Las políticas de control eficientes permiten a las empresas industriales aumentar su rentabilidad maximizando la productividad y al mismo tiempo reduciendo el tiempo de inactividad no programado y el consumo de energía. Encontrar políticas de control óptimas es una tarea compleja porque los sistemas físicos, como los reactores químicos y las turbinas eólicas, suelen ser difíciles de modelar y porque la deriva en la dinámica del proceso puede provocar que el rendimiento se deteriore con el tiempo. El aprendizaje por refuerzo fuera de línea es una estrategia de control que permite a las empresas industriales crear políticas de control completamente a partir de datos históricos sin la necesidad de un modelo de proceso explícito. Este enfoque no requiere interacción con el proceso directamente en una etapa de exploración, lo que elimina una de las barreras para la adopción del aprendizaje por refuerzo en aplicaciones críticas para la seguridad. En esta publicación, crearemos una solución de extremo a extremo para encontrar políticas de control óptimas utilizando solo datos históricos sobre Amazon SageMaker usando ray RLlib biblioteca. Para obtener más información sobre el aprendizaje por refuerzo, consulte Utilice el aprendizaje por refuerzo con Amazon SageMaker.
Use cases
El control industrial implica la gestión de sistemas complejos, como líneas de fabricación, redes de energía y plantas químicas, para garantizar un funcionamiento eficiente y confiable. Muchas estrategias de control tradicionales se basan en reglas y modelos predefinidos, que a menudo requieren optimización manual. Es una práctica estándar en algunas industrias monitorear el desempeño y ajustar la política de control cuando, por ejemplo, el equipo comienza a degradarse o las condiciones ambientales cambian. La resintonización puede llevar semanas y puede requerir inyectar excitaciones externas en el sistema para registrar su respuesta en un enfoque de prueba y error.
El aprendizaje por refuerzo ha surgido como un nuevo paradigma en el control de procesos para aprender políticas de control óptimas mediante la interacción con el entorno. Este proceso requiere dividir los datos en tres categorías: 1) mediciones disponibles del sistema físico, 2) el conjunto de acciones que se pueden realizar sobre el sistema y 3) una métrica numérica (recompensa) del rendimiento del equipo. Una política está entrenada para encontrar la acción, en una observación determinada, que probablemente produzca las mayores recompensas futuras.
En el aprendizaje por refuerzo fuera de línea, se puede entrenar una política sobre datos históricos antes de implementarlos en producción. El algoritmo entrenado en esta publicación de blog se llama "Aprendizaje Q conservador”(CQL). CQL contiene un modelo "actor" y un modelo "crítico" y está diseñado para predecir de forma conservadora su propio desempeño después de realizar una acción recomendada. En esta publicación, el proceso se demuestra con un problema ilustrativo de control de postes de carro. El objetivo es entrenar a un agente para equilibrar un poste en un carro y al mismo tiempo mover el carro hacia una ubicación objetivo designada. El procedimiento de capacitación utiliza datos fuera de línea, lo que permite al agente aprender de información preexistente. Este estudio de caso de carrito demuestra el proceso de capacitación y su efectividad en posibles aplicaciones del mundo real.
Resumen de la solución
La solución presentada en esta publicación automatiza la implementación de un flujo de trabajo de un extremo a otro para el aprendizaje por refuerzo fuera de línea con datos históricos. El siguiente diagrama describe la arquitectura utilizada en este flujo de trabajo. Los datos de medición se producen en el borde mediante un equipo industrial (aquí simulado por un AWS Lambda función). Los datos se colocan en un Kinesis amazónica Data Firehose, que lo almacena en Servicio de almacenamiento simple de Amazon (Amazon S3). Amazon S3 es una solución de almacenamiento duradera, eficaz y de bajo costo que le permite servir grandes volúmenes de datos a un proceso de capacitación de aprendizaje automático.
