
Imagen creada por el autor con DALL•E 3
Puntos clave
- Chain of Code (CoC) es un enfoque novedoso para interactuar con modelos de lenguaje, mejorando las habilidades de razonamiento a través de una combinación de escritura de código y emulación selectiva de código.
- CoC amplía las capacidades de los modelos de lenguaje en tareas lógicas, aritméticas y lingüísticas, especialmente aquellas que requieren una combinación de estas habilidades.
- Con CoC, los modelos de lenguaje escriben código y también emulan partes del mismo que no se pueden compilar, lo que ofrece un enfoque único para resolver problemas complejos.
- CoC muestra eficacia tanto para LM grandes como pequeños.
La idea clave es alentar a los LM a formatear subtareas lingüísticas en un programa como pseudocódigo flexible que el compilador pueda detectar explícitamente comportamientos indefinidos y transferirlos para simularlos con un LM (como un 'LMulator').
Siguen surgiendo nuevas técnicas de estimulación, comunicación y entrenamiento del modelo de lenguaje (LM) para mejorar las capacidades de razonamiento y desempeño de LM. Uno de esos surgimiento es el desarrollo de la Cadena de Código (CoC), un método destinado a avanzar en el razonamiento basado en código en LM. Esta técnica es una fusión de codificación tradicional y la innovadora emulación de ejecución de código LM, lo que crea una poderosa herramienta para abordar tareas complejas de razonamiento lingüístico y aritmético.
CoC se diferencia por su capacidad para manejar problemas complejos que combinan lógica, aritmética y procesamiento del lenguaje, lo cual, como saben los usuarios de LM desde hace bastante tiempo, ha sido durante mucho tiempo una tarea desafiante para los LM estándar. La eficacia de CoC no se limita a modelos grandes, sino que se extiende a varios tamaños, lo que demuestra versatilidad y amplia aplicabilidad en el razonamiento de la IA.
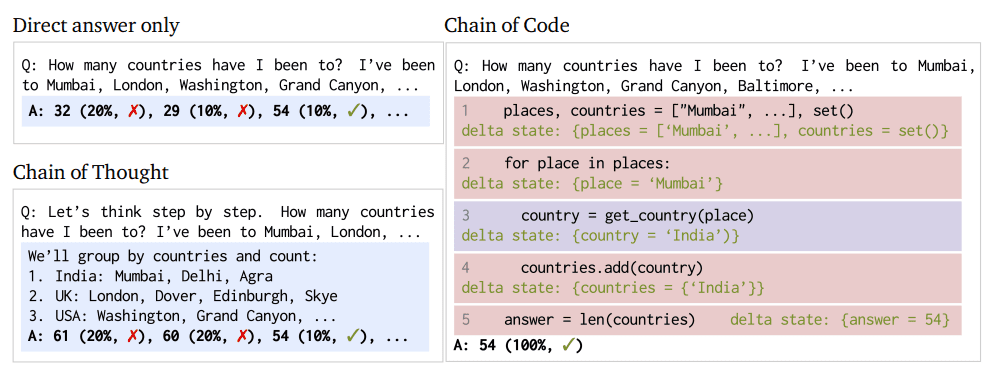
Figura 1 y XNUMX: Enfoque de cadena de código y comparación de procesos (Imagen del artículo)
CoC es un cambio de paradigma en la funcionalidad de LM; Esta no es una simple táctica de incitación para aumentar las posibilidades de provocar la respuesta deseada de un LM. En cambio, CoC redefine el enfoque del LM hacia las tareas de razonamiento antes mencionadas.
En esencia, CoC permite a los LM no solo escribir código sino también emular partes del mismo, especialmente aquellos aspectos que no son directamente ejecutables. Esta dualidad permite a los LM manejar una gama más amplia de tareas, combinando matices lingüísticos con resolución de problemas lógicos y aritméticos. CoC puede formatear tareas lingüísticas como pseudocódigo y cerrar eficazmente la brecha entre la codificación tradicional y el razonamiento de la IA. Este puente permite un sistema flexible y más capaz para la resolución de problemas complejos. El LMulator, un componente principal de las mayores capacidades de CoC, permite la simulación e interpretación de la salida de ejecución de código que de otro modo no estaría directamente disponible para el LM.
CoC ha demostrado un éxito notable en diferentes puntos de referencia, superando significativamente los enfoques existentes como Chain of Thought, particularmente en escenarios que requieren una combinación de razonamiento lingüístico y computacional.
Los experimentos demuestran que Chain of Code supera a Chain of Thought y otras líneas de base en una variedad de puntos de referencia; en BIG-Bench Hard, Chain of Code alcanza el 84%, una ganancia del 12% sobre Chain of Thought.
