La segmentación, el proceso de identificar píxeles de imagen que pertenecen a objetos, es el núcleo de la visión artificial. Este proceso se utiliza en aplicaciones que van desde la creación de imágenes científicas hasta la edición de fotografías, y los expertos técnicos deben poseer habilidades altamente calificadas y acceso a la infraestructura de IA con grandes cantidades de datos anotados para un modelado preciso.
Meta AI presentó recientemente su Segmentar cualquier proyecto? que es un conjunto de datos de segmentación de imágenes y un modelo con Segment Anything Model (SAM) y el conjunto de datos de la máscara SA-1B?—? El conjunto de datos de segmentación más grande jamás realizado admite más investigaciones en modelos básicos para la visión por computadora. Hicieron que SA-1B esté disponible para uso de investigación, mientras que SAM tiene una licencia abierta de Apache 2.0 para que cualquiera pueda probar SAM con sus imágenes usando este manifestación!

Segmentar Cualquier cosa Modelo / Imagen por Meta IA
Antes, los problemas de segmentación se abordaban utilizando dos clases de enfoques:
- Segmentación interactiva en la que los usuarios guían la tarea de segmentación refinando iterativamente una máscara.
- La segmentación automática permitió segmentar automáticamente categorías de objetos selectivos como gatos o sillas, pero requirió una gran cantidad de objetos anotados para el entrenamiento (es decir, miles o incluso decenas de miles de ejemplos de gatos segmentados) junto con recursos informáticos y experiencia técnica para entrenar un modelo de segmentación. ninguno de los enfoques proporcionó una solución general y totalmente automática para la segmentación.
SAM utiliza segmentación interactiva y automática en un modelo. La interfaz propuesta permite un uso flexible, haciendo posible una amplia gama de tareas de segmentación mediante la ingeniería del indicador adecuado (como clics, cuadros o texto).
SAM se desarrolló utilizando un conjunto de datos expansivo y de alta calidad que contiene más de mil millones de máscaras recopiladas como parte de este proyecto, lo que le da la capacidad de generalizar a nuevos tipos de objetos e imágenes más allá de los observados durante el entrenamiento. Como resultado, los profesionales ya no necesitan recopilar sus datos de segmentación y adaptar un modelo específicamente a su caso de uso.
Estas capacidades permiten a SAM generalizar tareas y dominios, algo que ningún otro software de segmentación de imágenes ha hecho antes.
SAM viene con poderosas capacidades que hacen que la tarea de segmentación sea más efectiva:
- Variedad de indicaciones de entrada: Indica que la segmentación directa permite a los usuarios realizar fácilmente diferentes tareas de segmentación sin requisitos de capacitación adicionales. Puede aplicar la segmentación mediante puntos y cuadros interactivos, segmentar automáticamente todo en una imagen y generar varias máscaras válidas para indicaciones ambiguas. En la figura a continuación, podemos ver que la segmentación se realiza para ciertos objetos utilizando un indicador de texto de entrada.

Cuadro delimitador mediante mensaje de texto.
- Integración con otros sistemas: SAM puede aceptar indicaciones de entrada de otros sistemas, como en el futuro tomar la mirada del usuario desde un auricular AR/VR y seleccionar objetos.
- Salidas extensibles: Las máscaras de salida pueden servir como entradas para otros sistemas de IA. Por ejemplo, las máscaras de objetos se pueden rastrear en videos, habilitar aplicaciones de edición de imágenes, elevarse al espacio 3D o incluso usarse creativamente, como compaginar
- Generalización de tiro cero: SAM ha desarrollado una comprensión de los objetos que le permite adaptarse rápidamente a objetos desconocidos sin necesidad de formación adicional.
- Generación de múltiples máscaras: SAM puede producir múltiples máscaras válidas cuando se enfrenta a la incertidumbre con respecto a la segmentación de un objeto, lo que brinda una asistencia crucial al resolver la segmentación en entornos del mundo real.
- Generación de máscaras en tiempo real: SAM puede generar una máscara de segmentación para cualquier solicitud en tiempo real después de calcular previamente la incrustación de la imagen, lo que permite la interacción en tiempo real con el modelo.
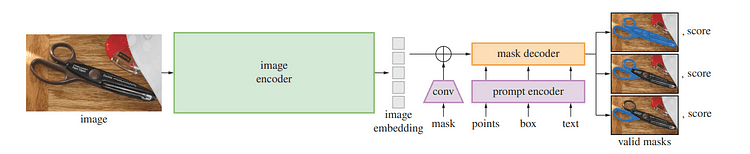
Descripción general del modelo SAM / Imagen por Segmentar cualquier cosa
Uno de los avances recientes en el procesamiento del lenguaje natural y la visión por computadora han sido los modelos básicos que permiten el aprendizaje de disparos cero y pocos disparos para nuevos conjuntos de datos y tareas a través de "indicaciones". Los investigadores de Meta AI entrenaron a SAM para devolver una máscara de segmentación válida para cualquier mensaje, como puntos de primer plano/fondo, cuadros/máscaras o máscaras aproximadas, texto de forma libre o cualquier información que indique el objeto de destino dentro de una imagen.
Una máscara válida simplemente significa que incluso cuando el mensaje puede referirse a múltiples objetos (por ejemplo: un punto en una camisa puede representar tanto a sí mismo como a alguien que lo usa), su salida debe proporcionar una máscara razonable para un solo objeto. -entrenamiento del modelo y resolución de tareas generales de segmentación downstream vía prompting.
