Imagen del autor
Estamos viendo un rápido desarrollo de ChatGPT alternativas de código abierto, pero nadie está trabajando en la alternativa GPT-4, que proporciona multimodalidad. GPT-4 es un modelo multimodal avanzado y potente que acepta imágenes y texto como respuesta de texto de entrada y salida. Puede resolver problemas complejos con mayor precisión y aprender de sus errores.
En esta publicación, aprenderemos sobre MiniGPT-4, una alternativa de código abierto a GPT-4 de OpenAI que puede comprender tanto el contexto visual como el textual sin dejar de ser liviano.
Al igual que GPT-4, MiniGPT-4 puede exhibir una generación detallada de descripciones de imágenes, escribir historias usando imágenes y crear un sitio web usando la interfaz de usuario dibujada a mano. Lo logra mediante la utilización de un modelo de lenguaje grande (LLM) más avanzado.
Puede experimentarlo usted mismo probando la demostración: MiniGPT-4: un espacio para abrazar la cara de Vision-CAIR.
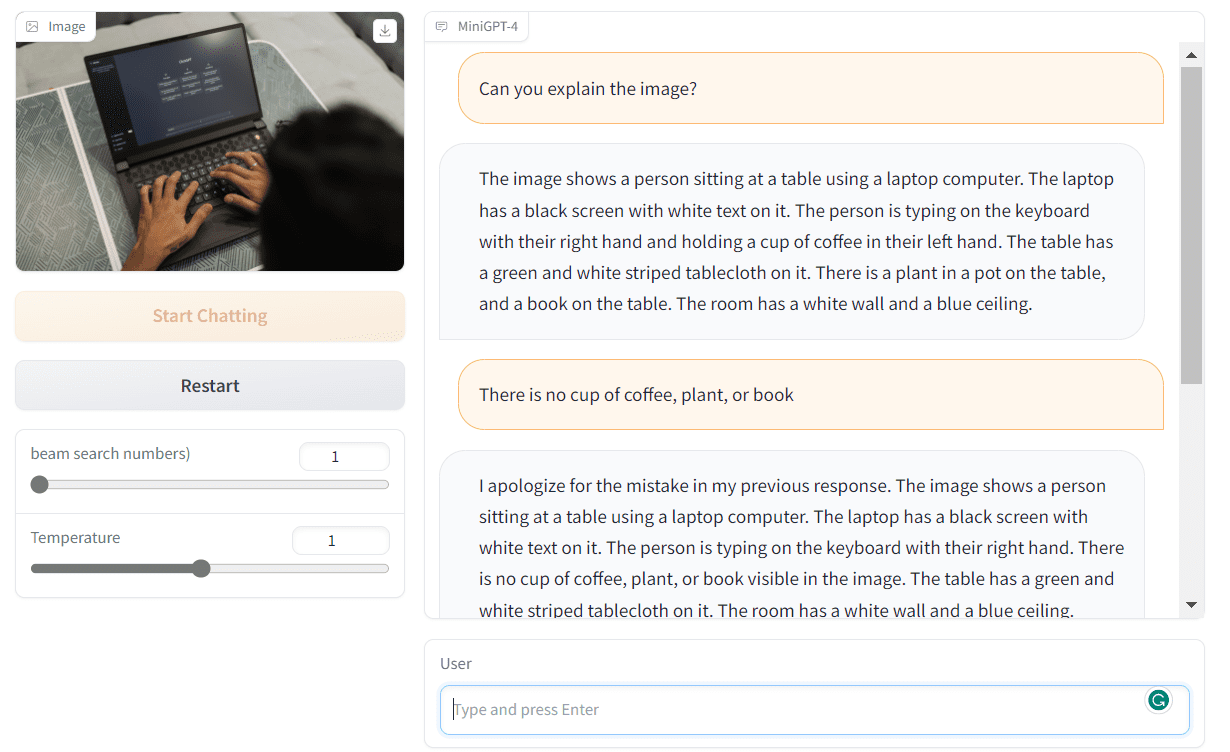
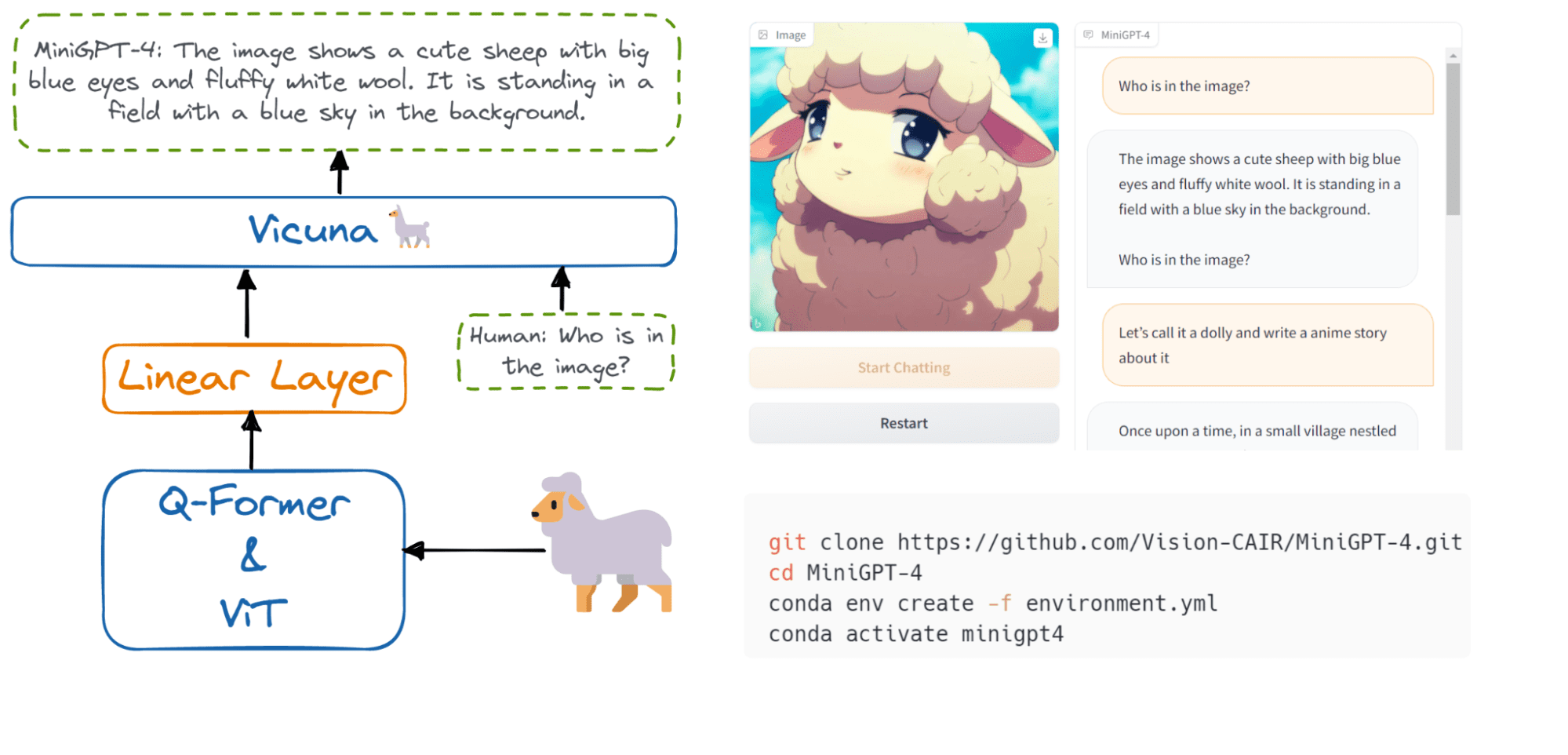
Imagen por Autor | Demostración de MiniGPT-4
Los autores de MiniGPT-4: mejora de la comprensión del lenguaje visual con modelos avanzados de lenguaje grande descubrió que el entrenamiento previo en pares de imagen-texto sin procesar podría producir resultados deficientes que carecen de coherencia, incluida la repetición y oraciones fragmentadas. Para contrarrestar este problema, seleccionaron un conjunto de datos bien alineado y de alta calidad y ajustaron el modelo utilizando una plantilla conversacional.
