Hacia el final de 2022, AWS anunció la disponibilidad general de la ingesta de streaming en tiempo real a Desplazamiento al rojo de Amazon para Secuencias de datos de Amazon Kinesis y Amazon Managed Streaming para Apache Kafka (Amazon MSK), eliminando la necesidad de organizar la transmisión de datos en Servicio de almacenamiento simple de Amazon (Amazon S3) antes de ingerirlo en Amazon Redshift.
Transmisión de ingestión de Amazon MSK a Amazon Redshift, representa un enfoque de vanguardia para el procesamiento y análisis de datos en tiempo real. Amazon MSK actúa como un servicio altamente escalable y totalmente administrado para Apache Kafka, lo que permite la recopilación y el procesamiento fluidos de grandes flujos de datos. La integración de datos en streaming en Amazon Redshift aporta un valor inmenso al permitir a las organizaciones aprovechar el potencial del análisis en tiempo real y la toma de decisiones basada en datos.
Esta integración le permite lograr una latencia baja, medida en segundos, mientras ingiere cientos de megabytes de datos de transmisión por segundo en Amazon Redshift. Al mismo tiempo, esta integración ayuda a garantizar que la información más actualizada esté disponible para su análisis. Debido a que la integración no requiere datos provisionales en Amazon S3, Amazon Redshift puede ingerir datos de transmisión con una latencia más baja y sin costos de almacenamiento intermediario.
Puede configurar la ingesta de streaming de Amazon Redshift en un clúster de Redshift mediante declaraciones SQL para autenticarse y conectarse a un tema de MSK. Esta solución es una excelente opción para los ingenieros de datos que buscan simplificar las canalizaciones de datos y reducir el costo operativo.
En esta publicación, proporcionamos una descripción completa sobre cómo configurar Ingestión de streaming de Amazon Redshift de AmazonMSK.
Resumen de la solución
El siguiente diagrama de arquitectura describe los servicios y características de AWS que utilizará.

El flujo de trabajo incluye los siguientes pasos:
- Se comienza configurando un Conexión de Amazon MSK conector de origen, para crear un tema de MSK, generar datos simulados y escribirlos en el tema de MSK. Para esta publicación, trabajamos con datos de clientes simulados.
- El siguiente paso es conectarse a un clúster de Redshift utilizando el Editor de consultas v2.
- Finalmente, configura un esquema externo y crea una vista materializada en Amazon Redshift para consumir los datos del tema MSK. Esta solución no depende de un conector receptor de MSK Connect para exportar los datos de Amazon MSK a Amazon Redshift.
El siguiente diagrama de arquitectura de la solución describe con más detalle la configuración e integración de los servicios de AWS que utilizará.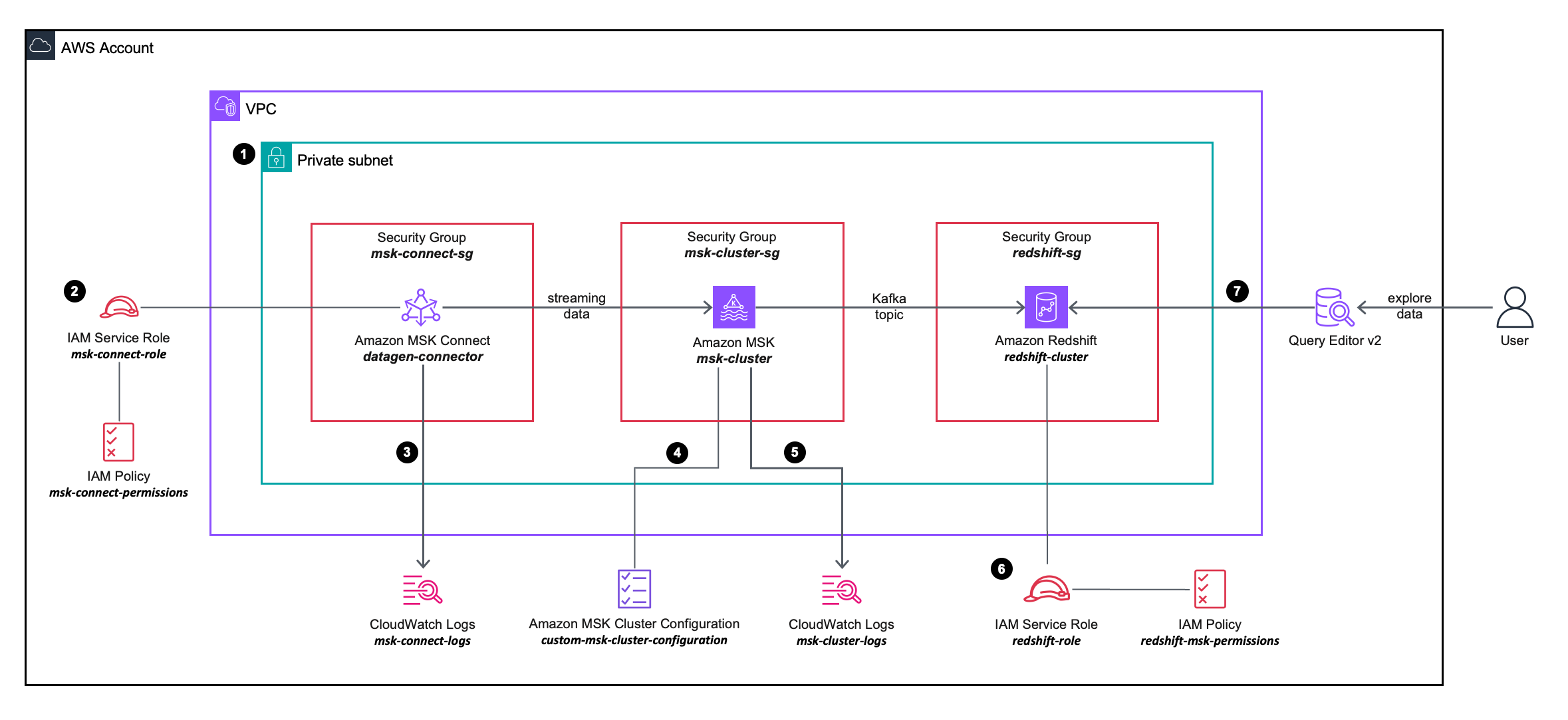
El flujo de trabajo incluye los siguientes pasos:
- Implementa un conector de origen de MSK Connect, un clúster de MSK y un clúster de Redshift dentro de las subredes privadas de una VPC.
- El conector de origen de MSK Connect utiliza permisos granulares definidos en un Administración de acceso e identidad de AWS (IAM) política en línea adjunto a un Rol de IAM, que permite que el conector de origen realice acciones en el clúster MSK.
