
Imagen del autor
Los datos dispersos se refieren a conjuntos de datos con muchas características con valores cero. Puede causar problemas en diferentes campos, especialmente en el aprendizaje automático.
Los datos escasos pueden ocurrir como resultado de métodos de ingeniería de características inapropiados. Por ejemplo, usar una codificación one-hot que crea una gran cantidad de variables ficticias.
La dispersión se puede calcular tomando la relación de ceros en un conjunto de datos con el número total de elementos. Abordar la escasez afectará la precisión de su modelo de aprendizaje automático.
Además, debemos distinguir la escasez de datos faltantes. Los datos faltantes simplemente significan que algunos valores no están disponibles. En datos escasos, todos los valores están presentes, pero la mayoría son cero.
Además, la escasez genera desafíos únicos para el aprendizaje automático. Para ser exactos, provoca sobreajuste, pérdida de buenos datos, problemas de memoria y problemas de tiempo.
Este artículo explorará estos problemas comunes relacionados con la escasez de datos. Luego cubriremos las técnicas utilizadas para manejar este problema.
Finalmente, aplicaremos diferentes modelos de aprendizaje automático a los datos escasos y explicaremos por qué estos modelos son adecuados para datos escasos.
A lo largo del artículo, utilizaré predominantemente la biblioteca scikit-learn y, si desea modificar el código y los argumentos, también proporcionaré los enlaces de la documentación oficial.
Ahora comencemos con los problemas comunes con datos dispersos.
Los datos escasos pueden plantear desafíos únicos para el análisis de datos. Ya mencionamos que algunos de los problemas más comunes incluyen sobreajuste, pérdida de buenos datos, problemas de memoria y problemas de tiempo.
Ahora, echemos un vistazo detallado a cada uno.

Imagen del autor
Sobreajuste
El sobreajuste ocurre cuando un modelo se vuelve demasiado complejo y comienza a capturar ruido en los datos en lugar de los patrones subyacentes.
En datos escasos, puede haber una gran cantidad de características, pero solo algunas de ellas son realmente relevantes para el análisis. Esto puede hacer que sea difícil identificar qué características son importantes y cuáles no.
Como resultado, un modelo puede sobreajustarse al ruido en los datos y tener un desempeño deficiente en datos nuevos.
Si es nuevo en el aprendizaje automático o quiere saber más, puede hacerlo en el documentación de scikit-learn sobre sobreajuste.
Perder buenos datos
Uno de los mayores problemas con la escasez de datos es que puede conducir a la pérdida de información potencialmente útil.
Cuando tenemos datos muy limitados, se vuelve más difícil identificar patrones o relaciones significativos en esos datos. Esto se debe a que el ruido y la aleatoriedad inherentes a cualquier conjunto de datos pueden oscurecer más fácilmente las características esenciales cuando los datos son escasos.
Además, debido a que la cantidad de datos disponibles es limitada, existe una mayor probabilidad de que nos perdamos algunos de los patrones o relaciones verdaderamente valiosos en los datos. Esto es especialmente cierto en los casos en que los datos son escasos debido a la falta de muestreo, en lugar de simplemente faltar. En tales casos, es posible que ni siquiera nos demos cuenta de los puntos de datos que faltan y, por lo tanto, es posible que no nos demos cuenta de que estamos perdiendo información valiosa.
Es por eso que si se eliminan demasiadas funciones o si los datos se comprimen demasiado, se puede perder información importante, lo que da como resultado un modelo menos preciso.
Problema de memoria
Pueden surgir problemas de memoria debido al gran tamaño del conjunto de datos. Los datos escasos a menudo dan como resultado muchas funciones, y almacenar estos datos puede ser costoso desde el punto de vista computacional. Esto puede limitar la cantidad de datos que se pueden procesar a la vez o requerir recursos informáticos significativos.
Aquí puede ver diferentes estrategias para escalar sus datos usando scikit-learn.
problema de tiempo
El problema del tiempo también puede ocurrir debido al gran tamaño del conjunto de datos. Los datos escasos pueden requerir tiempos de procesamiento más prolongados, especialmente cuando se trata de una gran cantidad de funciones. Esto puede limitar la velocidad a la que se pueden procesar los datos, lo que puede ser problemático en aplicaciones sensibles al tiempo.

