Los datos pierden valor con el tiempo. Nuestros clientes nos dicen que les gustaría analizar las transacciones comerciales en tiempo real. Tradicionalmente, los clientes utilizaban enfoques basados en lotes para el movimiento de datos desde sistemas operativos a sistemas analíticos. La carga por lotes puede ejecutarse una o varias veces al día. Un enfoque basado en lotes puede introducir latencia en el movimiento de datos y reducir el valor de los datos para el análisis. El enfoque basado en Change Data Capture (CDC) ha surgido como una alternativa a los enfoques basados en lotes. Un enfoque basado en CDC captura los cambios de datos y los pone a disposición en almacenes de datos para análisis adicionales en tiempo real.
CDC rastrea los cambios realizados en la base de datos de origen, como inserciones, actualizaciones y eliminaciones, y actualiza continuamente esos cambios en la base de datos de destino. Cuando el CDC es de alta frecuencia, la base de datos de origen cambia rápidamente y la base de datos de destino (es decir, generalmente un almacén de datos) necesita reflejar esos cambios casi en tiempo real.
Con la explosión de los datos, ha aumentado la cantidad de sistemas de datos en las organizaciones. Los silos de datos hacen que los datos vivan en diferentes fuentes, lo que dificulta la realización de análisis.
Para obtener conocimientos más profundos y ricos, puede reunir todos los cambios de diferentes silos de datos en un solo lugar, como un almacén de datos. Este post muestra cómo utilizar la ingestión de streaming para llevar datos a Desplazamiento al rojo de Amazon.
Ingestión de transmisión de Redshift proporciona ingesta de datos de alto rendimiento y baja latencia, lo que permite a los clientes obtener información en segundos en lugar de minutos. Es fácil de configurar e ingiere directamente datos en streaming en su almacén de datos desde Secuencias de datos de Amazon Kinesis y Amazon Managed Streaming para Kafka (Amazon MSK) sin necesidad de realizar una puesta en escena Servicio de almacenamiento simple de Amazon (Amazon S3). Puede crear vistas materializadas utilizando declaraciones SQL. Después de eso, al utilizar la actualización de vista materializada, puede ingerir cientos de megabytes de datos por segundo.
Resumen de la solución
En esta publicación, creamos una replicación de datos de baja latencia entre Amazon Aurora MySQL a Amazon Redshift Data Warehouse, utilizando Ingestión de transmisión de Redshift de Amazon MSK. Al utilizar Amazon MSK, transmitimos datos de forma segura con un servicio Apache Kafka totalmente administrado y de alta disponibilidad. Apache Kafka es una plataforma de transmisión de eventos distribuida de código abierto utilizada por miles de empresas para canalizaciones de datos de alto rendimiento, análisis de transmisión, integración de datos y aplicaciones de misión crítica. Almacenamos eventos de CDC en Amazon MSK, durante un período de tiempo determinado, lo que hace posible entregar eventos de CDC a destinos adicionales, como el lago de datos de Amazon S3.
desplegamos MySQL debezium Conector Kafka de origen en Amazon MSK Connect. Conexión de Amazon MSK facilita la implementación, el monitoreo y la escala automática de conectores que mueven datos entre clústeres de Apache Kafka y sistemas externos como bases de datos, sistemas de archivos e índices de búsqueda. Amazon MSK Connect es totalmente compatible con Conexión de Apache Kafka, que le permite levantar y cambiar sus aplicaciones Apache Kafka Connect sin cambios de código.
Esta solución utiliza Amazon Aurora MySQL que aloja la base de datos de ejemplo. salesdb. Los usuarios de la base de datos pueden realizar las operaciones INSERTAR, ACTUALIZAR y ELIMINAR a nivel de fila para producir los eventos de cambio en el ejemplo. salesdb base de datos. MySQL debezium fuente Kafka Connector lee estos eventos de cambio y los emite a los temas de Kafka en Amazon MSK. Luego, Amazon Redshift lee los mensajes de los temas de Kafka de Amazon MSK mediante la función Amazon Redshift Streaming. Amazon Redshift almacena estos mensajes mediante vistas materializadas y los procesa a medida que llegan.