Pegamento AWS cataloga los datos y los hace consultables usando Atenea amazónica. Athena transforma los datos de medición en una forma que un algoritmo de aprendizaje por refuerzo pueda ingerir y luego los descarga nuevamente en Amazon S3. Amazon SageMaker carga estos datos en un trabajo de entrenamiento y produce un modelo entrenado. Luego, SageMaker entrega ese modelo en un punto final de SageMaker. Luego, el equipo industrial puede consultar ese punto final para recibir recomendaciones de acción.
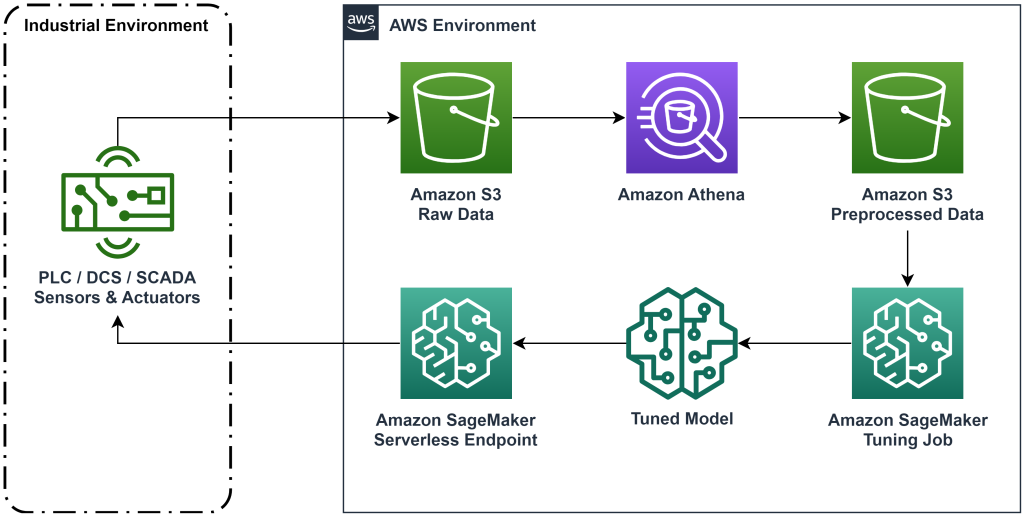
Figura 1: Diagrama de arquitectura que muestra el flujo de trabajo de aprendizaje por refuerzo de un extremo a otro.
En esta publicación, dividiremos el flujo de trabajo en los siguientes pasos:
- Formule el problema. Decida qué acciones se pueden tomar, en qué medidas basarse para hacer recomendaciones y determine numéricamente qué tan bien se desempeñó cada acción.
- Prepara los datos. Transforme la tabla de medidas a un formato que el algoritmo de aprendizaje automático pueda consumir.
- Entrene el algoritmo con esos datos.
- Seleccione la mejor ejecución de entrenamiento según las métricas de entrenamiento.
- Implemente el modelo en un punto final de SageMaker.
- Evaluar el desempeño del modelo en producción.
Requisitos previos
Para completar este tutorial, necesita tener un Cuenta de AWS y una interfaz de línea de comando con AWS SAM instalado. Siga estos pasos para implementar la plantilla de AWS SAM para ejecutar este flujo de trabajo y generar datos de entrenamiento:
- Descargue el repositorio de código con el comando
- Cambie el directorio al repositorio:
- Construya el repositorio:
- Implementar el repositorio
- Utilice los siguientes comandos para llamar a un script bash, que genera datos simulados mediante una función AWS Lambda.
sudo yum install jqcd utilssh generate_mock_data.sh
Tutorial de la solución
formular problema
Nuestro sistema en esta publicación de blog es un carro con un poste en equilibrio en la parte superior. El sistema funciona bien cuando el poste está en posición vertical y la posición del carro está cerca de la posición objetivo. En el paso de requisito previo, generamos datos históricos de este sistema.
