Amazon SageMaker es un servicio completamente administrado para flujos de trabajo de ciencia de datos y aprendizaje automático (ML). Ayuda a los científicos y desarrolladores de datos a preparar, construir, entrenar e implementar modelos ML de alta calidad rápidamente al reunir un amplio conjunto de capacidades especialmente diseñadas para ML.
En 2021, AWS anunció la integración de Servidor de inferencia NVIDIA Triton en SageMaker. Puede usar NVIDIA Triton Inference Server para servir modelos para inferencia en SageMaker. Al usar una imagen de contenedor de NVIDIA Triton, puede servir fácilmente modelos de ML y beneficiarse de las optimizaciones de rendimiento, el procesamiento por lotes dinámico y la compatibilidad con varios marcos que proporciona NVIDIA Triton. Triton ayuda a maximizar la utilización de GPU y CPU, lo que reduce aún más el costo de la inferencia.
En algunos escenarios, los usuarios desean implementar varios modelos. Por ejemplo, una aplicación para revisar la composición en inglés siempre incluye varios modelos, como BERT para la clasificación de textos y GECToR para la revisión gramatical. Una solicitud típica puede fluir a través de múltiples modelos, como preprocesamiento de datos, BERT, GECToR y posprocesamiento, y se ejecutan en serie como canalizaciones de inferencia. Si estos modelos se alojan en diferentes instancias, la latencia de red adicional entre estas instancias aumenta la latencia general. Para una aplicación con tráfico incierto, la implementación de múltiples modelos en diferentes instancias conducirá inevitablemente a una utilización ineficiente de los recursos.
Considere otro escenario, en el que los usuarios desarrollan varios modelos con diferentes versiones, y cada modelo usa un marco de entrenamiento diferente. Una práctica común es usar varios contenedores, cada uno de los cuales implementa un modelo. Pero esto aumentará la carga de trabajo y los costos de desarrollo, operación y mantenimiento. En esta publicación, analizamos cómo SageMaker y NVIDIA Triton Inference Server pueden resolver este problema.
Resumen de la solución
Veamos cómo funciona la inferencia de SageMaker. SageMaker invoca el servicio de hospedaje ejecutando un contenedor Docker. El contenedor Docker lanza un servidor de inferencia RESTful (como Flask) para servir solicitudes HTTP para inferencia. El servidor de inferencia carga el modelo y escucha el puerto 8080 proporcionando un servicio externo. La aplicación cliente envía una solicitud POST al extremo de SageMaker, SageMaker pasa la solicitud al contenedor y devuelve el resultado de la inferencia del contenedor al cliente.
En nuestra arquitectura, usamos NVIDIA Triton Inference Server, que proporciona ejecuciones simultáneas de varios modelos de diferentes marcos, y usamos un servidor Flask para procesar solicitudes del lado del cliente y enviar estas solicitudes al servidor Triton backend. Al iniciar un contenedor Docker, el servidor Triton y el servidor Flask se inician automáticamente. El servidor Triton carga varios modelos y expone los puertos 8000, 8001 y 8002 como servidor gRPC, HTTP y de métricas. El servidor Flask escucha los puertos 8080 y analiza la solicitud original y la carga útil, y luego invoca el backend local de Triton a través del nombre del modelo y la información de la versión. Para el lado del cliente, agrega el nombre del modelo y la versión del modelo en la solicitud además de la carga útil original, de modo que Flask pueda enrutar la solicitud de inferencia al modelo correcto en el servidor Triton.
El siguiente diagrama ilustra este proceso.