Puede ver cómo CDC realiza la creación de eventos mirando este ejemplo esta página. Usaremos el campo OP: su cadena obligatoria describe el tipo de operación que provocó que el conector generara el evento en nuestra solución de procesamiento. En este ejemplo, c indica que la operación creó una fila. Los valores válidos para el campo OP son:
- c = crear
- u = actualizar
- d = eliminar
- r = leer (se aplica solo a instantáneas)
El siguiente diagrama ilustra la arquitectura de la solución:
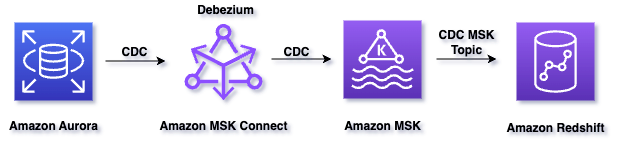
El flujo de trabajo de la solución consta de los siguientes pasos:
- Amazon Aurora MySQL tiene un registro binario (es decir, binlog) que registra todas las operaciones (INSERT, UPDATE, DELETE) en el orden en que se confirman en la base de datos.
- Amazon MSK Connect ejecuta el conector Kafka de origen llamado conector Debezium para MySQL, lee el binlog, produce eventos de cambio para operaciones INSERT, UPDATE y DELETE a nivel de fila y emite los eventos de cambio a temas de Kafka en amazon MSK.
- Un clúster aprovisionado por Amazon Redshift es el consumidor de la transmisión y puede leer mensajes de temas de Kafka desde Amazon MSK.
- Una vista materializada en Amazon Redshift es el área de aterrizaje para los datos leídos del flujo, que se procesa a medida que llega.
- Cuando se actualiza la vista materializada, los nodos informáticos de Amazon Redshift asignan un grupo de particiones Kafka a un segmento informático.
- Cada segmento consume datos de las particiones asignadas hasta que la vista alcanza la paridad con el último desplazamiento del tema de Kafka.
- Las actualizaciones posteriores de la vista materializada leen datos desde el último desplazamiento de la actualización anterior hasta que alcanza la paridad con los datos del tema.
- Dentro de Amazon Redshift, creamos un procedimiento almacenado para procesar registros CDC y actualizar la tabla de destino.
Requisitos previos
Esta publicación supone que tiene una pila de Amazon MSK Connect en ejecución en su entorno con los siguientes componentes:
- Aurora MySQL aloja una base de datos. En esta publicación, utiliza la base de datos de ejemplo.
salesdb. - El conector Debezium MySQL que se ejecuta en Amazon MSK Connect, que conecta Amazon MSK en su Nube privada virtual de Amazon (VPC de Amazon).
- Clúster de Amazon MSK
Si no tiene una pila de Amazon MSK Connect, siga las instrucciones del Configuración del laboratorio MSK Connect y verifique que su conector de origen replica los cambios de datos en los temas de Amazon MSK.
Debe aprovisionar el clúster de Amazon Redshift en la misma VPC del clúster de Amazon MSK. Si no ha implementado uno, siga los pasos esta página en la documentación de AWS.
Usamos AWS Identity and Access Management (IAM de AWS) autenticación para la comunicación entre Amazon MSK y el clúster de Amazon Redshift. Asegúrese de haber creado una función de AWS IAM con una política de confianza que permita a su clúster de Amazon Redshift asumir la función. Para obtener información sobre cómo configurar la política de confianza para el rol de AWS IAM, consulte Autorizar a Amazon Redshift a acceder a otros servicios de AWS en su nombre. Una vez creado, el rol debe tener la siguiente política de AWS IAM, que proporciona permiso para comunicarse con el clúster de Amazon MSK.
Reemplace el ARN que contiene xxx de la política de ejemplo anterior con el ARN de su clúster de Amazon MSK.
- Además, verifique que el clúster de Amazon Redshift tenga acceso al clúster de Amazon MSK. En el grupo de seguridad de Amazon Redshift Cluster, agregue la regla de entrada para el grupo de seguridad MSK que permita el puerto 9098. Para ver cómo administrar el grupo de seguridad del clúster Redshift, consulte Administrar grupos de seguridad de VPC para un clúster.

- Y en el grupo de seguridad del clúster de Amazon MSK agregue la regla de entrada que permite el puerto 9098 para la dirección IP líder de su clúster de Amazon Redshift, como se muestra en el siguiente diagrama. Puede encontrar la dirección IP del nodo líder de su clúster de Amazon Redshift en la pestaña de propiedades del clúster de Amazon Redshift en Consola de administración de AWS.

Tutorial
Navegue hasta el servicio Amazon Redshift desde la Consola de administración de AWS y luego configure la ingesta de streaming de Amazon Redshift para Amazon MSK realizando los siguientes pasos:
- enable_case_SENSITIVE_IDENTIFICADOR a verdadero – En caso de que esté utilizando un grupo de parámetros predeterminado para Amazon Redshift Cluster, no podrá configurar
enable_case_sensitive_identifiera verdadero. Puedes crear nuevos grupo de parámetrosenable_case_sensitive_identifieren verdadero y adjuntarlo al clúster de Amazon Redshift. Después de modificar los valores de los parámetros, debe reiniciar todos los clústeres asociados con el grupo de parámetros modificado. Es posible que el clúster de Amazon Redshift tarde unos minutos en reiniciarse.
