IA generativa Los modelos tienen el potencial de revolucionar las operaciones empresariales, pero las empresas deben considerar cuidadosamente cómo aprovechar su poder mientras superan desafíos como salvaguardar los datos y garantizar la calidad del contenido generado por IA.
El marco de recuperación de generación aumentada (RAG) aumenta las indicaciones con datos externos de múltiples fuentes, como repositorios de documentos, bases de datos o API, para que los modelos básicos sean efectivos para tareas específicas de dominio. Esta publicación presenta las capacidades del modelo RAG y destaca el potencial transformador de MongoDB Atlas con su función de búsqueda vectorial.
Atlas de MongoDB es un conjunto integrado de servicios de datos que acelera y simplifica el desarrollo de aplicaciones basadas en datos. Su almacén de datos vectoriales se integra perfectamente con el almacenamiento de datos operativos, eliminando la necesidad de una base de datos independiente. Esta integración permite potentes capacidades de búsqueda semántica a través de Búsqueda de vectores, una forma rápida de crear búsqueda semántica y aplicaciones basadas en inteligencia artificial.
Amazon SageMaker permite a las empresas crear, entrenar e implementar modelos de aprendizaje automático (ML). JumpStart de Amazon SageMaker proporciona modelos y datos previamente entrenados para ayudarle a comenzar con el aprendizaje automático. Puede acceder, personalizar e implementar modelos y datos previamente entrenados a través de la página de inicio de SageMaker JumpStart en Estudio Amazon SageMaker Con unos pocos clics.
Amazon lex es una interfaz conversacional que ayuda a las empresas a crear chatbots y robots de voz que participan en interacciones naturales y realistas. Al integrar Amazon Lex con IA generativa, las empresas pueden crear un ecosistema holístico donde las aportaciones de los usuarios se transforman sin problemas en respuestas coherentes y contextualmente relevantes.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de la solución.

En las siguientes secciones, explicamos los pasos para implementar esta solución y sus componentes.
Configurar un clúster MongoDB
Para crear un clúster MongoDB Atlas de nivel gratuito, siga las instrucciones en Crear un clúster. Configurar la base de datos de la máquina y red de la máquina.
Implementar el modelo de incrustación de SageMaker
Puede elegir el modelo de empotramiento (ALL MiniLM L6 v2) en el SageMaker JumpStart Modelos, portátiles, soluciones .
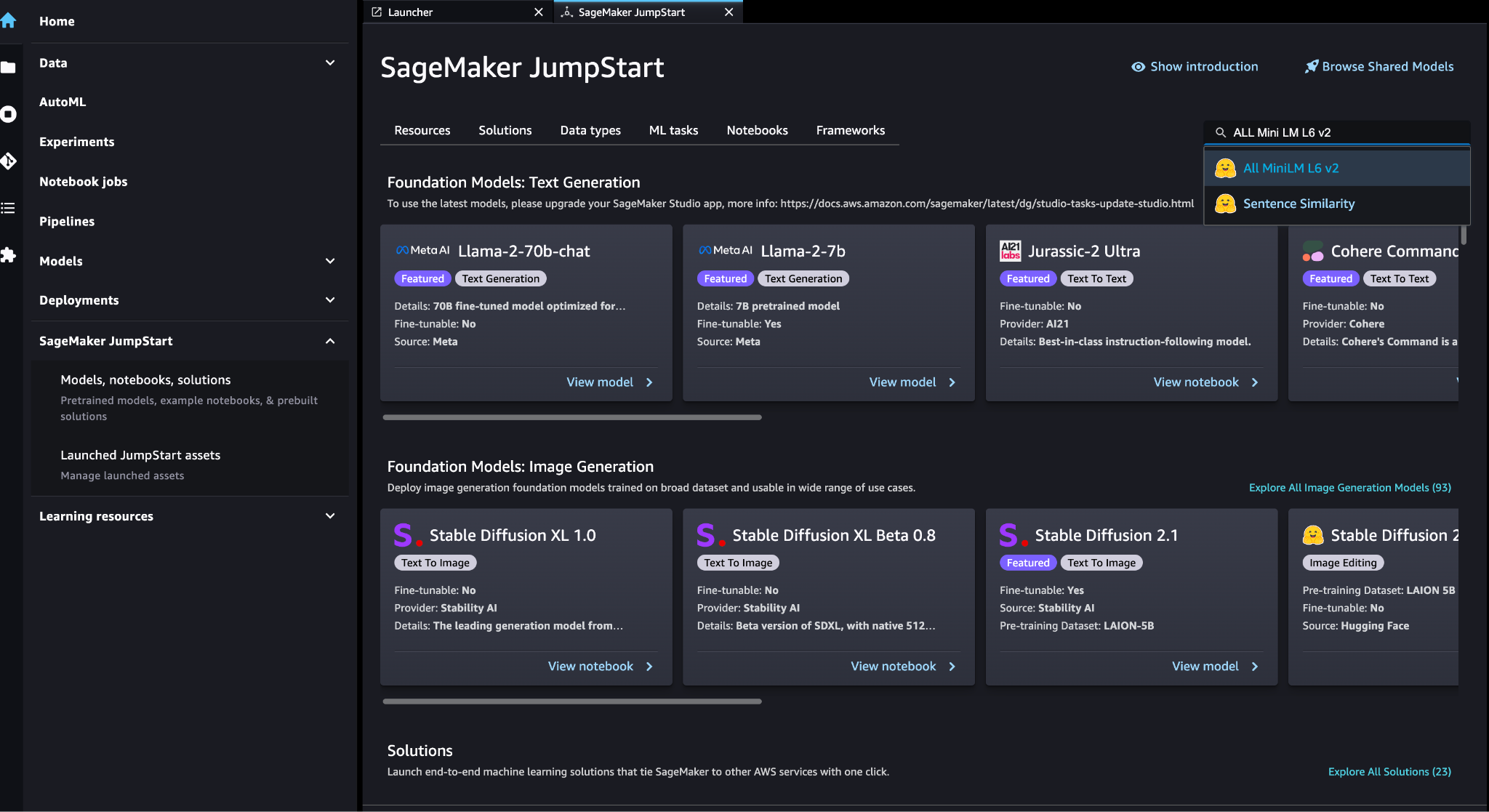
Elige Despliegue para desplegar el modelo.
Verifique que el modelo se haya implementado correctamente y verifique que se haya creado el punto final.

