Imagen del autor
El aprendizaje profundo es un tipo de inteligencia desarrollado para imitar los sistemas y las neuronas del cerebro humano, que desempeñan un papel esencial en el proceso de pensamiento humano.
Esta tecnología utiliza redes neuronales profundas, que están compuestas por capas de neuronas artificiales que pueden analizar y procesar grandes cantidades de datos, lo que les permite aprender y mejorar con el tiempo.
Nosotros, los humanos, confiamos en nuestros cinco sentidos para interpretar el mundo que nos rodea. Usamos nuestros sentidos de la vista, el oído, el tacto, el gusto y el olfato para recopilar información sobre nuestro entorno y darle sentido.
De manera similar, el aprendizaje multimodal es un nuevo y emocionante campo de la IA que busca replicar esta capacidad mediante la combinación de información de múltiples modelos. Al integrar información de diversas fuentes, como texto, imagen, audio y video, los modelos multimodales pueden generar una comprensión más rica y completa de los datos subyacentes, desbloquear nuevos conocimientos y habilitar una amplia gama de aplicaciones.
Las técnicas utilizadas en el aprendizaje multimodal incluyen enfoques basados en fusión, enfoques basados en alineaciones y fusión tardía.
En este artículo, exploraremos los fundamentos del aprendizaje multimodal, incluidas las diferentes técnicas utilizadas para fusionar información de diversas fuentes, así como sus muchas aplicaciones interesantes, desde el reconocimiento de voz hasta los automóviles autónomos y más.

Imagen del autor
El aprendizaje multimodal es un subcampo de la inteligencia artificial que busca procesar y analizar datos de múltiples modalidades de manera efectiva.
En términos simples, esto significa combinar información de diferentes fuentes, como texto, imagen, audio y video, para generar una comprensión más completa y precisa de los datos subyacentes.
El concepto de aprendizaje multimodal ha encontrado aplicaciones en una amplia gama de temas, incluido el reconocimiento de voz, el automóvil autónomo y el reconocimiento de emociones. Hablaremos de ellos en los siguientes apartados.
Las técnicas de aprendizaje multimodal permiten que los modelos procesen y analicen datos de múltiples modalidades de manera efectiva, proporcionando una comprensión más completa y precisa de los datos subyacentes.
En la siguiente sección, mencionaremos estas técnicas, pero antes de hacerlo, hablemos sobre la combinación de modelos.
Estos dos conceptos pueden parecer similares, pero pronto descubrirá que no lo son.
La combinación de modelos es una técnica de aprendizaje automático que implica el uso de varios modelos para mejorar el rendimiento de un solo modelo.
La idea detrás de la combinación de modelos es que las fortalezas de un modelo pueden compensar la debilidad de otro, lo que da como resultado una predicción más precisa y sólida. Los modelos de conjunto, el apilamiento y el embolsado son técnicas utilizadas para combinar modelos.

Imagen del autor
Modelos de conjunto

Imagen del autor
Los modelos de conjunto implican la combinación de los resultados de múltiples modelos base para producir un mejor modelo general.
Un ejemplo de un modelo de conjunto son los bosques aleatorios. Los bosques aleatorios son un algoritmo de árbol de decisión que combina varios árboles de decisión para mejorar la precisión del modelo. Cada árbol de decisión se entrena en un subconjunto diferente de los datos, y la predicción final se realiza promediando las predicciones de todos los árboles.
Puede ver cómo usar el algoritmo de bosques aleatorios en la biblioteca scikit-learn esta página.
Apilado

Imagen del autor
El apilamiento implica el uso de las salidas de varios modelos como entradas para otro modelo.
Un ejemplo real de apilamiento es el procesamiento del lenguaje natural, donde se puede aplicar al análisis de sentimientos.
Por ejemplo, la Conjunto de datos de Stanford Sentiment Treebank contiene reseñas de películas con etiquetas de opinión que van desde muy negativas hasta muy positivas. En este caso, múltiples modelos como bosque al azar, Máquinas de vectores de soporte (SVM), y Naive Bayes se puede entrenar para predecir el sentimiento de las reseñas.
Luego, las predicciones de estos modelos se pueden combinar mediante un metamodelo, como una regresión logística o una red neuronal, que se entrena con los resultados de los modelos base para realizar la predicción final.
El apilamiento puede mejorar la precisión de la predicción de opiniones y hacer que el análisis de opiniones sea más sólido.
Harpillera