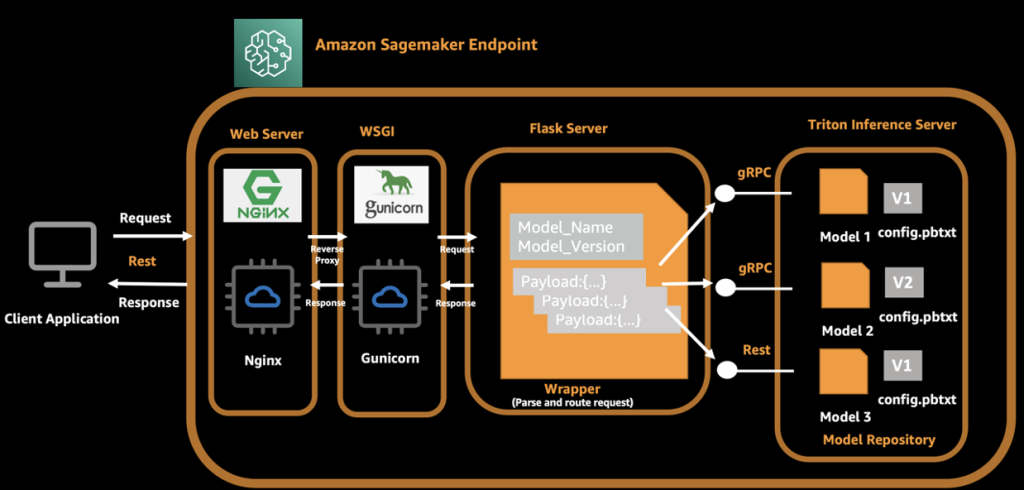
Una llamada API completa del cliente es la siguiente:
- El cliente ensambla la solicitud e inicia la solicitud a un extremo de SageMaker.
- El servidor Flask recibe y analiza la solicitud y obtiene el nombre del modelo, la versión y la carga útil.
- El servidor Flask vuelve a ensamblar la solicitud y la enruta al punto final correspondiente del servidor Triton según el nombre del modelo y la versión.
- El servidor Triton ejecuta una solicitud de inferencia y envía respuestas al servidor Flask.
- El servidor Flask recibe el mensaje de respuesta, ensambla el mensaje nuevamente y lo devuelve al cliente.
- El cliente recibe y analiza la respuesta y continúa con los procedimientos comerciales posteriores.
En las siguientes secciones, presentamos los pasos necesarios para preparar un modelo y construir el motor TensorRT, preparar una imagen de Docker, crear un extremo de SageMaker y verificar el resultado.
Prepara modelos y construye el motor.
Demostramos el alojamiento de tres modelos típicos de ML en nuestra solución: clasificación de imágenes (ResNet50), detección de objetos (YOLOv5) y un modelo de procesamiento de lenguaje natural (NLP) (base BERT). NVIDIA Triton Inference Server admite varios formatos, incluidos TensorFlow 1. x y 2. x, TensorFlow SavedModel, TensorFlow GraphDef, TensorRT, ONNX, OpenVINO y PyTorch TorchScript.
La siguiente tabla resume los detalles de nuestro modelo.
| Nombre de Modelo | Tamaño modelo | Formato |
| ResNet50 | 52 m | Tensor RT |
| YOLOv5 | 38 m | Tensor RT |
| base BERT | 133 m | ONNX-RT |
NVIDIA proporciona información detallada documentación describiendo cómo generar el motor TensorRT. Para lograr el mejor rendimiento, el motor TensorRT debe construirse sobre el dispositivo. Esto significa que el tiempo de compilación y el tiempo de ejecución requieren la misma capacidad informática. Por ejemplo, un motor TensorRT creado en una instancia g4dn no se puede implementar en una instancia g5.
Puedes generar tus propios motores TensorRT según tus necesidades. Para fines de prueba, preparamos códigos de muestra y modelos desplegables con el motor TensorRT. El código fuente también está disponible en GitHub.
A continuación, usamos un Nube informática elástica de Amazon (Amazon EC2) Instancia G4dn para generar el motor TensorRT con los siguientes pasos. Usamos YOLOv5 como ejemplo.
- Inicie una instancia EC4 G2dn.2xlarge con Deep Learning AMI (Ubuntu 20.04) en el
us-east-1Región. - Abra una ventana de terminal y use el
sshcomando para conectarse a la instancia. - Ejecute los siguientes comandos uno por uno:
- Créar un
config.pbtxtarchivo: - Cree la siguiente estructura de archivos y coloque los archivos generados en la ubicación adecuada:
Probar el motor TensorRT
Antes de implementar SageMaker, iniciamos un servidor Triton para verificar que estos tres modelos estén configurados correctamente. Utilice el siguiente comando para iniciar un servidor Triton y cargar los modelos:
Si recibe el siguiente mensaje de aviso, significa que el servidor Triton se inició correctamente.

