Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
W Limpiar y preparar la mayor parte del tiempo en un proyecto de ciencia de datos. Al ejecutar varios enfoques de preprocesamiento, podemos encontrar varios problemas que pueden resolverse principalmente con una sola biblioteca: Pandas. Pandas es un módulo de Python muy conocido que maneja todo, desde el preprocesamiento de datos hasta el análisis de datos. El amplio conjunto de funciones de Pandas permite a los usuarios completar trabajos considerablemente más rápido que los tradicionales.

Este artículo analizará algunas de las operaciones simples pero poderosas dignas de marcar de Pand que discutiremos son en su mayoría genéricas, y se pueden modificar según los casos de uso.
Operaciones en Pandas
1. Para reemplazar los valores de NaN con valores aleatorios de una lista
Para reemplazar los valores de NaN en un Pandas DataFrame, generalmente, usamos el .fillna() método en un DataFrame. Para llenar estos valores de NaN al azar de una lista de números (incluidos float e int) o cadenas, podemos usar el .loc() método en el DataFrame.
Veamos un ejemplo a continuación:
Importar las bibliotecas
importar pandas como pd importar numpy como np
Creando un Pandas DataFrame con datos ficticios
df = pd.DataFrame({ 'Nombre': ['Alex', 'Jimmy', 'Katie', 'Brute'], 'Deporte favorito': [np.nan, 'Tenis sobre césped', 'Baloncesto', np. nan], 'Altura (en cm)': [167.7, 182.3, 178.7, 166.2], 'Salario': [12134343, 21312324, 421324554, 234434325] })
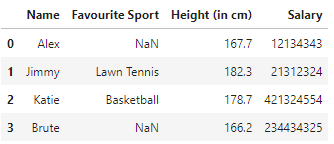
Al ejecutar este código, obtenemos el Pandas DataFrame, como se adjunta en la imagen de arriba. En este conjunto de datos, agregamos a propósito algunos valores de NaN, ya que los necesitaríamos para tratar en esta operación.
Configuración del valor inicial:
Establezcamos el valor inicial ya que reemplazaremos los valores de NaN con datos aleatorios generados a partir de la biblioteca NumPy, y queremos el mismo conjunto de resultados cada vez que ejecutamos este código.
np.random.seed (124)
Sustitución de los valores de NaN
Ahora que tenemos nuestro conjunto de semillas, usaremos el .loc() en nuestro DataFrame para realizar nuestra operación.
df.loc[df['Deporte Favorito'].isna(), 'Deporte Favorito'] = [i for i in np.random.choice(['Voleibol', 'Fútbol', 'Baloncesto', 'Críquet'] , df['Deporte Favorito'].isna().sum())]
Ejecutar esto asignará una lista de valores a los valores de NaN en la columna 'Deporte favorito'. Esta lista habría elegido valores al azar de una lista de ['Voleibol', 'Fútbol', 'Baloncesto', 'Críquet'], y el número de valores a elegir será igual al número de NaNs en la columna seleccionada, aquí Deporte Favorito.
Cómo aplicar todos los conceptos
# Importar las bibliotecas import pandas como pd import numpy as np # Creando el DataFrame df = pd.DataFrame({ 'Name': ['Alex', 'Jimmy', 'Katie', 'Brute'], 'Favourite Sport': [np.nan, 'Lawn Tennis', 'Baloncesto', np.nan], 'Altura (en cm)': [167.7, 182.3, 178.7, 166.2], 'Salario': [12134343, 21312324, 421324554, 234434325] }) np.random.seed(124) df.loc[df['Deporte Favorito'].isna(), 'Deporte Favorito'] = [i for i in np.random.choice(['Voleibol', 'Fútbol ', 'Baloncesto', 'Críquet'], df['Deporte favorito'].isna().sum())] print(df)
Al ejecutar este código, nuestro conjunto de datos final se vería así:
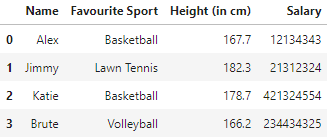
Como se explicó, para los índices 0 y 3, vemos que los NaN se reemplazan con valores seleccionados al azar, es decir, 'Baloncesto' y 'Vóleibol' de la lista deportiva mencionada.