Imagen del autor
El embolsado es otra forma de crear conjuntos, donde varios modelos base se entrenan en diferentes subconjuntos de datos y sus predicciones se promedian para tomar una decisión final.
Un ejemplo de embolsado es el método de agregación de arranque, en el que se entrenan varios modelos en diferentes subconjuntos de los datos de entrenamiento. La predicción final se realiza promediando las predicciones de todos los modelos.
Un ejemplo de embolsado en la vida real está en las finanzas. El Conjunto de datos S&P 500 contiene datos históricos sobre los precios de las acciones de las 500 empresas más grandes que cotizan en bolsa en los Estados Unidos entre 2012 y 2018.
El embolsado se puede usar en este conjunto de datos entrenando múltiples modelos en scikit-learn, como bosques al azar y aumento de gradiente, para predecir los precios de las acciones de las empresas.
Cada modelo se entrena en un subconjunto diferente de los datos de entrenamiento y sus predicciones se promedian para hacer la predicción final. El uso de embolsado puede mejorar la precisión de la predicción del precio de las acciones y hacer que el análisis financiero sea más sólido.
Al combinar modelos, los modelos se entrenan de forma independiente y la predicción final se realiza combinando los resultados de estos modelos utilizando técnicas como modelos de conjunto, apilamiento o embolsado.
La combinación de modelos es particularmente útil cuando los modelos individuales tienen fortalezas y debilidades complementarias, ya que la combinación puede conducir a una predicción más precisa y sólida.
En el aprendizaje multimodal, el objetivo es combinar información de diferentes modalidades para realizar una tarea de predicción. Esto puede implicar el uso de técnicas como el enfoque basado en la fusión, el enfoque basado en la alineación o la fusión tardía para crear una representación de alta dimensión que capture la información semántica de los datos de cada modalidad.
El aprendizaje multimodal es particularmente útil cuando diferentes modalidades brindan información complementaria que puede mejorar la precisión de la predicción.
La principal diferencia entre la combinación de modelos y el aprendizaje multimodal es que la combinación de modelos implica el uso de múltiples modelos para mejorar el rendimiento de un solo modelo. Por el contrario, el aprendizaje multimodal implica aprender y combinar información de múltiples modalidades, como imágenes, texto y audio, para realizar una prueba de predicción.
Ahora, veamos las técnicas de aprendizaje multimodal.

Imagen del autor
Enfoque basado en la fusión
El enfoque basado en la fusión implica la codificación de las diferentes modalidades en un espacio de representación común, donde las representaciones se fusionan para crear una única representación invariable de modalidad que captura la información semántica de todas las modalidades.
Este enfoque se puede dividir en técnicas de fusión temprana y de fusión media, dependiendo de cuándo se produzca la fusión.
Subtítulos de texto
Un ejemplo típico de un enfoque basado en la fusión es una imagen y subtítulos de texto.
Es el enfoque basado en la fusión porque las características visuales de la imagen y la información semántica del texto se codifican en un espacio de representación común y luego se fusionan para generar una única representación invariable de modalidad que captura la información semántica de ambas modalidades.
En concreto, las características visuales de la imagen se extraen mediante una red neuronal convolucional (CNN) y la información semántica del texto se captura mediante una red neuronal recurrente (RNN).
Estas dos modalidades se codifican luego en un espacio de representación común. Las características visuales y textuales se fusionan utilizando técnicas de concatenación o multiplicación de elementos para crear una única representación invariable de modalidad.
Esta representación final se puede usar para generar una leyenda para la imagen.
Un conjunto de datos de código abierto que se puede usar para realizar subtítulos de imágenes y texto es el Conjunto de datos Flickr30k, que contiene 31,000 imágenes junto con cinco leyendas por imagen. Este conjunto de datos contiene imágenes de varias escenas cotidianas, con cada imagen anotada por varias personas para proporcionar subtítulos diversos.

Fuente: https://paperswithcode.com/dataset/flickr30k-cna
El conjunto de datos de Flickr30k se puede utilizar para aplicar el enfoque basado en la fusión para los subtítulos de imágenes y texto mediante la extracción de características visuales de las CNN previamente entrenadas y el uso de técnicas como incrustaciones de palabras o representaciones de bolsas de palabras para características textuales. La representación fusionada resultante se puede utilizar para generar subtítulos más precisos e informativos.
Enfoque basado en la alineación
Este enfoque implica alinear las diferentes modalidades para que puedan compararse directamente.
El objetivo es crear representaciones de modalidad invariable que se puedan comparar entre modalidades. Este enfoque es ventajoso cuando las modalidades comparten una relación directa, como en el reconocimiento de voz audiovisual.
Reconocimiento de lenguaje de señas

