
Imagen de ormavaredo on Pixabay
Python es uno de los lenguajes de programación más utilizados en el mundo y ofrece a los desarrolladores una amplia gama de bibliotecas.
De todos modos, cuando se trata de manipulación de datos y computación científica, generalmente pensamos en bibliotecas como Numpy, Pandaso SciPy.
En este artículo, presentamos 3 bibliotecas de Python que pueden interesarle.
Presentando a Dask
Dask es una biblioteca de computación paralela flexible que permite la computación distribuida y el paralelismo para el procesamiento de datos a gran escala.
Entonces, ¿por qué deberíamos usar Dask? Como dicen en su página web:
Python ha crecido hasta convertirse en el lenguaje dominante tanto en análisis de datos como en programación general. Este crecimiento ha sido impulsado por bibliotecas computacionales como NumPy, pandas y scikit-learn. Sin embargo, estos paquetes no fueron diseñados para escalar más allá de una sola máquina. Dask se desarrolló para escalar de forma nativa estos paquetes y el ecosistema circundante a máquinas de múltiples núcleos y clústeres distribuidos cuando los conjuntos de datos exceden la memoria.
Entonces, uno de los usos comunes de Dask, como ellos dicen, es:
Dask DataFrame se usa en situaciones donde comúnmente se necesita pandas, generalmente cuando pandas falla debido al tamaño de los datos o la velocidad de cálculo:
– Manipular grandes conjuntos de datos, incluso cuando esos conjuntos de datos no caben en la memoria
– Acelerar cálculos largos mediante el uso de muchos núcleos
– Cómputo distribuido en grandes conjuntos de datos con operaciones estándar de pandas como agrupar, unir y cómputos de series temporales
Por lo tanto, Dask es una buena opción cuando necesitamos lidiar con enormes marcos de datos de Pandas. Esto se debe a que Dask:
Permite a los usuarios manipular conjuntos de datos de más de 100 GB en una computadora portátil o conjuntos de datos de más de 1 TB en una estación de trabajo
Lo cual es un resultado bastante impresionante.
Lo que sucede bajo el capó es que:
Dask DataFrames coordina muchos DataFrames/Series de pandas dispuestos a lo largo del índice. Un Dask DataFrame está particionado en fila, agrupando filas por valor de índice para mayor eficiencia. Estos objetos pandas pueden vivir en el disco o en otras máquinas.
Entonces, tenemos algo como esto:
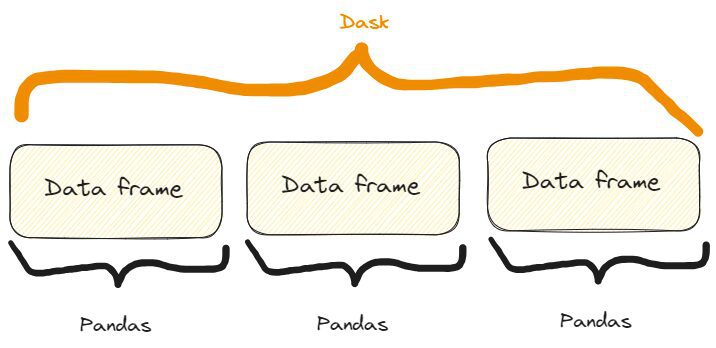
La diferencia entre un marco de datos Dask y Pandas. Imagen del autor, inspirada libremente en una del sitio web de Dask ya citada.
Algunas características de Dask en acción
Primero que nada, necesitamos instalar Dask. Podemos hacerlo a través de pip or conda al igual que:
$ pip install dask[complete] or $ conda install daskFUNCIÓN UNO: ABRIR UN ARCHIVO CSV
La primera característica que podemos mostrar de Dask es cómo podemos abrir un CSV. Podemos hacerlo así:
import dask.dataframe as dd # Load a large CSV file using Dask
df_dask = dd.read_csv('my_very_large_dataset.csv') # Perform operations on the Dask DataFrame
mean_value_dask = df_dask['column_name'].mean().compute()Entonces, como podemos ver en el código, la forma en que usamos Dask es muy similar a Pandas. En particular:
- Usamos el método
read_csv()exactamente como en Pandas - Interceptamos una columna exactamente como en Pandas. De hecho, si tuviéramos un marco de datos de Pandas llamado
dfinterceptaríamos una columna de esta manera:df['column_name']. - Aplicamos el
mean()método a la columna interceptada similar a Pandas, pero aquí también necesitamos agregar el métodocompute().
