
En el ámbito de la IA generativa, los proyectos de código abierto se han convertido en herramientas poderosas que democratizan el acceso a modelos de vanguardia y fomentan el desarrollo colaborativo. Permiten a los investigadores, desarrolladores y entusiastas experimentar, mejorar los modelos existentes y crear aplicaciones novedosas que benefician a la sociedad en su conjunto.
En este artículo, quiero revisar brevemente los proyectos clave de código abierto y analizar su potencial y los riesgos de seguridad.
Hugging Face: un centro de modelos de IA de código abierto
Abrazando la cara se destaca como un centro principal para modelos de código abierto en varios dominios de IA. Al albergar más de 200,000 XNUMX modelos, cierra la brecha entre la investigación académica y las aplicaciones de la industria. Los modelos son aportados por líderes tecnológicos como Meta, Microsoft, Google y OpenAI, así como por investigadores de todo el mundo.
En particular, Hugging Face se extiende más allá de los modelos de alojamiento. Tiene un conjunto de sus propias bibliotecas, como las bibliotecas de transformadores y difusores, que se adaptan a una variedad de tareas.
- Transformers biblioteca proporciona API y herramientas para descargar y entrenar fácilmente modelos preentrenados de última generación. Estos modelos soportan tareas comunes en diferentes modalidades, tales como:
- Procesamiento del lenguaje natural: clasificación de texto, reconocimiento de entidades nombradas, respuesta a preguntas, modelado de lenguaje, resumen, traducción, opción múltiple y generación de texto.
- Visión artificial: clasificación de imágenes, detección de objetos y segmentación.
- Audio: reconocimiento automático de voz y clasificación de audio.
- Multimodal: respuesta a preguntas en tablas, reconocimiento óptico de caracteres, extracción de información de documentos escaneados, clasificación de videos y respuesta visual a preguntas.
- Difusores La biblioteca proporciona modelos de difusión de audio y visión preentrenados, y sirve como una caja de herramientas modular para la inferencia y el entrenamiento. Más precisamente, Difusores ofrece:
- difusión de última generación tuberías que se puede ejecutar en inferencia con solo un par de líneas de código;
- varios ruidos programadores que se puede usar indistintamente para el equilibrio preferido entre velocidad y calidad en la inferencia;
- múltiples tipos de modelos, como UNet, se pueden utilizar como componentes básicos en un sistema de difusión de extremo a extremo.
- Formación ejemplos para mostrar cómo entrenar las tareas del modelo de difusión más populares.
- En su último desarrollo, Hugging Face ha introducido AbrazosChat, su propio chatbot. La interfaz es muy similar a ChatGPT pero también verá el enlace a el modelo utilizado para este chatbot (basado en LLaMA) y el correspondiente página del conjunto de datos. Además, Chat UI también es de código abierto en GitHub.
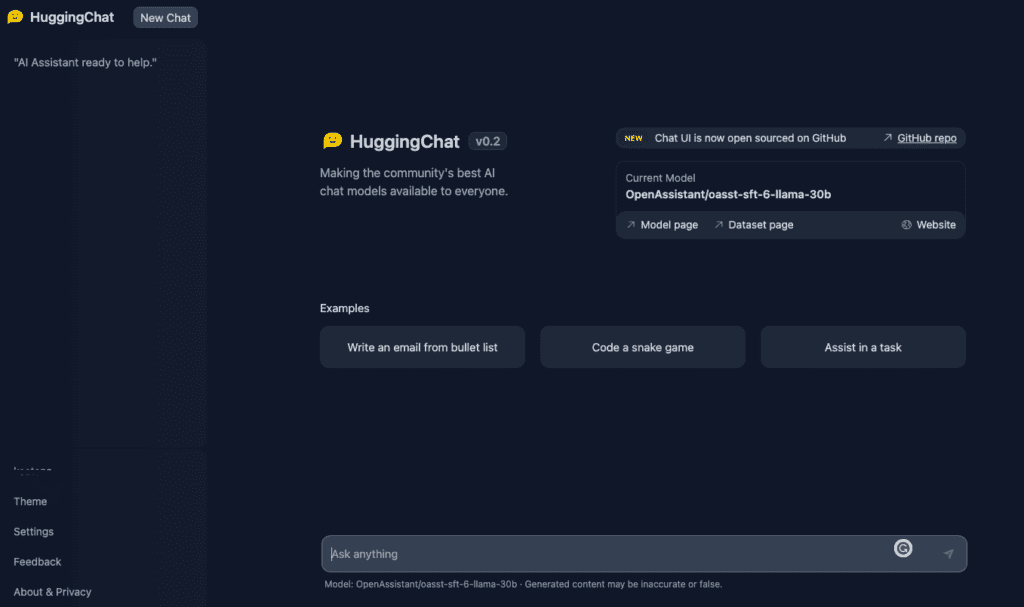
- Tenga en cuenta que Hugging Face aplica un mecanismo de acceso en el que las personas deben solicitar acceso y recibir aprobación antes de descargar numerosos modelos de la plataforma de la empresa. El objetivo es limitar el acceso únicamente a aquellas personas que puedan proporcionar una justificación válida, según lo determinado por Hugging Face, para obtener el modelo.