Imagen del autor
Un ejemplo de un enfoque basado en la alineación es la tarea de reconocimiento del lenguaje de señas.
Este uso implica el enfoque basado en la alineación porque requiere que el modelo alinee la información temporal de las modalidades tanto visual (cuadros de video) como de audio (forma de onda de audio).
La tarea es que el modelo reconozca los gestos del lenguaje de señas y los traduzca en texto. Los gestos se capturan con una cámara de video, y el audio correspondiente y las dos modalidades deben estar alineados para reconocer los gestos con precisión. Esto implica identificar la alineación temporal entre los cuadros de video y la forma de onda de audio para reconocer los gestos y las palabras habladas correspondientes.
Un conjunto de datos de código abierto para el reconocimiento del lenguaje de señas es el Conjunto de datos RWTH-PHOENIX-Weather 2014T que contiene grabaciones de video del lenguaje de señas alemán (DGS) de varios signatarios. El conjunto de datos incluye modalidades visuales y de audio, lo que lo hace adecuado para tareas de aprendizaje multimodal que requieren enfoques basados en la alineación.
Fusión tardía
Este enfoque implica combinar las predicciones de modelos entrenados en cada modalidad por separado. Las predicciones individuales luego se combinan para crear una predicción final. Este enfoque es particularmente útil cuando las modalidades no están directamente relacionadas o las modalidades individuales brindan información complementaria.
Reconocimiento de emociones

Imagen del autor
Un ejemplo de la vida real de fusión tardía es el reconocimiento de emociones en la música. En esta tarea, el modelo debe reconocer el contenido emocional de una pieza musical utilizando tanto las funciones de audio como las letras.
El enfoque de fusión tardía se aplica en este ejemplo porque combina las predicciones de modelos entrenados en modalidades separadas (características de audio y letras) para crear una predicción final.
Los modelos individuales se entrenan por separado en cada modalidad y las predicciones se combinan en una etapa posterior. Por lo tanto, fusión tardía.
Las características de audio se pueden extraer usando técnicas como los coeficientes cepstrales de frecuencia Mel (MFCC), mientras que las letras se pueden codificar usando técnicas como la bolsa de palabras o incrustaciones de palabras. Los modelos se pueden entrenar por separado en cada modalidad y las predicciones se pueden combinar mediante la fusión tardía para generar una predicción final.
El conjunto de datos DEAM fue diseñado para respaldar la investigación sobre el reconocimiento y análisis de emociones musicales, e incluye funciones de audio y letras para una colección de más de 2,000 canciones. Las características de audio incluyen varios descriptores, como MFCC, contraste espectral y características de ritmo, mientras que las letras se representan mediante técnicas de bolsa de palabras y de incrustación de palabras.
El enfoque de fusión tardía se puede aplicar al conjunto de datos DEAM al combinar las predicciones de modelos separados entrenados en cada modalidad (audio y letras).