2. Para mapear valores en una columna categórica en códigos
La asignación de valores a códigos numéricos es un método útil que puede ser útil cuando queremos datos numéricos en nuestro DataFrame, pero debe ser único y estar relacionado con otra cosa. Un uso de esta función puede ser la asignación automática de números de lista en una clase a partir de una lista de nombres de estudiantes.
Comencemos repitiendo los requisitos previos del paso anterior: importar las bibliotecas, generar un DataFrame de Pandas y ejecutar la operación (1.).
Realización de los requisitos previos
# Importando las bibliotecas import pandas como pd import numpy as np # Creando el DataFrame df = pd.DataFrame({ 'Name': ['Alex', 'Jimmy', 'Katie', 'Brute'], 'Favourite Sport': [np.nan, 'Lawn Tennis', 'Baloncesto', np.nan], 'Altura (en cm)': [167.7, 182.3, 178.7, 166.2], 'Salario': [12134343, 21312324, 421324554, 234434325] }) # Reemplazo de los valores de NaN np.random.seed(124) df.loc[df['Deporte favorito'].isna(), 'Deporte favorito'] = [i por i en np.random.choice([' Voleibol', 'Fútbol', 'Baloncesto', 'Críquet'], df['Deporte Favorito'].isna().sum())]
Creando una lista de Códigos (desde la columna 'Nombre')
list(pd.Categorical(df['Name'], ordered = True).codes)
Al ejecutar esto, obtenemos lo siguiente:
![]()
Aquí, usamos el método Categorical() de Pandas y pasamos el 'Nombre' columna de nuestro DataFrame. También pasamos el valor 'Verdadero' al parámetro 'ordenado,' y así, obtenemos la lista de números basados en el orden alfabético 'Nombre' columna. Así que cuando el Nombre 'Alex', el código asignado es '0', mientras que para el nombre 'Palanqueta,' el código asignado será '2' como el nombre 'Palanqueta' viene en la 3ra posición entre los cuatro nombres en el 'Nombre' columna, alfabéticamente. Pasamos todo este código a una lista para obtener una lista de valores.
También podemos pasar esta lista de valores al DataFrame como una columna.
Crear una nueva columna a partir de códigos
df['Número de rollo'] = lista(pd.Categorical(df['Nombre'], ordenado = Verdadero).códigos)
Ejecutar esto creará una nueva columna llamada 'Número de rollo'.
Poniendo todo esto junto
# Importar las bibliotecas import pandas como pd import numpy as np # Creando el DataFrame df = pd.DataFrame({ 'Name': ['Alex', 'Jimmy', 'Katie', 'Brute'], 'Favourite Sport': [np.nan, 'Lawn Tennis', 'Baloncesto', np.nan], 'Altura (en cm)': [167.7, 182.3, 178.7, 166.2], 'Salario': [12134343, 21312324, 421324554, 234434325] }) # Reemplazo de los valores de NaN np.random.seed(124) df.loc[df['Deporte favorito'].isna(), 'Deporte favorito'] = [i por i en np.random.choice([' Volleyball', 'Football', 'Basketball', 'Cricket'], df['Favourite Sport'].isna().sum())] # Asignación de la columna 'Nombre' a códigos numéricos df['Roll Number'] = list(pd.Categorical(df['Name'], ordered = True).codes) print(df)
Al ejecutar este código, nuestro DataFrame se vería así:
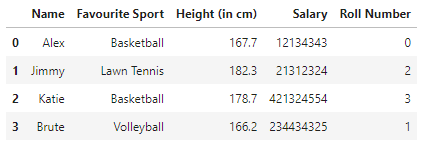
3. Para formatear los enteros en un marco de datos
Este proceso ayuda a mejorar la legibilidad de los números para los usuarios. Con frecuencia nos encontramos con números con numerosos dígitos en un DataFrame, lo que provoca confusión y mala interpretación.
