Introducción
La predicción del rendimiento de los cultivos es esencial análisis predictivo técnica en la industria agrícola. Es una práctica agrícola que puede ayudar a los agricultores y las empresas agrícolas a predecir el rendimiento de los cultivos en una temporada en particular, cuándo plantar un cultivo y cuándo cosechar para obtener un mejor rendimiento del cultivo. Analítica predictiva es una poderosa herramienta que puede ayudar a mejorar la toma de decisiones en la industria agrícola. Se puede usar para la predicción del rendimiento de cultivos, la mitigación de riesgos, la reducción del costo de los fertilizantes, etc. La predicción del rendimiento de cultivos mediante ML y el despliegue de matraces encontrará análisis sobre las condiciones climáticas, la calidad del suelo, la producción de frutos, la masa de frutos, etc.

OBJETIVOS DE APRENDIZAJE
- Repasaremos brevemente el proyecto de principio a fin para predecir el rendimiento de los cultivos utilizando modelos de simulación de polinización.
- Seguiremos cada paso del ciclo de vida del proyecto de ciencia de datos, incluida la exploración de datos, el preprocesamiento, el modelado, la evaluación y la implementación.
- Finalmente, implementaremos el modelo usando Flask API en una plataforma de servicios en la nube llamada render.
Entonces, comencemos con este emocionante enunciado del problema del mundo real.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Descripción del Proyecto
El conjunto de datos utilizado para este proyecto se generó utilizando un modelo informático de simulación espacial explícito para analizar y estudiar varios factores que afectan la predicción de arándanos silvestres, que incluyen:
- Arreglo espacial de plantas
- Cruzamiento y autopolinización
- Composiciones de especies de abejas
- Las condiciones climáticas (en forma aislada y en combinación) afectan la eficiencia de la polinización y el rendimiento del arándano silvestre en el ecosistema agrícola.
El modelo de simulación ha sido validado por la observación de campo y los datos experimentales recopilados en Maine, EE. UU. y Canadian Maritimes durante los últimos 30 años y ahora es una herramienta útil para probar hipótesis y estimar la predicción del rendimiento de arándanos silvestres. Estos datos simulados brindan a los investigadores datos reales recopilados del campo para varios experimentos sobre la predicción del rendimiento de cultivos, así como también brindan datos para que los desarrolladores y científicos de datos construyan en el mundo real. máquina de aprendizaje modelos para la predicción del rendimiento de cultivos.

¿Qué es el modelo de simulación de polinización?
El modelado de simulación de polinización es el proceso de utilizar modelos informáticos para simular el proceso de polinización. Hay varios casos de uso de simulación de polinización, tales como:
- Estudiar los efectos de diferentes factores en la polinización, como el cambio climático, la pérdida de hábitat y los pesticidas.
- Diseño de paisajes favorables a la polinización
- Predicción del impacto de la polinización en el rendimiento de los cultivos
Los modelos de simulación de polinización se pueden utilizar para estudiar el movimiento de los granos de polen entre las flores, el momento de los eventos de polinización y la eficacia de las diferentes estrategias de polinización. Esta información se puede utilizar para mejorar las tasas de polinización y el rendimiento de los cultivos, lo que puede ayudar aún más a los agricultores a producir cultivos de manera efectiva con un rendimiento óptimo.
Los modelos de simulación de polinización aún están en desarrollo, pero tienen el potencial de desempeñar un papel importante en el futuro de la agricultura. Al comprender cómo funciona la polinización, podemos proteger y administrar mejor este proceso esencial.
En nuestro proyecto, usaremos un conjunto de datos con varias características como 'tamaño clon','abeja','Dias lluviosos','Promedio de días de lluvia', etc., que se crearon utilizando un proceso de simulación de polinización para estimar el rendimiento de los cultivos.
Planteamiento del problema
En este proyecto, nuestra tarea es clasificar la variable de rendimiento (característica objetivo) en función de las otras 17 características paso a paso al realizar la tarea de cada día. Las métricas de evaluación se calificarán con RMSE. Implementaremos el modelo utilizando el marco Flask de Python en una plataforma basada en la nube.