Fuente: Conjunto de datos DEAM: análisis emocional en la música
Por ejemplo, puede entrenar un modelo de aprendizaje automático independiente para predecir el contenido emocional de cada canción mediante funciones de audio, como MFCC y contraste espectral.
Se puede entrenar otro modelo para predecir el contenido emocional de cada canción usando la letra, representada usando técnicas como la bolsa de palabras o incrustaciones de palabras.
Después de entrenar los modelos individuales, las predicciones de cada modelo se pueden combinar utilizando el enfoque de fusión tardía para generar una predicción final.
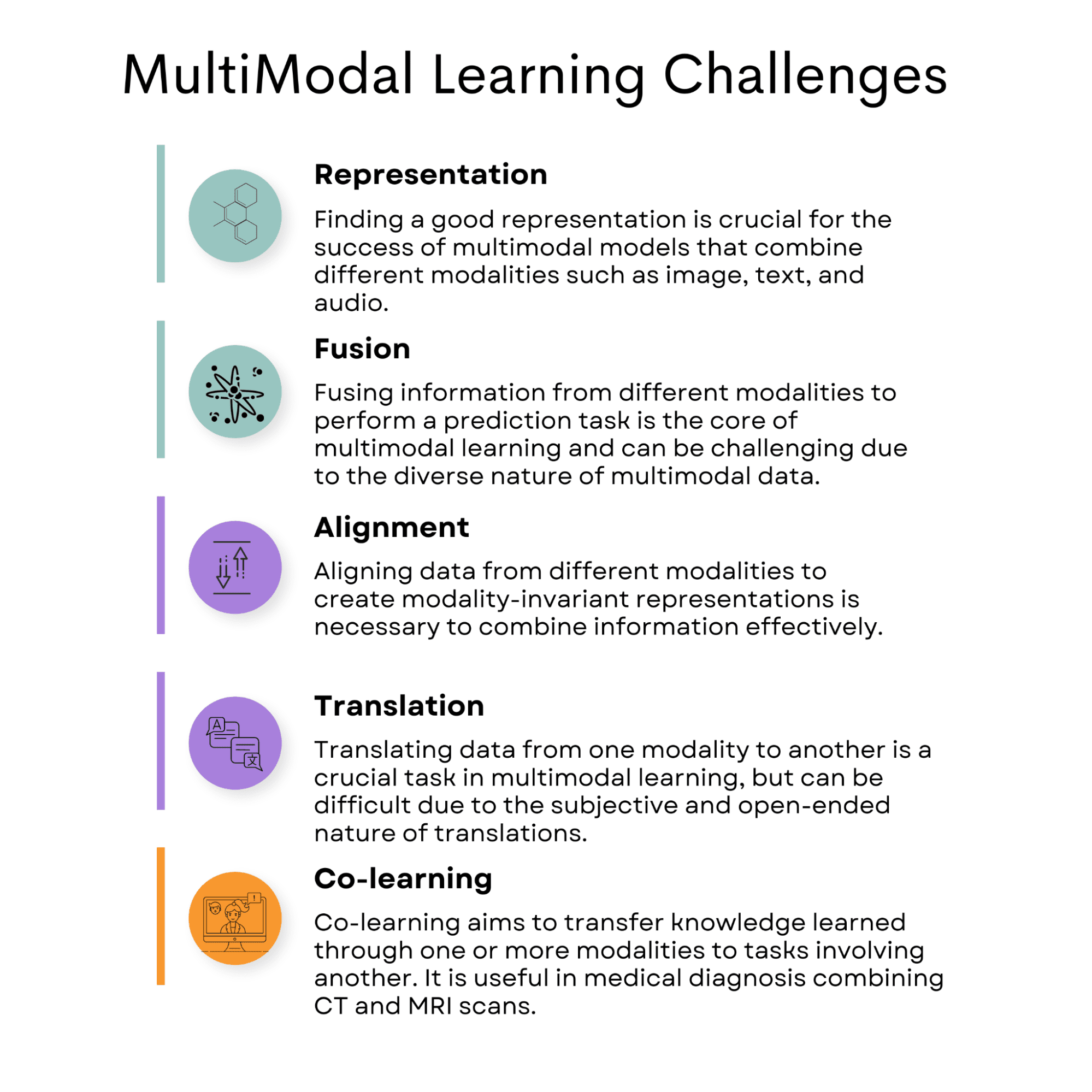
Imagen del autor
Representación
Los datos multimodales pueden venir en diferentes modalidades, como texto y audio. Combinarlos de una manera que conserve sus características individuales sin dejar de capturar sus relaciones puede ser un desafío.
Esto puede generar problemas como que el modelo no se generalice bien, esté sesgado hacia una modalidad o no capture de manera efectiva la información conjunta.
Para resolver problemas de representación en el aprendizaje multimodal, se pueden emplear varias estrategias:
representación conjunta: Como se mencionó anteriormente, este enfoque implica la codificación de ambas modalidades en un espacio compartido de alta dimensión. Se pueden utilizar técnicas como los métodos de fusión basados en el aprendizaje profundo para aprender representaciones conjuntas óptimas.
Representación coordinada: En lugar de fusionar las modalidades directamente, este enfoque mantiene codificaciones separadas para cada modalidad pero asegura que sus representaciones estén relacionadas y transmitan el mismo significado. Se pueden utilizar mecanismos de alineación o atención para lograr esta coordinación.
Pares de pie de foto
El Conjunto de datos MS COCO se usa ampliamente en la investigación de procesamiento de lenguaje natural y visión por computadora, y contiene muchas imágenes con objetos en varios contextos, junto con múltiples leyendas textuales que describen el contenido de las imágenes.
Cuando se trabaja con el conjunto de datos MS COCO, dos estrategias principales para manejar los desafíos de representación son la representación conjunta y la representación coordinada.
representación conjunta: Al combinar la información de ambas modalidades, el modelo puede comprender su significado combinado. Por ejemplo, puede usar un modelo de aprendizaje profundo con capas diseñadas para procesar y fusionar funciones de datos de imagen y texto. Esto da como resultado una representación conjunta que captura la relación entre la imagen y el pie de foto.
Representación coordinada: En este enfoque, la imagen y el pie de foto se codifican por separado, pero sus representaciones están relacionadas y transmiten el mismo significado. En lugar de fusionar directamente las modalidades, el modelo mantiene codificaciones separadas para cada modalidad al tiempo que garantiza que estén asociadas de manera significativa.
Se pueden emplear estrategias de representación tanto conjuntas como coordinadas cuando se trabaja con el conjunto de datos MS COCO para manejar de manera efectiva los desafíos del aprendizaje multimodal y crear modelos que puedan procesar y comprender las relaciones entre la información visual y textual.
Fusion
Fusion es una técnica utilizada en el aprendizaje multimodal para combinar información de diferentes modalidades de datos, como texto, imágenes y audio, para crear una comprensión más completa de una situación o contexto particular. El proceso de fusión ayuda a los modelos a hacer mejores predicciones y decisiones basadas en la información combinada en lugar de depender de una sola modalidad.
Un desafío en el aprendizaje multimodal es determinar la mejor manera de fusionar las diferentes modalidades. Diferentes técnicas de fusión pueden ser más efectivas que otras para tareas o situaciones específicas, y encontrar la correcta puede ser difícil.
Calificación de la película