Imagen del autor
Los datos escasos plantean un desafío en el análisis de datos debido a su baja ocurrencia de valores distintos de cero. Sin embargo, hay varios métodos disponibles para mitigar este problema.
Un enfoque común es eliminar la característica que causa escasez en el conjunto de datos.
Otra opción es utilizar el análisis de componentes principales (PCA) para reducir la dimensionalidad del conjunto de datos y conservar la información importante.
Hashing de características es otra técnica que se puede emplear, que implica la asignación de características a un vector de longitud fija.
T-Distributed Stochastic Neighbor Embedding (t-SNE) es otro método útil que se puede utilizar para visualizar conjuntos de datos de alta dimensión.
Además de estas técnicas, es crucial seleccionar un modelo de aprendizaje automático adecuado que pueda manejar datos escasos, como SVM o regresión logística.
Al implementar estas estrategias, uno puede abordar de manera efectiva los desafíos asociados con la escasez de datos en el análisis de datos.
Ahora, comencemos primero con las tácticas utilizadas para reducir los datos dispersos, luego profundizaremos en los modelos.
¡Quítelo!
Cuando se trabaja con datos escasos, un enfoque consiste en eliminar las características que contienen en su mayoría valores cero. Esto se puede hacer estableciendo un umbral en el porcentaje de valores distintos de cero en cada función. Cualquier característica que caiga por debajo de este umbral se puede eliminar del conjunto de datos.
Este enfoque puede ayudar a reducir la dimensionalidad del conjunto de datos y mejorar el rendimiento de ciertos algoritmos de aprendizaje automático.
Ejemplo de código
En este ejemplo, establecemos las dimensiones del conjunto de datos, así como el nivel de escasez, que determina cuántos valores en el conjunto de datos serán cero.
Luego, generamos datos aleatorios con el nivel de escasez especificado para verificar si nuestro método funciona o no. En este paso, calculamos la dispersión para comparar después.
A continuación, el código establece la cantidad de ceros que se eliminarán y elimina aleatoriamente una cantidad específica de ceros del conjunto de datos. Luego volvemos a calcular la escasez del conjunto de datos modificado para verificar si nuestro método funciona o no.
Finalmente, volvemos a calcular la dispersión para ver los cambios.
Aquí está el código.
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Set the number of zeros to remove
num_zeros_to_remove = 50000 # Remove a specific number of zeros randomly from the dataset
zero_indices = np.argwhere(data == 0)
zeros_to_remove = np.random.choice( zero_indices.shape[0], num_zeros_to_remove, replace=False
)
data[ zero_indices[zeros_to_remove, 0], zero_indices[zeros_to_remove, 1]
] = np.nan # Calculate the sparsity of the modified dataset num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print( "Sparsity after removing {} zeros:".format(num_zeros_to_remove), sparsity
)
Aquí está la salida.

PCA
PCA es una técnica popular para la reducción de la dimensionalidad. Identifica los componentes principales de los datos, que son las direcciones en las que los datos varían más.
Estos componentes principales se pueden usar para representar los datos en un espacio de menor dimensión.
En el contexto de datos escasos, PCA se puede utilizar para identificar las características más importantes que contienen la mayor variación en los datos.
Al seleccionar solo estas características, podemos reducir la dimensionalidad del conjunto de datos y al mismo tiempo conservar la mayor parte de la información importante.
Puede implementar PCA mediante la biblioteca de aprendizaje de sci-kit, como lo haremos a continuación en el ejemplo de código. Aquí es la documentación oficial si desea obtener más información al respecto.
Ejemplo de código
Para aplicar PCA a datos dispersos, podemos usar la biblioteca scikit-learn en Python.
La biblioteca proporciona una clase de PCA que podemos usar para ajustar un modelo de PCA a los datos y transformarlos en un espacio de menor dimensión.
En la primera sección del siguiente código, creamos un conjunto de datos como lo hicimos en la sección anterior, con una dimensión y escasez determinadas.
En la segunda sección, aplicaremos PCA para reducir la dimensión del conjunto de datos a 10. Después de eso, volveremos a calcular la dispersión.
Aquí está el código.
