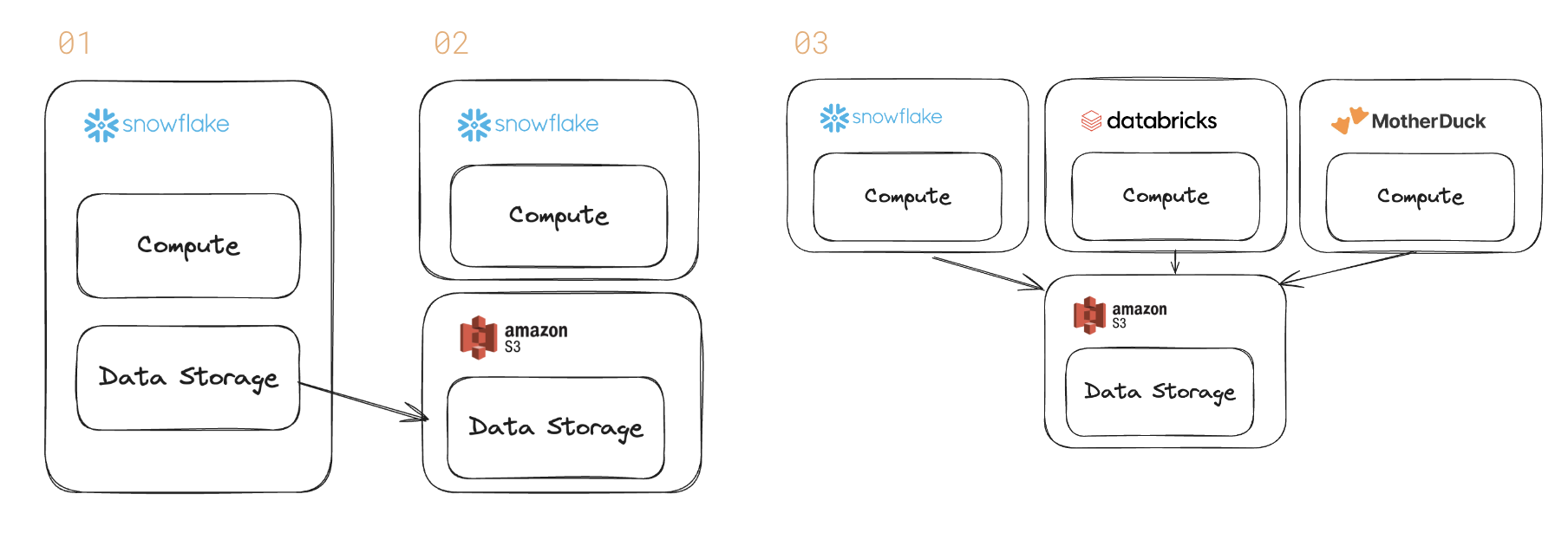
La base de datos se está desagregando. Históricamente, una base de datos como Snowflake vendía almacenamiento de datos y un motor de consultas (y la potencia informática para ejecutar la consulta). Ese es el paso 1 anterior.
Sin embargo, los clientes están presionando por una separación más profunda entre computación y almacenamiento. La reciente convocatoria de resultados de Snowflake destacó la tendencia. Los clientes más grandes prefieren formatos abiertos para la interoperabilidad (pasos 2 y 3).
Muchos grandes clientes quieren tener formatos de archivo abiertos que les brinden opciones... Por lo tanto, la interoperabilidad de datos es muy importante y nuestros productos de inteligencia artificial generalmente también pueden actuar sobre los datos que se encuentran almacenados en la nube.
Esperamos que varios de nuestros grandes clientes adopten formatos Iceberg y saquen sus datos de Snowflake, donde perderemos esos ingresos por almacenamiento y también los ingresos por computación asociados con el traslado de esos datos a Snowflake.
En lugar de bloquear los datos en una base de datos, los clientes prefieren tenerlos en formatos abiertos como Apache Arrow, Apache Parquet, Apache Iceberg.
A medida que se ha ampliado el uso de datos dentro de una empresa, también lo ha hecho la diversidad de demandas sobre esos datos.
En lugar de copiarlos cada vez para un propósito diferente, ya sea análisis exploratorio, inteligencia empresarial o cargas de trabajo de IA, ¿por qué no centralizar los datos y luego hacer que muchos sistemas diferentes accedan a ellos?
Esto ahorra dinero: el almacenamiento cuesta entre 280 y 300 millones de dólares en total para Snowflake.
Como recordatorio, entre el 10% y el 11% de nuestros ingresos totales están asociados con el almacenamiento.
Pero también simplifica las arquitecturas.
También marca el comienzo de una época en la que los motores de consulta competirán por diferentes cargas de trabajo en precio y rendimiento. Snowflake puede ser mejor para BI a gran escala; Spark de Databricks para canalizaciones de datos de IA; madrepato para análisis interactivos.
Los proveedores de almacenes de datos han comercializado el separación de almacenamiento y computación en el pasado. Pero ese mensaje trataba de escalar el sistema para manejar datos más grandes dentro de su propio producto.
Los clientes exigen una separación más profunda: un mundo en el que las bases de datos no cobren por el almacenamiento.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.tomtunguz.com/why-databases-wont-charge-storage/