- Los registros del conector de origen de MSK Connect se capturan y envían a un Reloj en la nube de Amazon grupo de registro.
- El clúster MSK utiliza un configuración personalizada del clúster MSK, lo que permite que el conector MSK Connect cree temas en el clúster de MSK.
- Los registros del clúster MSK se capturan y envían a un grupo de registros de Amazon CloudWatch.
- El clúster de Redshift utiliza permisos granulares definidos en una política en línea de IAM adjunta a una función de IAM, lo que permite que el clúster de Redshift realice acciones en el clúster de MSK.
- Puede utilizar el Editor de consultas v2 para conectarse al clúster de Redshift.
Requisitos previos
Para simplificar el aprovisionamiento y la configuración de los recursos de requisitos previos, puede utilizar lo siguiente Formación en la nube de AWS modelo:
![]()
Complete los siguientes pasos al iniciar la pila:
- Nombre de pila, ingrese un nombre significativo para la pila, por ejemplo,
prerequisites. - Elige Siguiente.
- Elige Siguiente.
- Seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM con nombres personalizados.
- Elige Enviar.
La pila de CloudFormation crea los siguientes recursos:
- una VPC
custom-vpc, creado en tres zonas de disponibilidad, con tres subredes públicas y tres subredes privadas:- Las subredes públicas están asociadas con una tabla de rutas pública y el tráfico saliente se dirige a una puerta de enlace de Internet.
- Las subredes privadas están asociadas con una tabla de rutas privada y el tráfico saliente se envía a una puerta de enlace NAT.
- An puerta de enlace de internet adjunto a la VPC de Amazon.
- A Puerta de enlace NAT que está asociado con un IP elástica y se implementa en una de las subredes públicas.
- Tres puestos grupos de seguridad:
msk-connect-sg, que luego se asociará con el conector MSK Connect.redshift-sg, que luego se asociará con el clúster Redshift.msk-cluster-sg, que luego se asociará con el clúster MSK. Permite el tráfico entrante desdemsk-connect-sgyredshift-sg.
- Dos grupos de registros de CloudWatch:
msk-connect-logs, que se utilizará para los registros de MSK Connect.msk-cluster-logs, que se utilizará para los registros del clúster MSK.
- Dos funciones de IAM:
msk-connect-role, que incluye permisos granulares de IAM para MSK Connect.redshift-role, que incluye permisos granulares de IAM para Amazon Redshift.
- A configuración personalizada del clúster MSK, lo que permite que el conector MSK Connect cree temas en el clúster de MSK.
- Un clúster MSK, con tres corredores implementados en las tres subredes privadas de
custom-vpc. Elmsk-cluster-sggrupo de seguridad y elcustom-msk-cluster-configurationLa configuración se aplica al clúster MSK. Los registros del corredor se entregan almsk-cluster-logsGrupo de registros de CloudWatch. - A Grupo de subred del clúster Redshift, que utiliza las tres subredes privadas de
custom-vpc. - Un clúster de Redshift, con un único nodo implementado en una subred privada dentro del grupo de subred del clúster de Redshift. El
redshift-sggrupo de seguridad yredshift-roleEl rol de IAM se aplica al clúster Redshift.