Este configuración valor que determina si los identificadores de nombres de bases de datos, tablas y columnas distinguen entre mayúsculas y minúsculas. Una vez hecho esto, abra un nuevo Amazon Redshift Query Editor V2 para que se reflejen los cambios de configuración que realizamos y luego siga los siguientes pasos.
- Cree un esquema externo que se asigne a la fuente de datos de transmisión.
Una vez hecho esto, verifique si ve las siguientes tablas creadas a partir de temas de MSK:
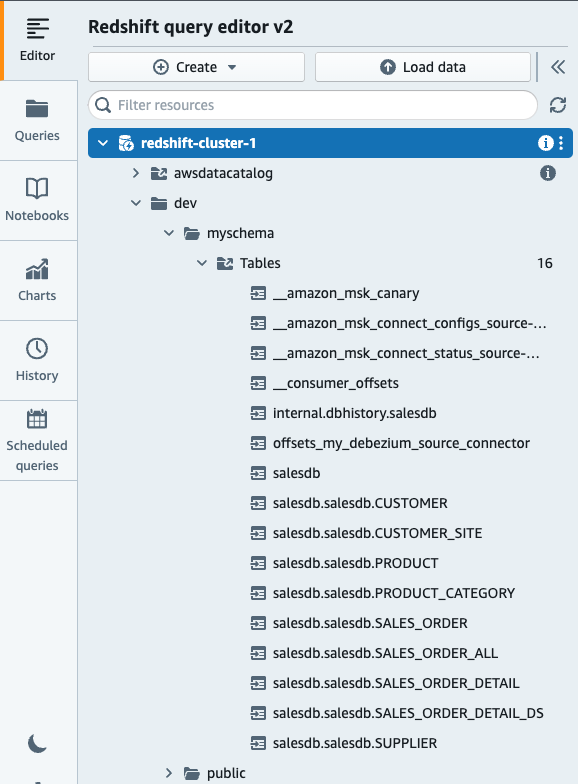
- Cree una vista materializada que haga referencia al esquema externo.
Ahora, puede consultar la vista materializada recién creada customer_debezium usando el siguiente comando.
Verifique que la vista materializada esté completa con los registros CDC
- ACTUALIZAR VISTA MATERIALIZADA (opcional). Este paso es opcional como ya hemos especificado
AUTO REFRESH AS YESmientras crea MV (vista materializada).
NOTA: La vista superior materializada se actualiza automáticamente, lo que significa que si no ve los registros inmediatamente, deberá esperar unos segundos y volver a ejecutar la instrucción de selección. La vista de ingestión de streaming de Amazon Redshift también viene con la opción de actualización manual, que le permite actualizar manualmente el objeto. Puede utilizar la siguiente consulta que extrae la transmisión de datos al objeto Redshift inmediatamente.
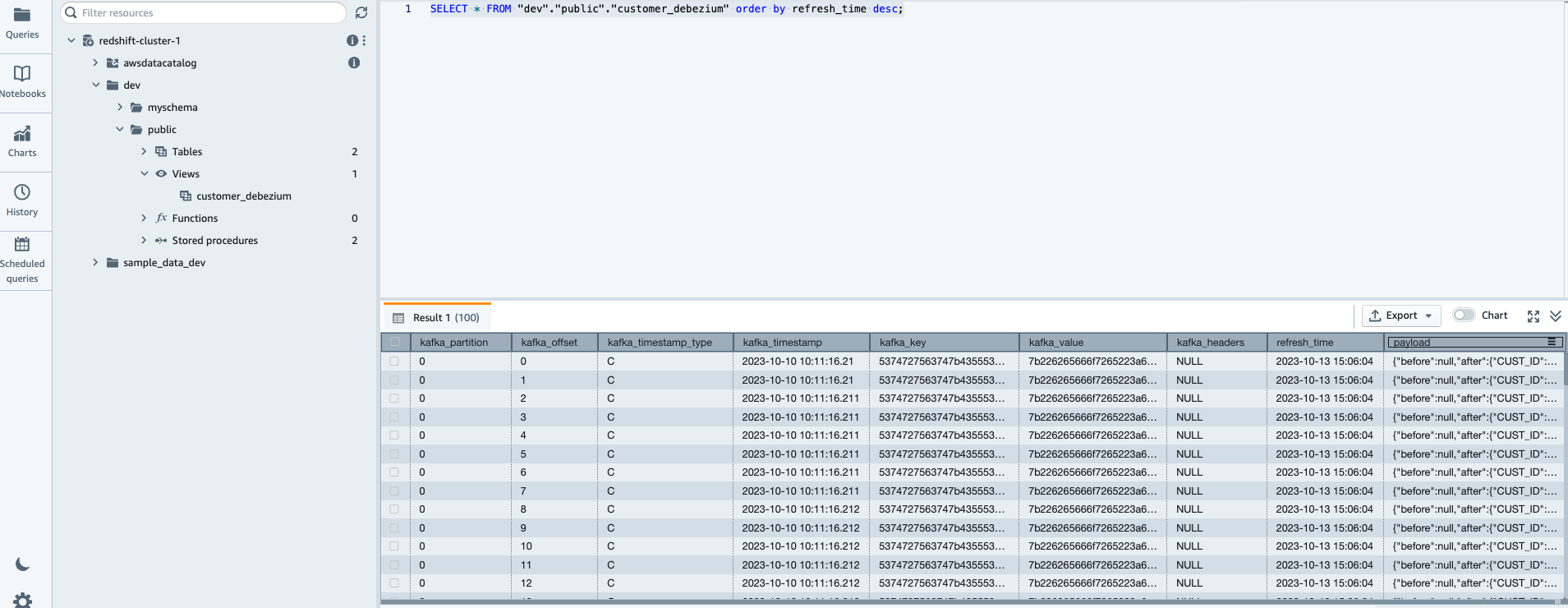
Procesar registros CDC en Amazon Redshift
En los siguientes pasos, creamos la tabla provisional para contener los datos CDC, que es la tabla de destino que contiene la última instantánea y el procedimiento almacenado para procesar registros CDC y actualizarlos en la tabla de destino.
- Crear tabla de preparación: La mesa de preparación Es una tabla temporal que contiene todos los datos que se utilizarán para realizar cambios en el tabla de destino, incluidas actualizaciones e inserciones.
