Al implementar tecnología de punta como inteligencia artificial (IA) y máquina de aprendizaje, las empresas están intentando aumentar la accesibilidad de la información y los servicios para los consumidores. Estas tecnologías se adoptan cada vez más en diversas áreas comerciales, incluidas la banca, las finanzas, el comercio minorista, la fabricación y la atención médica.
Algunos roles organizacionales en demanda que adoptan la IA son los científicos de datos, los ingenieros de inteligencia artificial, los ingenieros de aprendizaje automático y los analistas de datos. Conocer los tipos de preguntas de la entrevista de aprendizaje automático que los gerentes de contratación podrían plantear si tiene la intención de postularse para puestos en este campo es esencial porque una entrevista de ML exigiría una preparación rigurosa en términos de conocimiento profundo de los conceptos y algoritmos de ML, habilidades técnicas y de programación. , etc.
Para ayudarlo a optimizar sus esfuerzos a medida que emprende este viaje de aprendizaje, decidí comenzar una serie de preguntas esenciales de ML que se espera que uno enfrente durante las entrevistas. Cada parte constará de 10 preguntas para proporcionar una cobertura breve y enfocada de cada tema. Para la primera parte, decidí tratar la cuestión pertinente y significativa para el aprendizaje automático y la estadística. Esto debería proporcionarle suficientes antecedentes y material de revisión antes de su siguiente entrevista. En las secciones restantes, trataría cuestiones específicas de Deep Learning, Computer Vision, NLP, Time Series Analysis, etc.
Entonces, si está listo para comenzar la carrera de sus sueños en ML, continúe leyendo a continuación para refrescar su memoria y agregar nuevos conocimientos a su experiencia actual.
1. ¿Cuáles son los principales tipos de algoritmos de aprendizaje automático?
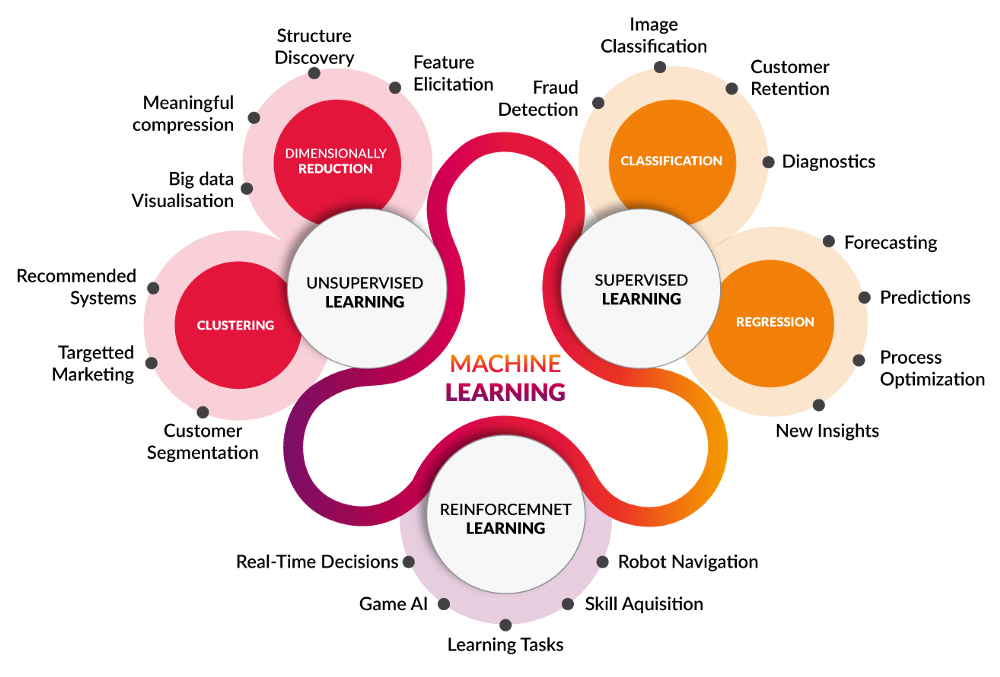
En una categoría amplia, los algoritmos de ML se pueden subdividir en tres categorías principales:
A. Aprendizaje supervisado: Estos algoritmos dan predicciones basadas en inferir una función basada en datos de entrenamiento etiquetados, es decir, las variables objetivo están presentes.