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Apply PCA to the dataset
pca = PCA(n_components=10)
data_pca = pca.fit_transform(data)
# Calculate the sparsity of the reduced dataset
num_zeros = (data_pca == 0).sum()
total_elements = data_pca.shape[0] * data_pca.shape[1]
sparsity = num_zeros / total_elements print(f"Sparsity after PCA: {sparsity:.4f}")
Aquí está la salida.

Hash de funciones
Otro método para trabajar con datos escasos se denomina hashing de características. Este enfoque convierte cada característica en una matriz de valores de longitud fija mediante una función hash.
La función hash asigna cada característica de entrada a un conjunto de índices en la matriz de longitud fija. Los valores se suman si varias entidades de entrada se asignan al mismo índice. El hashing de características puede ser útil para grandes conjuntos de datos en los que puede no ser factible almacenar un diccionario de características grande.
Cubriremos esto juntos en la siguiente sección, pero si desea profundizar en ello, esta página puede ver la documentación oficial del hasher de características en la biblioteca scikit-learn.
Ejemplo de código
Aquí, nuevamente usamos el mismo método en la creación de conjuntos de datos.
Luego, aplicamos hash de características al conjunto de datos usando la clase FeatureHasher de scikit-learn.
Especificamos el número de características de salida con el n_características parámetro y el tipo de entrada como un diccionario con el tipo de entrada parámetro.
Luego, transformamos los datos de entrada en matrices con hash utilizando el método de transformación del objeto FeatureHasher.
Finalmente, calculamos la escasez del conjunto de datos resultante.
Aquí está el código.
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Apply feature hashing to the dataset
hasher = FeatureHasher(n_features=10, input_type="dict")
data_dict = [ dict(("feature" + str(i), val) for i, val in enumerate(row)) for row in data
]
data_hashed = hasher.transform(data_dict).toarray() # Calculate the sparsity of the reduced dataset
num_zeros = (data_hashed == 0).sum()
total_elements = data_hashed.shape[0] * data_hashed.shape[1]
sparsity = num_zeros / total_elements print(f"Sparsity after feature hashing: {sparsity:.4f}")
Aquí está la salida.
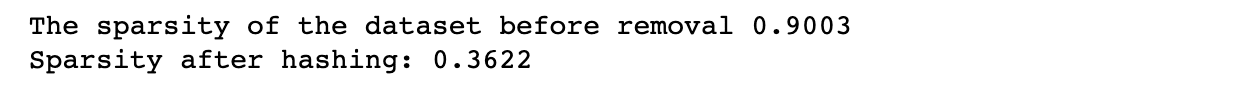
incrustación de t-SNE
t-SNE (t-Distributed Stochastic Neighbor Embedding) es una técnica de reducción de dimensionalidad no lineal utilizada para visualizar datos de alta dimensión. Reduce la dimensionalidad de los datos mientras preserva su estructura global y se ha convertido en una herramienta popular en el aprendizaje automático para visualizar y agrupar datos de alta dimensión.
t-SNE es particularmente útil para trabajar con datos dispersos porque puede reducir efectivamente la dimensionalidad de los datos mientras mantiene su estructura. El algoritmo t-SNE funciona calculando distancias por pares entre puntos de datos en espacios de alta y baja dimensión. Luego minimiza la diferencia entre estas distancias en espacios de alta y baja dimensión.
Para usar t-SNE con datos dispersos, los datos primero deben convertirse en una matriz densa. Esto se puede hacer usando varias técnicas, como PCA o hashing de características. Una vez que se han convertido los datos, t-SNE puede ser high-x para obtener una incrustación de baja dimensión de los datos.
Además, si tiene curiosidad acerca de t-SNE, esta página es la documentación oficial del scikit-learn para ver más.
Ejemplo de código
El siguiente código primero establece las dimensiones del conjunto de datos y el nivel de dispersión, genera datos aleatorios con el nivel de dispersión especificado y calcula la dispersión del conjunto de datos antes de aplicar t-SNE, como hicimos en los ejemplos anteriores.
Luego aplica t-SNE al conjunto de datos con 3 componentes y calcula la escasez de la incrustación de t-SNE resultante. Finalmente, imprime la escasez de la incrustación de t-SNE.
