La seguridad está surgiendo como una preocupación en un número cada vez mayor de industrias, pero no existen estándares y metodologías para garantizar que los sistemas electrónicos alcancen un nivel definido de seguridad con el tiempo. Gran parte de esto recae sobre los hombros de la industria de los chips, que proporciona la tecnología subyacente, y plantea interrogantes sobre qué más se puede hacer para mejorar la seguridad.
un crudo taxonomía Recientemente se introdujo para la verificación y prueba de seguridad y protección (ver figura 1 a continuación). Muchos problemas abarcan una matriz total. Por ejemplo, un vehículo autónomo debe tener hardware y software seguros y protegidos durante la vida útil del producto, pero también debe permanecer seguro incluso en presencia de fallas de hardware. Desafortunadamente, no existen herramientas que puedan determinar si se ha logrado este objetivo abstracto. En cambio, las herramientas y metodologías tienden a cubrir una o dos de las casillas, y la integración de eso es algo ad-hoc. Eso, a su vez, permite que algunos problemas potenciales caigan entre las grietas. Además, las métricas utilizadas están vagamente correlacionadas con la realidad.
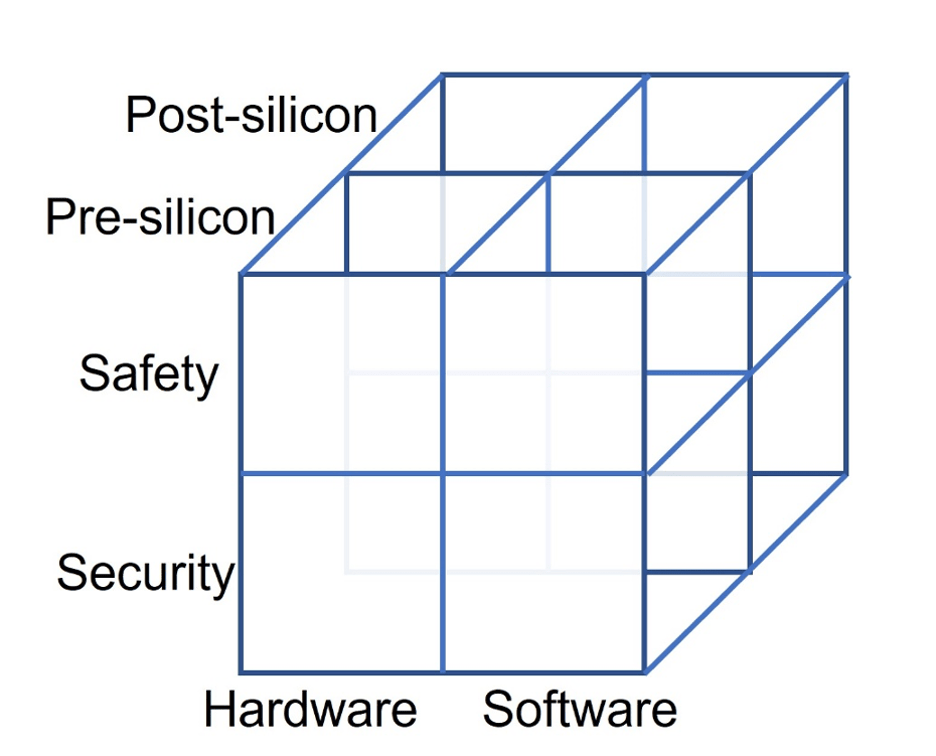
Fig. 1: Matriz de temas asociados a la seguridad y protección. Fuente: Ingeniería de semiconductores
Para empeorar las cosas, no todas las casillas o combinaciones de casillas se tratan adecuadamente en la actualidad, en parte porque se consideran de menor prioridad y en parte porque los costos son simplemente demasiado altos. Por ejemplo, la seguridad del hardware se trata mediante estándares en varios campos. La seguridad del software también está cubierta por diferentes estándares, pero nada define la seguridad del hardware y el software combinados ni habla sobre la seguridad del sistema completo. Lo más cerca que se pone es considerar campañas de fallas que intentan mostrar el porcentaje de errores de hardware detectados por el software. Además, cuanto más se optimice el hardware para cargas de trabajo y escenarios definidos, mayor será la posibilidad de que el software, o futuras actualizaciones de software, hagan que el hardware funcione de maneras que no se consideraron originalmente. Eso, a su vez, puede hacer que el hardware envejezca prematuramente o ponerlo en estados que creen vulnerabilidades inesperadas.