IA de estabilidad: la nueva frontera
Estabilidad IA, otro jugador crucial en el ámbito de la IA de código abierto, ofrece un conjunto de modelos de código abierto para la generación de texto e imágenes.
- Difusión estable – un conjunto de modelos de código abierto para la generación de texto a imagen.
- Deep Floyd SI – un poderoso modelo de texto a imagen que puede integrar texto en imágenes de manera inteligente.
- MO estable – LLM de código abierto. La versión Alpha del modelo está disponible en parámetros 3B y 7B, con modelos de parámetros 15B a 65B a continuación. Los desarrolladores pueden obtener acceso gratuito para inspeccionar, usar y adaptar los modelos base de StableLM con fines comerciales o de investigación.
- Vicuña estable – el primer chatbot de código abierto a gran escala entrenado a través del aprendizaje reforzado a partir de la retroalimentación humana (RLHF). StableVicuna se basa en un afinado Llama modelo 13B.
- Animación estable – Herramienta de texto a animación, actualmente disponible solo para desarrolladores, ya que aún no tiene una interfaz fácil de usar. La herramienta permite tres formas de crear animaciones:
- Texto a animación: los usuarios ingresan un mensaje de texto y modifican varios parámetros para producir una animación.
- Entrada de texto + entrada de imagen inicial: Los usuarios proporcionan una imagen inicial que actúa como punto de partida de su animación. Se utiliza un mensaje de texto junto con la imagen para producir la animación de salida final.
- Entrada de vídeo + entrada de texto: Los usuarios proporcionan un video inicial para basar su animación. Al ajustar varios parámetros, llegan a una animación de salida final que, además, está guiada por un mensaje de texto.
[Contenido incrustado]
Otros modelos de código abierto
Recientemente se han lanzado muchos otros modelos de código abierto. Los modelos destacados incluyen:
- Alpaca de un equipo de la Universidad de Stanford,
- Muñequita de la firma de software Databricks, y
- Cerebras-GPT de la firma de inteligencia artificial Cerebras.
Estos modelos son adiciones importantes al ecosistema de IA de código abierto y enriquecen aún más su diversidad.
Sin embargo, es importante tener en cuenta que muchos modelos de código abierto se basan en los modelos fundamentales lanzado por gigantes tecnológicos como Meta y OpenAI.
- Por ejemplo, HuggingChat y Stable Vicuna se basan en el modelo LLaMA de código abierto de Meta.
- Además, la comunidad de código abierto también se ha beneficiado del extenso conjunto de datos públicos llamado Pile, compilado por EleutherAI, una organización sin fines de lucro. The Pile fue posible en gran parte debido a la apertura de OpenAI, que permitió a un grupo de codificadores aplicar ingeniería inversa a cómo se hizo GPT-3.
Ahora, las políticas de código abierto de estos gigantes tecnológicos están evolucionando.
- OpenAI es reconsiderando su anterior política abierta debido a los temores de la competencia.
- Meta es la búsqueda de para equilibrar la transparencia y la seguridad, implementando medidas como licencias de clic y restricciones en el uso de datos.
Las empresas tecnológicas líderes como Meta, Google o Microsoft deben ser especialmente cautelosas con respecto a los riesgos de reputación y, por lo tanto, tomarse muy en serio todas las preocupaciones de seguridad relacionadas con el código abierto de sus modelos.
Preocupaciones de seguridad en proyectos de IA de código abierto
A pesar de su inmenso potencial, los proyectos de IA de código abierto no están exentos de riesgos. Éstas incluyen:
- Mal uso del modelo: La accesibilidad de los modelos de IA de código abierto también significa que pueden ser mal utilizados por actores malintencionados con fines como falsificaciones profundas, spam automatizado o campañas de desinformación.
- Por ejemplo, mucha gente usa el código fuente abierto de los modelos Stable Diffusion para eliminar filtros y generar pornografía e imágenes dañinas.
- Sesgo y equidad: Los modelos de código abierto entrenados en datos públicos pueden reflejar y propagar sesgos presentes en esos datos. También pueden ajustarse de manera que introduzcan nuevos sesgos, lo que lleva a resultados que son injustos o discriminatorios.
- Falta de supervisión y rendición de cuentas: En un entorno de código abierto, puede ser un desafío mantener la supervisión de cómo se usan y modifican los modelos. Esto podría conducir a situaciones en las que no está claro quién es el responsable si algo sale mal.
- Seguridad y privacidad de los datos: Los proyectos de código abierto pueden ser vulnerables a problemas de seguridad de datos si no se gestionan adecuadamente. Los datos confidenciales podrían estar potencialmente expuestos durante el proceso de desarrollo, y también puede haber riesgos asociados con los datos utilizados para entrenar, probar o ajustar modelos.
En conclusión, los proyectos de código abierto en IA generativa ofrecen un inmenso potencial para el avance de la tecnología de IA y sus aplicaciones. Sin embargo, es crucial reconocer la responsabilidad que conlleva esta libertad. A medida que el campo continúa evolucionando, se vuelve cada vez más importante garantizar que se prioricen las consideraciones éticas. La protección contra el uso indebido potencial y las consecuencias no deseadas es primordial.
¿Disfrutas este artículo? Regístrese para obtener más actualizaciones de investigación de IA.
Le informaremos cuando publiquemos más artículos de resumen como este.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://www.topbots.com/open-source-projects-generative-ai/