Participar nvidia-smi en la terminal para ver el uso de la memoria GPU.

Implementación de cliente para inferencia
La estructura del archivo es la siguiente:
- ayudar – El contenedor que inicia el servidor de inferencia. El script de Python inicia el servidor NGINX, Flask y Triton.
- predictor.py – La implementación Flask para
/pingy/invocationspuntos finales y solicitudes de despacho. - wsgi.py – El shell de inicio para los trabajadores del servidor individuales.
- base.py – La definición del método abstracto que requiere cada cliente para implementar su método de inferencia.
- carpeta del cliente – Una carpeta por cliente:
resnetbert_baseyolov5
- nginx.conf – La configuración para el servidor primario NGINX.

Definimos un método abstracto para implementar la interfaz de inferencia, y cada cliente implementa este método:
El servidor Triton expone un extremo HTTP en el puerto 8000, un extremo gRPC en el puerto 8001 y un extremo de métricas de Prometheus en el puerto 8002. El siguiente es un ejemplo de cliente ResNet con una llamada gRPC. Puede implementar la interfaz HTTP o la interfaz gRPC según su caso de uso.
En esta arquitectura, los servidores NGINX, Flask y Triton deben iniciarse desde el principio. Editar el ayudar archivo y agregue una línea para iniciar el servidor Triton.
Cree una imagen de Docker y envíe la imagen a Amazon ECR
El código del archivo Docker tiene el siguiente aspecto:
La siguiente tabla muestra el costo de compartir un punto final para tres modelos que utilizan la arquitectura anterior. El costo total es de aproximadamente $676.8/mes. A partir de este resultado, podemos concluir que puede ahorrar un 30 % en costos y al mismo tiempo tener un servicio 24/7 desde su terminal.
| Nombre de Modelo | Punto final en ejecución/día | Tipo de instancia | Costo/mes (us-east-1) |
| ResNet, YOLOv5, BERT | 24 horas | ml.g4dn.2xgrande | 0.94 * 24 * 30 = 676.8 dólares |
Resumen
En esta publicación, presentamos una arquitectura mejorada en la que varios modelos comparten un punto final en SageMaker. Bajo algunas condiciones, esta solución puede ayudarlo a ahorrar costos y mejorar la utilización de recursos. Es adecuado para escenarios empresariales con baja simultaneidad y requisitos insensibles a la latencia.
Para obtener más información sobre SageMaker y las soluciones AI/ML, consulte Amazon SageMaker.
Referencias
Sobre los autores
 Zheng Zhang es un arquitecto de soluciones especializado sénior en AWS, se enfoca en ayudar a los clientes a acelerar el entrenamiento, la inferencia y la implementación de modelos para soluciones de aprendizaje automático. También tiene una rica experiencia en capacitación distribuida a gran escala, diseño de soluciones AI/ML.
Zheng Zhang es un arquitecto de soluciones especializado sénior en AWS, se enfoca en ayudar a los clientes a acelerar el entrenamiento, la inferencia y la implementación de modelos para soluciones de aprendizaje automático. También tiene una rica experiencia en capacitación distribuida a gran escala, diseño de soluciones AI/ML.
 Yinuo él es especialista en AI/ML en AWS. Tiene experiencia en el diseño y desarrollo de productos basados en aprendizaje automático para brindar mejores experiencias de usuario. Ahora trabaja para ayudar a los clientes a tener éxito en su proceso de aprendizaje automático.
Yinuo él es especialista en AI/ML en AWS. Tiene experiencia en el diseño y desarrollo de productos basados en aprendizaje automático para brindar mejores experiencias de usuario. Ahora trabaja para ayudar a los clientes a tener éxito en su proceso de aprendizaje automático.
- Coinsmart. El mejor intercambio de Bitcoin y criptografía de Europa.Haga clic aquí
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/serve-multiple-models-with-amazon-sagemaker-and-triton-inference-server/