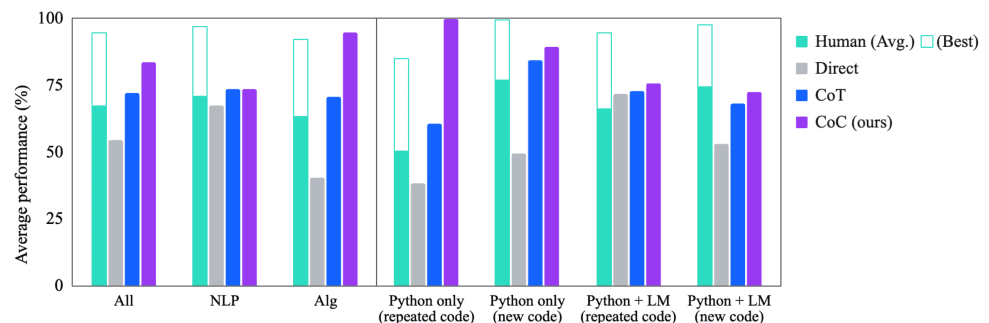
Figura 2 y XNUMX: Comparación del rendimiento de la cadena de código (imagen del artículo)
La implementación de CoC implica un enfoque distintivo para las tareas de razonamiento, integrando procesos de codificación y emulación. CoC anima a los LM a formatear tareas de razonamiento complejas como pseudocódigo, que luego se interpreta y resuelve. Este proceso comprende varios pasos:
- Identificar tareas de razonamiento: determinar la tarea lingüística o aritmética que requiere razonamiento.
- Escritura de código: el LM escribe pseudocódigo o fragmentos de código flexibles para delinear una solución.
- Emulación de código: para partes del código que no son directamente ejecutables, el LM emula el resultado esperado, simulando efectivamente la ejecución del código.
- Combinación de resultados: el LM combina los resultados de la ejecución del código real y su emulación para formar una solución integral al problema.
Estos pasos permiten a los LM abordar una gama más amplia de preguntas de razonamiento "pensando en código", mejorando así sus capacidades de resolución de problemas.
LMulator, como parte del marco de CoC, puede ayudar significativamente a refinar tanto el código como el razonamiento de algunas maneras específicas:
- Identificación y simulación de errores: cuando un modelo de lenguaje escribe código que contiene errores o partes no ejecutables, LMulator puede simular cómo se comportaría este código si se ejecutara, revelando errores lógicos, bucles infinitos o casos extremos, y guiando el LM. repensar y ajustar la lógica del código.
- Manejo de comportamientos indefinidos: en los casos en los que el código implica un comportamiento indefinido o ambiguo que un intérprete estándar no puede ejecutar, LMulator utiliza la comprensión del contexto y la intención del modelo de lenguaje para inferir cuál debería ser el resultado o el comportamiento, proporcionando un resultado simulado y razonado donde es tradicional. la ejecución fallaría.
- Mejorar el razonamiento en el código: cuando se requiere una combinación de razonamiento lingüístico y computacional, LMulator permite que el modelo de lenguaje itere sobre su propia generación de código, simulando los resultados de varios enfoques, "razonando" de manera efectiva a través del código, lo que lleva a resultados más precisos y eficientes. soluciones.
- Exploración de casos extremos: LMulator puede explorar y probar cómo el código maneja casos extremos simulando diferentes entradas, lo cual es particularmente útil para garantizar que el código sea sólido y pueda manejar una variedad de escenarios.
- Bucle de retroalimentación para el aprendizaje: a medida que LMulator simula e identifica problemas o posibles mejoras en el código, el modelo de lenguaje puede utilizar esta retroalimentación para aprender y perfeccionar su enfoque de codificación y resolución de problemas, que es un proceso de aprendizaje continuo que mejora la capacidades de codificación y razonamiento del modelo a lo largo del tiempo.
LMulator mejora la capacidad del modelo de lenguaje para escribir, probar y refinar código al proporcionar una plataforma para simulación y mejora iterativa.
La técnica CoC es un avance en la mejora de las capacidades de razonamiento de los LM. CoC amplía el alcance de los problemas que los LM pueden abordar al integrar la escritura de código con la emulación selectiva de código. Este enfoque demuestra el potencial de la IA para manejar tareas más complejas del mundo real que requieren un pensamiento matizado. Es importante destacar que CoC ha demostrado sobresalir tanto en LM pequeños como grandes, lo que abre un camino para que la creciente variedad de modelos más pequeños mejoren potencialmente sus capacidades de razonamiento y acerquen su efectividad a la de los modelos más grandes.
Para una comprensión más profunda, consulte el documento completo aquí.
Mateo Mayo (@mattmayo13) tiene una maestría en informática y un diploma de posgrado en minería de datos. Como editor en jefe de KDnuggets, Matthew tiene como objetivo hacer accesibles conceptos complejos de ciencia de datos. Sus intereses profesionales incluyen el procesamiento del lenguaje natural, los algoritmos de aprendizaje automático y la exploración de la IA emergente. Lo impulsa la misión de democratizar el conocimiento en la comunidad de ciencia de datos. Matthew ha estado codificando desde que tenía 6 años.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/enhancing-llm-reasoning-unveiling-chain-of-code-prompting?utm_source=rss&utm_medium=rss&utm_campaign=enhancing-llm-reasoning-unveiling-chain-of-code-prompting