Daremos formato a los valores en la columna 'Salario' en el siguiente ejemplo.
Comencemos por completar los requisitos de las operaciones principales: importar bibliotecas, construir Pandas DataFrame y las dos operaciones anteriores.
Realización de los requisitos previos
# Importar las bibliotecas import pandas como pd import numpy as np # Creando el DataFrame df = pd.DataFrame({ 'Name': ['Alex', 'Jimmy', 'Katie', 'Brute'], 'Favourite Sport': [np.nan, 'Lawn Tennis', 'Baloncesto', np.nan], 'Altura (en cm)': [167.7, 182.3, 178.7, 166.2], 'Salario': [12134343, 21312324, 421324554, 234434325] }) # Reemplazo de los valores de NaN np.random.seed(124) df.loc[df['Deporte favorito'].isna(), 'Deporte favorito'] = [i por i en np.random.choice([' Volleyball', 'Football', 'Basketball', 'Cricket'], df['Favourite Sport'].isna().sum())] # Asignación de la columna 'Nombre' a códigos numéricos df['Roll Number'] = list(pd.Categorical(df['Name'], ordered = True).codes)
Dar formato a la columna 'Salario'
df['Salario'] = df['Salario'].apply(lambda x: format(x, ',d'))
Cómo aplicar todos los conceptos
# Importar las bibliotecas import pandas como pd import numpy as np # Creando el DataFrame df = pd.DataFrame({ 'Name': ['Alex', 'Jimmy', 'Katie', 'Brute'], 'Favourite Sport': [np.nan, 'Lawn Tennis', 'Baloncesto', np.nan], 'Altura (en cm)': [167.7, 182.3, 178.7, 166.2], 'Salario': [12134343, 21312324, 421324554, 234434325] }) # Reemplazo de los valores de NaN np.random.seed(124) df.loc[df['Deporte favorito'].isna(), 'Deporte favorito'] = [i por i en np.random.choice([' Volleyball', 'Football', 'Basketball', 'Cricket'], df['Favourite Sport'].isna().sum())] # Asignación de la columna 'Nombre' a códigos numéricos df['Roll Number'] = list(pd.Categorical(df['Name'],ordered = True).codes) # Formatear valores en la columna 'Salary' df['Salary'] = df['Salary'].apply(lambda x: format(x , ',d')) imprimir(df)
Al ejecutar este código, obtenemos lo siguiente:
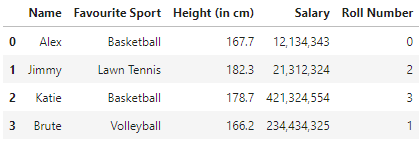
Aquí, pasamos cada valor en el 'Salario' columna en el incorporado formato() método, usando el .solicitar() Método de Pandas.
Una posible advertencia al realizar esta operación es que el valor se vuelve de tipo objeto o categórico al formatear un entero debido a las comas entre los dígitos.
4. Para extraer filas si una cierta columna categórica tiene una subcadena dada
A veces deseamos eliminar filas que cumplen un requisito específico. Esta operación a menudo se realiza en las columnas categóricas de un DataFrame. Realizaremos una operación similar en una de nuestras columnas categóricas a continuación.
En nuestro DataFrame, extraeremos todas las filas donde la persona tiene un juego de pelota como Deporte favorito. Para llevar a cabo este proceso, utilizaremos nuestra columna de Deporte Favorito.
Comenzaremos con los requisitos previos, incluidas las importaciones de bibliotecas, la construcción de DataFrame y las operaciones completadas anteriormente.
