Introducción
“Menos es más”, como dijo el famoso arquitecto Ludwig Mies van der Rohe, y esto es lo que significa resumir. El resumen es una herramienta fundamental para reducir el contenido textual voluminoso a fragmentos concisos y relevantes, que atraigan el acelerado consumo de información actual. En aplicaciones de texto, el resumen ayuda a la recuperación de información y respalda la toma de decisiones. La integración de la IA generativa, como los modelos basados en OpenAI GPT-3, ha revolucionado este proceso al no solo extraer elementos clave del texto y generar resúmenes coherentes que conservan la esencia de la fuente. Curiosamente, las capacidades de la IA generativa se extienden más allá del texto al resumen de vídeo. Esto implica extraer escenas, diálogos y conceptos fundamentales de los videos, creando representaciones abreviadas del contenido. Puede lograr un resumen de video de muchas maneras diferentes, incluida la generación de un breve video resumido, la realización de un análisis del contenido del video y el resaltado de secciones clave del video o la creación de un resumen textual del video mediante la transcripción de video.
La API Open AI Whisper aprovecha la tecnología de reconocimiento automático de voz para convertir el lenguaje hablado en texto escrito, aumentando así la precisión y eficiencia del resumen de texto. Por otro lado, la API Hugging Face Chat proporciona modelos de lenguaje de última generación como GPT-3.
OBJETIVOS DE APRENDIZAJE
En este artículo aprenderemos sobre:
- Aprendemos sobre técnicas de resumen de vídeos.
- Comprender las aplicaciones del resumen de vídeo
- Explore la arquitectura del modelo Open AI Whisper
- Aprenda a implementar el resumen textual en video utilizando la API Open AI Whisper y Hugging Chat
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Técnicas de resumen de vídeo
Análisis de vídeo
Implica el proceso de extraer información significativa de un video. Usar deep learning para rastrear e identificar objetos y acciones en un video e identificar las escenas. Algunas de las técnicas populares para el resumen de videos son:
Extracción de fotogramas clave y detección de límites de disparo
Este proceso incluye convertir el video a una cantidad limitada de imágenes fijas. Video skim es otro término para este video más corto de tomas clave.
Las tomas de vídeo son series continuas e ininterrumpidas de fotogramas. El reconocimiento de límites de toma detecta transiciones entre tomas, como cortes, desvanecimientos o disoluciones, y elige fotogramas de cada toma para crear un resumen. A continuación se detallan los pasos principales para extraer un resumen de video breve continuo de un video más largo:
- Extracción de cuadros – La instantánea del video se extrae del video, podemos tomar 1 fps para video de 30 fps.
- Detección de rostros y emociones – Luego podemos extraer caras del video y calificar las emociones de las caras para detectar puntuaciones de emociones. Detección de rostros mediante SSD (Detector multibox de disparo único).
- Clasificación y selección de cuadros – Seleccione fotogramas que tengan una puntuación de emoción alta y luego clasifíquelos.
- Extracción final – Extraemos subtítulos del vídeo junto con marcas de tiempo. Luego extraemos las oraciones correspondientes a los cuadros extraídos seleccionados anteriormente, junto con sus horas de inicio y finalización en el video. Finalmente, fusionamos las partes del video correspondientes a estos intervalos para generar el video resumen final.
Reconocimiento de acciones y submuestreo temporal
En esto tratamos de identificar la acción humana realizada en el video. Esta es una aplicación ampliamente utilizada de análisis de video. Dividimos el vídeo en pequeñas subsecuencias en lugar de fotogramas e intentamos estimar la acción realizada en el segmento mediante técnicas de clasificación y reconocimiento de patrones como HMC (Análisis de cadena oculta de Markov).
Enfoques únicos y multimodales
En este artículo hemos utilizado un enfoque modal único en el que utilizamos el audio del vídeo para crear un resumen del vídeo utilizando un resumen textual. Aquí utilizamos un
Un solo aspecto del video que es audio, conviértalo en texto y luego obtenga un resumen usando ese texto.
En un enfoque multimodal, combinamos información de muchas modalidades, como audio, visual y texto, brindando un conocimiento holístico del contenido del video para un resumen más preciso.
Aplicaciones del resumen de vídeo
Antes de profundizar en la implementación de nuestro resumen de vídeo, primero debemos conocer las aplicaciones del resumen de vídeo. A continuación se muestran algunos de los ejemplos enumerados de resúmenes de vídeo en una variedad de campos y dominios:
- Seguridad y vigilancia: El resumen de video puede permitirnos analizar una gran cantidad de videos de vigilancia para resaltar eventos importantes sin revisar el video manualmente.
- Educación y entrenamiento: Se pueden entregar notas clave y videos de capacitación para que los estudiantes puedan revisar el contenido del video sin tener que revisar todo el video.
- Navegación de contenido: Youtube utiliza esto para resaltar una parte importante del vídeo relevante para la búsqueda del usuario con el fin de permitir que los usuarios decidan si quieren ver ese vídeo en particular o no según sus requisitos de búsqueda.
- Gestión de desastres: Para emergencias y crisis, el resumen en video puede permitir tomar acciones basadas en situaciones destacadas en el resumen en video.
Descripción general del modelo Open AI Whisper
El modelo Whisper de Open AI es un reconocimiento automático de voz (ASR). Se utiliza para transcribir audio de voz a texto.
