
- Inspirándose en los modelos PaLM, los investigadores reemplazaron la no linealidad ReLU con la función de activación SwiGLU para mejorar el rendimiento.
- Inspirado por thesuburbansoapbox.com Su et al (2021), eliminaron las incrustaciones posicionales absolutas y, en su lugar, incorporaron incrustaciones posicionales rotativas (RoPE) en cada capa de la red.
- Finalmente, el equipo de Meta AI mejoró la velocidad de entrenamiento de su modelo al:
- Uso de una implementación de atención multicabezal causal eficiente al no almacenar ponderaciones de atención ni calcular puntuaciones de consultas/claves enmascaradas.
- Uso de puntos de control para minimizar las activaciones recalculadas durante el pase hacia atrás.
- Superposición del cómputo de activaciones y la comunicación entre GPU a través de la red (debido a las operaciones all_reduce).
¿Cuáles son los resultados?
- LLaMA-13B supera a GPT-3 a pesar de ser 10 veces más pequeño, mientras que LLaMA-65B se mantiene firme frente a PaLM-540B.
¿Dónde obtener más información sobre esta investigación?
¿Dónde puede obtener el código de implementación?
- Meta AI brinda acceso a LLaMA a investigadores académicos, personas asociadas con el gobierno, la sociedad civil, instituciones académicas y laboratorios de investigación de la industria global sobre la base de una evaluación de casos individuales. Para aplicar, vaya a la siguiente Repositorio GitHub.
7. GPT-4 por OpenAI
Resumen
GPT-4 es un modelo multimodal a gran escala que acepta entradas de imagen y texto y genera salidas de texto. Debido a problemas de competencia y seguridad, se retienen detalles específicos sobre la arquitectura y el entrenamiento del modelo. En términos de rendimiento, GPT-4 supera los modelos de lenguaje anteriores en los puntos de referencia tradicionales y muestra mejoras significativas en la comprensión de la intención del usuario y las propiedades de seguridad. El modelo también logra un rendimiento a nivel humano en varios exámenes, incluido un puntaje máximo del 10 % en un examen de barra uniforme simulado.
Cual es el objetivo?
- Desarrollar un modelo multimodal a gran escala que pueda aceptar entradas de imágenes y texto y producir salidas de texto.
- Desarrollar infraestructura y métodos de optimización que se comporten de manera predecible en una amplia gama de escalas.
¿Cómo se aborda el problema?
- Debido al panorama competitivo y las implicaciones de seguridad, OpenAI decidió ocultar detalles sobre arquitectura, tamaño del modelo, hardware, cómputo de entrenamiento, construcción de conjuntos de datos y métodos de entrenamiento.
- Revelan que:
- GPT-4 es un modelo basado en Transformer, entrenado previamente para predecir el siguiente token en un documento.
- Utiliza datos disponibles públicamente y datos con licencia de terceros.
- El modelo se ajustó utilizando el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF).
- La información no confirmada sugiere que GPT-4 no es un modelo denso singular como sus predecesores, sino una poderosa coalición de ocho modelos separados, cada uno con la asombrosa cantidad de 220 mil millones de parámetros.
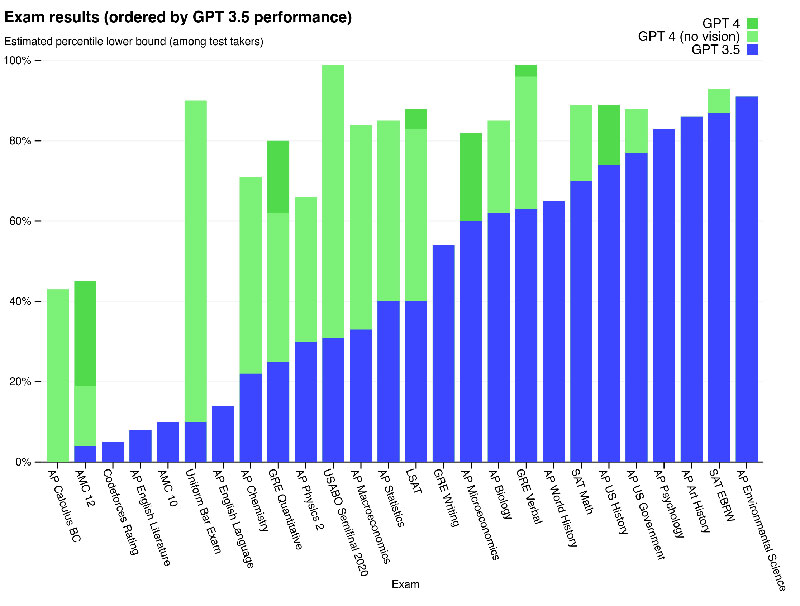
¿Cuáles son los resultados?
- GPT-4 logra un rendimiento a nivel humano en la mayoría de los exámenes profesionales y académicos, en particular con un puntaje en el 10% superior en un examen de barra uniforme simulado.
- El modelo base GPT-4 preentrenado supera los modelos de lenguaje existentes y los sistemas de vanguardia anteriores en los puntos de referencia tradicionales de NLP, sin elaboración específica de puntos de referencia ni protocolos de capacitación adicionales.
- GPT-4 demuestra una mejora sustancial en el seguimiento de la intención del usuario, con sus respuestas preferidas sobre las respuestas de GPT-3.5 en el 70.2 % de las 5,214 indicaciones de ChatGPT y la API de OpenAI.