Modelos de falla
Medir cualquier cosa requiere una métrica práctica en el sentido de que algo debe ser manejable y efectivo, pero no necesariamente tiene que estar basado en la realidad. Los modelos de fallas, como el de atascado en la falla, existen desde hace mucho tiempo y han demostrado ser efectivos para representar fallas de hardware, aunque hay muchas formas en las que el hardware puede fallar, como circuitos abiertos, cortocircuitos o funcionamiento lento. Las fallas transitorias también son importantes porque representan posibles cambios de bits causados por la radiación.
“Existe una familia de especificaciones que se aplican a la seguridad funcional en varias industrias”, dice Pete Hardee, director de grupo para la gestión de productos en Cadencia. “Existe un estándar IEC general, IEC 61508, que es una especie de metaestándar. ISO 26262 fue un derivado de eso, hecho más específico para el mercado automotriz. Hay otros derivados de ese mismo metaestándar para ferrocarriles, equipos médicos, automatización de fábricas, nucleares, para todo tipo de cosas. Existe DO-254, que se aplica a la industria aeroespacial. Cada vez más personas ingresan a la cadena de suministro de esas áreas y tienen que considerar cumplir con algunas especificaciones de seguridad funcional”.
Entonces podemos impulsar esas especificaciones. "ISO 26262, y específicamente las partes 5 y 11, son la guía para los semiconductores", dice Jake Wiltgen, gerente de seguridad funcional y soluciones autónomas de Software de Siemens Digital Industries. “Hay métricas específicas que esos estándares solicitan, y esas son métricas de cobertura. El término utilizado en ISO es cobertura de diagnóstico, pero esencialmente es la tasa de fallas que se detecta sobre la tasa de fallas total”.
Es necesario establecer procesos. “Lograr un alto grado de confianza en la seguridad depende de procesos bien definidos y su estricta obediencia”, dice Roland Jancke, jefe de metodología de diseño en Fraunhofer IIS ' División Ingeniería de Sistemas Adaptativos. “Uno de los mejores métodos para eso es la ingeniería de requisitos (RE). Comienza con objetivos de seguridad bien definidos, continúa con el establecimiento de los requisitos respectivos y los transforma en casos de prueba. Un ingrediente esencial es establecer un seguimiento de los requisitos a lo largo de todo el proceso para entrar en el ciclo de rediseño solo para las partes afectadas en caso de que algo cambie”.
Para la automoción, la seguridad que debe tener un sistema depende del grado de autonomía. “Realmente depende del nivel de ASIL al que aspiran las personas”, dice Hardee de Cadence. “ASIL A no es un cambio real, pero 'tengo que certificar mi proceso'. ASIL B también puede tener muy poco impacto en algunos casos. Pero cuando se trata de cumplir con los niveles de ASIL C y ASIL D, puede convertirse en un gran desafío. Esto está muy relacionado con lo que la gente ya está haciendo para la verificación funcional, porque la metodología básica para verificar y cumplir con las especificaciones es observar una buena máquina y lograr una buena cobertura con la verificación funcional. Luego voy a comparar eso con una mala máquina en la que voy a introducir fallas. La tasa de fallas debe ser de 10 a menos ocho por hora de funcionamiento y tengo que ser capaz de detectar el 99 % de esas fallas y garantizar que el sistema falle de manera segura”.
Cómo se hace eso se deja al diseñador. “Depende de los diseñadores idear arquitecturas, tecnologías o soluciones que puedan demostrar que pueden cumplir con esos objetivos de calidad”, dice Simon Davidmann, fundador y director ejecutivo de Software Imperas. “El desafío es cómo revisan la calidad de lo que han hecho. Es posible que deseen ejecutar simulaciones, con fallas inyectadas, para ver qué tan resistente fue su software y hardware a estas fallas. Se ha trabajado mucho en los modelos de fallas, en términos de representar estas diferentes cosas que suceden en el mundo real”.