Pre-requisitos
Este proyecto es ideal para estudiantes intermedios de ciencia de datos y aprendizaje automático para construir sus proyectos de cartera. Los principiantes en el campo pueden emprender este proyecto si están familiarizados con las siguientes habilidades:
- Conocimiento del lenguaje de programación Python y algoritmos de aprendizaje automático utilizando la biblioteca scikit-learn
- Comprensión básica del desarrollo de sitios web utilizando El marco del matraz de Python
- Entendimiento de Regresión métricas de evaluación
Descripción de datos
En esta sección, veremos todas y cada una de las variables del conjunto de datos para nuestro proyecto.
- Tamaño de clonación — m2 — El tamaño promedio de los clones de arándanos en el campo
- Miel De Abeja — abejas/m2/min — Densidad de abejas en el campo
- abejorros — abejas/m2/min — Densidad de abejorros en el campo
- andreña — abejas/m2/min — Densidad de abejas Andrena en el campo
- osmia — abejas/m2/min — Densidad de abejas Osmia en el campo
- MaxOfUpperTRango — ℃ —El registro más alto de la temperatura del aire diaria de la banda superior durante la temporada de floración
- MinOfUpperTRango — ℃ — El registro más bajo de la temperatura del aire diaria de la banda superior
- PromedioDeUpperTRango — ℃ — El promedio de la temperatura del aire diaria de la banda superior
- MaxOfLowerTRango — ℃ — El registro más alto de la temperatura del aire diaria de la banda inferior
- MinOfLowerTRango — ℃ — El registro más bajo de la temperatura del aire diaria de la banda inferior
- PromedioDeLowerTRango — ℃ — El promedio de la temperatura del aire diaria de la banda inferior
- Dias lluviosos — Día — El número total de días durante la temporada de floración, cada uno de los cuales tiene una precipitación mayor que cero
- Promedio de días de lluvia — Día — El promedio de días de lluvia en toda la temporada de floración
- Set de frutas — Tiempo de transición del cuajado
- masa de fruta — Masa del cuajado
- Tratamiento — Número de semillas en cuajado
- Rendimiento — Rendimiento del cultivo (una variable objetivo)
¿Cuál es el valor de estos datos para el caso de uso de predicción de cultivos?
- Este conjunto de datos proporciona información práctica sobre los rasgos espaciales de las plantas de arándanos silvestres, las especies de abejas y las situaciones climáticas. Por lo tanto, permite a los investigadores y desarrolladores crear modelos de aprendizaje automático para la predicción temprana del rendimiento de los arándanos.
- Este conjunto de datos puede ser esencial para otros investigadores que tienen datos de observación de campo pero desean probar y evaluar el rendimiento de diferentes algoritmos de aprendizaje automático comparando el uso de datos reales con los datos generados por simulación por computadora como entrada en la predicción del rendimiento del cultivo.
- Los educadores en diferentes niveles pueden usar el conjunto de datos para entrenar la clasificación de aprendizaje automático o regresión problemas en la industria agrícola.
Cargando conjunto de datos
En esta sección, cargaremos el conjunto de datos en cualquier entorno en el que esté trabajando. Cargue el conjunto de datos en el entorno kaggle. Use el conjunto de datos de kaggle o descárguelo a su máquina local y ejecútelo en el entorno local.