El modelo MiniGPT-4 es altamente eficiente desde el punto de vista computacional, ya que han entrenado solo una capa de proyección que utiliza aproximadamente 5 millones de pares de imagen y texto alineados.
MiniGPT-4 alinea un codificador visual congelado con un LLM congelado llamado Vicuna usando solo una capa de proyección. El codificador visual consta de modelos ViT y Q-Former preentrenados que están conectados a un modelo avanzado de lenguaje grande de Vicuna a través de una única capa de proyección lineal.
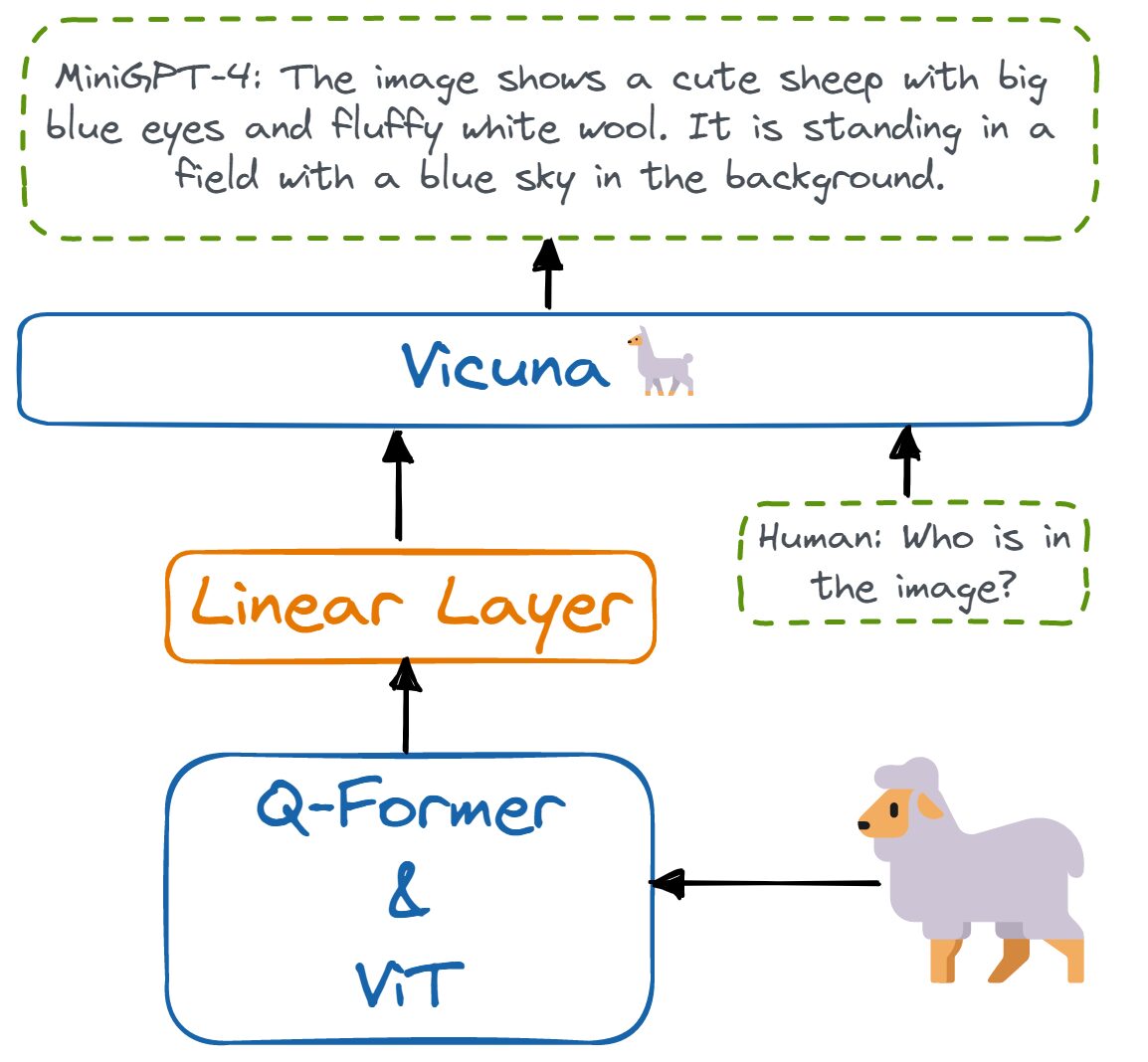
Imagen por autor | La arquitectura de MiniGPT-4.