Cree un complemento personalizado de MSK Connect
Para esta publicación, usamos un Generador de datos de Amazon MSK implementado en MSK Connect, para generar datos de clientes simulados y escribirlos en un tema de MSK.
Complete los siguientes pasos:
- Descargue nuestra Generador de datos de Amazon MSK Archivo JAR con dependencias de GitHub.

- Cargue el archivo JAR en un depósito S3 en su cuenta de AWS.
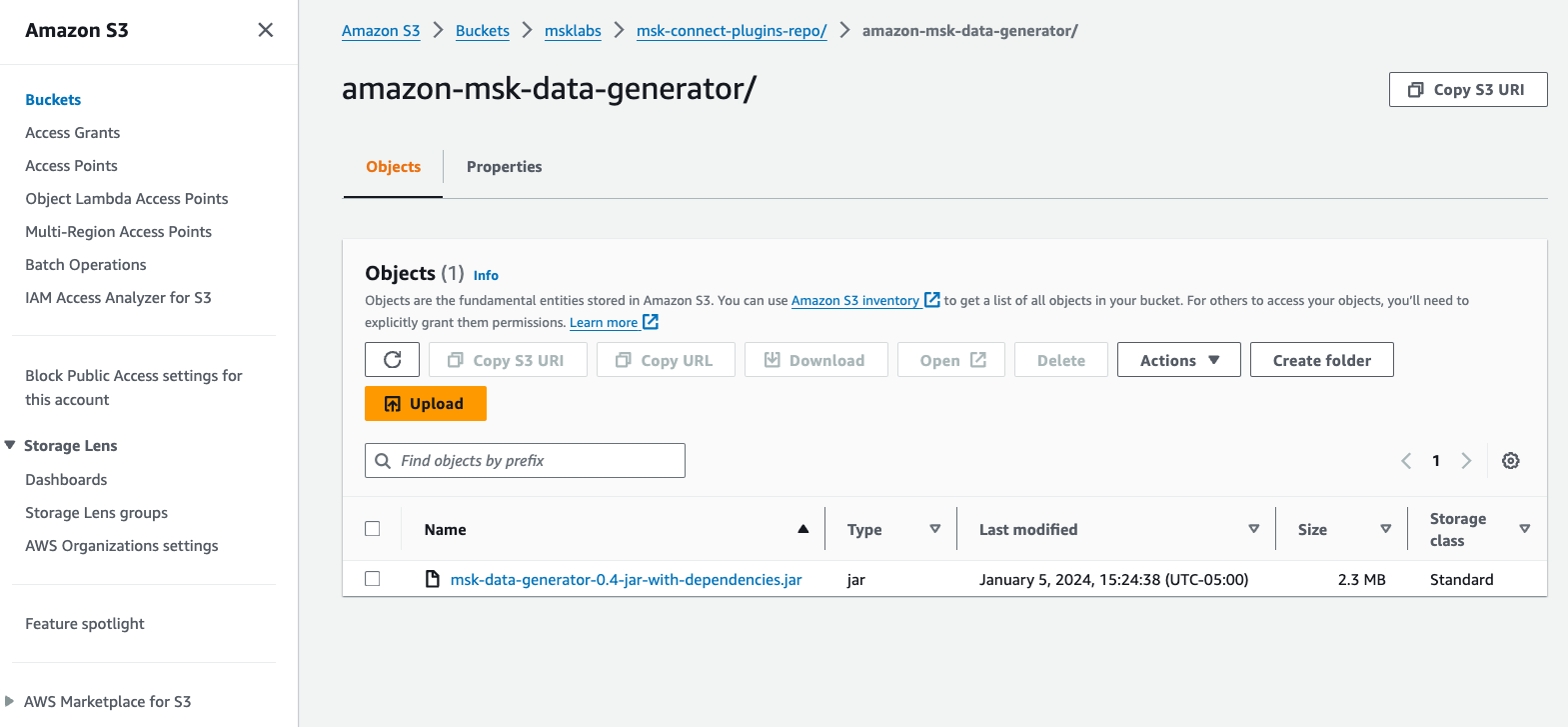
- En la consola de Amazon MSK, elija Complementos personalizados bajo Conexión MSK en el panel de navegación.
- Elige Crea un complemento personalizado.
- Elige Examinar S3, busque el archivo JAR del generador de datos de Amazon MSK que cargó en Amazon S3 y luego elija Elige.
- Nombre de complemento personalizado, introduzca
msk-datagen-plugin. - Elige Crea un complemento personalizado.
Cuando se crea el complemento personalizado, verá que su estado es Activey podrá pasar al siguiente paso.
Crear un conector MSK Connect
Complete los siguientes pasos para crear su conector:
- En la consola de Amazon MSK, elija Conectores bajo Conexión MSK en el panel de navegación.
- Elige Crear conector.
- Tipo de complemento personalizado, escoger Utilice el complemento existente.
- Seleccione
msk-datagen-plugin, A continuación, elija Siguiente. - Nombre del conector, introduzca
msk-datagen-connector. - Tipo de clúster, escoger Clúster Apache Kafka autogestionado.