Fuente del conjunto de datos: Haga clic aquí
Veamos el código para cargar el conjunto de datos y cargar las bibliotecas para el proyecto.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.feature_selection import mutual_info_regression, SelectKBest
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split, cross_val_score, KFold from sklearn.model_selection import GridSearchCV, RepeatedKFold
from sklearn.ensemble import AdaBoostRegressor, GradientBoostingRegressor from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
import sklearn
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
import statsmodels.api as sm
from xgboost import XGBRegressor
import shap # setting up os env in kaggle import os
for dirname, _, filenames in os.walk('/kaggle/input'): for filename in filenames: print(os.path.join(dirname, filename)) # read the csv file and load first 5 rows in the platform df = pd.read_csv("/kaggle/input/wildblueberrydatasetpollinationsimulation/
WildBlueberryPollinationSimulationData.csv", index_col='Row#')
df.head()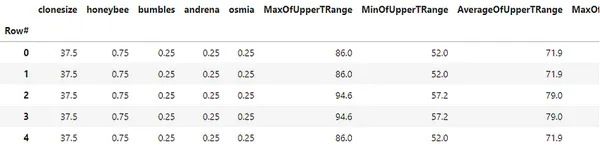
# print the metadata of the dataset
df.info() # data description
df.describe()
Códigos anteriores como 'df.info()' proporciona un resumen del marco de datos con el número de filas, el número de valores nulos, los tipos de datos de cada variable, etc. mientras 'df.describe()' proporcionar estadísticas descriptivas del conjunto de datos, como la media, la mediana, el conteo y los percentiles de cada variable en el conjunto de datos.
Análisis exploratorio de datos
En esta sección, veremos el análisis de datos exploratorios del conjunto de datos de cultivos y obtendremos información del conjunto de datos.
Mapa de calor del conjunto de datos
# create featureset and target variable from the dataset
features_df = df.drop('yield', axis=1)
tar = df['yield'] # plot the heatmap from the dataset
plt.figure(figsize=(15,15))
sns.heatmap(df.corr(), annot=True, vmin=-1, vmax=1)
plt.show()
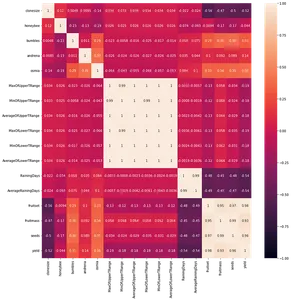
El gráfico anterior muestra una visualización de los coeficientes de correlación del conjunto de datos. Usando una biblioteca marina de Python podemos visualizarlo en solo 3 líneas de código.
Distribución de la Variable Objetivo
# plot the boxplot using seaborn library of the target variable 'yield'
plt.figure(figsize=(5,5))
sns.boxplot(x='yield', data=df)
plt.show()
El código anterior muestra la distribución de la variable de destino mediante un diagrama de caja. podemos ver que la mediana de la distribución está en alrededor de 6000 con un par de valores atípicos con el rendimiento más bajo.
Distribución por las características categóricas del conjunto de datos
# matplotlib subplot for the categorical feature nominal_df = df[['MaxOfUpperTRange','MinOfUpperTRange','AverageOfUpperTRange','MaxOfLowerTRange', 'MinOfLowerTRange','AverageOfLowerTRange','RainingDays','AverageRainingDays']] fig, ax = plt.subplots(2,4, figsize=(20,13))
for e, col in enumerate(nominal_df.columns): if e<=3: sns.boxplot(data=df, x=col, y='yield', ax=ax[0,e]) else: sns.boxplot(data=df, x=col, y='yield', ax=ax[1,e-4]) plt.show()
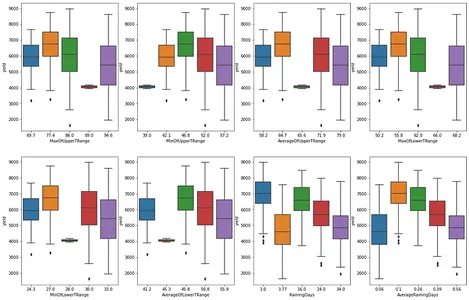
Distribución de tipos de abejas en nuestro conjunto de datos
# matplotlib subplot technique to plot distribution of bees in our dataset
plt.figure(figsize=(15,10))
plt.subplot(2,3,1)
plt.hist(df['bumbles'])
plt.title("Histogram of bumbles column")
plt.subplot(2,3,2)
plt.hist(df['andrena'])
plt.title("Histogram of andrena column")
plt.subplot(2,3,3)
plt.hist(df['osmia'])
plt.title("Histogram of osmia column")
plt.subplot(2,3,4)
plt.hist(df['clonesize'])