- Crear tabla de destino
Utilizamos customer_target tabla para cargar los eventos CDC procesados.
- Crear
Last_extract_timetabla de debezium e inserción de valor ficticio.
Necesitamos almacenar la marca de tiempo de los últimos eventos CDC extraídos. Usamos de debezium_last_extract tabla para este fin. Para el registro inicial insertamos un valor ficticio, que nos permite realizar una comparación entre la marca de tiempo de procesamiento CDC actual y la siguiente.
- Crear procedimiento almacenado
Este procedimiento almacenado procesa los registros CDC y actualiza la tabla de destino con los últimos cambios.

Prueba la solución
Ejemplo de actualización salesdb alojado en Amazon Aurora
- Esta sera tu Aurora amazónica base de datos y accedemos a ella desde Amazon Elastic Compute Cloud (Amazon EC2) instancia con
Name= KafkaClientInstance. - Por favor, reemplace el punto final de Amazon Aurora con el valor de su punto final de Amazon Aurora y ejecute el siguiente comando y el
use salesdb.
- Realiza una actualización, inserción y eliminación en cualquiera de las tablas creadas. También puede actualizar más de una vez para comprobar el último registro actualizado más adelante en Amazon Redshift.
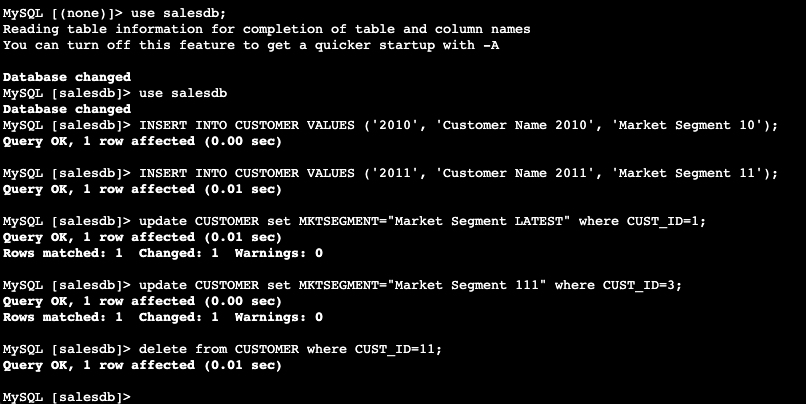
- Invocar el procedimiento almacenado cliente_sincronización_incremental creado en los pasos anteriores desde Amazon Redshift Query Editor v2. Puede ejecutar proc manualmente usando el siguiente comando o programarla.
call incremental_sync_customer();- Consulte la tabla de destino para conocer los últimos cambios.. Este paso es para verificar los últimos valores en la tabla de destino. Verá que todas las actualizaciones y eliminaciones que realizó en la tabla de origen se muestran en la parte superior como resultado ordenado por
refresh_time.