La siguiente tabla muestra datos históricos recopilados del sistema.
| Posición del carrito | Velocidad del carro | Ángulo del polo | Velocidad angular del polo | Posición de portería | Fuerza externa | Gana dinero | Horario |
| 0.53 | -0.79 | -0.08 | 0.16 | 0.50 | -0.04 | 11.5 | 5: 37: 54 PM |
| 0.51 | -0.82 | -0.07 | 0.17 | 0.50 | -0.04 | 11.9 | 5: 37: 55 PM |
| 0.50 | -0.84 | -0.07 | 0.18 | 0.50 | -0.03 | 12.2 | 5: 37: 56 PM |
| 0.48 | -0.85 | -0.07 | 0.18 | 0.50 | -0.03 | 10.5 | 5: 37: 57 PM |
| 0.46 | -0.87 | -0.06 | 0.19 | 0.50 | -0.03 | 10.3 | 5: 37: 58 PM |
Puede consultar información histórica del sistema mediante Amazon Athena con la siguiente consulta:
El estado de este sistema está definido por la posición del carro, la velocidad del carro, el ángulo del polo, la velocidad angular del polo y la posición de la meta. La acción tomada en cada paso es la fuerza externa aplicada al carro. El entorno simulado genera un valor de recompensa que es mayor cuando el carro está más cerca de la posición objetivo y el poste está más vertical.
Preparar datos
Para presentar la información del sistema al modelo de aprendizaje por refuerzo, transfórmela en objetos JSON con claves que categoricen los valores en categorías de estado (también llamado observación), acción y recompensa. Almacene estos objetos en Amazon S3. A continuación se muestra un ejemplo de objetos JSON producidos a partir de pasos de tiempo en la tabla anterior.
|
{“obs”:[[0.53,-0.79,-0.08,0.16,0.5]], “action”:[[-0.04]], “reward”:[11.5] ,”next_obs”:[[0.51,-0.82,-0.07,0.17,0.5]]} |
|
{“obs”:[[0.51,-0.82,-0.07,0.17,0.5]], “action”:[[-0.04]], “reward”:[11.9], “next_obs”:[[0.50,-0.84,-0.07,0.18,0.5]]} |
|
{“obs”:[[0.50,-0.84,-0.07,0.18,0.5]], “action”:[[-0.03]], “reward”:[12.2], “next_obs”:[[0.48,-0.85,-0.07,0.18,0.5]]} |
La pila de AWS CloudFormation contiene una salida llamada AthenaQueryToCreateJsonFormatedData. Ejecute esta consulta en Amazon Athena para realizar la transformación y almacenar los objetos JSON en Amazon S3. El algoritmo de aprendizaje por refuerzo utiliza la estructura de estos objetos JSON para comprender en qué valores basar las recomendaciones y el resultado de tomar acciones en los datos históricos.
agente de tren
Ahora podemos comenzar un trabajo de capacitación para producir un modelo de recomendación de acciones entrenado. Amazon SageMaker le permite iniciar rápidamente varios trabajos de capacitación para ver cómo las distintas configuraciones afectan el modelo entrenado resultante. Llame a la función Lambda denominada TuningJobLauncherFunction para iniciar un trabajo de ajuste de hiperparámetros que experimente con cuatro conjuntos diferentes de hiperparámetros al entrenar el algoritmo.
Selecciona la mejor carrera de entrenamiento
Para encontrar cuál de los trabajos de capacitación produjo el mejor modelo, examine las curvas de pérdida producidas durante la capacitación. El modelo crítico de CQL estima el desempeño del actor (llamado valor Q) después de realizar una acción recomendada. Parte de la función de pérdida del crítico incluye el error de diferencia temporal. Esta métrica mide la precisión del valor Q del crítico. Busque ejecuciones de entrenamiento con un valor Q medio alto y un error de diferencia temporal bajo. Este papel, Un flujo de trabajo para el aprendizaje por refuerzo robótico sin modelos fuera de línea, detalla cómo seleccionar la mejor carrera de entrenamiento. El repositorio de código tiene un archivo, /utils/investigate_training.py, que crea una figura html gráfica que describe el último trabajo de capacitación. Ejecute este archivo y utilice el resultado para elegir la mejor ejecución de entrenamiento.