Ahí es donde entra en juego la practicidad. "Si toma un diseño de 100 millones de puertas y observa la cantidad de mecanismos de falla diferentes, no hay forma de que un solo enfoque pueda cubrir eso", dice Manish Pandey, vicepresidente de ingeniería del Grupo EDA en Sinopsis. “Desde una perspectiva formal, tomar todas las fallas e intentar propagarlas es computacionalmente inviable. Necesitamos mejores metodologías para muestrear los puntos, tener diferentes modos de falla interna, decidir regiones seguras e inseguras, etc. Dicha metodología de seguridad necesita formas de construir campañas de falla apropiadas, y esto debe hacerse de manera muy consciente. La conciencia de la microarquitectura es fundamental”.
Seguridad en el tiempo
No es suficiente hacer esto en un hardware ideal. “Otra categoría es garantizar la funcionalidad esperada durante toda la vida útil”, dice Jancke de Fraunhofer. “Esto está garantizado por la simulación de confiabilidad, que a su vez depende de los modelos de degradación adecuados para los mecanismos de envejecimiento conocidos y las capacidades integrales de extrapolación de la vida útil”.
El envejecimiento juega un papel fundamental. “Si observa las pruebas de fabricación, generalmente prueban un 20 % por encima y más allá de la especificación absoluta, ya sea la frecuencia del reloj, la potencia o la temperatura”, dice Robert Serphillips, gerente de producto de Veloce, DFT y seguridad funcional en Siemens EDA. “El silicio se degradará con el tiempo y la temperatura es muy crítica. Con calor alto, el dispositivo se ralentiza físicamente. Cosas como la ruta rápida y la ruta lenta ahora comienzan a volverse problemáticas. Desde el punto de vista de la seguridad, la forma en que se comporta el dispositivo en su entorno ambiental es fundamental para determinar cómo se degrada el dispositivo, cómo comienzan a aparecer las fallas y cómo comienzan a fallar los circuitos. Todo eso debe tenerse en cuenta, no solo los fotones aleatorios que se disparan desde el espacio exterior. ¿Puede el dispositivo comportarse de la misma manera durante la vida útil para la que está clasificado?
¿Y eso es compatible con el uso del modelo atascado? “Cuando consideramos el envejecimiento, el umbral de los circuitos puede cambiar”, dice Hardee. “El circuito puede ser más susceptible a esas cosas y el dispositivo puede fallar por completo, lo que generalmente creará una falla atascada”.
Pero no siempre. “Cuando vas a una geometría de 5nm o 3nm, hay muchas formas extrañas en las que estos chips envejecen y fallan”, dice Pandey de Synopsys. “En los cables, tienes electromigración y esto podría producir un circuito abierto. Hay algunos mecanismos que ni siquiera conocemos. Otra cosa interesante que está sucediendo es cómo se detectan fallas y cómo los sensores incorporados en el diseño pueden monitorear cómo se comportan estos chips, cómo se degradan. ¿Hay una falla potencial arrastrándose? Tendremos que complementar los enfoques tradicionales de campaña de fallas con monitoreo de chips e inteligencia de chips adicionales”.
El monitoreo en chip complementa otros bist tecnicas “Los monitores SLM avanzados se actualizan a través de análisis para actuar como mecanismos de seguridad capaces contra fallas intermitentes y degradantes”, dice Dan Alexandrescu, líder del equipo central de confiabilidad dentro de Ingeniería de Sistemas Estratégicos de Synopsys. “Un enfoque de varias etapas utiliza información de sensores avanzados que están estrechamente integrados en bloques de diseño críticos. El monitoreo del margen de la ruta, la detección previa al error, las mediciones del tiempo de acceso a la memoria, el ECC y los eventos BiST se evalúan de manera cohesiva en métricas de seguridad y calidad relevantes y oportunas. A continuación, se emite información procesable a los actuadores del sistema para corregir rápidamente las amenazas de seguridad y confiabilidad. Los datos de silicio profundo se envían a plataformas de borde y en la nube para el monitoreo a nivel de flota. Los análisis avanzados en todas las etapas brindan una comprensión rápida y precisa de eventos y fenómenos muy poco frecuentes, lo que ayuda a que los productos implementados se usen de manera segura y permiten una mayor calidad para los diseños futuros”.
El análisis remoto impone requisitos a la verificación funcional. “La supervisión del ciclo de vida y la notificación al OEM de que algo anda mal en un automóvil en particular con un número de VIN definido es algo que los OEM buscan hacer”, dice Johannes Stahl, director senior de gestión de línea de productos de Systems Design. Grupo en Synopsis. “Desde una perspectiva de verificación, en la etapa previa al silicio, debe asegurarse de que estos mecanismos funcionen y proporcionen la información correcta”.