Incrustación de vectores
Incrustación de vectores es un proceso de convertir un texto o una imagen en una representación vectorial. Con el siguiente código, podemos generar incrustaciones de vectores con SageMaker JumpStart y actualizar la colección con el vector creado para cada documento:
payload = {"text_inputs": [document[field_name_to_be_vectorized]]}
query_response = query_endpoint_with_json_payload(json.dumps(payload).encode('utf-8'))
embeddings = parse_response_multiple_texts(query_response) # update the document
update = {'$set': {vector_field_name : embeddings[0]}}
collection.update_one(query, update)El código anterior muestra cómo actualizar un solo objeto en una colección. Para actualizar todos los objetos siga las Instrucciones.
Almacén de datos vectoriales MongoDB
Búsqueda vectorial del Atlas de MongoDB es una nueva característica que le permite almacenar y buscar datos vectoriales en MongoDB. Los datos vectoriales son un tipo de datos que representan un punto en un espacio de alta dimensión. Este tipo de datos se utiliza a menudo en aplicaciones de aprendizaje automático e inteligencia artificial. MongoDB Atlas Vector Search utiliza una técnica llamada k-vecinos más cercanos (k-NN) para buscar vectores similares. k-NN funciona encontrando los k vectores más similares a un vector dado. Los vectores más similares son los que están más cerca del vector dado en términos de distancia euclidiana.
