Para los clientes de lagos de datos que necesitan descubrir petabytes de datos, Rastreadores de AWS Glue son una forma popular de descubrir y catalogar datos en segundo plano. Esto permite a los usuarios buscar y encontrar datos relevantes de múltiples fuentes de datos. Muchos clientes también tienen datos en bases de datos operativas administradas como MongoDB Atlas y necesitan combinarlos con datos de Servicio de almacenamiento simple de Amazon (Amazon S3) lagos de datos para obtener información. Los rastreadores de AWS Glue ahora son compatibles con MongoDB Atlas, lo que simplifica la comprensión de la evolución de las colecciones de MongoDB y la extracción de información significativa.
Pegamento AWS es un servicio de integración de datos sin servidor que simplifica el descubrimiento, la preparación, el movimiento y la integración de datos de múltiples fuentes para análisis, aprendizaje automático (ML) y desarrollo de aplicaciones.
Atlas de MongoDB es un servicio de datos para desarrolladores del socio tecnológico de AWS MongoDB, Inc.. El servicio combina procesamiento transaccional, búsqueda basada en relevancia, análisis en tiempo real y sincronización de datos de móvil a nube en una arquitectura integrada.
Con el lanzamiento de hoy, puede crear y programar un rastreador de AWS Glue para rastrear MongoDB Atlas. En la configuración del rastreador, puede seleccionar MongoDB como fuente de datos. A continuación, puede crear una conexión de AWS Glue con MongoDB Atlas y proporcionar el nombre y las credenciales del clúster de MongoDB Atlas. Te guiamos a través de este proceso en esta publicación.
Resumen de la solución
La siguiente arquitectura ilustra cómo puede escanear una base de datos y colecciones de MongoDB Atlas utilizando AWS Glue.
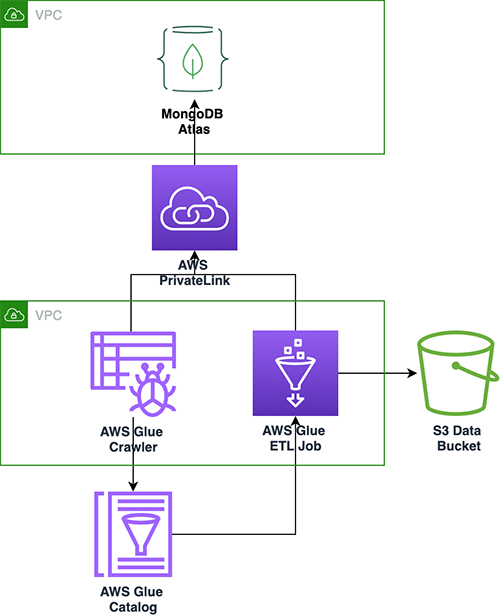
Con cada ejecución del rastreador, el rastreador inspecciona la información de colecciones y catálogos específicos, como actualizaciones o eliminaciones de colecciones, vistas y vistas materializadas de MongoDB Atlas en AWS Glue Data Catalog. En AWS Glue Studio, puede usar AWS Glue Data Catalog como fuente para extraer datos de MongoDB Atlas y completar un destino de Amazon S3. Finalmente, este trabajo puede ejecutar y leer datos de MongoDB Atlas y escribir los resultados en Amazon S3, lo que abre posibilidades para integrarse con servicios de AWS como Amazon SageMaker, Amazon QuickSight, y más.
En las siguientes secciones, describimos cómo crear un rastreador de AWS Glue con MongoDB Atlas como fuente de datos. Luego creamos una conexión de AWS Glue y proporcionamos la información y las credenciales del clúster de MongoDB Atlas. Luego especificamos la base de datos y las colecciones de MongoDB Atlas para rastrear.
Requisitos previos
Para seguir esta publicación, debe tener acceso a MongoDB Atlas y al Consola de administración de AWS. También asumimos que tiene acceso a una VPC con subredes preconfiguradas a través de Nube privada virtual de Amazon (VPC de Amazon). El rastreador que configuramos más adelante en la publicación se ejecuta en la VPC y se conecta a MongoDB Atlas a través de un Enlace privado de AWS punto final
Configurar MongoDB Atlas
Para configurar MongoDB Atlas, complete los siguientes pasos:
- Configure un clúster de MongoDB en AWS. Para obtener instrucciones, consulte Cómo configurar un clúster de MongoDB.
- Configure PrivateLink siguiendo los pasos descritos en Conexión segura de aplicaciones a un plano de datos de MongoDB Atlas con AWS PrivateLink.
Esto nos permite simplificar nuestra arquitectura de red y asegurarnos de que el tráfico permanezca en la red de AWS.
A continuación, obtenemos la cadena de conexión del clúster de MongoDB de la interfaz de usuario de Connect en la consola de MongoDB Atlas.
- En la consola de MongoDB Atlas, seleccione Contacto, Punto final privadoy Método de conexión.
- Copie la cadena de conexión SRV.

Usamos esta cadena de conexión SRV en los pasos posteriores.
La siguiente captura de pantalla muestra que hemos cargado una colección de muestra en MongoDB Atlas, que rastrearemos en los siguientes pasos. Tenga en cuenta que los registros de esta colección incluyen varias matrices, así como datos anidados.