- VPC, escoger
custom-vpc. - Subred 1, elija la subred privada dentro de su primera zona de disponibilidad.
Para el custom-vpc creado por la plantilla de CloudFormation, utilizamos rangos CIDR impares para las subredes públicas e rangos CIDR pares para las subredes privadas:
-
- Los CIDR para las subredes públicas son 10.10.1.0/24, 10.10.3.0/24 y 10.10.5.0/24.
- Los CIDR para las subredes privadas son 10.10.2.0/24, 10.10.4.0/24 y 10.10.6.0/24.
- Subred 2, seleccione la subred privada dentro de su segunda zona de disponibilidad.
- Subred 3, seleccione la subred privada dentro de su tercera zona de disponibilidad.
- Servidores de arranque, ingrese la lista de servidores de arranque para la autenticación TLS de su clúster MSK.
A recupere los servidores de arranque para su clúster MSK, navegue hasta la consola de Amazon MSK, elija Clusters, escoger msk-cluster, A continuación, elija Ver información del cliente. Copie los valores TLS para los servidores de arranque.
- Grupos de seguridad, escoger Utilice grupos de seguridad específicos con acceso a este clúster, y elige
msk-connect-sg. - Configuración del conector, reemplace la configuración predeterminada con la siguiente:
- Para Capacidad del conector, elija Aprovisionado.
- Recuento de MCU por trabajador, escoger 1.
- Numero de trabajadores, escoger 1.
- Configuración del trabajador, escoger Usar la configuración predeterminada de MSK.
- Permisos de acceso, escoger
msk-connect-role. - Elige Siguiente.
- Para cifrado, seleccione Tráfico cifrado TLS.
- Elige Siguiente.
- Entrega de registro, escoger Entregar a Amazon CloudWatch Logs.
- Elige Explorar, seleccione
msk-connect-logs, y elige Elige. - Elige Siguiente.
- Revisa y elige Crear conector.
Una vez creado el conector personalizado, verá que su estado es Correry podrá pasar al siguiente paso.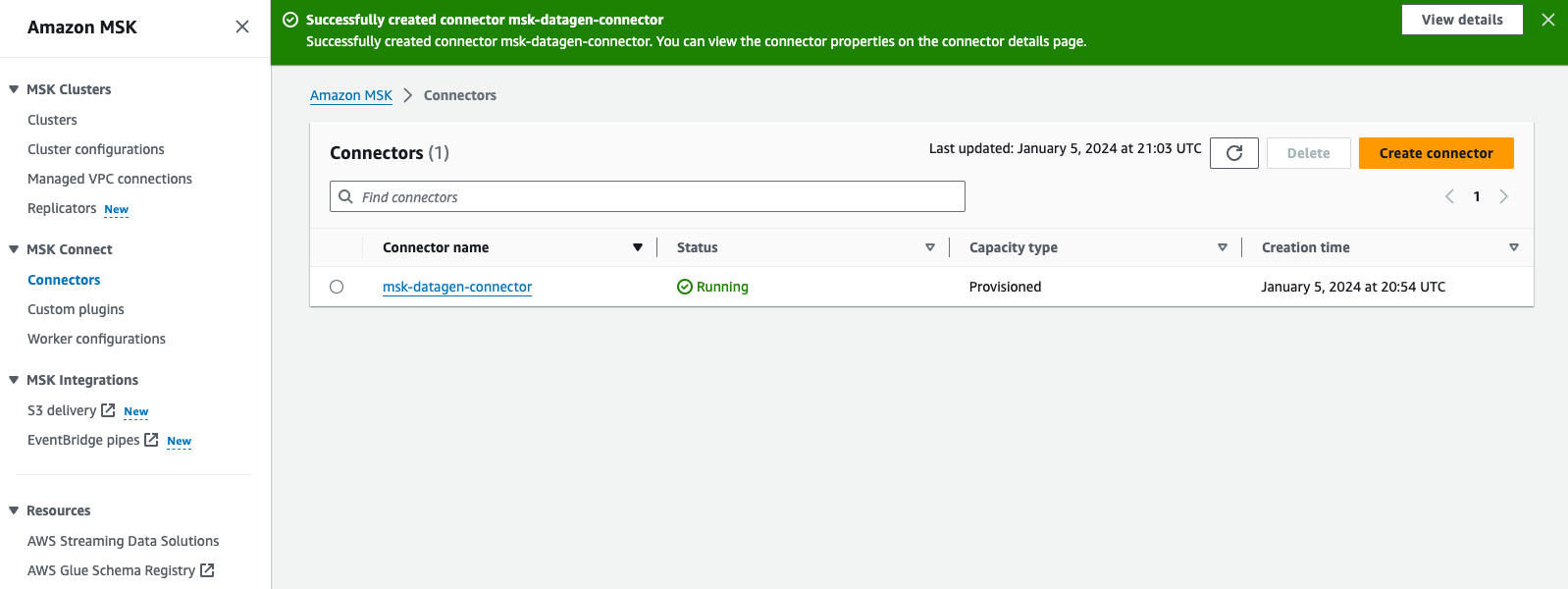
Configurar la ingesta de streaming de Amazon Redshift para Amazon MSK
Complete los siguientes pasos para configurar la ingesta de streaming:
- Conéctese a su clúster de Redshift usando Query Editor v2 y autentíquese con el nombre de usuario de la base de datos.
awsuser, y contraseñaAwsuser123. - Cree un esquema externo desde Amazon MSK utilizando la siguiente declaración SQL.