plt.title("Histogram of clonesize column")
plt.subplot(2,3,5)
plt.hist(df['honeybee'])
plt.title("Histogram of honeybee column")
plt.show()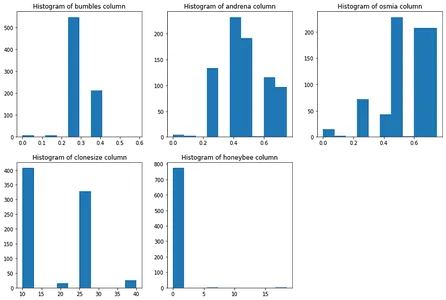
Anotemos algunas de las observaciones de about analysis:
- Las columnas de rango T superior e inferior se correlacionan entre sí
- Los días de lluvia y el promedio de días de lluvia se correlacionan entre sí
- "masa de fruta','set de frutas', y'semillasestán correlacionados
- La 'tropiezaLa columna ' está muy desequilibrada mientras que la 'andrena'Y'osmia' las columnas no son
- 'Honeybee' también es una columna desequilibrada en comparación con 'tamaño clon'
Preprocesamiento de datos y preparación de datos
En esta sección, preprocesaremos el conjunto de datos para el modelado. realizaremos una 'regresión de información mutua' para seleccionar las mejores características del conjunto de datos, realizaremos un agrupamiento en tipos de abejas en nuestro conjunto de datos y estandarizaremos el conjunto de datos para un modelado de aprendizaje automático eficiente.
Regresión de información mutua
# run the MI scores of the dataset
mi_score = mutual_info_regression(features_df, tar, n_neighbors=3,random_state=42)
mi_score_df = pd.DataFrame({'columns':features_df.columns, 'MI_score':mi_score})
mi_score_df.sort_values(by='MI_score', ascending=False)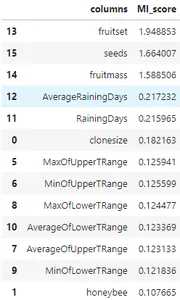
El código anterior calcula la regresión mutua utilizando el coeficiente de Pearson para encontrar las características más correlacionadas con la variable de destino. podemos ver las características más correlacionadas en orden descendente y cuáles están más correlacionadas con la característica de destino. ahora vamos a agrupar los tipos de abejas para crear una nueva función.
Agrupación usando K-medias
# clustering using kmeans algorithm
X_clus = features_df[['honeybee','osmia','bumbles','andrena']] # standardize the dataset using standard scaler
scaler = StandardScaler()
scaler.fit(X_clus)
X_new_clus = scaler.transform(X_clus) # K means clustering clustering = KMeans(n_clusters=3, random_state=42)
clustering.fit(X_new_clus)
n_cluster = clustering.labels_ # add new feature to feature_Df features_df['n_cluster'] = n_cluster
df['n_cluster'] = n_cluster
features_df['n_cluster'].value_counts() ---------------------------------[Output]----------------------------------
1 368
0 213
2 196
Name: n_cluster, dtype: int64El código anterior estandariza el conjunto de datos y luego aplica el algoritmo de agrupación para agrupar las filas en 3 grupos diferentes.
Normalización de datos usando el escalador Min-Max
features_set = ['AverageRainingDays','clonesize','AverageOfLowerTRange', 'AverageOfUpperTRange','honeybee','osmia','bumbles','andrena','n_cluster'] # final dataframe X = features_df[features_set]
y = tar.round(1) # train and test dataset to build baseline model using GBT and RFs by scaling the dataset
mx_scaler = MinMaxScaler()
X_scaled = pd.DataFrame(mx_scaler.fit_transform(X))
X_scaled.columns = X.columns
El código anterior representa el conjunto de características normalizadas 'X_escalado' y la variable de destino 'y' que se utilizará para el modelado.
Modelado y Evaluación
En esta sección, veremos el modelado de aprendizaje automático mediante el modelado de aumento de gradiente y el ajuste de hiperparámetros para obtener la precisión y el rendimiento deseados del modelo. Además, mire el modelo de regresión de mínimos cuadrados ordinarios usando la biblioteca de statsmodels y el explicador de modelos de forma para visualizar qué características son más importantes para nuestra predicción de rendimiento del cultivo objetivo.