Imagen del autor
Un ejemplo de la vida real de fusión en el aprendizaje multimodal es un sistema de recomendación de películas. En este caso, el sistema podría utilizar datos de texto (descripciones de películas, reseñas o perfiles de usuario), datos de audio (bandas sonoras, diálogos) y datos visuales (carteles de películas, videoclips) para generar recomendaciones personalizadas para los usuarios.
El proceso de fusión combina estas diferentes fuentes de información para crear una comprensión más precisa y significativa de las preferencias e intereses del usuario, lo que lleva a mejores sugerencias de películas.
Un conjunto de datos de la vida real adecuado para desarrollar un sistema de recomendación de películas con fusión es el Conjunto de datos MovieLens. MovieLens es una colección de calificaciones y metadatos de películas, incluidas las etiquetas generadas por los usuarios, recopiladas por el proyecto GroupLens Research de la Universidad de Minnesota. El conjunto de datos contiene información sobre películas, como títulos, géneros, calificaciones de usuarios y perfiles de usuarios.
Para crear un sistema de recomendación de películas multimodal con el conjunto de datos de MovieLens, puede combinar la información textual (títulos, géneros y etiquetas de películas) con datos visuales adicionales (carteles de películas) y datos de audio (bandas sonoras, diálogos). Puede obtener carteles de películas y datos de audio de otras fuentes, como IMDB o TMDB.
¿Cómo la fusión podría ser un desafío?
Fusion puede ser un desafío al aplicar el aprendizaje multimodal a este conjunto de datos porque necesita determinar la forma más efectiva de combinar las diferentes modalidades.
Por ejemplo, debe encontrar el equilibrio adecuado entre la importancia de los datos textuales (géneros, etiquetas), datos visuales (carteles) y datos de audio (bandas sonoras, diálogo) para la tarea de recomendación.
Además, algunas películas pueden tener datos faltantes o incompletos, como carteles o muestras de audio que faltan.
En este caso, el sistema de recomendaciones debe ser lo suficientemente sólido para manejar los datos que faltan y aun así brindar recomendaciones precisas basadas en la información disponible.
En resumen, con el conjunto de datos de MovieLens, junto con datos visuales y de audio adicionales, puede desarrollar un sistema de recomendación de películas multimodal que aproveche las técnicas de fusión.
Sin embargo, pueden surgir desafíos a la hora de determinar el método de fusión más efectivo y manejar datos faltantes o incompletos.
Alineación
La alineación es una tarea crucial en aplicaciones como el reconocimiento de voz audiovisual. En esta tarea, las modalidades de audio y visual deben estar alineadas para reconocer el habla con precisión.
Los investigadores han utilizado métodos de alineación como el modelo oculto de Markov y la deformación dinámica del tiempo para lograr esta sincronización.
Por ejemplo, el modelo oculto de Markov se puede usar para modelar la relación entre las modalidades de audio y visual y para estimar la alineación entre la forma de onda de audio y los cuadros de video. La deformación temporal dinámica se puede utilizar para alinear las secuencias de datos estirándolas o comprimiéndolas en el tiempo para que coincidan más estrechamente.
Reconocimiento de voz audiovisual