Además, incluso si la metodología para abrir un archivo CSV es la misma que en Pandas, bajo el capó Dask procesa sin esfuerzo un gran conjunto de datos que excede la capacidad de memoria de una sola máquina.
Esto significa que no podemos ver ninguna diferencia real, excepto el hecho de que no se puede abrir un marco de datos grande en Pandas, pero sí en Dask.
FUNCIÓN DOS: ESCALA DE FLUJOS DE TRABAJO DE APRENDIZAJE AUTOMÁTICO
También podemos usar Dask para crear un conjunto de datos de clasificación con una gran cantidad de muestras. Luego podemos dividirlo en el tren y los conjuntos de prueba, ajustar el conjunto de trenes con un modelo ML y calcular predicciones para el conjunto de prueba.
Podemos hacerlo así:
import dask_ml.datasets as dask_datasets
from dask_ml.linear_model import LogisticRegression
from dask_ml.model_selection import train_test_split # Load a classification dataset using Dask
X, y = dask_datasets.make_classification(n_samples=100000, chunks=1000) # Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y) # Train a logistic regression model in parallel
model = LogisticRegression()
model.fit(X_train, y_train) # Predict on the test set
y_pred = model.predict(X_test).compute()Este ejemplo enfatiza la capacidad de Dask para manejar enormes conjuntos de datos incluso en el caso de un problema de aprendizaje automático, mediante la distribución de cálculos en múltiples núcleos.
En particular, podemos crear un "conjunto de datos Dask" para un caso de clasificación con el método dask_datasets.make_classification(), y podemos especificar el número de muestras y fragmentos (¡incluso, muy grandes!).
Al igual que antes, las predicciones se obtienen con el método compute().
NOTE: in this case, you may need to intsall the module dask_ml. You can do it like so: $ pip install dask_mlFUNCIÓN TRES: PROCESAMIENTO DE IMAGEN EFICIENTE
El poder del procesamiento paralelo que utiliza Dask también se puede aplicar a las imágenes.
En particular, podríamos abrir varias imágenes, cambiar su tamaño y guardarlas redimensionadas. Podemos hacerlo así:
import dask.array as da
import dask_image.imread
from PIL import Image # Load a collection of images using Dask
images = dask_image.imread.imread('image*.jpg') # Resize the images in parallel
resized_images = da.stack([da.resize(image, (300, 300)) for image in images]) # Compute the result
result = resized_images.compute() # Save the resized images
for i, image in enumerate(result): resized_image = Image.fromarray(image) resized_image.save(f'resized_image_{i}.jpg')Entonces, aquí está el proceso:
- Abrimos todas las imágenes “.jpg” en la carpeta actual (o en una carpeta que puedas especificar) con el método
dask_image.imread.imread("image*.jpg"). - Cambiamos su tamaño a todos a 300×300 usando una lista por comprensión en el método
da.stack(). - Calculamos el resultado con el método
compute(), como hicimos antes. - Guardamos todas las imágenes redimensionadas con el ciclo for.
Presentando Sympy
Si necesita realizar cálculos y cálculos matemáticos y desea ceñirse a Python, puede probar Sympy.
De hecho: ¿por qué utilizar otras herramientas y software, cuando podemos utilizar nuestro querido Python?
Según lo que escriben en su página web, Sympy es:
Una biblioteca de Python para matemáticas simbólicas. Su objetivo es convertirse en un sistema de álgebra informática (CAS) con todas las funciones manteniendo el código lo más simple posible para que sea comprensible y fácilmente extensible. SymPy está escrito completamente en Python.
Pero ¿por qué utilizar SymPy? Ellos sugieren:
SymPy es...
- Gratis: Con licencia BSD, SymPy es gratuito tanto en voz como en cerveza.
– Basado en Python: SymPy está escrito completamente en Python y utiliza Python como lenguaje.
– Ligero: SymPy sólo depende de mpmath, una biblioteca pura de Python para aritmética arbitraria de punto flotante, lo que la hace fácil de usar.
- Una biblioteca: Más allá de su uso como herramienta interactiva, SymPy puede integrarse en otras aplicaciones y ampliarse con funciones personalizadas.
Entonces, ¡básicamente tiene todas las características que pueden ser amadas por los adictos a Python!
Ahora, veamos algunas de sus características.