Línea base de modelado de aprendizaje automático
# let's fit the data to the models lie adaboost, gradientboost and random forest
model_dict = {"abr": AdaBoostRegressor(), "gbr": GradientBoostingRegressor(), "rfr": RandomForestRegressor() } # Cross value scores of the models
for key, val in model_dict.items(): print(f"cross validation for {key}") score = cross_val_score(val, X_scaled, y, cv=5, scoring='neg_mean_squared_error') mean_score = -np.sum(score)/5 sqrt_score = np.sqrt(mean_score) print(sqrt_score) -----------------------------------[Output]------------------------------------
cross validation for abr
730.974385377955
cross validation for gbr
528.1673164806733
cross validation for rfr
608.0681265123212En el modelo de aprendizaje automático anterior, tenemos el error cuadrático medio más bajo en el regresor de aumento de gradiente, mientras que el error más alto en el regresor Adaboost. Ahora, entrenaremos el modelo de aumento de gradiente y evaluaremos el error usando el tren scikit-learn y probaremos el método de división.
# split the train and test data
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42) # gradient boosting regressor modeling
bgt = GradientBoostingRegressor(random_state=42)
bgt.fit(X_train,y_train)
preds = bgt.predict(X_test)
score = bgt.score(X_train,y_train)
rmse_score = np.sqrt(mean_squared_error(y_test, preds))
r2_score = r2_score(y_test, preds)
print("RMSE score gradient boosting machine:", rmse_score) print("R2 score for the model: ", r2_score) -----------------------------[Output]-------------------------------------------
RMSE score gradient boosting machine: 363.18286194620714
R2 score for the model: 0.9321362721127562Aquí, podemos ver que la puntuación RMSE del modelado de aumento de gradiente sin ajuste de hiperparámetros del modelo es de aproximadamente 363. Mientras que el R2 del modelo es de alrededor del 93 %, que es una mejor precisión del modelo que la precisión de la línea de base. Además, ajuste los hiperparámetros para optimizar la precisión del modelo de aprendizaje automático.
Ajuste de hiperparámetros
# K-fold split the dataset
kf = KFold(n_splits = 5, shuffle=True, random_state=0) # params grid for tuning the hyperparameters
param_grid = {'n_estimators': [100,200,400,500,800], 'learning_rate': [0.1,0.05,0.3,0.7], 'min_samples_split': [2,4], 'min_samples_leaf': [0.1,0.4], 'max_depth': [3,4,7] } # GBR estimator object estimator = GradientBoostingRegressor(random_state=42) # Grid search CV object clf = GridSearchCV(estimator=estimator, param_grid=param_grid, cv=kf, scoring='neg_mean_squared_error', n_jobs=-1)
clf.fit(X_scaled,y) # print the best the estimator and params
best_estim = clf.best_estimator_
best_score = clf.best_score_
best_param = clf.best_params_
print("Best Estimator:", best_estim)
print("Best score:", np.sqrt(-best_score)) -----------------------------------[Output]----------------------------------
Best Estimator: GradientBoostingRegressor(max_depth=7, min_samples_leaf=0.1, n_estimators=500, random_state=42)
Best score: 306.57274619213206Podemos ver que el error del modelo potenciador de gradiente sintonizado se ha reducido aún más con respecto a los anteriores y hemos optimizado los parámetros para nuestro modelo ML.
Explicación del modelo de forma
Aprendizaje automático La explicabilidad es un aspecto muy importante del modelado de ML en la actualidad. mientras que los modelos ML han dado resultados prometedores en muchos dominios, pero su complejidad inherente hace que sea difícil comprender cómo llegaron a ciertas predicciones o decisiones. La biblioteca Shap usa 'bien formado' valores para medir qué características influyen en la predicción de los valores objetivo. ahora veamos el 'Shap' gráficas explicativas del modelo para nuestro modelo de aumento de gradiente.