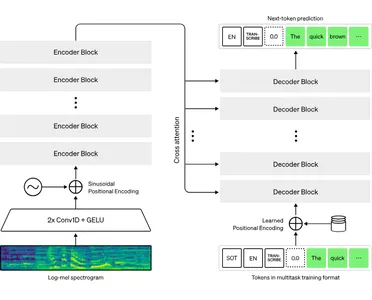
Se basa en la arquitectura transformadora, que apila bloques codificadores y decodificadores con un mecanismo de atención que propaga información entre ellos. Tomará la grabación de audio, la dividirá en partes de 30 segundos y procesará cada una individualmente. Para cada grabación de 30 segundos, el codificador codifica el audio y conserva la ubicación de cada palabra dicha, y el decodificador utiliza esta información codificada para determinar lo que se dijo.
El decodificador esperará tokens de toda esta información, que son básicamente cada palabra pronunciada. Luego repetirá este proceso para la siguiente palabra, utilizando la misma información para ayudarlo a identificar la siguiente que tiene más sentido.

Ejemplo de codificación para resumen textual en vídeo

1 – Instalar y cargar bibliotecas
!pip install yt-dlp openai-whisper hugchat
import yt_dlp
import whisper
from hugchat import hugchat
#Function for saving audio from input video id of youtube
def download(video_id: str) -> str: video_url = f'https://www.youtube.com/watch?v={video_id}' ydl_opts = { 'format': 'm4a/bestaudio/best', 'paths': {'home': 'audio/'}, 'outtmpl': {'default': '%(id)s.%(ext)s'}, 'postprocessors': [{ 'key': 'FFmpegExtractAudio', 'preferredcodec': 'm4a', }] } with yt_dlp.YoutubeDL(ydl_opts) as ydl: error_code = ydl.download([video_url]) if error_code != 0: raise Exception('Failed to download video') return f'audio/{video_id}.m4a' #Call function with video id
file_path = download('A_JQK_k4Kyc&t=99s')
3 – Transcribe audio a texto usando Whisper
# Load whisper model
whisper_model = whisper.load_model("tiny") # Transcribe audio function
def transcribe(file_path: str) -> str: # `fp16` defaults to `True`, which tells the model to attempt to run on GPU. transcription = whisper_model.transcribe(file_path, fp16=False) return transcription['text'] #Call the transcriber function with file path of audio transcript = transcribe('/content/audio/A_JQK_k4Kyc.m4a')
print(transcript)4 – Resume el texto transcrito usando Hugging Chat
Nota para usar la API de Hugging Chat, debemos iniciar sesión o registrarnos en Hugging Face. plataforma. Después de eso, en lugar de "nombre de usuario" y "contraseña", debemos pasar nuestras credenciales de cara de abrazo.
from hugchat.login import Login # login
sign = Login("username", "password")
cookies = sign.login()
sign.saveCookiesToDir("/content") # load cookies from usercookies
cookies = sign.loadCookiesFromDir("/content") # This will detect if the JSON file exists, return cookies if it does and raise an Exception if it's not. # Create a ChatBot
chatbot = hugchat.ChatBot(cookies=cookies.get_dict()) # or cookie_path="usercookies/<email>.json"
print(chatbot.chat("Hi!")) #Summarise Transcript
print(chatbot.chat('''Summarize the following :-'''+transcript))Conclusión
En conclusión, el concepto de resumen es una fuerza transformadora en la gestión de la información. Es una poderosa herramienta que resume contenido voluminoso en formas concisas y significativas, adaptadas al acelerado consumo del mundo actual.
A través de la integración de modelos de IA generativa como GPT-3 de OpenAI, el resumen ha trascendido sus límites tradicionales, evolucionando hacia un proceso que no solo extrae sino que genera resúmenes coherentes y contextualmente precisos.
El viaje hacia el resumen en vídeo revela su relevancia en diversos sectores. La implementación de cómo la extracción de audio, la transcripción usando Whisper y el resumen a través de Hugging Face Chat se pueden integrar perfectamente para crear resúmenes textuales en video.
Puntos clave
1. IA generativa: el resumen de videos se puede lograr utilizando tecnologías de IA generativa como LLM y ASR.
2. Aplicaciones en campos: el resumen de videos es realmente beneficioso en muchos campos importantes donde uno tiene que analizar una gran cantidad de videos para extraer información crucial.
3. Implementación básica: en este artículo exploramos la implementación del código básico del resumen de video basado en la dimensión de audio.
4. Arquitectura del modelo: también aprendimos sobre la arquitectura básica del modelo Open AI Whisper y su flujo de proceso.
Preguntas frecuentes
R. El límite de llamadas a la API de Whisper es 50 por minuto. No hay límite de longitud de audio, pero solo se pueden compartir archivos de hasta 25 MB. Se puede reducir el tamaño del archivo de audio disminuyendo la tasa de bits de audio.
A. Los siguientes formatos de archivo: m4a, mp3, webm, mp4, mpga, wav, mpeg
R. Algunas de las principales alternativas para el reconocimiento automático de voz son: Twilio Voice, Deepgram, Azure Speech-to-text, Google Cloud Speech-to-text.
R. Una de las dificultades para comprender diversos acentos de un mismo idioma, necesidad de aplicaciones de formación especializada en campos especializados.
R. Se están llevando a cabo investigaciones avanzadas en el campo del reconocimiento de voz, como la decodificación del habla imaginada a partir de señales EEG utilizando arquitectura neuronal. Esto permite a las personas
con discapacidades del habla para comunicar sus pensamientos sobre el habla al mundo exterior con la ayuda de dispositivos. Uno de esos artículos interesantes esta página.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/09/video-summarization-using-openai-whisper-and-hugging-chat-api/