Podemos utilizar el valor Q medio para predecir el rendimiento del modelo entrenado. Los valores Q están entrenados para predecir de forma conservadora la suma de los valores de recompensa futuros descontados. Para procesos de larga duración, podemos convertir este número a un promedio ponderado exponencialmente multiplicando el valor Q por (1-“tasa de descuento”). La mejor ejecución de entrenamiento en este conjunto logró un valor Q medio de 539. Nuestra tasa de descuento es 0.99, por lo que el modelo predice al menos 5.39 de recompensa promedio por paso de tiempo. Puede comparar este valor con el rendimiento histórico del sistema para obtener una indicación de si el nuevo modelo superará la política de control histórica. En este experimento, la recompensa promedio de los datos históricos por paso de tiempo fue 4.3, por lo que el modelo CQL predice un rendimiento un 25 por ciento mejor que el que el sistema logró históricamente.
Implementar modelo
Los puntos de enlace de Amazon SageMaker le permiten ofrecer modelos de aprendizaje automático de varias maneras diferentes para satisfacer una variedad de casos de uso. En esta publicación, usaremos el tipo de punto final sin servidor para que nuestro punto final escale automáticamente con la demanda y solo paguemos por el uso de cómputo cuando el punto final esté generando una inferencia. Para implementar un punto final sin servidor, incluya un ProductionVariantServerlessConfig existentes variante de producción del Sabio configuración de punto final. El siguiente fragmento de código muestra cómo se implementa el punto final sin servidor de este ejemplo mediante el kit de desarrollo de software de Amazon SageMaker para Python. Encuentre el código de muestra utilizado para implementar el modelo en sagemaker-fuera de línea-refuerzo-aprendizaje-ray-cql.
Los archivos del modelo entrenado se encuentran en los artefactos del modelo S3 para cada ejecución de entrenamiento. Para implementar el modelo de aprendizaje automático, ubique los archivos del modelo de la mejor ejecución de entrenamiento y llame a la función Lambda denominada "ModelDeployerFunction”con un evento que contiene los datos de este modelo. La función Lambda iniciará un punto final sin servidor de SageMaker para atender el modelo entrenado. Evento de muestra para usar al llamar al "ModelDeployerFunction"
Evaluar el rendimiento del modelo entrenado
¡Es hora de ver cómo le va a nuestro modelo entrenado en producción! Para comprobar el rendimiento del nuevo modelo, llame a la función Lambda denominada "RunPhysicsSimulationFunction” con el nombre del punto final de SageMaker en el evento. Esto ejecutará la simulación utilizando las acciones recomendadas por el punto final. Evento de muestra para usar al llamar al RunPhysicsSimulatorFunction:
Utilice la siguiente consulta de Athena para comparar el rendimiento del modelo entrenado con el rendimiento histórico del sistema.
| Fuente de acción | Recompensa promedio por paso de tiempo |
trained_model |
10.8 |
historic_data |
4.3 |
Las siguientes animaciones muestran la diferencia entre un episodio de muestra de los datos de entrenamiento y un episodio en el que se utilizó el modelo entrenado para elegir qué acción tomar. En las animaciones, el cuadro azul es el carro, la línea azul es el poste y el rectángulo verde es la ubicación de la portería. La flecha roja muestra la fuerza aplicada al carro en cada paso de tiempo. La flecha roja en los datos de entrenamiento salta bastante hacia adelante y hacia atrás porque los datos se generaron utilizando un 50 por ciento de acciones expertas y un 50 por ciento de acciones aleatorias. El modelo entrenado aprendió una política de control que mueve el carro rápidamente a la posición objetivo, manteniendo la estabilidad, enteramente a partir de la observación de demostraciones no expertas.
 |
 |
Limpiar
Para eliminar los recursos utilizados en este flujo de trabajo, navegue hasta la sección de recursos de la pila de Amazon CloudFormation y elimine los depósitos de S3 y las funciones de IAM. Luego elimine la pila de CloudFormation.