# shaply tree explainer
shap_tree = shap.TreeExplainer(bgt)
shap_values = shap_tree.shap_values(X_test)
shap.summary_plot(shap_values, X_test)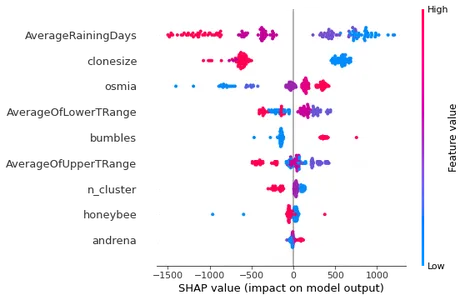
En el gráfico de salida anterior, está claro que Promedio de días de lluvia es la variable más influyente para explicar los valores predichos de la variable objetivo. mientras que la andrena característica afecta menos el resultado de la variable de predicción.
Despliegue del modelo usando FlaskAPI
En esta sección, implementaremos el modelo de aprendizaje automático mediante FlaskAPI en una plataforma de servicios en la nube llamada render.com. Antes de la implementación, es necesario guardar el archivo del modelo con la extensión joblib para crear una API que se pueda implementar en la nube.
Guardar el archivo del modelo
# remove the 'n_cluster' feature from the dataset
X_train_n = X_train.drop('n_cluster', axis=1)
X_test_n = X_test.drop('n_cluster', axis=1) # train a model for flask API creation =
xgb_model = XGBRegressor(max_depth=9, min_child_weight=7, subsample=1.0)
xgb_model.fit(X_train_n, y_train)
pr = xgb_model.predict(X_test_n)
err = mean_absolute_error(y_test, pr)
rmse_n = np.sqrt(mean_squared_error(y_test, pr)) # after training, save the model using joblib library
joblib.dump(xgb_model, 'wbb_xgb_model2.joblib')
Como puede ver, hemos guardado el archivo del modelo en el código anterior y cómo escribiremos el archivo de la aplicación Flask y el archivo del modelo para cargarlos en el repositorio de github.
Estructura del repositorio de aplicaciones
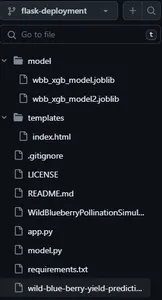
La imagen de arriba es la instantánea del repositorio de la aplicación que contiene los siguientes archivos y directorios.
- aplicación.py — Archivo de aplicación de matraz
- modelo.py — Archivo de predicción del modelo
- requerimientos.txt — Dependencias de la aplicación
- Directorio de modelos — Archivos de modelos guardados
- directorio de plantillas — Archivo de interfaz de usuario front-end
archivo app.py
from flask import Flask, render_template, Response
from flask_restful import reqparse, Api
import flask import numpy as np
import pandas as pd
import ast import os
import json from model import predict_yield curr_path = os.path.dirname(os.path.realpath(__file__)) feature_cols = ['AverageRainingDays', 'clonesize', 'AverageOfLowerTRange', 'AverageOfUpperTRange', 'honeybee', 'osmia', 'bumbles', 'andrena'] context_dict = { 'feats': feature_cols, 'zip': zip, 'range': range, 'len': len, 'list': list,
} app = Flask(__name__)
api = Api(app) # # FOR FORM PARSING
parser = reqparse.RequestParser()
parser.add_argument('list', type=list) @app.route('/api/predict', methods=['GET','POST'])
def api_predict(): data = flask.request.form.get('single input') # converts json to int i = ast.literal_eval(data) y_pred = predict_yield(np.array(i).reshape(1,-1)) return {'message':"success", "pred":json.dumps(int(y_pred))} @app.route('/')
def index(): # render the index.html templete return render_template("index.html", **context_dict) @app.route('/predict', methods=['POST'])
def predict(): # flask.request.form.keys() will print all the input from form test_data = [] for val in flask.request.form.values(): test_data.append(float(val)) test_data = np.array(test_data).reshape(1,-1) y_pred = predict_yield(test_data) context_dict['pred']= y_pred print(y_pred) return render_template('index.html', **context_dict) if __name__ == "__main__": app.run()El código anterior es el archivo de Python que toma la entrada de los usuarios e imprime la predicción del rendimiento del cultivo en la interfaz.