Algunas características de SymPy en acción
Primero que nada, necesitamos instalarlo:
$ pip install sympyPAY ATTENTION: if you write $ pip install simpy you'll install another (completely different!) library. So, the second letter is a "y", not an "i".FUNCIÓN UNO: RESOLVER UNA ECUACIÓN ALGEBRAICA
Si necesitamos resolver una ecuación algebraica, podemos usar SymPy así:
from sympy import symbols, Eq, solve # Define the symbols
x, y = symbols('x y') # Define the equation
equation = Eq(x**2 + y**2, 25) # Solve the equation
solutions = solve(equation, (x, y)) # Print solution
print(solutions) >>> [(-sqrt(25 - y**2), y), (sqrt(25 - y**2), y)]Entonces, ese es el proceso:
- Definimos los símbolos de la ecuación con el método.
symbols(). - Escribimos la ecuación algebraica con el método
Eq. - Resolvemos la ecuación con el método
solve().
Cuando estaba en la Universidad utilicé diferentes herramientas para resolver este tipo de problemas, y tengo que decir que SymPy, como podemos ver, es muy legible y fácil de usar.
Pero, de hecho: es una biblioteca de Python, entonces, ¿cómo podría ser diferente?
FUNCIÓN DOS: CÁLCULO DE DERIVADOS
Calcular derivadas es otra tarea que podemos necesitar matemáticamente, por muchas razones, al analizar datos. A menudo, es posible que necesitemos cálculos por cualquier motivo y SympY realmente simplifica este proceso. De hecho, podemos hacerlo así:
from sympy import symbols, diff # Define the symbol
x = symbols('x') # Define the function
f = x**3 + 2*x**2 + 3*x + 4 # Calculate the derivative
derivative = diff(f, x) # Print derivative
print(derivative) >>> 3*x**2 + 4*x + 3Entonces, como podemos ver, el proceso es muy sencillo y autoexplicativo:
- Definimos el símbolo de la función con la que estamos derivando
symbols(). - Definimos la función.
- Calculamos la derivada con
diff()especificando la función y el símbolo estamos calculando la derivada (esta es una derivada absoluta, pero podríamos realizar incluso derivadas parciales en el caso de funciones que tenganxyyvariable).
Y si lo probamos veremos que el resultado llega en cuestión de 2 o 3 segundos. Entonces, también es bastante rápido.
FUNCIÓN TRES: CÁLCULO DE INTEGRACIONES
Por supuesto, si SymPy puede calcular derivadas, también puede calcular integraciones. Vamos a hacerlo:
from sympy import symbols, integrate, sin # Define the symbol
x = symbols('x') # Perform symbolic integration
integral = integrate(sin(x), x) # Print integral
print(integral) >>> -cos(x)Entonces aquí usamos el método integrate(), especificando la función a integrar y la variable de integración.
¡¿No podría ser más fácil?!
Presentando Xarray
Xarray es una biblioteca de Python que amplía las características y funcionalidades de NumPy, brindándonos la posibilidad de trabajar con matrices y conjuntos de datos etiquetados.
Como ellos dicen en su página web, En realidad:
¡Xarray hace que trabajar con arreglos multidimensionales etiquetados en Python sea simple, eficiente y divertido!
Y también:
Xarray introduce etiquetas en forma de dimensiones, coordenadas y atributos además de matrices multidimensionales sin formato tipo NumPy, lo que permite una experiencia de desarrollador más intuitiva, más concisa y menos propensa a errores.
En otras palabras, amplía la funcionalidad de las matrices NumPy agregando etiquetas o coordenadas a las dimensiones de la matriz. Estas etiquetas proporcionan metadatos y permiten un análisis y manipulación más avanzados de datos multidimensionales.
Por ejemplo, en NumPy, se accede a las matrices mediante la indexación basada en enteros.
En cambio, en Xarray, cada dimensión puede tener una etiqueta asociada, lo que facilita la comprensión y manipulación de los datos en función de nombres significativos.
Por ejemplo, en lugar de acceder a los datos con arr[0, 1, 2], nosotros podemos usar arr.sel(x=0, y=1, z=2) en Xarray, donde x, yy z son etiquetas de dimensiones.
¡Esto hace que el código sea mucho más legible!
Entonces, veamos algunas características de Xarray.