Ampliando la solución
En esta solución, mostramos el procesamiento CDC para la tabla de clientes y puede usar el mismo enfoque para extenderlo a otras tablas del ejemplo. salesdb base de datos o agregar más bases de datos a Configuración de conexión MSK perfecta database.include.list.
Nuestro enfoque propuesto puede funcionar con cualquier fuente MySQL soportada por MySQL debezium fuente Conector Kafka. De manera similar, para extender este ejemplo a sus cargas de trabajo y casos de uso, debe crear las tablas provisionales y de destino de acuerdo con el esquema de la tabla de origen. Entonces necesitas actualizar el coalesce(payload.after."CUST_ID",payload.before."CUST_ID")::varchar as customer_id declaraciones con los nombres y tipos de columnas en sus tablas de origen y de destino. Como en el ejemplo indicado en esta publicación, utilizamos la codificación LZO como codificación LZO, que funciona bien para columnas CHAR y VARCHAR que almacenan cadenas de caracteres muy largas. También puede utilizar BYTEDICT si coincide con su caso de uso. Otra consideración a tener en cuenta al crear tablas de destino y de preparación es elegir un estilo de distribución y una clave en función de los datos de la base de datos de origen. Aquí hemos elegido el estilo de distribución como clave con Customer_id, que se basa en los datos de origen y la actualización del esquema siguiendo las mejores prácticas mencionadas. esta página.
Limpiar
- Eliminar todos los clústeres de Amazon Redshift
- Eliminar el clúster de Amazon MSK y el clúster de MSK Connect
- En caso de que no desee eliminar los clústeres de Amazon Redshift, puede eliminar manualmente el MV y las tablas creadas durante esta publicación utilizando los siguientes comandos:
Además, elimine las reglas de seguridad entrantes agregadas a sus clústeres de Amazon Redshift y Amazon MSK, junto con los roles de AWS IAM creados en la sección Requisitos previos.
Conclusión
En esta publicación, le mostramos cómo la ingesta de streaming de Amazon Redshift proporcionó una ingesta de datos de streaming de alto rendimiento y baja latencia desde Secuencias de datos de Amazon Kinesis y Amazon MSK en una vista materializada de Amazon Redshift. Aumentamos la velocidad y reducimos el costo de la transmisión de datos a Amazon Redshift al eliminar la necesidad de utilizar servicios intermediarios.
Además, también mostramos cómo los datos CDC se pueden procesar rápidamente después de la generación, utilizando una interfaz SQL simple que permite a los clientes realizar análisis casi en tiempo real en una variedad de fuentes de datos (por ejemplo, dispositivos de Internet de las cosas [IoT], sistemas de telemetría). datos o datos de secuencia de clics) de un sitio web o aplicación ocupado.
A medida que explora las opciones para simplificar y habilitar análisis casi en tiempo real para sus datos de CDC,
Esperamos que esta publicación le proporcione una valiosa orientación. Agradecemos cualquier idea o pregunta en la sección de comentarios.
Acerca de los autores
 Umesh Chaudhari es arquitecto de soluciones de streaming en AWS. Trabaja con clientes de AWS para diseñar y construir sistemas de procesamiento de datos en tiempo real. Tiene 13 años de experiencia laboral en ingeniería de software, incluida la arquitectura, el diseño y el desarrollo de sistemas de análisis de datos.
Umesh Chaudhari es arquitecto de soluciones de streaming en AWS. Trabaja con clientes de AWS para diseñar y construir sistemas de procesamiento de datos en tiempo real. Tiene 13 años de experiencia laboral en ingeniería de software, incluida la arquitectura, el diseño y el desarrollo de sistemas de análisis de datos.
 Vishal Khatri es gerente técnico senior de cuentas y especialista en análisis en AWS. Vishal trabaja con el gobierno estatal y local ayudando a educar y compartir las mejores prácticas con los clientes al liderar y ser propietario del desarrollo y entrega de contenido técnico mientras diseña soluciones integrales para el cliente.
Vishal Khatri es gerente técnico senior de cuentas y especialista en análisis en AWS. Vishal trabaja con el gobierno estatal y local ayudando a educar y compartir las mejores prácticas con los clientes al liderar y ser propietario del desarrollo y entrega de contenido técnico mientras diseña soluciones integrales para el cliente.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/break-data-silos-and-stream-your-cdc-data-with-amazon-redshift-streaming-and-amazon-msk/