Extendiéndose a la IA
Los vehículos autónomos utilizan cada vez más la IA, y esto presenta un nuevo conjunto de desafíos para la verificación y validación. Muchos de estos no se entienden completamente hoy. La Figura 2 (abajo) define cómo la verificación de los sistemas de IA difiere del software convencional.


Fig. 2: Contraste de algoritmos de aprendizaje automático y convencional desde la perspectiva de V&V. Fuente: Reproducido con autorización de un artículo titulado "PolyVerif: An Open-Source Environment for Autonomous Vehicle Validation and Verification Research Acceleration", escrito por Rahul Razdan, et al. Acceso IEEE - 2023
¿Cómo se detecta que un sistema de IA ha fallado? “La inteligencia artificial es un sistema estadístico y fallará en algún momento”, dice Pandey. “¿Cómo nos aseguramos de que estos sigan siendo sistemas que se comporten bien? Está surgiendo trabajo para verificar formalmente algunos de estos sistemas de IA y asegurarse de que se mantengan dentro de los límites. Se están realizando investigaciones para contener estos sistemas. Pero si estamos complementando los sistemas tradicionales con sensores adicionales y otros mecanismos a prueba de fallas, se necesita algo para calificar y asegurarnos de que los sistemas realmente hagan lo que se supone que deben hacer”.
En el futuro, se vuelve aún más complejo. “A nivel filosófico, un sistema de IA es por naturaleza un sistema de aprendizaje”, dice Stahl de Synopsys. “El software está escrito por un humano y puede contener errores. Entonces, filosóficamente, ¿la IA tiene un mayor riesgo que el software? ¿Es un sistema de IA que puede aprender?
Restricción del espacio de falla
El espacio de fallas para el hardware es enorme, incluso con un modelo de fallas muy restringido. Por lo tanto, se deben usar técnicas adicionales para limitar el número de fallas que realmente se deben considerar.
“El análisis de diagnóstico y efectos del modo de falla (FMEDA) tiene en cuenta las cifras de confiabilidad de los circuitos con los que está tratando”, dice Hardee. “Estás viendo los modos de falla y los efectos de esos modos. Así que en realidad solo estamos observando el subconjunto de fallas, que podrían ocurrir en lugares que se propagan a salidas funcionales que podrían causar daño”.
No hay una sola mejor manera de hacer esto. “Con la simulación de fallas, está inyectando fallas en el diseño y viendo si se detectan u observan”, dice Wiltgen de Siemens. “Pero esa no es la única manera. También hay otros métodos analíticos que se pueden implementar para llegar a esas métricas. Se necesita una combinación de diferentes herramientas y metodologías, tanto en el espacio estático y formal, como en el espacio de simulación, para llegar a esas métricas de la manera más rápida y eficiente posible”.
Las pruebas de campo y los gemelos digitales pueden complementar las herramientas existentes. “Alguien juguetea con un interruptor DIP y dice que estoy insertando un error aquí”, dice Frank Schirrmeister, vicepresidente de marketing de arterisa. “Desea verificar que su prueba realmente encontró este error. Esto es como ejecutar una campaña de seguridad, pero ejecutándola físicamente en el sistema. ¿Habrá más herramientas como esta para insertar elementos de seguridad y protección? Probablemente, y los extenderán a la virtualización. Con un gemelo digital electrónico, insertas algo y descubres si la representación virtual coincide con el hardware real”.
Conclusión
La evidencia empírica sugiere que los modelos de falla simplificados, aplicados racionalmente al aspecto del hardware del sistema, junto con software y sensores integrados para detectar y, a veces, corregir comportamientos errantes, hacen un trabajo adecuado para garantizar que el hardware esté seguro durante su vida útil. Se basa en unos pocos expertos que supervisan el proceso para asegurarse de que se le dé la consideración adecuada, según el entorno en el que va a operar y la cantidad de seguridad que se puede brindar.
Sin embargo, el proceso es ad-hoc e incompleto porque no considera la seguridad total del sistema. Ese debería ser el objetivo.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://semiengineering.com/why-its-so-difficult-to-ensure-system-safety-over-time/