En el siguiente código, ingrese los valores para el redshift-role rol de IAM y el msk-cluster ARN del clúster.
- Elige Ejecutar para ejecutar la instrucción SQL.
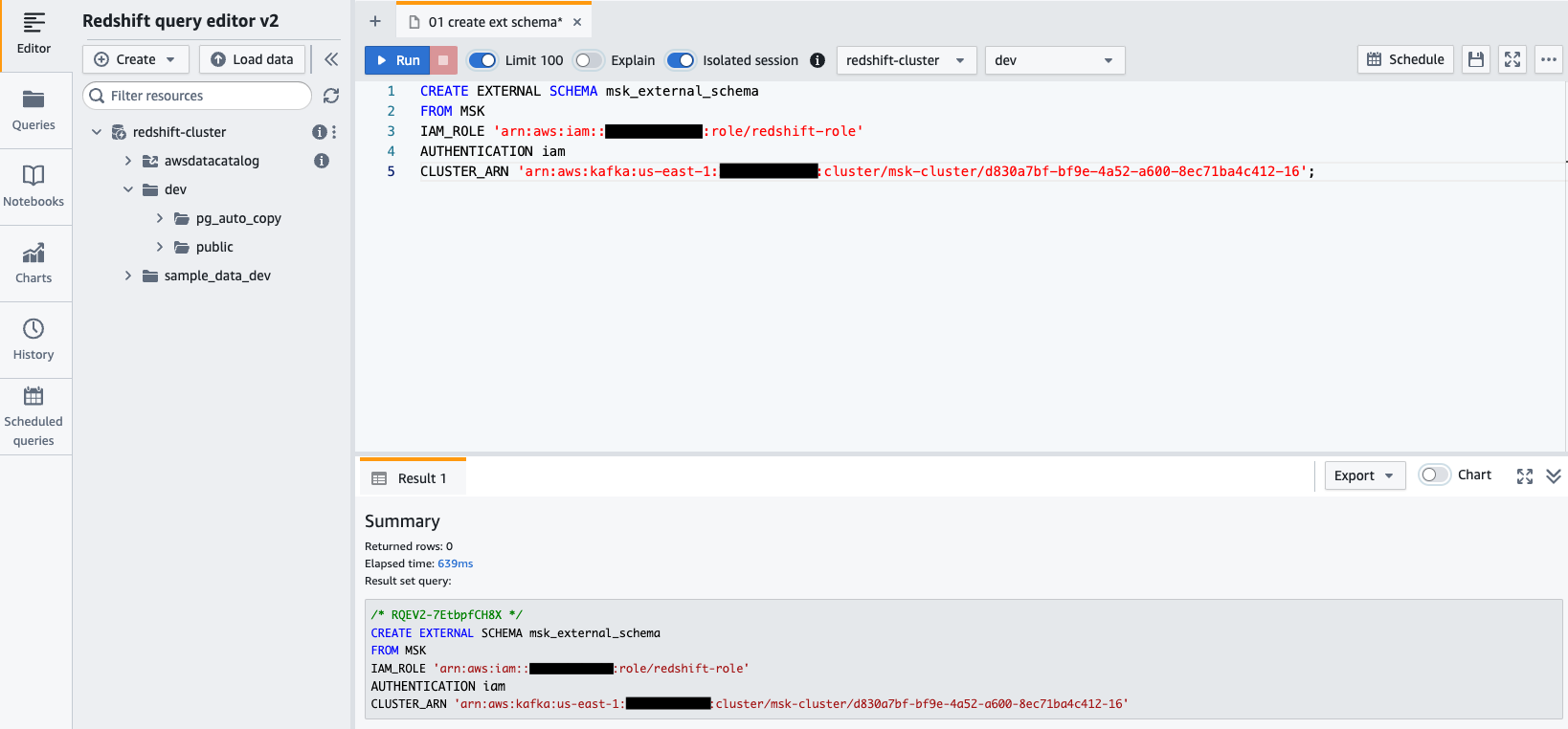
- Créar un vista materializada utilizando la siguiente declaración SQL:
- Elige Ejecutar para ejecutar la instrucción SQL.