MiniGPT-4 solo requiere entrenar la capa lineal para alinear las características visuales con Vicuna. Por lo tanto, es liviano, requiere menos recursos computacionales y produce resultados similares a GPT-4.
Si miras los resultados oficiales en minigpt-4.github.io, verá que los autores han creado un sitio web cargando la interfaz de usuario dibujada a mano y pidiéndole que escriba un sitio web HTML/JS. El MiniGPT-4 entendió el contexto y generó código HTML, CSS y JS. Es asombroso.
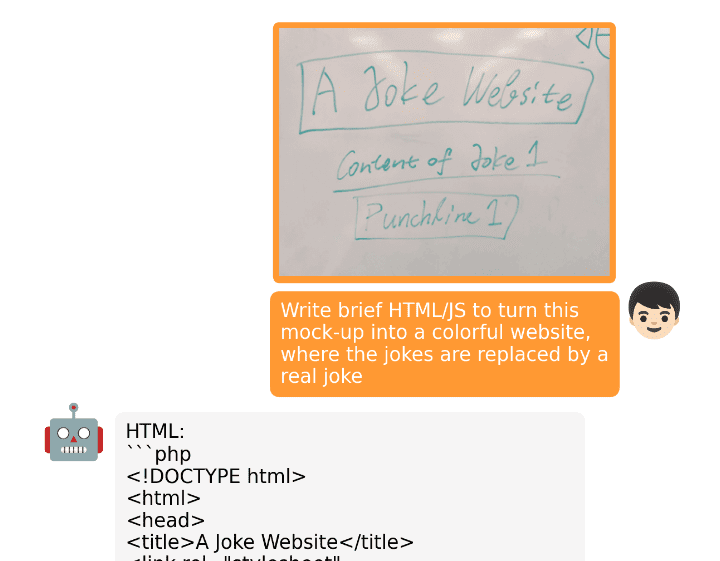

Imagen de minigpt-4.github.io
También han mostrado cómo puede usar el modelo para generar una receta proporcionando imágenes de alimentos, escribiendo anuncios para el producto, describiendo una imagen compleja, explicando la pintura y más.
Probemos esto por nuestra cuenta dirigiéndonos a la MiniGPT-4 manifestación. Como podemos ver, proporcioné la imagen generada por Bing AI y le pedí al MiniGPT-4 que escribiera una historia usándola. El resultado es asombroso.
La historia es coherente.