Imagen del autor
Al alinear los datos de audio y visuales en el conjunto de datos de GRID Corpus, los investigadores pueden crear representaciones coordinadas que capturan las relaciones entre las modalidades y luego usar estas representaciones para reconocer el habla con precisión usando ambas modalidades.
El Conjunto de datos del corpus GRID contiene grabaciones audiovisuales de hablantes que producen oraciones en inglés. Cada grabación incluye la forma de onda de audio y el video de la cara del hablante, que captura el movimiento de los labios y otras características faciales. El conjunto de datos se usa ampliamente para la investigación en reconocimiento de voz audiovisual, donde el objetivo es reconocer el habla con precisión utilizando modalidades de audio y visuales.
Traducción
La traducción es un desafío multimodal común en el que se deben alinear diferentes modalidades de datos, como texto e imágenes, para crear una representación coherente. Un ejemplo de tal desafío es la tarea de subtitulado de imágenes, donde una imagen debe describirse en lenguaje natural.
En esta tarea, un modelo debe poder reconocer no solo los objetos y el contexto en una imagen, sino también generar una descripción en lenguaje natural que transmita con precisión el significado de la imagen.
Esto requiere alinear las modalidades visuales y textuales para crear representaciones coordinadas que capturen las relaciones entre ellas.
Losa
Una pintura al óleo de pandas meditando en el Tíbet

Referencia: Dall-E
Un ejemplo reciente de un modelo que puede realizar una traducción multimodal es DALL-E2. DALL-E2 es un modelo de red neuronal desarrollado por OpenAI que puede generar imágenes de alta calidad a partir de descripciones textuales. También puede generar descripciones textuales a partir de imágenes, traduciendo efectivamente entre las modalidades visual y textual.
DALL-E2 logra esto aprendiendo un espacio de representación conjunta que captura las relaciones entre las modalidades visual y textual.
El modelo se entrena en un gran conjunto de datos de los pares de imagen y pie de foto y aprende a asociar imágenes con sus pies de foto correspondientes. Luego puede generar imágenes a partir de descripciones textuales al tomar muestras del espacio de representación aprendido y generar descripciones textuales a partir de imágenes al decodificar la representación aprendida.
En general, la traducción multimodal es un desafío importante que requiere alinear diferentes modalidades de datos para crear representaciones coordinadas. Modelos como DALL-E2 pueden realizar esta tarea mediante el aprendizaje de espacios de representación conjunta que capturan las relaciones entre las modalidades visual y textual y se pueden aplicar a tareas como subtítulos de imágenes y respuesta visual a preguntas.
Co-aprendizaje
El co-aprendizaje multimodal tiene como objetivo transferir el conocimiento aprendido a través de una o más modalidades a tareas que involucran a otra.
El co-aprendizaje es especialmente importante en tareas objetivo de bajos recursos, modalidades que faltan total o parcialmente o son ruidosas.
Sin embargo, encontrar métodos efectivos para transferir conocimiento de una modalidad a otra manteniendo el significado semántico es un desafío significativo en el aprendizaje multimodal.
En el diagnóstico médico, diferentes modalidades de imágenes médicas, como tomografías computarizadas y resonancias magnéticas, brindan información complementaria para un diagnóstico. El coaprendizaje multimodal se puede utilizar para combinar estas modalidades para mejorar la precisión del diagnóstico.
Segmentación multimodal de tumores

Fuente: https://www.med.upenn.edu/sbia/brats2018.html
Por ejemplo, en el caso de los tumores cerebrales, las imágenes de resonancia magnética brindan imágenes de alta resolución de los tejidos blandos, mientras que las tomografías computarizadas brindan imágenes detalladas de la estructura ósea. La combinación de estas modalidades puede proporcionar una imagen completa de la condición del paciente e informar las decisiones de tratamiento.
Un conjunto de datos que incluye resonancias magnéticas y tomografías computarizadas de tumores cerebrales para su uso en el coaprendizaje multimodal es el multimodal Conjunto de datos de segmentación de tumores cerebrales (BraTS). Este conjunto de datos incluye resonancias magnéticas y tomografías computarizadas de tumores cerebrales y anotaciones para la segmentación de las regiones tumorales.
Para implementar el aprendizaje conjunto con las resonancias magnéticas y las tomografías computarizadas de los tumores cerebrales, necesitamos desarrollar un enfoque que combine la información de ambas modalidades de una manera que mejore la precisión del diagnóstico. Un enfoque posible es utilizar un modelo de aprendizaje profundo multimodal entrenado en resonancias magnéticas y tomografías computarizadas.
Mencionaremos varias otras aplicaciones del aprendizaje multimodal, como el reconocimiento de voz y los automóviles autónomos.
Reconocimiento de voz

Imagen del autor
El aprendizaje multimodal puede mejorar la precisión del reconocimiento de voz al combinar datos de audio y visuales.
Por ejemplo, un modelo multimodal puede analizar tanto la señal de audio del habla como los movimientos de los labios correspondientes para mejorar la precisión del reconocimiento del habla. Al combinar modalidades de audio y visuales, los modelos multimodales pueden reducir los efectos del ruido y la variabilidad en las señales del habla, lo que lleva a un mejor rendimiento del reconocimiento del habla.