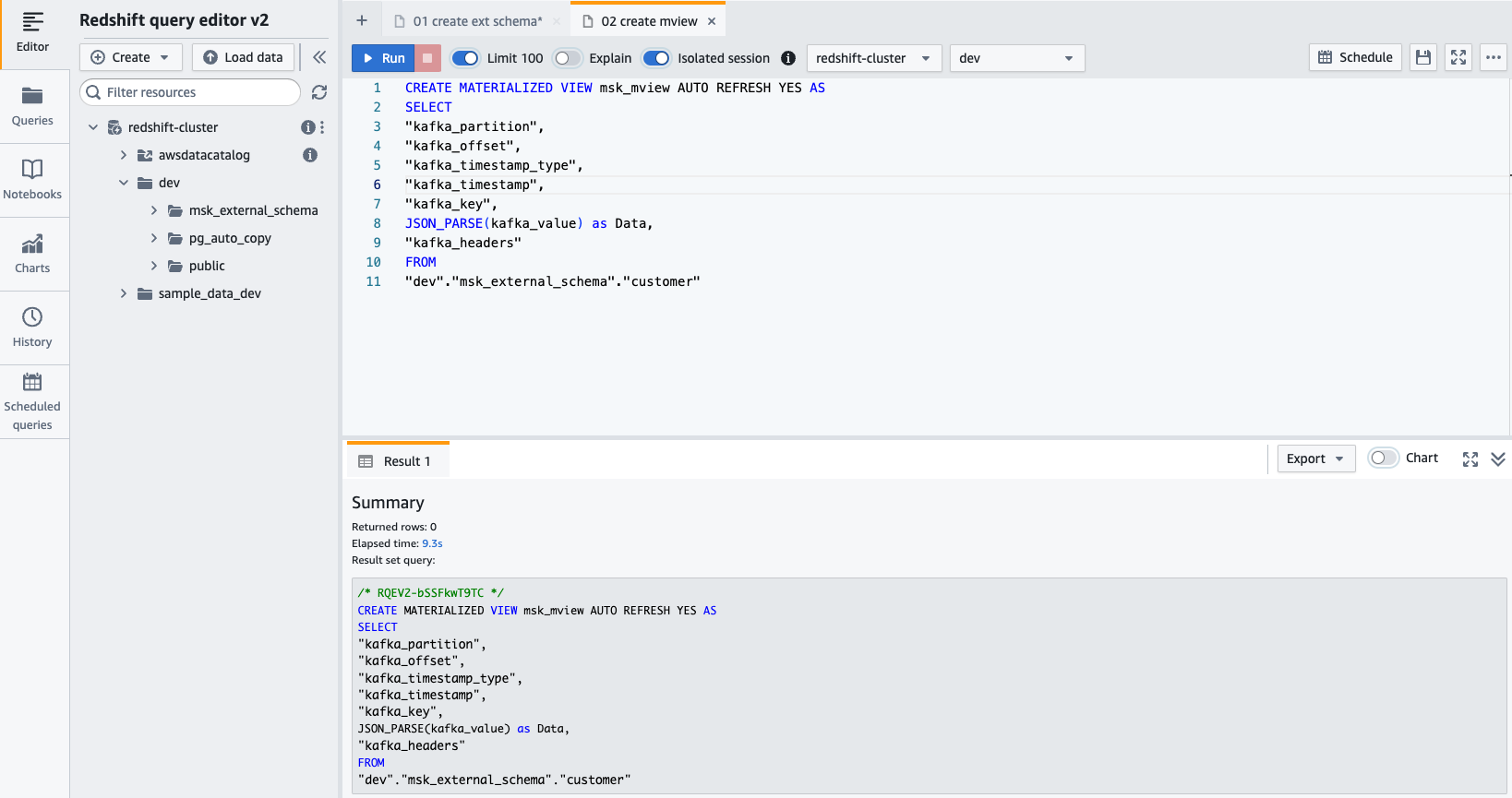
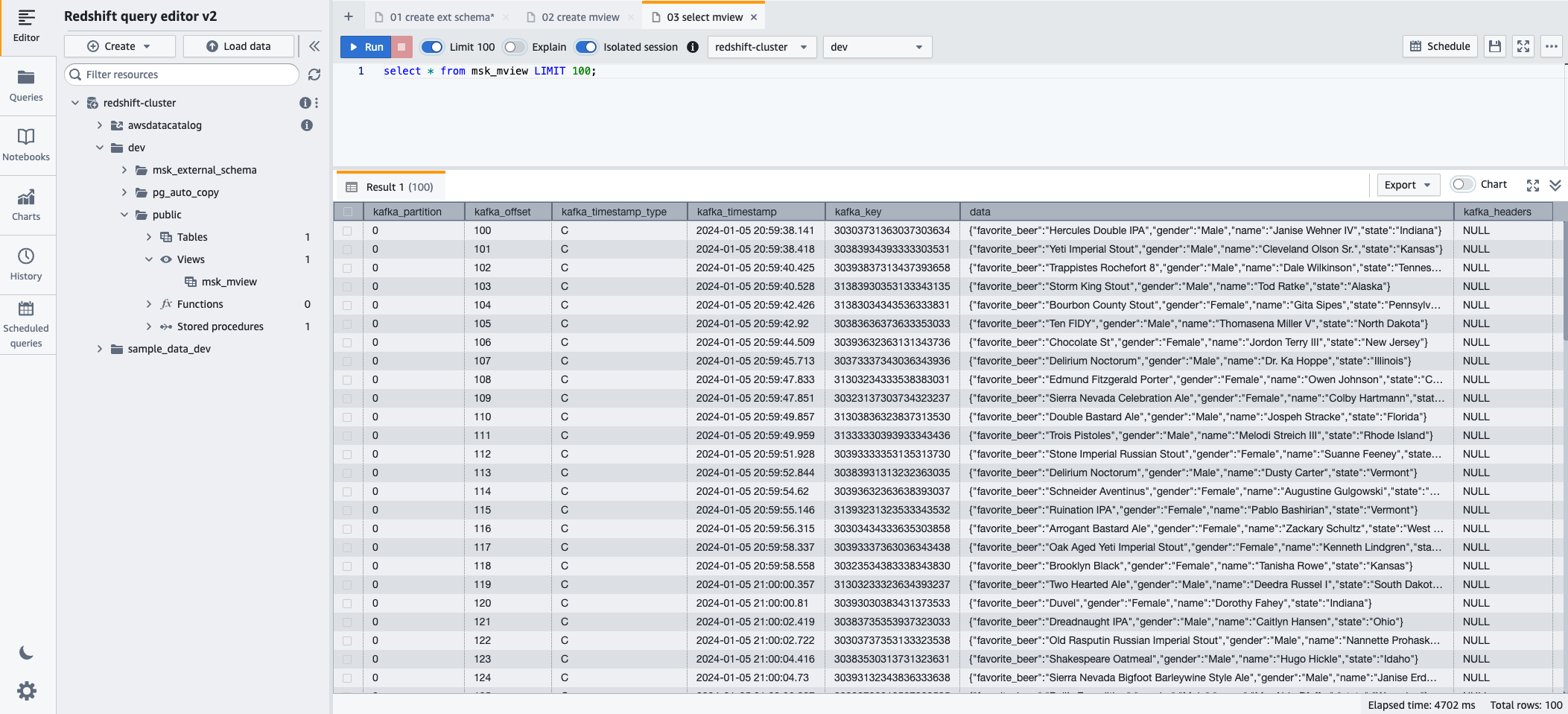
- Ahora puede consultar la vista materializada utilizando la siguiente declaración SQL:
- Elige Ejecutar para ejecutar la instrucción SQL.
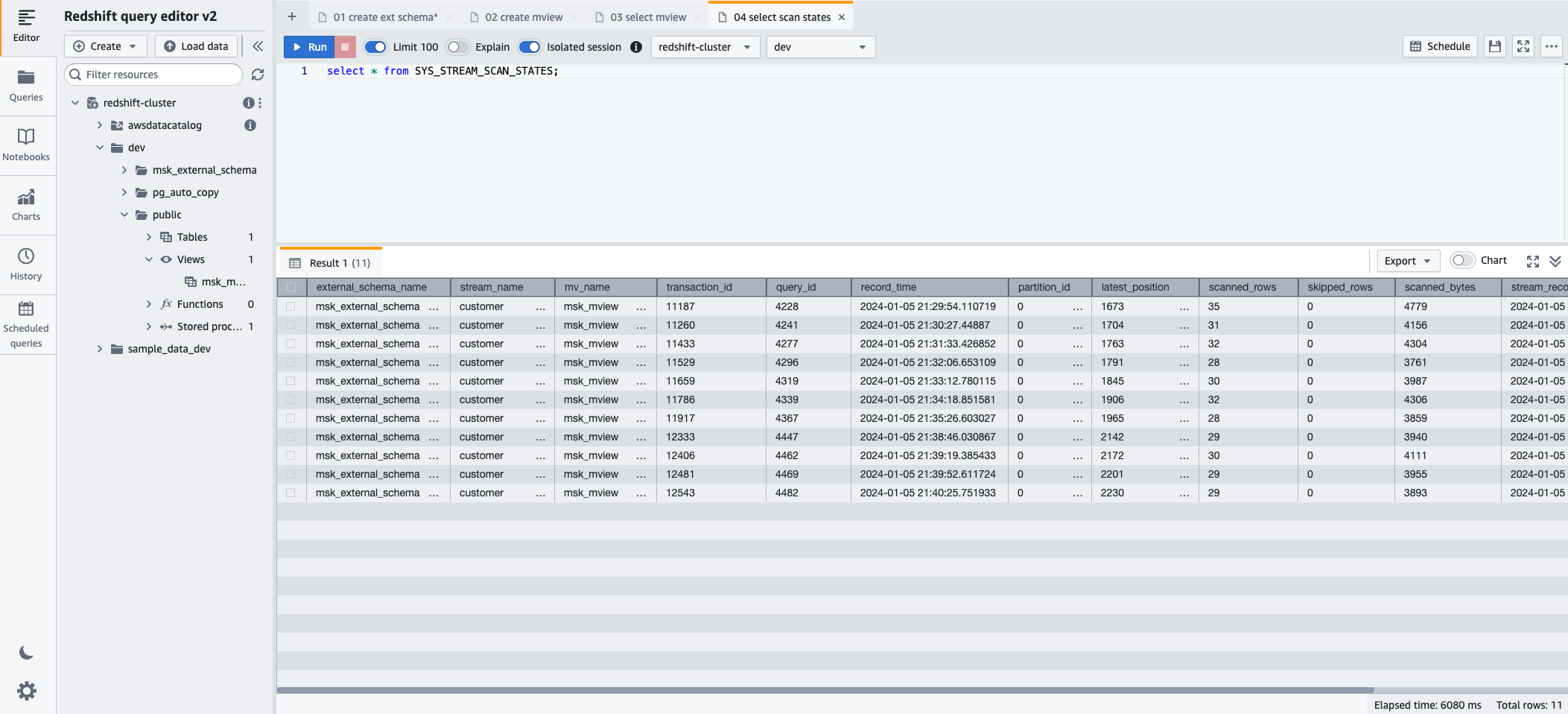
- Para monitorear el progreso de los registros cargados a través de la ingesta de streaming, puede aprovechar la SYS_STREAM_SCAN_STATES vista de monitoreo usando la siguiente declaración SQL:
- Elige Ejecutar para ejecutar la instrucción SQL.