Conclusión
El aprendizaje por refuerzo fuera de línea puede ayudar a las empresas industriales a automatizar la búsqueda de políticas óptimas sin comprometer la seguridad mediante el uso de datos históricos. Para implementar este enfoque en sus operaciones, comience por identificar las mediciones que conforman un sistema determinado por el estado, las acciones que puede controlar y las métricas que indican el desempeño deseado. Luego, accede este repositorio de GitHub para la implementación de una solución automática de extremo a extremo utilizando Ray y Amazon SageMaker.
La publicación solo toca la superficie de lo que puede hacer con Amazon SageMaker RL. Pruébelo y envíenos sus comentarios, ya sea en el Foro de discusión de Amazon SageMaker oa través de sus contactos habituales de AWS.
Acerca de los autores
 Walt Mayfield es arquitecto de soluciones en AWS y ayuda a las empresas de energía a operar de manera más segura y eficiente. Antes de unirse a AWS, Walt trabajó como ingeniero de operaciones para Hilcorp Energy Company. Le gusta trabajar en el jardín y pescar con mosca en su tiempo libre.
Walt Mayfield es arquitecto de soluciones en AWS y ayuda a las empresas de energía a operar de manera más segura y eficiente. Antes de unirse a AWS, Walt trabajó como ingeniero de operaciones para Hilcorp Energy Company. Le gusta trabajar en el jardín y pescar con mosca en su tiempo libre.
 Felipe Lopez es arquitecto senior de soluciones en AWS con especialización en operaciones de producción de petróleo y gas. Antes de unirse a AWS, Felipe trabajó con GE Digital y Schlumberger, donde se centró en productos de modelado y optimización para aplicaciones industriales.
Felipe Lopez es arquitecto senior de soluciones en AWS con especialización en operaciones de producción de petróleo y gas. Antes de unirse a AWS, Felipe trabajó con GE Digital y Schlumberger, donde se centró en productos de modelado y optimización para aplicaciones industriales.
 yingwei yu es científico aplicado en Generative AI Incubator, AWS. Tiene experiencia trabajando con varias organizaciones de distintos sectores en diversas pruebas de concepto de aprendizaje automático, incluido el procesamiento del lenguaje natural, el análisis de series temporales y el mantenimiento predictivo. En su tiempo libre, le gusta nadar, pintar, hacer caminatas y pasar tiempo con familiares y amigos.
yingwei yu es científico aplicado en Generative AI Incubator, AWS. Tiene experiencia trabajando con varias organizaciones de distintos sectores en diversas pruebas de concepto de aprendizaje automático, incluido el procesamiento del lenguaje natural, el análisis de series temporales y el mantenimiento predictivo. En su tiempo libre, le gusta nadar, pintar, hacer caminatas y pasar tiempo con familiares y amigos.
 Wang Haozhu es un científico investigador en Amazon Bedrock que se centra en la construcción de los modelos de base Titan de Amazon. Anteriormente, trabajó en Amazon ML Solutions Lab como codirector de Reinforcement Learning Vertical y ayudó a los clientes a crear soluciones avanzadas de ML con las últimas investigaciones sobre aprendizaje por refuerzo, procesamiento del lenguaje natural y aprendizaje de gráficos. Haozhu recibió su doctorado en Ingeniería Eléctrica e Informática de la Universidad de Michigan.
Wang Haozhu es un científico investigador en Amazon Bedrock que se centra en la construcción de los modelos de base Titan de Amazon. Anteriormente, trabajó en Amazon ML Solutions Lab como codirector de Reinforcement Learning Vertical y ayudó a los clientes a crear soluciones avanzadas de ML con las últimas investigaciones sobre aprendizaje por refuerzo, procesamiento del lenguaje natural y aprendizaje de gráficos. Haozhu recibió su doctorado en Ingeniería Eléctrica e Informática de la Universidad de Michigan.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/optimize-equipment-performance-with-historical-data-ray-and-amazon-sagemaker/