Archivo modelo.py
import joblib import pandas as pd
import numpy as np
import os # load the model file
curr_path = os.path.dirname(os.path.realpath(__file__))
xgb_model = joblib.load(curr_path + "/model/wbb_xgb_model2.joblib") # function to predict the yield
def predict_yield(attributes: np.ndarray): """ Returns Blueberry Yield value""" # print(attributes.shape) # (1,8) pred = xgb_model.predict(attributes) print("Yield predicted") return pred[0] El archivo Model.py carga el modelo durante el tiempo de ejecución y proporciona el resultado de la predicción.
Despliegue en Render
Una vez que todos los archivos se envían al repositorio de github, simplemente puede crear una cuenta en render.com para enviar la rama del repositorio que contiene el archivo app.py junto con otros artefactos. luego simplemente presione para desplegar en segundos. Además, render también proporciona una opción de implementación automática, lo que garantiza que cualquier cambio que se realice en sus archivos de implementación se refleje automáticamente en el sitio web.
Puede encontrar más información sobre el proyecto y el código en este liga del repositorio de github.
Conclusión
En este artículo, aprendimos sobre un proyecto integral de predicción del rendimiento de arándanos silvestres mediante algoritmos de aprendizaje automático y la implementación mediante FlaskAPI. Comenzamos a cargar el conjunto de datos, seguido de EDA, preprocesamiento de datos, modelado de aprendizaje automático e implementación en la plataforma de servicios en la nube.
Los resultados mostraron que el modelo podía predecir el rendimiento del cultivo con hasta un 93 % de R2. La API de Flask facilita el acceso al modelo y lo utiliza para hacer predicciones. lo hace accesible a una amplia gama de usuarios, incluidos agricultores, investigadores y formuladores de políticas. ahora veamos algunas de las lecciones aprendidas de este artículo.
- Aprendimos a definir declaraciones de problemas para el proyecto y realizar una canalización de proyecto de ML de extremo a extremo.
- Aprendimos sobre el análisis exploratorio de datos y el preprocesamiento del conjunto de datos para el modelado.
- Finalmente, aplicamos algoritmos de aprendizaje automático a nuestro conjunto de características para implementar un modelo para predicciones
Preguntas frecuentes
A. Los agricultores y las industrias agrícolas pueden utilizar la predicción del rendimiento de cultivos, una aplicación de aprendizaje automático, para pronosticar y predecir con precisión los rendimientos de cultivos específicos para un año o temporada determinados. Esto les permite prepararse para la temporada de cosecha y administrar de manera efectiva los costos asociados.
A. En agricultura inteligente, emplee varios algoritmos basados en sus aplicaciones. Algunos de estos algoritmos incluyen regresores de árbol de decisión, regresores de bosque aleatorio, regresores de aumento de gradiente, redes neuronales profundas y más.
A. Use AI y ML para predecir y pronosticar el rendimiento de los cultivos y predecir el costo estimado de la cosecha durante una temporada. Los algoritmos de IA ayudan a detectar enfermedades de cultivos y clasificaciones de plantas para clasificar y distribuir los cultivos sin problemas.
R. Los parámetros como la temperatura, la composición de los insectos, la altura del cultivo, la ubicación del suelo y varios parámetros meteorológicos como la lluvia y la humedad predicen el rendimiento del cultivo.
A. Para ayudar a los agricultores y las industrias agrícolas a crecer y estimar el rendimiento de los cultivos. Otro objetivo es ayudar a las agencias gubernamentales a decidir el precio de la cosecha y tomar las medidas apropiadas para el almacenamiento y distribución del rendimiento de la cosecha.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- EVM Finanzas. Interfaz unificada para finanzas descentralizadas. Accede Aquí.
- Grupo de medios cuánticos. IR/PR amplificado. Accede Aquí.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/06/crop-yield-prediction-using-machine-learning-and-flask-deployment/