- Para monitorear los errores encontrados en los registros cargados mediante la ingestión de transmisión, puede aprovechar la SYS_STREAM_SCAN_ERRORS vista de monitoreo usando la siguiente declaración SQL:
- Elige Ejecutar para ejecutar la instrucción SQL.
Limpiar
Después de seguir adelante, si ya no necesita los recursos que creó, elimínelos en el siguiente orden para evitar incurrir en cargos adicionales:
- Eliminar el conector MSK Connect
msk-datagen-connector. - Eliminar el complemento MSK Connect
msk-datagen-plugin. - Elimine el archivo JAR del generador de datos de Amazon MSK que descargó y elimine el depósito S3 que creó.
- Después de eliminar su conector MSK Connect, puede eliminar la plantilla de CloudFormation. Todos los recursos creados por la plantilla de CloudFormation se eliminarán automáticamente de su cuenta de AWS.
Conclusión
En esta publicación, demostramos cómo configurar la ingesta de streaming de Amazon Redshift desde Amazon MSK, centrándonos en la privacidad y la seguridad.
La combinación de la capacidad de Amazon MSK para manejar flujos de datos de alto rendimiento con las sólidas capacidades analíticas de Amazon Redshift permite a las empresas obtener información procesable rápidamente. Esta integración de datos en tiempo real mejora la agilidad y la capacidad de respuesta de las organizaciones para comprender las tendencias cambiantes de los datos, los comportamientos de los clientes y los patrones operativos. Permite tomar decisiones oportunas e informadas, obteniendo así una ventaja competitiva en el dinámico panorama empresarial actual.
Esta solución también es aplicable para clientes que desean utilizar Amazon MSK sin servidor y Amazon Redshift sin servidor.
Esperamos que esta publicación haya sido una buena oportunidad para aprender más sobre la integración y configuración de servicios de AWS. Háganos saber sus comentarios en la sección de comentarios.
Sobre los autores
 Sebastián Vlad es un arquitecto de soluciones socio senior de Amazon Web Services, apasionado por las soluciones de análisis y datos y el éxito del cliente. Sebastian trabaja con clientes empresariales para ayudarlos a diseñar y crear soluciones modernas, seguras y escalables para lograr sus resultados comerciales.
Sebastián Vlad es un arquitecto de soluciones socio senior de Amazon Web Services, apasionado por las soluciones de análisis y datos y el éxito del cliente. Sebastian trabaja con clientes empresariales para ayudarlos a diseñar y crear soluciones modernas, seguras y escalables para lograr sus resultados comerciales.
 Sharad Pai es consultor técnico líder en AWS. Se especializa en análisis de transmisión y ayuda a los clientes a crear soluciones escalables utilizando Amazon MSK y Amazon Kinesis. Tiene más de 16 años de experiencia en la industria y actualmente trabaja con clientes de medios que alojan plataformas de transmisión en vivo en AWS, gestionando una concurrencia máxima de más de 50 millones. Antes de unirse a AWS, la carrera de Sharad como desarrollador líder de software incluyó 9 años de codificación, trabajando con tecnologías de código abierto como JavaScript, Python y PHP.
Sharad Pai es consultor técnico líder en AWS. Se especializa en análisis de transmisión y ayuda a los clientes a crear soluciones escalables utilizando Amazon MSK y Amazon Kinesis. Tiene más de 16 años de experiencia en la industria y actualmente trabaja con clientes de medios que alojan plataformas de transmisión en vivo en AWS, gestionando una concurrencia máxima de más de 50 millones. Antes de unirse a AWS, la carrera de Sharad como desarrollador líder de software incluyó 9 años de codificación, trabajando con tecnologías de código abierto como JavaScript, Python y PHP.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/simplify-data-streaming-ingestion-for-analytics-using-amazon-msk-and-amazon-redshift/