Si la variable objetivo es continua, la elección habitual de algoritmos es la de varios modelos de regresión (lineal, cuadrática, polinomial)
Si la variable objetivo es categórica, los algoritmos preferidos incluyen Regresión Logística, Naive Bayes, KNN, SVM, Árbol de Decisión, Algoritmos Boosting, Random Forest, etc.
B. Aprendizaje no supervisado: Estos algoritmos predicen la variable objetivo en función de algunos patrones en el conjunto de datos dados. Los datos para este propósito no tienen ninguna variable dependiente o etiqueta para predecir. Los algoritmos que caen en esta categoría incluyen Algoritmos de agrupamiento, detección de anomalías, modelos de espacio latente, descomposición de valores singulares, análisis de componentes principales, etc.
C. Aprendizaje por refuerzo: Estos algoritmos utilizan un enfoque basado en prueba y error, y el aprendizaje se produce en función de las recompensas recibidas de la acción anterior.
Fuente: Experty Insights
2. ¿Cómo puede determinar las variables críticas del conjunto de datos con el que está trabajando?
Se pueden implementar varios medios para seleccionar variables esenciales de un conjunto de datos:
1. Identificar y descartar los valores correlacionados antes de finalizar las variables importantes
2. Escoger las variables en base a los valores de p” obtenidos de la prueba de hipótesis
3. Selección hacia adelante, hacia atrás y paso a paso
4. Regresión de lazo
5. Use Random Forest y seleccione variables basadas en los gráficos de importancia de características
6. Las funciones principales se pueden seleccionar en función de la información obtenida del conjunto de funciones disponibles
3. Explique la covarianza y la correlación.
Covarianza indica el grado en que dos variables aleatorias dependen una de la otra. Un número más alto denotaría una mayor dependencia. Su valor se encuentra en el rango de -∞ y +∞. El problema con la covarianza es que son difíciles de calcular sin realizar la normalización en todo el conjunto de datos, y un cambio de escala de los datos afectaría la covarianza.
La correlación es una medida estadística que determina qué tan fuertemente están relacionadas dos variables. Su valor oscilaría entre -1 y +1, que es independiente de la escala.
Fuente: Experty Insights
4. ¿Qué es el valor “P”?
El valor P se utiliza para decidir la prueba de hipótesis. El valor P denota el nivel significativo mínimo en el que podemos rechazar la hipótesis nula. Un valor P más bajo significaría que es más probable que rechacemos la hipótesis nula.
5. ¿Qué son los modelos paramétricos y no paramétricos?
Modelos paramétricos tienen parámetros limitados, y solo se requiere conocimiento sobre los parámetros del modelo para predecir nuevos datos.
Modelos no paramétricos no poseen límites en el número de parámetros de entrada, lo que permite una mayor flexibilidad en la predicción de datos más nuevos. Todo lo que necesitamos saber para proporcionar las predicciones es el estado de los datos y los parámetros del modelo.
Representación tabular de las diferencias entre modelos paramétricos y no paramétricos
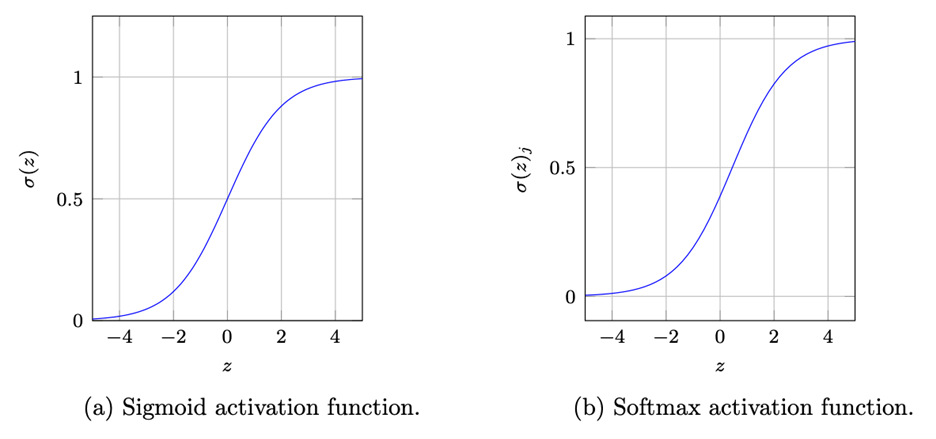
6. ¿Cuál es la diferencia entre las funciones Sigmoid y Softmax?