Algunas características de Xarray en acción
Como es habitual, para instalarlo:
$ pip install xarrayFUNCIÓN UNO: TRABAJAR CON COORDENADAS ETIQUETADAS
Supongamos que queremos crear algunos datos relacionados con la temperatura y queremos etiquetarlos con coordenadas como latitud y longitud. Podemos hacerlo así:
import xarray as xr
import numpy as np # Create temperature data
temperature = np.random.rand(100, 100) * 20 + 10 # Create coordinate arrays for latitude and longitude
latitudes = np.linspace(-90, 90, 100)
longitudes = np.linspace(-180, 180, 100) # Create an Xarray data array with labeled coordinates
da = xr.DataArray( temperature, dims=['latitude', 'longitude'], coords={'latitude': latitudes, 'longitude': longitudes}
) # Access data using labeled coordinates
subset = da.sel(latitude=slice(-45, 45), longitude=slice(-90, 0))Y si los imprimimos obtenemos:
# Print data
print(subset) >>>
array([[13.45064786, 29.15218061, 14.77363206, ..., 12.00262833, 16.42712411, 15.61353963], [23.47498117, 20.25554247, 14.44056286, ..., 19.04096482, 15.60398491, 24.69535367], [25.48971105, 20.64944534, 21.2263141 , ..., 25.80933737, 16.72629302, 29.48307134], ..., [10.19615833, 17.106716 , 10.79594252, ..., 29.6897709 , 20.68549602, 29.4015482 ], [26.54253304, 14.21939699, 11.085207 , ..., 15.56702191, 19.64285595, 18.03809074], [26.50676351, 15.21217526, 23.63645069, ..., 17.22512125, 13.96942377, 13.93766583]])
Coordinates: * latitude (latitude) float64 -44.55 -42.73 -40.91 ... 40.91 42.73 44.55 * longitude (longitude) float64 -89.09 -85.45 -81.82 ... -9.091 -5.455 -1.818Entonces, veamos el proceso paso a paso:
- Hemos creado los valores de temperatura como una matriz NumPy.
- Hemos definido los valores de latitudes y longitudes como matrices NumPy.
- Hemos almacenado todos los datos en una matriz Xarray con el método
DataArray(). - Hemos seleccionado un subconjunto de latitudes y longitudes con el método
sel()que selecciona los valores que queremos para nuestro subconjunto.
El resultado también es fácilmente legible, por lo que el etiquetado es realmente útil en muchos casos.
FUNCIÓN DOS: MANEJO DE DATOS FALTANTES
Supongamos que estamos recopilando datos relacionados con las temperaturas durante el año. Queremos saber si tenemos algunos valores nulos en nuestra matriz. Así es como podemos hacerlo:
import xarray as xr
import numpy as np
import pandas as pd # Create temperature data with missing values
temperature = np.random.rand(365, 50, 50) * 20 + 10
temperature[0:10, :, :] = np.nan # Set the first 10 days as missing values # Create time, latitude, and longitude coordinate arrays
times = pd.date_range('2023-01-01', periods=365, freq='D')
latitudes = np.linspace(-90, 90, 50)
longitudes = np.linspace(-180, 180, 50) # Create an Xarray data array with missing values
da = xr.DataArray( temperature, dims=['time', 'latitude', 'longitude'], coords={'time': times, 'latitude': latitudes, 'longitude': longitudes}
) # Count the number of missing values along the time dimension
missing_count = da.isnull().sum(dim='time') # Print missing values
print(missing_count) >>>
array([[10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10], ..., [10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10], [10, 10, 10, ..., 10, 10, 10]])
Coordinates: * latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0 * longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0Y así obtenemos que tenemos 10 valores nulos.
Además, si miramos de cerca el código, podemos ver que podemos aplicar los métodos de Pandas a un Xarray como isnull.sum(), como en este caso, que cuenta el número total de valores faltantes.
FUNCIÓN UNO: MANEJO Y ANÁLISIS DE DATOS MULTIDIMENSIONALES
La tentación de manejar y analizar datos multidimensionales es alta cuando tenemos la posibilidad de etiquetar nuestras matrices. ¿Así que por qué no intentarlo?
Por ejemplo, supongamos que todavía estamos recopilando datos relacionados con las temperaturas en determinadas latitudes y longitudes.