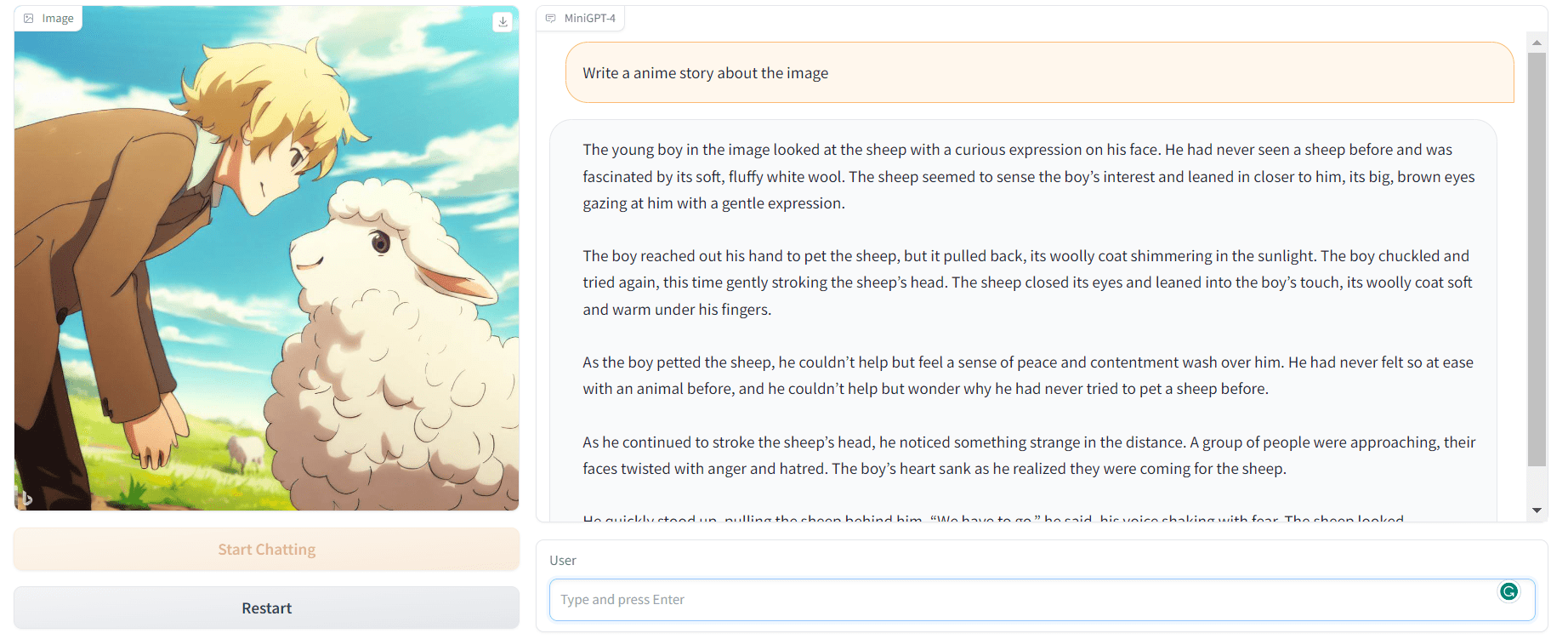
Imagen por Autor | Demostración de MiniGPT-4
Quería saber más, así que le pedí que siguiera escribiendo y, al igual que un chatbot de IA, siguió escribiendo la trama.