Los investigadores observaron que las tareas de preentrenamiento y la recopilación interactiva de datos imponían restricciones específicas en el diseño del modelo. Lo más importante es que la simulación en tiempo real debe ejecutarse de manera eficiente en una CPU en un navegador web para permitir que los anotadores usen SAM de forma interactiva en tiempo real para una anotación eficiente. Aunque las limitaciones de tiempo de ejecución dieron lugar a compensaciones entre la calidad y las limitaciones de tiempo de ejecución, los diseños simples produjeron resultados satisfactorios en la práctica.
Debajo del capó de SAM, un codificador de imágenes genera una incrustación única para imágenes, mientras que un codificador liviano convierte cualquier solicitud en un vector de incrustación en tiempo real. Estas fuentes de información luego se combinan mediante un decodificador liviano que predice máscaras de segmentación basadas en incrustaciones de imágenes calculadas con SAM, por lo que SAM puede producir segmentos en solo 50 milisegundos para cualquier indicación dada en un navegador web.
Construir y entrenar el modelo requiere acceso a un conjunto enorme y diverso de datos que no existían al comienzo del entrenamiento. El lanzamiento del conjunto de datos de segmentación de hoy es, con mucho, el más grande hasta la fecha. Los anotadores utilizaron SAM para anotar imágenes de forma interactiva antes de actualizar SAM con estos nuevos datos, repitiendo este ciclo muchas veces para refinar continuamente tanto el modelo como el conjunto de datos.
SAM hace que la recopilación de máscaras de segmentación sea más rápida que nunca, con solo 14 segundos por máscara anotada de forma interactiva; ese proceso es solo dos veces más lento que anotar cuadros delimitadores que toman solo 7 segundos usando interfaces de anotación rápidas. Los esfuerzos comparables de recopilación de datos de segmentación a gran escala incluyen la anotación de máscara totalmente manual basada en polígonos de COCO, que demora aproximadamente 10 horas; Los esfuerzos de anotación asistida por el modelo SAM fueron aún más rápidos; ¡su tiempo de anotación por máscara anotada fue 6.5 veces más rápido frente a 2 veces más lento en términos de tiempo de anotación de datos que el modelo anterior asistido por esfuerzos de anotaciones de datos a gran escala!
La anotación interactiva de máscaras no es suficiente para generar el conjunto de datos SA-1B; así se desarrolló un motor de datos. Este motor de datos contiene tres "engranajes", comenzando con anotadores asistidos antes de pasar a la anotación totalmente automatizada combinada con la anotación asistida para aumentar la diversidad de máscaras recopiladas y, finalmente, la creación de máscaras completamente automática para escalar el conjunto de datos.
El conjunto de datos final de SA-1B presenta más de 1.1 millones de máscaras de segmentación recopiladas en más de 11 millones de imágenes con licencia y que preservan la privacidad, lo que representa 4 veces más máscaras que cualquier conjunto de datos de segmentación existente, según estudios de evaluación humana. Según lo verificado por estas evaluaciones humanas, estas máscaras exhiben alta calidad y diversidad en comparación con conjuntos de datos anteriores anotados manualmente con tamaños de muestra mucho más pequeños.
Las imágenes de SA-1B se obtuvieron a través de un proveedor de imágenes de varios países que representaban diferentes regiones geográficas y niveles de ingresos. Si bien ciertas regiones geográficas siguen estando subrepresentadas, SA-1B brinda una mayor representación debido a su mayor cantidad de imágenes y una mejor cobertura general en todas las regiones.
Los investigadores realizaron pruebas destinadas a descubrir cualquier sesgo en el modelo a través de la presentación de género, la percepción del tono de piel, el rango de edad de las personas y la edad percibida de las personas presentadas, y encontraron que el modelo SAM funcionó de manera similar en varios grupos. Esperan que esto haga que el trabajo resultante sea más equitativo cuando se aplique en casos de uso del mundo real.
Si bien SA-1B permitió el resultado de la investigación, también puede permitir que otros investigadores entrenen modelos básicos para la segmentación de imágenes. Además, estos datos pueden convertirse en la base para nuevos conjuntos de datos con anotaciones adicionales.
Los investigadores de Meta AI esperan que al compartir su investigación y conjunto de datos, puedan acelerar la investigación en la segmentación de imágenes y la comprensión de imágenes y videos. Dado que este modelo de segmentación puede realizar esta función como parte de sistemas más grandes.
En este artículo, cubrimos qué es SAM y su capacidad y casos de uso. Después de eso, analizamos cómo funciona y cómo se entrenó para brindar una descripción general del modelo. Finalmente, concluimos el artículo con la visión y el trabajo a futuro. Si desea saber más sobre SAM, asegúrese de leer el y prueba el manifestación.
Youssef Rafaat es un investigador de visión artificial y científico de datos. Su investigación se centra en el desarrollo de algoritmos de visión artificial en tiempo real para aplicaciones sanitarias. También trabajó como científico de datos durante más de 3 años en el dominio de marketing, finanzas y atención médica.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/07/segment-anything-model-foundation-model-image-segmentation.html?utm_source=rss&utm_medium=rss&utm_campaign=segment-anything-model-foundation-model-for-image-segmentation