Aquí está el código.
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Apply t-SNE to the dataset
tsne = TSNE(n_components=3)
data_tsne = tsne.fit_transform(data) # Calculate the sparsity of the t-SNE embedding
num_zeros = (data_tsne == 0).sum()
total_elements = data_tsne.shape[0] * data_tsne.shape[1]
sparsity = num_zeros / total_elements print(f"Sparsity after t-SNE: {sparsity:.4f}")
Aquí está la salida.

Ahora que hemos abordado los desafíos de trabajar con datos escasos, podemos explorar modelos de aprendizaje automático diseñados específicamente para funcionar bien con datos escasos.
Estos modelos pueden manejar las características únicas de los datos escasos, como una gran cantidad de características con muchos ceros e información limitada, lo que puede dificultar el logro de predicciones precisas con los modelos tradicionales.
Mediante el uso de modelos diseñados explícitamente para datos escasos, podemos garantizar que nuestras predicciones sean más precisas y confiables.
Ahora hablemos de los modelos buenos para datos dispersos.
SVC (Clasificador de vectores de soporte)
SVC (Clasificador de vectores de soporte) con el núcleo lineal puede funcionar bien con datos escasos porque utiliza un subconjunto de puntos de entrenamiento, conocidos como vectores de soporte, para hacer predicciones. Esto significa que puede manejar datos dispersos de gran dimensión de manera eficiente.
También puede usar el vector de soporte para la regresión.
expliqué el Máquina de vectores de soporte aquí si quieres saber más sobre el algoritmo de Vector de Soporte, tanto de clasificación como de regresión.
Regresión logística
Esto también puede funcionar bien con datos escasos porque la regresión logística utiliza un término de regularización para controlar la complejidad del modelo, lo que puede ayudar a evitar el sobreajuste en conjuntos de datos escasos.
Si desea obtener más información sobre la regresión logística y también sobre otros algoritmos de clasificación, aquí está el Descripción general de los algoritmos de aprendizaje automático: clasificación.
KVecinosClasificador
Este algoritmo puede funcionar bien con datos escasos, ya que calcula distancias entre puntos de datos y puede manejar datos de gran dimensión.
Puedes ver KNN y otros algoritmos de aprendizaje automático aquí que debes saber para la ciencia de datos.
Clasificador MLP
El MLPClassifier puede funcionar bien con datos escasos cuando los datos de entrada están estandarizados, ya que utiliza el descenso de gradiente para la optimización.
Aquí puede ver la implementación de MLP Classifier, junto con un montón de otros algoritmos, con la ayuda de ChatGPT.
Clasificador de árbol de decisión
Puede funcionar bien con datos escasos cuando la cantidad de características es pequeña. Si no sabes de árboles de decisión, te expliqué árboles de decisión y bosques aleatorios aquí, que será nuestro modelo final para analizar los modelos de datos dispersos.
Clasificador de bosque aleatorio
RandomForestClassifier puede funcionar bien con datos escasos cuando la cantidad de características es pequeña.

Imagen del autor
Ahora, le mostraré cómo funcionan estos modelos en los datos generados. Pero agregaré otro algoritmo para ver si estos algoritmos superarán a este algoritmo (que generalmente no es bueno para datos dispersos) o no.
Ejemplo de código
En esta sección, probaremos varios modelos de aprendizaje automático en un conjunto de datos escaso, que es un conjunto de datos con muchos valores vacíos o cero.
Calcularemos la escasez del conjunto de datos y evaluaremos los modelos utilizando la puntuación F1.
Luego, crearemos un marco de datos con los puntajes F1 para cada modelo para comparar su desempeño. Además, filtraremos cualquier advertencia que pueda aparecer durante el proceso de evaluación.