- Las propiedades de seguridad de GPT-4 han mejorado significativamente en comparación con GPT-3.5, con una disminución del 82 % en la respuesta a solicitudes de contenido no permitido y un aumento del 29 % en el cumplimiento de las políticas para solicitudes confidenciales (p. ej., asesoramiento médico y autolesiones).
¿Dónde obtener más información sobre esta investigación?
¿Dónde puede obtener el código de implementación?
- La implementación del código de GPT-4 no está disponible.
Aplicaciones del mundo real de modelos de lenguaje grandes (de visión)
Los avances más significativos en investigación de IA de los últimos años provienen de grandes modelos de IA entrenados en grandes conjuntos de datos. Estos modelos demuestran un rendimiento impresionante y es fascinante pensar cómo la IA puede revolucionar industrias enteras, como servicio al cliente, marketing, comercio electrónico, atención médica, desarrollo de software, periodismo y muchas otras.
Los modelos de lenguaje grande tienen numerosas aplicaciones en el mundo real. GPT-4 enumera lo siguiente:
- Comprensión y generación de lenguaje natural para chatbots y asistentes virtuales.
- Traducción automática entre idiomas.
- Resumen de artículos, informes u otros documentos de texto.
- Análisis de sentimiento para investigación de mercado o monitoreo de redes sociales.
- Generación de contenido para marketing, redes sociales o escritura creativa.
- Sistemas de preguntas y respuestas para atención al cliente o bases de conocimiento.
- Clasificación de texto para filtrado de spam, categorización de temas u organización de documentos.
- Herramientas personalizadas de aprendizaje y tutoría de idiomas.
- Asistencia en generación de código y desarrollo de software.
- Análisis y asistencia de documentos médicos, legales y técnicos.
- Herramientas de accesibilidad para personas con discapacidades, como conversión de texto a voz y de voz a texto.
- Servicios de transcripción y reconocimiento de voz.
Si añadimos una parte visual, las áreas de posibles aplicaciones se amplían aún más:
Es muy emocionante seguir los avances recientes de la IA y pensar en sus posibles aplicaciones en el mundo real. Sin embargo, antes de implementar estos modelos en la vida real, debemos abordar los riesgos y limitaciones correspondientes, que desafortunadamente son bastante importantes.
Riesgos y limitaciones
Si le pregunta a GPT-4 sobre sus riesgos y limitaciones, es probable que le proporcione una larga lista de inquietudes relevantes. Después de filtrar esta lista y agregar algunas consideraciones adicionales, terminé con el siguiente conjunto de riesgos y limitaciones clave que poseen los modelos modernos de lenguaje grande:
- Sesgo y discriminación: estos modelos aprenden de grandes cantidades de datos de texto, que a menudo contienen sesgos y contenido discriminatorio. Como resultado, los resultados generados pueden perpetuar sin querer estereotipos, lenguaje ofensivo y discriminación basada en factores como el género, la raza o la religión.
- Desinformación: Los modelos de lenguaje extenso pueden generar contenido que sea incorrecto, engañoso o desactualizado. Si bien los modelos se entrenan en una amplia gama de fuentes, es posible que no siempre proporcionen la información más precisa o actualizada. A menudo, esto sucede porque el modelo prioriza la generación de resultados que sean gramaticalmente correctos o parezcan coherentes, incluso si son engañosos.
- Falta de entendimiendo: Aunque estos modelos parecen comprender el lenguaje humano, funcionan principalmente mediante la identificación de patrones y asociaciones estadísticas en los datos de entrenamiento. No tienen una comprensión profunda del contenido que generan, lo que a veces puede resultar en resultados sin sentido o irrelevantes.
- Contenido inapropiado: Los modelos de lenguaje a veces pueden generar contenido ofensivo, dañino o inapropiado. Si bien se hacen esfuerzos para minimizar dicho contenido, aún puede ocurrir debido a la naturaleza de los datos de entrenamiento y la incapacidad de los modelos para discernir el contexto o la intención del usuario.
Conclusión
Sin duda, los grandes modelos de lenguaje han revolucionado el campo del procesamiento del lenguaje natural y han demostrado un inmenso potencial para mejorar la productividad en varios roles e industrias. Su capacidad para generar texto similar al humano, automatizar tareas mundanas y brindar asistencia en procesos creativos y analíticos los ha convertido en herramientas indispensables en el mundo acelerado e impulsado por la tecnología de hoy.
Sin embargo, es crucial reconocer y comprender las limitaciones y los riesgos asociados con estos poderosos modelos. No se pueden ignorar problemas como el sesgo, la información errónea y el potencial de uso malicioso. A medida que continuamos integrando estas tecnologías impulsadas por IA en nuestra vida diaria, es esencial lograr un equilibrio entre aprovechar sus capacidades y garantizar la supervisión humana, particularmente en situaciones delicadas y de alto riesgo.
Si logramos adoptar tecnologías de IA generativa de manera responsable, allanaremos el camino para un futuro en el que la inteligencia artificial y la experiencia humana trabajen juntas para impulsar la innovación y crear un mundo mejor para todos.
¿Disfrutas este artículo? Regístrese para obtener más actualizaciones de investigación de IA.
Le informaremos cuando publiquemos más artículos de resumen como este.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.topbots.com/top-language-models-transforming-ai-in-2023/