Fuente: Conjunto de datos CMU-MOSEI
Un ejemplo de un conjunto de datos multimodal que se puede utilizar para el reconocimiento de voz es el Conjunto de datos CMU-MOSEI. Este conjunto de datos contiene 23,500 1,000 oraciones pronunciadas por XNUMX hablantes de Youtube e incluye datos de audio y visuales de los hablantes.
El conjunto de datos se puede utilizar para desarrollar modelos multimodales para el reconocimiento de emociones, el análisis de sentimientos y la identificación del hablante.
Al combinar la señal de audio del habla con las características visuales del hablante, los modelos multimodales pueden mejorar la precisión del reconocimiento del habla y otras tareas relacionadas.
Coche autónomo
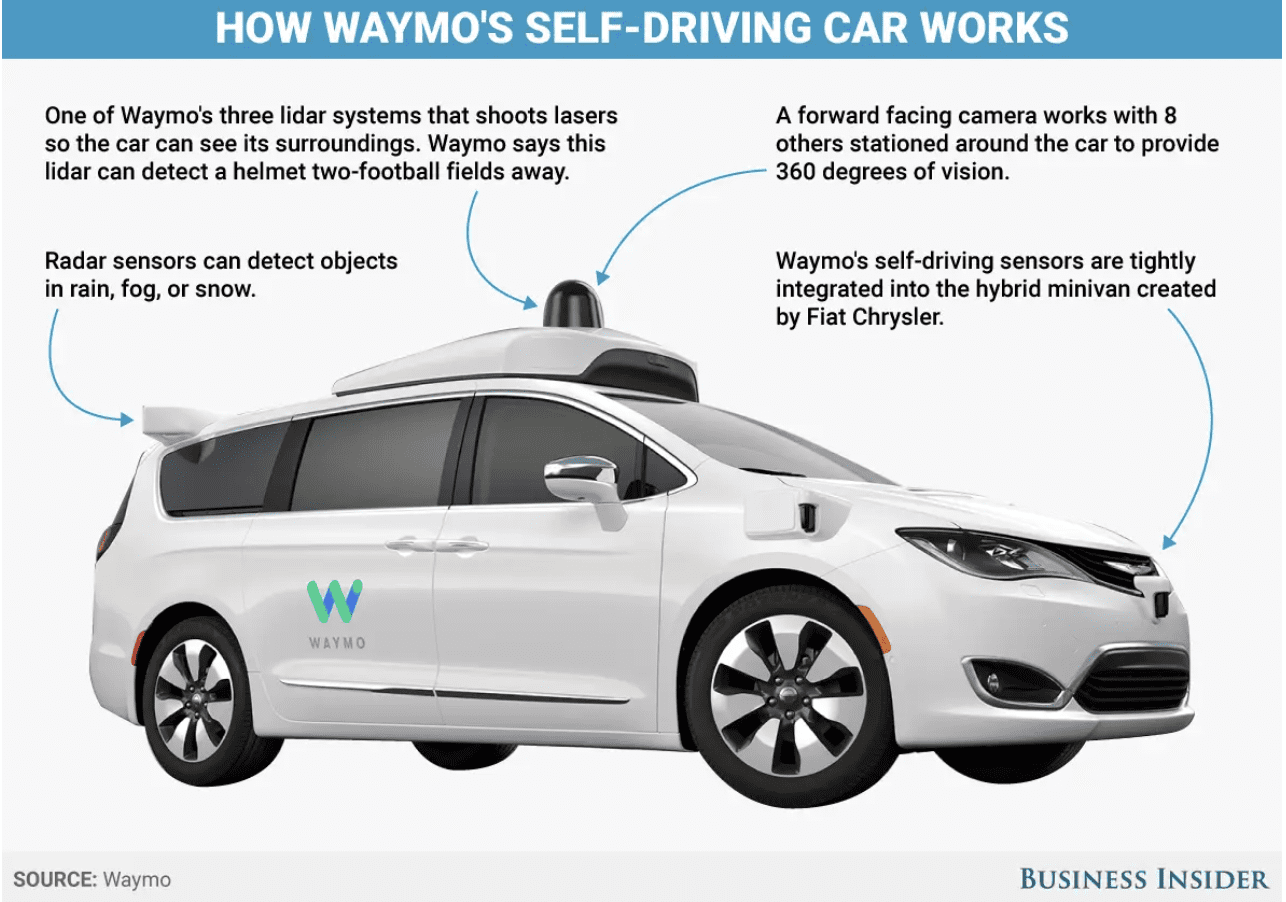
Fuente: Waymo; Business Insider
El aprendizaje multimodal se puede utilizar para mejorar las capacidades de los robots mediante la integración de información de múltiples sensores.
Por ejemplo, es esencial en el desarrollo de automóviles autónomos, que dependen de la información de múltiples sensores como cámaras, lidar y radar para navegar y tomar decisiones.
El aprendizaje multimodal puede ayudar a integrar la información de estos sensores, lo que permite que el automóvil perciba y reaccione a su entorno de manera más precisa y eficiente.
Un ejemplo de un conjunto de datos para automóviles autónomos es el Conjunto de datos abierto de Waymo, que incluye datos de sensores de alta resolución de los autos sin conductor de Waymo, junto con etiquetas para objetos como vehículos, peatones y ciclistas. Waymo es la compañía de automóviles autónomos de Google.
El conjunto de datos se puede utilizar para desarrollar y evaluar modelos multimodales para diversas tareas relacionadas con los automóviles autónomos, como la detección, el seguimiento y las predicciones de objetos.
Análisis de grabación de voz