import numpy as np
from scipy.sparse import random
import numpy as np
from scipy.sparse import random
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression, Lasso
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.exceptions import ConvergenceWarning
import warnings # Generate a sparse dataset
X = random(1000, 20, density=0.1, format="csr", random_state=42)
y = np.random.randint(2, size=1000) # Calculate the sparsity of the dataset
sparsity = 1.0 - X.nnz / float(X.shape[0] * X.shape[1])
print("Sparsity:", sparsity) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42
) # Train and evaluate multiple classifiers
classifiers = [ SVC(kernel="linear"), LogisticRegression(), KMeans( n_clusters=2, init="k-means++", max_iter=100, random_state=42, algorithm="full", ), KNeighborsClassifier(n_neighbors=5), MLPClassifier( hidden_layer_sizes=(100, 50), max_iter=1000, alpha=0.01, solver="sgd", verbose=0, random_state=21, tol=0.000000001, ), DecisionTreeClassifier(), RandomForestClassifier(),
] # Create an empty DataFrame with column names
df = pd.DataFrame(columns=["Classifier", "F1 Score"]) # Filter out the specific warning
warnings.filterwarnings( "ignore", category=ConvergenceWarning
) # Filter warning that mlp classifier will possibly print out. for clf in classifiers: clf.fit(X_train, y_train) y_pred = clf.predict(X_test) f1 = f1_score(y_test, y_pred) df = pd.concat( [ df, pd.DataFrame( {"Classifier": [type(clf).__name__], "F1 Score": [f1]} ), ], ignore_index=True, )
df = df.sort_values(by="F1 Score", ascending=True)
df
Aquí está la salida.
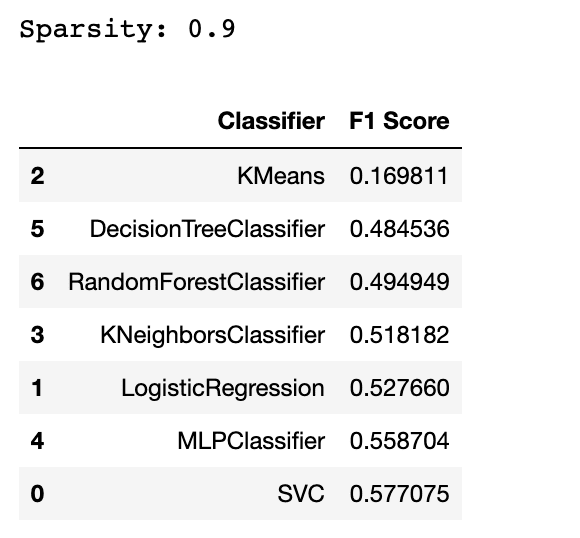
A estas alturas, es posible que detecte un algoritmo que no sea adecuado para los datos dispersos. Sí, la respuesta es el KMeans. ¿Pero por qué?
Por lo general, KMeans no es adecuado para datos dispersos porque se basa en medidas de distancia, lo que puede ser problemático con datos dispersos de gran dimensión.
También hay algunos algoritmos que ni siquiera podemos probar. Por ejemplo, si intenta incluir el clasificador GaussianNB en esta lista, obtendrá un error. Sugiere que el clasificador GaussianNB espera datos densos en lugar de datos dispersos. Esto se debe a que el clasificador GaussianNB asume que los datos de entrada siguen una distribución gaussiana y no son adecuados para datos dispersos.
En conclusión, trabajar con datos escasos puede ser un desafío debido a varios problemas como el sobreajuste, la pérdida de buenos datos, la memoria y los problemas de tiempo.
Sin embargo, hay varios métodos disponibles para trabajar con características escasas, incluida la eliminación de características, el uso de PCA y el hash de características.
Además, ciertos modelos de aprendizaje automático como SVM, Logistic Regression, Lasso, Decision Tree, Random Forest, MLP y los k-vecinos más cercanos son adecuados para manejar datos dispersos.
Estos modelos han sido diseñados para manejar datos dispersos y de alta dimensión de manera eficiente, lo que los convierte en las mejores opciones para problemas de datos dispersos. El uso de estos métodos y modelos puede mejorar la precisión de su modelo y ahorrar tiempo y recursos.
Nate Rosidi es científico de datos y en estrategia de producto. También es profesor adjunto de enseñanza de análisis y es el fundador de StrataScratch, una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas de entrevistas reales de las principales empresas. Conéctate con él en Gorjeo: StrataScratch or Etiqueta LinkedIn.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/04/best-machine-learning-model-sparse-data.html?utm_source=rss&utm_medium=rss&utm_campaign=best-machine-learning-model-for-sparse-data