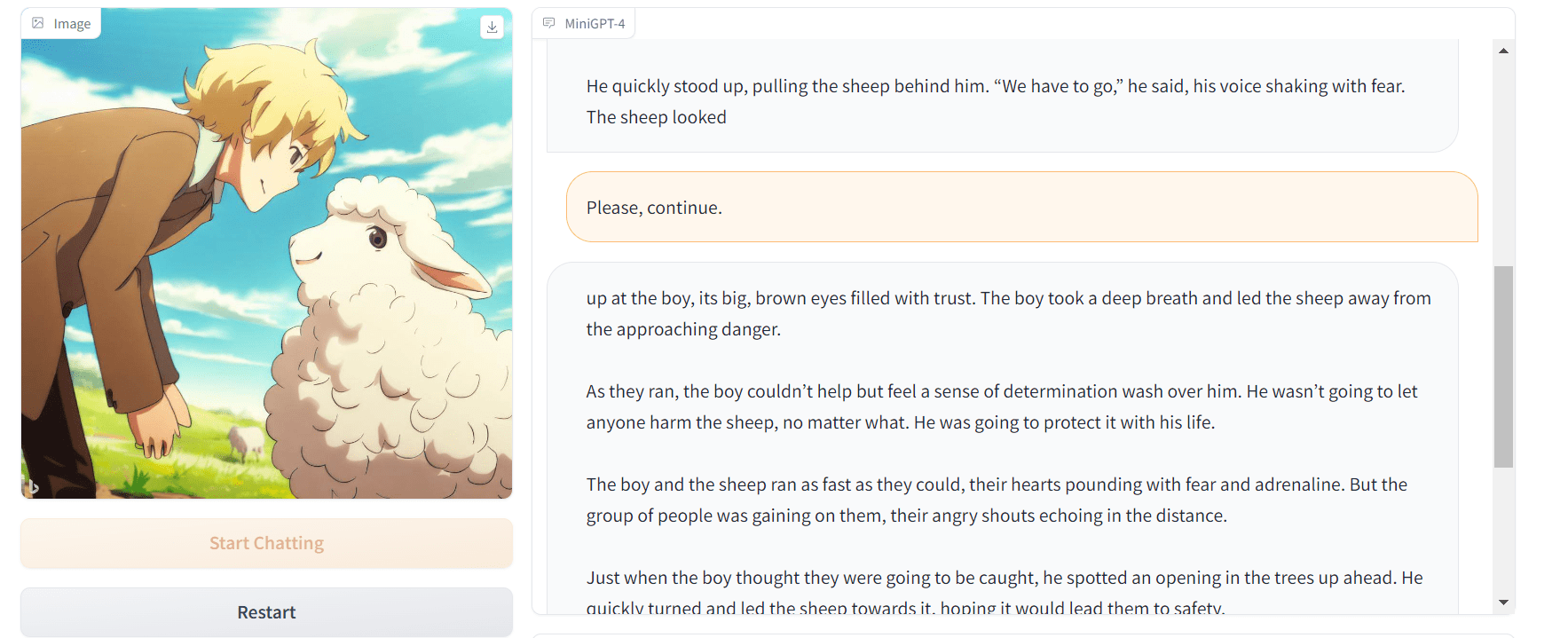
Imagen por Autor | Demostración de MiniGPT-4
En el segundo ejemplo, le pedí que me ayudara a mejorar el diseño de la imagen y luego le pedí que generara subtítulos para el blog usando la imagen.
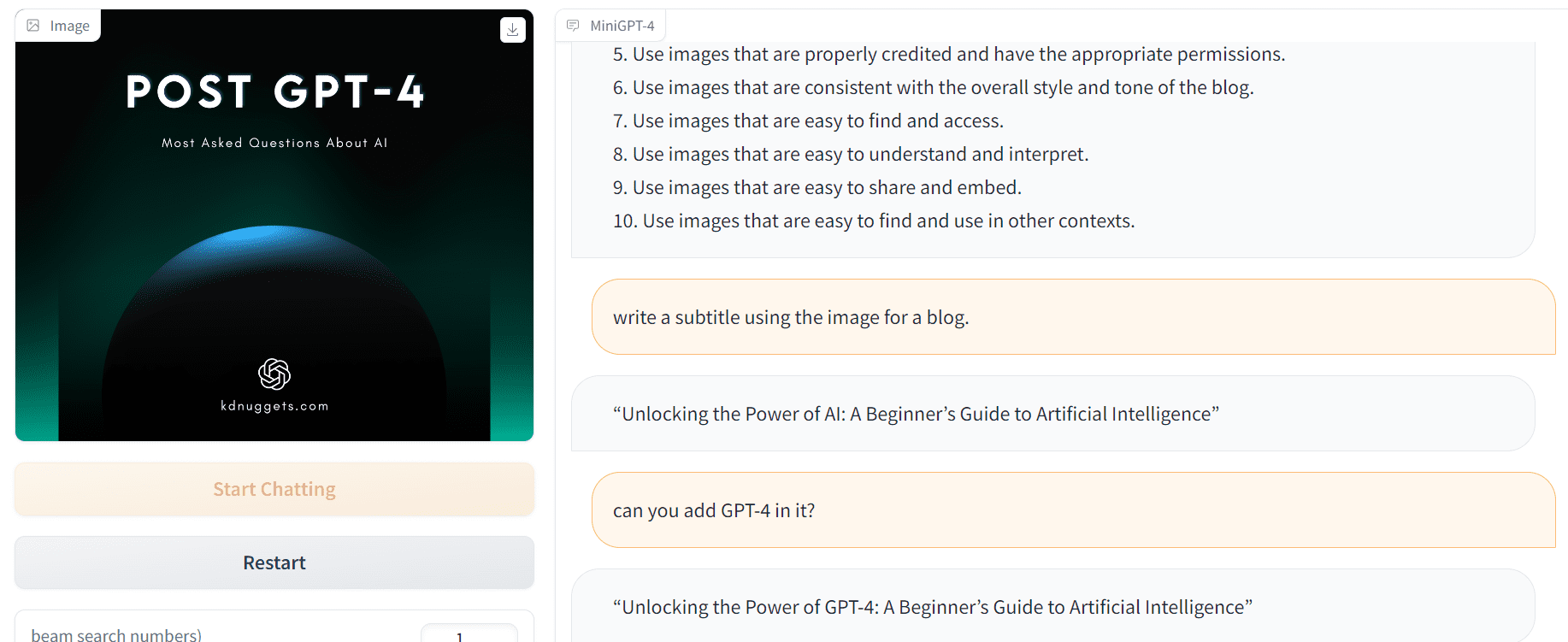
Imagen por Autor | Demostración de MiniGPT-4
MiniGPT-4 es increíble. Aprende de los errores y produce respuestas de alta calidad.
MiniGPT-4 tiene muchas capacidades avanzadas de visión y lenguaje, pero aún enfrenta varias limitaciones.
- Actualmente, la inferencia del modelo es lenta incluso con GPU de gama alta, lo que puede generar resultados lentos.
- El modelo se basa en LLM, por lo que hereda sus limitaciones, como la capacidad de razonamiento poco confiable y el conocimiento inexistente alucinante.
- El modelo tiene una percepción visual limitada y puede tener dificultades para reconocer información textual detallada en las imágenes.
El proyecto viene con entrenamiento, ajuste e inferencia del código fuente. También incluye pesos de modelos disponibles públicamente, conjunto de datos, trabajo de investigación, video de demostración y enlace a la demostración de Hugging Face.
Puede comenzar a piratear, comenzar a ajustar el modelo en su conjunto de datos o simplemente experimentar el modelo a través de varias instancias de la demostración oficial en la página oficial.
Es la primera versión del modelo. Verá una versión más mejorada en los próximos días, así que estad atentos.
Abid Ali Awan (@ 1abidaliawan) es un profesional científico de datos certificado al que le encanta crear modelos de aprendizaje automático. Actualmente, se está enfocando en la creación de contenido y escribiendo blogs técnicos sobre aprendizaje automático y tecnologías de ciencia de datos. Abid tiene una Maestría en Gestión de Tecnología y una licenciatura en Ingeniería de Telecomunicaciones. Su visión es construir un producto de IA utilizando una red neuronal gráfica para estudiantes que luchan contra enfermedades mentales.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/04/minigpt4-lightweight-alternative-gpt4-enhanced-visionlanguage-understanding.html?utm_source=rss&utm_medium=rss&utm_campaign=minigpt-4-a-lightweight-alternative-to-gpt-4-for-enhanced-vision-language-understanding