Almacenar datos vectoriales junto a datos operativos puede mejorar el rendimiento al reducir la necesidad de mover datos entre diferentes sistemas de almacenamiento. Esto es especialmente beneficioso para aplicaciones que requieren acceso en tiempo real a datos vectoriales.
Crear un índice de búsqueda de vectores
El siguiente paso es crear un Índice de búsqueda de vectores de MongoDB en el campo vectorial que creó en el paso anterior. MongoDB utiliza el knnVector escriba para indexar incrustaciones de vectores. El campo vectorial debe representarse como una matriz de números (solo tipos de datos BSON int32, int64 o double).
Consulte Revisar las limitaciones del tipo de knnVector para obtener más información sobre las limitaciones del knnVector tipo.
El siguiente código es una definición de índice de ejemplo:
{ "mappings": { "dynamic": true, "fields": { "egVector": { "dimensions": 384, "similarity": "euclidean", "type": "knnVector" } } }
}
Tenga en cuenta que la dimensión debe coincidir con la dimensión del modelo de incrustaciones.
Consultar el almacén de datos vectoriales
Puede consultar el almacén de datos vectoriales utilizando el Tubería de agregación de búsqueda vectorial. Utiliza el índice de búsqueda de vectores y realiza una búsqueda semántica en el almacén de datos vectoriales.
El siguiente código es una definición de búsqueda de ejemplo:
{ $search: { "index": "<index name>", // optional, defaults to "default" "knnBeta": { "vector": [<array-of-numbers>], "path": "<field-to-search>", "filter": {<filter-specification>}, "k": <number>, "score": {<options>} } }
}
Implementar el modelo de lenguaje grande de SageMaker
Modelos básicos de SageMaker JumpStart son modelos de lenguaje grande (LLM) previamente entrenados que se utilizan para resolver una variedad de tareas de procesamiento del lenguaje natural (NLP), como el resumen de texto, la respuesta a preguntas y la inferencia del lenguaje natural. Están disponibles en una variedad de tamaños y configuraciones. En esta solución utilizamos el Abrazando la cara Modelo FLAN-T5-XL.
Busque el modelo FLAN-T5-XL en SageMaker JumpStart.
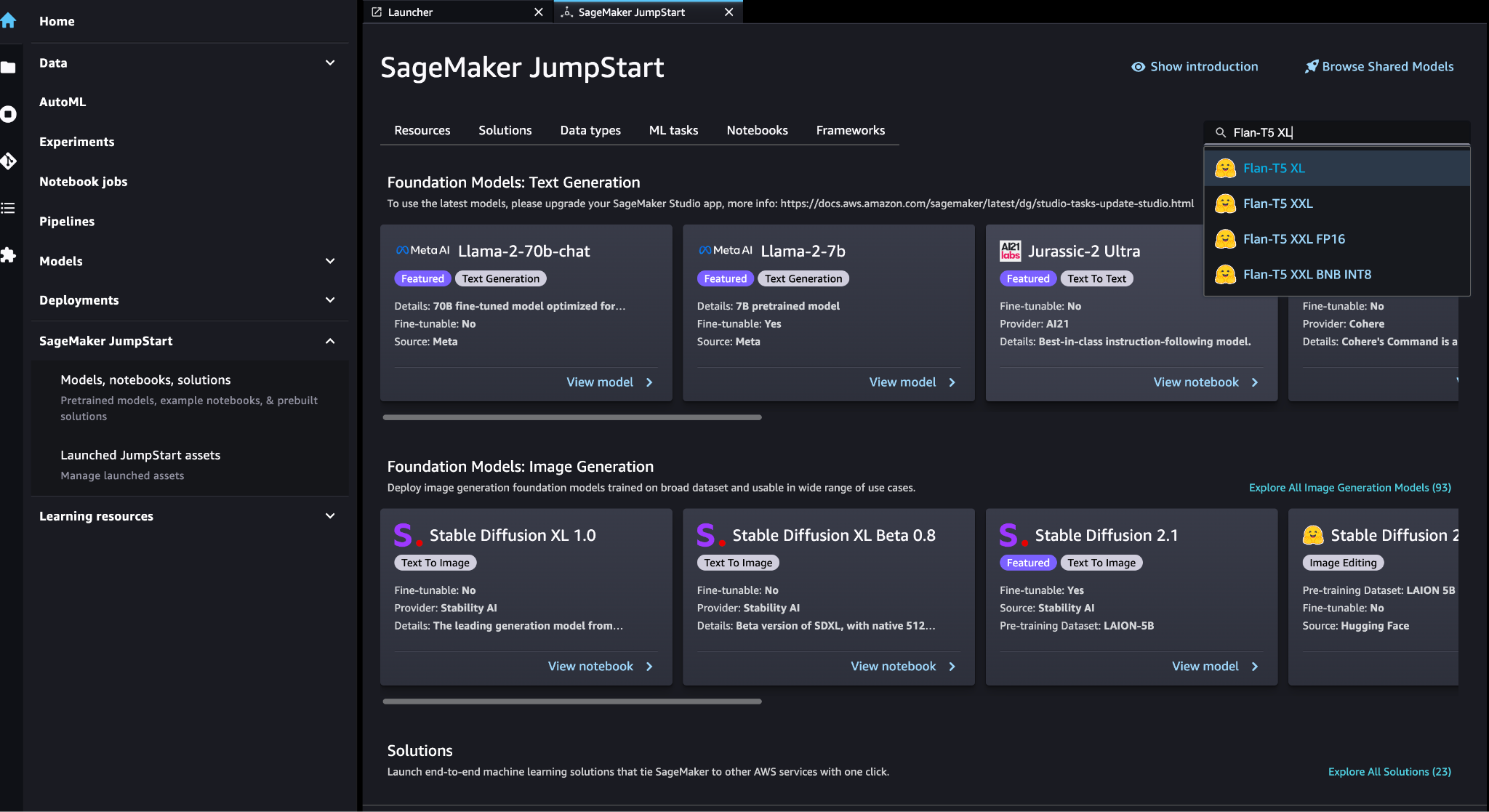
Elige Despliegue para configurar el modelo FLAN-T5-XL.
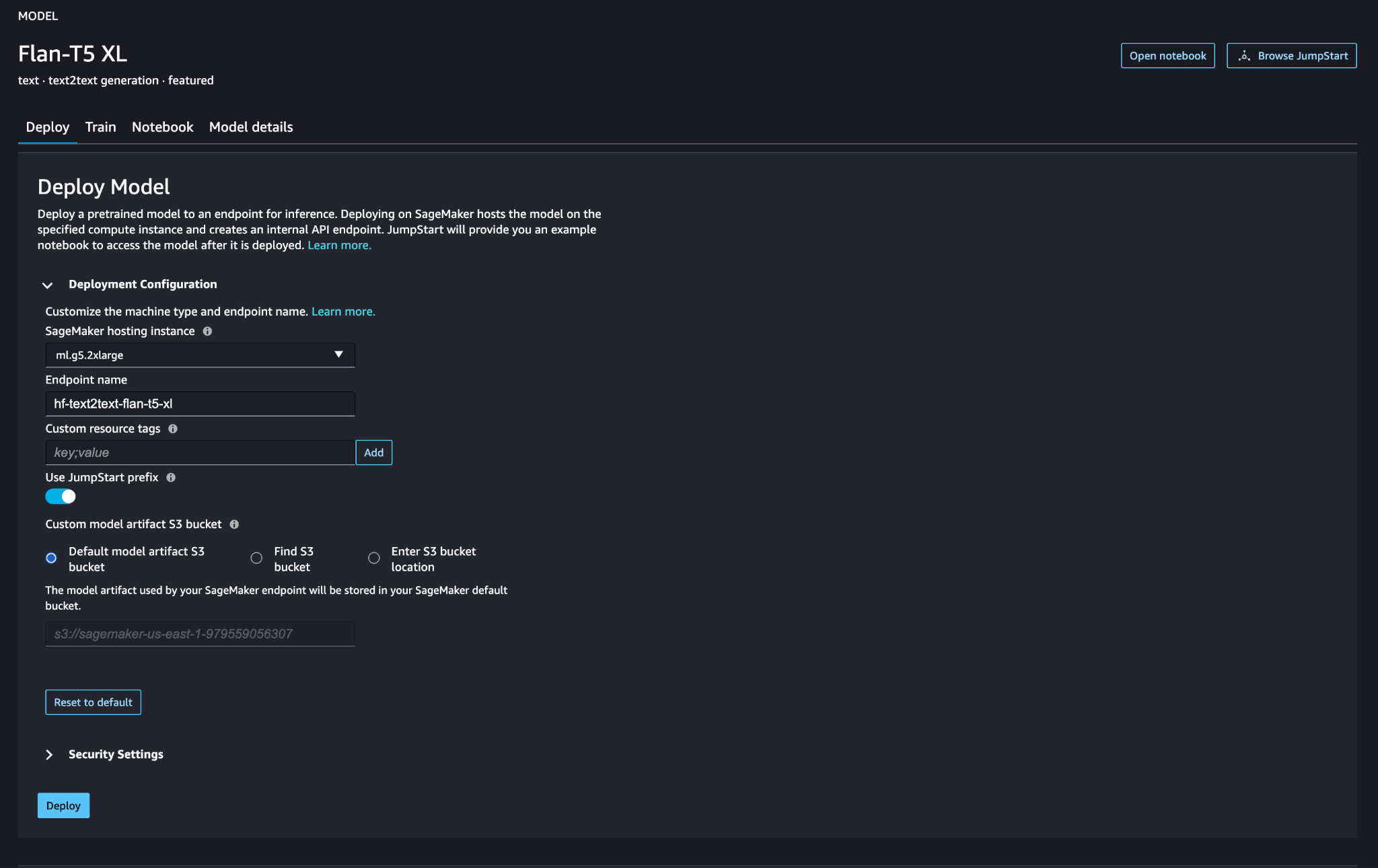
Verifique que el modelo se haya implementado correctamente y que el punto final esté activo.