Es posible que deseemos calcular las temperaturas media, máxima y mediana. Podemos hacerlo así:
import xarray as xr
import numpy as np
import pandas as pd # Create synthetic temperature data
temperature = np.random.rand(365, 50, 50) * 20 + 10 # Create time, latitude, and longitude coordinate arrays
times = pd.date_range('2023-01-01', periods=365, freq='D')
latitudes = np.linspace(-90, 90, 50)
longitudes = np.linspace(-180, 180, 50) # Create an Xarray dataset
ds = xr.Dataset( { 'temperature': (['time', 'latitude', 'longitude'], temperature), }, coords={ 'time': times, 'latitude': latitudes, 'longitude': longitudes, }
) # Perform statistical analysis on the temperature data
mean_temperature = ds['temperature'].mean(dim='time')
max_temperature = ds['temperature'].max(dim='time')
min_temperature = ds['temperature'].min(dim='time') # Print values print(f"mean temperature:n {mean_temperature}n")
print(f"max temperature:n {max_temperature}n")
print(f"min temperature:n {min_temperature}n") >>> mean temperature:
array([[19.99931701, 20.36395016, 20.04110699, ..., 19.98811842, 20.08895803, 19.86064693], [19.84016491, 19.87077812, 20.27445405, ..., 19.8071972 , 19.62665953, 19.58231185], [19.63911165, 19.62051976, 19.61247548, ..., 19.85043831, 20.13086891, 19.80267099], ..., [20.18590514, 20.05931149, 20.17133483, ..., 20.52858247, 19.83882433, 20.66808513], [19.56455575, 19.90091128, 20.32566232, ..., 19.88689221, 19.78811145, 19.91205212], [19.82268297, 20.14242279, 19.60842148, ..., 19.68290006, 20.00327294, 19.68955107]])
Coordinates: * latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0 * longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0 max temperature:
array([[29.98465531, 29.97609171, 29.96821276, ..., 29.86639343, 29.95069558, 29.98807808], [29.91802049, 29.92870312, 29.87625447, ..., 29.92519055, 29.9964299 , 29.99792388], [29.96647016, 29.7934891 , 29.89731136, ..., 29.99174546, 29.97267052, 29.96058079], ..., [29.91699117, 29.98920555, 29.83798369, ..., 29.90271746, 29.93747041, 29.97244906], [29.99171911, 29.99051943, 29.92706773, ..., 29.90578739, 29.99433847, 29.94506567], [29.99438621, 29.98798699, 29.97664488, ..., 29.98669576, 29.91296382, 29.93100249]])
Coordinates: * latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0 * longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0 min temperature:
array([[10.0326431 , 10.07666029, 10.02795524, ..., 10.17215336, 10.00264909, 10.05387097], [10.00355858, 10.00610942, 10.02567816, ..., 10.29100316, 10.00861792, 10.16955806], [10.01636216, 10.02856619, 10.00389027, ..., 10.0929342 , 10.01504103, 10.06219179], ..., [10.00477003, 10.0303088 , 10.04494723, ..., 10.05720692, 10.122994 , 10.04947012], [10.00422182, 10.0211205 , 10.00183528, ..., 10.03818058, 10.02632697, 10.06722953], [10.10994581, 10.12445222, 10.03002468, ..., 10.06937041, 10.04924046, 10.00645499]])
Coordinates: * latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0 * longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0Y obtuvimos lo que queríamos, además de forma claramente legible.
Y nuevamente, como antes, para calcular los valores máximo, mínimo y medio de las temperaturas, hemos usado las funciones de Pandas aplicadas a una matriz.
En este artículo, hemos mostrado tres bibliotecas para cálculo y computación científica.
Mientras que SymPy puede ser el sustituto de otras herramientas y software, dándonos la posibilidad de utilizar código Python para realizar cálculos matemáticos, Dask y Xarray amplían las funcionalidades de otras bibliotecas, ayudándonos en situaciones en las que podemos tener dificultades con otras bibliotecas Python más conocidas. para el análisis y manipulación de datos.
federico trotta Le encanta escribir desde que era un niño en la escuela, escribiendo historias de detectives como exámenes de clase. Gracias a su curiosidad descubrió la programación y la IA. Teniendo una ardiente pasión por la escritura, no pudo evitar comenzar a escribir sobre estos temas, por lo que decidió cambiar su carrera para convertirse en Redactor Técnico. Su propósito es educar a las personas sobre programación Python, aprendizaje automático y ciencia de datos a través de la escritura. Encuentra más sobre él en federicotrotta.com.
Original. Publicado de nuevo con permiso.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/08/beyond-numpy-pandas-unlocking-potential-lesserknown-python-libraries.html?utm_source=rss&utm_medium=rss&utm_campaign=beyond-numpy-and-pandas-unlocking-the-potential-of-lesser-known-python-libraries