Configure la conexión de MongoDB Atlas con AWS Glue
Antes de que podamos configurar el rastreador de AWS Glue, debemos crear la conexión de MongoDB Atlas en AWS Glue.
- En la consola de AWS Glue Studio, elija Conectores en el panel de navegación.
- Elige Crear conexión.

- Al completar los detalles de la conexión, use la cadena de conexión SRV que obtuvimos anteriormente en MongoDB Atlas.
- En Las opciones de red sección, la VPC y las subredes deben corresponder a la configuración de PrivateLink que configuró anteriormente.

Crear un rastreador MongoDB
Después de crear la conexión, podemos crear un rastreador de AWS Glue.
- En la consola de AWS Glue, elija Rastreadores en el panel de navegación.
- Elige Crear rastreador.

- Nombre, ingresa un nombre.
- Para la fuente de datos, elija la fuente de datos de MongoDB Atlas que configuramos anteriormente y proporcione la ruta que corresponde a la base de datos y la colección de MongoDB Atlas.

- Configure sus ajustes de seguridad, salida y programación.

- En Rastreadores página, elige Ejecutar rastreador.

Una vez que el rastreador termina de rastrear las colecciones de MongoDB, su estado se muestra como Completado.
Revise la base de datos y la tabla de MongoDB AWS Glue
Podemos navegar al catálogo de datos de AWS Glue para examinar las tablas que creó el rastreador.

Elija la tabla para ver el esquema y otros metadatos.

Tenga en cuenta que el rastreador capturó datos anidados como STRUCT y enumeró correctamente los campos ARRAY.
Importar datos de MongoDB Atlas a Amazon S3
Ahora usamos la tabla AWS Glue Data Catalog basada en MongoDB Atlas para realizar una importación de datos sin escribir código. Usamos AWS Glue Studio para crear código repetitivo rápidamente. Como alternativa, puede compilar la secuencia de comandos en el editor de secuencias de comandos.
- En la consola de AWS Glue Studio, elija Empleo en el panel de navegación.
- Elige Crear trabajo.
- Seleccione Objeto visual con un origen y un destino.
- Elija la tabla Data Catalog como origen y Amazon S3 como destino.

- En la interfaz de usuario de AWS Glue Studio, proporcione parámetros adicionales, como el nombre del depósito de S3, y elija la base de datos y la tabla en los menús desplegables.
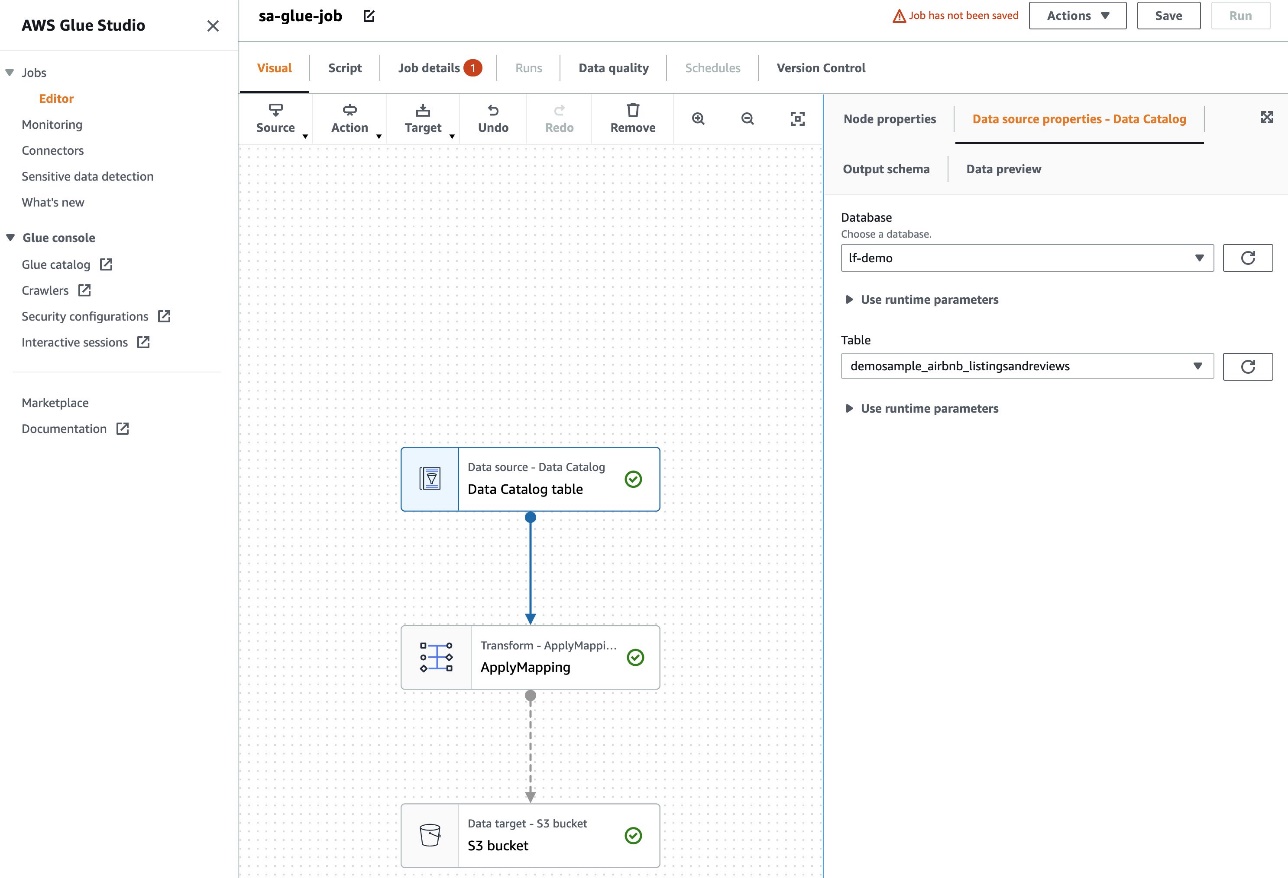
- A continuación, revise el script generado creado por AWS Glue Studio. Ahora necesitamos agregar una base de datos y una colección en el script de la siguiente manera:

Cuando se completa el trabajo de ETL, los datos extraídos están disponibles en Amazon S3.
- En la consola de Amazon S3, elija cubos en el panel de navegación.
- Elija nuestro depósito y carpeta que contiene los archivos extraídos.
- Elija un archivo y en la Acciones menú, seleccione Consulta con S3 Select para ver el contenido del archivo.

Limpiar
Para evitar incurrir en cargos por los servicios utilizados en este tutorial, complete los siguientes pasos para eliminar sus recursos:
- En la consola de AWS Glue, elija Rastreadores en el panel de navegación.
- Seleccione su rastreador y en el la columna Acción menú, seleccione Eliminar rastreador.
- En la consola de AWS Glue Studio, elija Ver trabajos.
- Seleccione el trabajo que ha creado y en la Acciones menú, seleccione Eliminar trabajo(s).
- Regrese a la consola de AWS Glue y elija Mesas en el panel de navegación.
- Seleccione su mesa y elija Borrar.
- Elige Bases de datos en el panel de navegación.
- Seleccione su base de datos y elija Borrar.
- En la consola de Amazon VPC, elija Endpoints en el panel de navegación.
- Seleccione el punto final de PrivateLink que creó y en la Acciones menú, seleccione Eliminar puntos de enlace de la VPC.
Conclusión
En esta publicación, mostramos cómo configurar un rastreador de AWS Glue para rastrear una colección de MongoDB Atlas, recopilar metadatos y crear registros de tablas en el catálogo de datos de AWS Glue. Con la tabla de catálogo de datos, creamos un proceso ETL utilizando la interfaz de usuario de AWS Glue Studio para extraer datos de la colección de MongoDB Atlas en un depósito S3 sin escribir una sola línea de código.
Puede probarlo usted mismo configurando un Rastreador de AWS Glue, creando un trabajo ETL de AWS Glue con Estudio de pegamento de AWSy lanzando MongoDB Atlas desde un QuickStart o desde MongoDB Atlas en el mercado de AWS.
Un agradecimiento especial a todos los que contribuyeron con el lanzamiento de esta característica del rastreador: Julio Montes de Oca, Mita Gavade y Alex Prazma.
Sobre los autores
 Igor Alekseev es socio sénior de arquitectura de soluciones en AWS en el dominio de datos y análisis. En su función, Igor está trabajando con socios estratégicos ayudándolos a construir arquitecturas complejas optimizadas para AWS. Antes de unirse a AWS, como arquitecto de soluciones/datos, implementó muchos proyectos en el dominio de Big Data, incluidos varios lagos de datos en el ecosistema de Hadoop. Como ingeniero de datos, participó en la aplicación de AI/ML a la detección de fraudes y la automatización de oficinas.
Igor Alekseev es socio sénior de arquitectura de soluciones en AWS en el dominio de datos y análisis. En su función, Igor está trabajando con socios estratégicos ayudándolos a construir arquitecturas complejas optimizadas para AWS. Antes de unirse a AWS, como arquitecto de soluciones/datos, implementó muchos proyectos en el dominio de Big Data, incluidos varios lagos de datos en el ecosistema de Hadoop. Como ingeniero de datos, participó en la aplicación de AI/ML a la detección de fraudes y la automatización de oficinas.
 Sandeep Adwankar es gerente sénior de productos técnicos en AWS. Con sede en el Área de la Bahía de California, trabaja con clientes de todo el mundo para traducir los requisitos comerciales y técnicos en productos que permitan a los clientes mejorar la forma en que administran, protegen y acceden a los datos.
Sandeep Adwankar es gerente sénior de productos técnicos en AWS. Con sede en el Área de la Bahía de California, trabaja con clientes de todo el mundo para traducir los requisitos comerciales y técnicos en productos que permitan a los clientes mejorar la forma en que administran, protegen y acceden a los datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/introducing-mongodb-atlas-metadata-collection-with-aws-glue-crawlers/