Realización de los requisitos previos
# Importar las bibliotecas import pandas como pd import numpy as np # Creando el DataFrame df = pd.DataFrame({ 'Name': ['Alex', 'Jimmy', 'Katie', 'Brute'], 'Favourite Sport': [np.nan, 'Lawn Tennis', 'Baloncesto', np.nan], 'Altura (en cm)': [167.7, 182.3, 178.7, 166.2], 'Salario': [12134343, 21312324, 421324554, 234434325] }) # Reemplazo de los valores de NaN np.random.seed(124) df.loc[df['Deporte favorito'].isna(), 'Deporte favorito'] = [i por i en np.random.choice([' Volleyball', 'Football', 'Basketball', 'Cricket'], df['Favourite Sport'].isna().sum())] # Mapeo de la columna 'Nombre' en códigos numéricos df['Roll Number'] = list(pd.Categorical(df['Name'],ordered = True).codes) # Formatear valores en la columna 'Salary' df['Salary'] = df['Salary'].apply(lambda x: format (x, ', d'))
Extracción de las filas de interés
print(df[df['Deporte Favorito'].str.contains('pelota')])
Ejecutar esto extraerá todas las filas donde el Deporte Favorito de una persona tiene el texto 'pelota' en ella.
Cómo aplicar todos los conceptos
# Importar las bibliotecas import pandas como pd import numpy as np # Creando el DataFrame df = pd.DataFrame({ 'Name': ['Alex', 'Jimmy', 'Katie', 'Brute'], 'Favourite Sport': [np.nan, 'Lawn Tennis', 'Baloncesto', np.nan], 'Altura (en cm)': [167.7, 182.3, 178.7, 166.2], 'Salario': [12134343, 21312324, 421324554, 234434325] }) # Reemplazo de los valores de NaN np.random.seed(124) df.loc[df['Deporte favorito'].isna(), 'Deporte favorito'] = [i por i en np.random.choice([' Volleyball', 'Football', 'Basketball', 'Cricket'], df['Favourite Sport'].isna().sum())] # Mapeo de la columna 'Nombre' en códigos numéricos df['Roll Number'] = list(pd.Categorical(df['Name'],ordered = True).codes) # Formatear valores en la columna 'Salary' df['Salary'] = df['Salary'].apply(lambda x: format (x, ',d')) # Comprobar si 'pelota' está en la columna 'Deporte favorito' print(df[df['Deporte favorito'].str.contains('pelota')])
Al ejecutar este código, obtenemos lo siguiente:
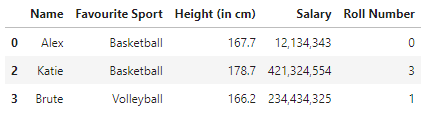
Aquí, como se explicó, obtuvimos todas las filas de nuestro DataFrame que tienen una subcadena 'pelota' en la columna Favorito.
Conclusiones
Este artículo analiza cuatro operaciones de Pandas simples pero poderosas que se pueden usar en varias situaciones. Todas las acciones descritas se realizan de la forma más sencilla posible; sin embargo, puede haber otras formas de realizar estas operaciones. Esta simplicidad hace que valga la pena marcar el artículo porque ahorra tiempo buscando soluciones similares en StackOverflow.
Puntos clave:
- Vimos cómo podíamos reemplazar los NaN con valores aleatorios: números o cadenas.
- También vimos cómo codificar las cadenas en números según la disposición alfabética de las cadenas.
- En la tercera operación, aprendimos cómo formatear los números enteros y mejorar la legibilidad para el usuario.
- También hemos visto cómo formatear esto puede cambiar el tipo de datos de la columna de int a str.
- En la cuarta operación, entendimos cómo extraer filas cuando una subcadena dada se encuentra en una de las columnas especificadas.
Conecta conmigo en Etiqueta LinkedIn. Mira mis otros artículos Aquí.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2022/11/essential-pandas-operations-you-must-bookmark-right-away/