Crear un bot de Amazon Lex
Para crear un bot de Amazon Lex, complete los siguientes pasos:
- En la consola de Amazon Lex, elija Crear bot.

- Nombre del bot, ingresa un nombre.
- Rol de tiempo de ejecución, seleccione Cree un rol con permisos básicos de Amazon Lex.

- Especifique su configuración de idioma y luego elija Terminado.

- Agregue un enunciado de muestra en el
NewIntentUI y elige Guardar intento.
- Navegue hasta la
FallbackIntentque fue creado para usted de forma predeterminada y alternar Active existentes Cumplimiento .
- Elige Construcción y después de que la construcción sea exitosa, elija Probar.
- Antes de realizar la prueba, elija el ícono de ajustes.

- Especifica el AWS Lambda función que interactuará con MongoDB Atlas y el LLM para proporcionar respuestas. Para crear la función lambda siga estos pasos.

- Ahora puede interactuar con el LLM.
Limpiar
Para limpiar sus recursos, complete los siguientes pasos:
- Elimine el bot de Amazon Lex.
- Elimine la función Lambda.
- Elimine el punto final de LLM SageMaker.
- Elimine el punto final de SageMaker del modelo de incrustaciones.
- Elimine el clúster MongoDB Atlas.
Conclusión
En la publicación, mostramos cómo crear un bot simple que utiliza la búsqueda semántica de MongoDB Atlas y se integra con un modelo de SageMaker JumpStart. Este bot le permite crear rápidamente un prototipo de interacción del usuario con diferentes LLM en SageMaker Jumpstart mientras los combina con el contexto que se origina en MongoDB Atlas.
Como siempre, AWS agradece los comentarios. Deje sus comentarios y preguntas en la sección de comentarios.
Sobre los autores

Igor Alekseev es socio sénior de arquitectura de soluciones en AWS en el dominio de datos y análisis. En su función, Igor está trabajando con socios estratégicos ayudándolos a construir arquitecturas complejas optimizadas para AWS. Antes de unirse a AWS, como arquitecto de soluciones/datos, implementó muchos proyectos en el dominio de Big Data, incluidos varios lagos de datos en el ecosistema de Hadoop. Como ingeniero de datos, participó en la aplicación de AI/ML a la detección de fraudes y la automatización de oficinas.
 Babu Srinivasan es Arquitecto de Soluciones de Socio Senior en MongoDB. En su puesto actual, trabaja con AWS para crear integraciones técnicas y arquitecturas de referencia para las soluciones de AWS y MongoDB. Cuenta con más de dos décadas de experiencia en tecnologías de Base de Datos y Nube. Le apasiona brindar soluciones técnicas a los clientes que trabajan con múltiples integradores de sistemas globales (GSI) en múltiples geografías.
Babu Srinivasan es Arquitecto de Soluciones de Socio Senior en MongoDB. En su puesto actual, trabaja con AWS para crear integraciones técnicas y arquitecturas de referencia para las soluciones de AWS y MongoDB. Cuenta con más de dos décadas de experiencia en tecnologías de Base de Datos y Nube. Le apasiona brindar soluciones técnicas a los clientes que trabajan con múltiples integradores de sistemas globales (GSI) en múltiples geografías.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/retrieval-augmented-generation-with-langchain-amazon-sagemaker-jumpstart-and-mongodb-atlas-semantic-search/