Imagen del autor
El Proyecto de Análisis de Grabaciones de Voz surgió durante las entrevistas para los puestos de ciencia de datos en Sandvik. Es un excelente ejemplo de una aplicación de aprendizaje multimodal, ya que busca predecir el género de una persona en función de las características vocales derivadas de los datos de audio.
En este escenario, el problema consiste en analizar y procesar información de dos modalidades distintas: señales de audio y características textuales. Estas modalidades aportan información valiosa que puede mejorar la precisión y eficacia del modelo predictivo.
Ampliando la naturaleza multimodal de este proyecto:
Señales de audio

Imagen del autor
La principal fuente de datos de este proyecto son las grabaciones de audio de las voces masculinas y femeninas de habla inglesa. Estas señales de audio contienen información rica y compleja sobre las características vocales del hablante. Al extraer características relevantes de estas señales de audio, como el tono, la frecuencia y la entropía espectral, el modelo puede identificar patrones y tendencias que se relacionan con las propiedades vocales específicas del género.
Características textuales

Imagen del autor
Acompañando a cada grabación de audio hay un archivo de texto que proporciona información crucial sobre la muestra, como el sexo del hablante, el idioma hablado y la frase pronunciada por la persona. Este archivo de texto no solo ofrece la verdad básica (etiquetas de género) para entrenar y evaluar los modelos de aprendizaje automático, sino que también se puede usar para crear funciones adicionales en combinación con los datos de audio. Al aprovechar la información del archivo de texto, el modelo puede comprender mejor el contexto y el contenido de cada muestra de audio, lo que podría mejorar su rendimiento predictivo general.
Por lo tanto, el proyecto Análisis de grabaciones de voz ejemplifica una aplicación de aprendizaje multimodal al aprovechar datos de múltiples modalidades, señales de audio y características textuales para predecir el género de una persona utilizando características vocales extraídas.
Este enfoque destaca la importancia de considerar diferentes tipos de datos al desarrollar modelos de aprendizaje automático, ya que puede ayudar a descubrir patrones y relaciones ocultos que pueden no ser evidentes al analizar cada modalidad de forma aislada.
En resumen, el aprendizaje multimodal se ha convertido en una poderosa herramienta para integrar diversos datos para mejorar el poder de la precisión de algoritmos de aprendizaje automático. La combinación de diferentes tipos de datos, incluidos texto, audio e información visual, puede generar predicciones más sólidas y precisas. Esto es particularmente cierto en el reconocimiento de voz, la fusión de texto e imágenes y la industria de automóviles autónomos.
Sin embargo, el aprendizaje multimodal presenta varios desafíos, como los relacionados con la representación, la fusión, la alineación, la traducción y el coaprendizaje. Esto requiere una cuidadosa consideración y atención.
Sin embargo, a medida que las técnicas de aprendizaje automático y el poder de cómputo continúan evolucionando, podemos anticipar el surgimiento de multimodales aún más avanzados en los próximos años.
Nate Rosidi es científico de datos y en estrategia de producto. También es profesor adjunto de enseñanza de análisis y es el fundador de StrataScratch, una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas de entrevistas reales de las principales empresas. Conéctate con él en Gorjeo: StrataScratch or Etiqueta LinkedIn.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/03/multimodal-models-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=multimodal-models-explained