La función Sigmoid se usa para los métodos de clasificación binaria, donde solo tenemos dos clases de salida, mientras que la función Softmax se aplica a los métodos multiclase. Por lo tanto, es evidente que la entrada y la salida de ambas partes serían ligeramente diferentes.
La función sigmoidea recibe solo una entrada y genera un solo número que representa la probabilidad de pertenecer a la clase 1 o 2.
Mientras que la función softmax está vectorizada, es decir, recibe un vector con el mismo número de entradas que el número de clases que tenemos. El vector de salida contiene las probabilidades de pertenecer a esa clase.
Representación esquemática de las funciones de activación, Fuente: Nomidl
7. ¿Cómo se puede determinar la normalidad de un conjunto de datos?
La forma más fácil de determinar la normalidad es graficar los datos dados. Sin embargo, algunas de las pruebas de normalidad también existen como se muestra a continuación:
Prueba de Shapiro-Wilk
Prueba de Anderson-Darling
Prueba de Kolmogorov-Smirnov
Prueba Martínez-Iglewicz
Prueba de asimetría de D'Agostino
8. ¿Cómo se puede seleccionar el valor K para el algoritmo de agrupamiento de K-medias?
El valor K se puede seleccionar de dos maneras diferentes: Método Directo y Método de Prueba Estadística.
1. Método Directo: Contiene los métodos de codo y silueta.
2. Método de prueba estadística: Incluye estadísticas de brecha
El método de la silueta sigue siendo el más utilizado para determinar el valor óptimo de K.
9. ¿Cómo puede manejar los valores atípicos en un conjunto de datos?
Los valores atípicos son puntos de datos significativamente diferentes del resto del conjunto de datos. Los enfoques que se pueden usar para descubrir los valores atípicos incluyen: diagrama de caja, puntaje Z, diagrama de dispersión, etc.
Las siguientes estrategias normalmente pueden manejar valores atípicos:
1. La forma más fácil es descartar los valores atípicos
2. Pueden marcarse por separado como valores atípicos y usarse como un vector de características diferente
3. La característica se puede transformar alternativamente para reducir el efecto del valor atípico
10. Explique las diferencias entre la función de pérdida y costo.
El término función de pérdida se puede usar cuando se trata de un solo punto de datos, mientras que cuando se calcula la suma del error para múltiples datos, se puede usar el término función de costo. Como tal, intuitivamente, ambos términos significarían lo mismo y no existe una diferencia significativa entre ellos. Por lo tanto, la función de pérdida captura la diferencia entre los valores reales y predichos para un solo punto de datos, mientras que la función de costo suma la diferencia de todos los datos de entrenamiento.
Conclusión sobre el aprendizaje automático
Por lo tanto, en esta primera parte de la serie, repasamos la cuestión fundamental del aprendizaje automático que se espera que uno enfrente. Contar con estos minuciosos que serán un empujón a tu preparación. Para resumir, las conclusiones clave de este artículo serían:
Las diferentes categorías de aprendizaje automático: cómo y sobre qué base se pueden clasificar en aprendizaje supervisado, no supervisado y de refuerzo.
Luego nos ocupamos de los métodos para determinar las diversas características esenciales de los datos, cómo encontrar la correlación y la covarianza y cómo extraer inferencias críticas y significativas de dichos datos; discutimos el valor de p y la regresión de lazo,
Luego discutimos modelos paramétricos y no paramétricos.
Las diferencias clave entre las funciones de activación sigmoide y softmax se trataron a continuación.
Luego se discutió un paso esencial de la normalización de datos y los diversos métodos para llevarla a cabo.
Otro factor crítico que afecta el rendimiento del modelo: los valores atípicos se discutieron a continuación y se elaboraron las diversas formas en que puede manejarlos.
Y finalmente, terminamos con las diferencias entre la función de costo y pérdida: dos de los términos más comunes que podría haber usado al desarrollar sus modelos ML;
Estas preguntas fundamentales deberían ser una excelente base para desarrollar en los próximos blogs a seguir. Estén atentos a las próximas partes.
En la parte 2 de esta serie, traté el aprendizaje profundo y los aspectos esenciales de DL. ¡Espero que esta lectura pueda agregar algo valioso a su conocimiento técnico existente de Machine Learning!
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.