El tamaño y la complejidad de los modelos de lenguaje grande (LLM) se han disparado en los últimos años. Los LLM han demostrado capacidades notables para aprender la semántica del lenguaje natural y producir respuestas similares a las humanas. Muchos LLM recientes se perfeccionan con una poderosa técnica llamada sintonización de instrucciones, que ayuda al modelo a realizar nuevas tareas o generar respuestas a nuevas indicaciones sin un ajuste fino específico de la indicación. Un modelo ajustado a la instrucción utiliza su comprensión de tareas o conceptos relacionados para generar predicciones para indicaciones novedosas. Debido a que esta técnica no implica la actualización de los pesos del modelo, evita el proceso laborioso y computacionalmente costoso necesario para ajustar un modelo para una tarea nueva que no se había visto anteriormente.
En esta publicación, mostramos cómo puede acceder e implementar un modelo Flan T5 ajustado por instrucciones desde Inicio rápido de Amazon SageMaker. También demostramos cómo puede diseñar indicaciones para que los modelos Flan-T5 realicen varias tareas de procesamiento de lenguaje natural (NLP). Además, estas tareas se pueden realizar con aprendizaje de disparo cero, donde un mensaje bien diseñado puede guiar al modelo hacia los resultados deseados. Por ejemplo, considere proporcionar una pregunta de opción múltiple y pedirle al modelo que devuelva la respuesta adecuada de las opciones disponibles. Cubrimos avisos para las siguientes tareas de PNL:
- Resumen de texto
- Razonamiento de sentido común
- Respuesta a la pregunta
- Clasificación de sentimiento
- Traducción
- resolución de pronombre
- Generación de texto basado en artículo
- Artículo imaginario basado en el título
El código para todos los pasos de esta demostración está disponible en el siguiente cuaderno.
JumpStart es el centro de aprendizaje automático (ML) de Amazon SageMaker que ofrece acceso con un solo clic a más de 350 algoritmos integrados; modelos preentrenados de TensorFlow, PyTorch, Hugging Face y MXNet; y plantillas de solución preconstruidas. JumpStart también proporciona modelos de cimientos como la IA de estabilidad Difusión estable modelo de texto a imagen, BLOOM, de Cohere Generar, AlexaTM de Amazon y más.
Ajuste de instrucciones
El ajuste de instrucciones es una técnica que implica el ajuste fino de un modelo de lenguaje en una colección de tareas de PNL usando instrucciones. En esta técnica, el modelo se entrena para realizar tareas siguiendo instrucciones textuales en lugar de conjuntos de datos específicos para cada tarea. El modelo se ajusta con un conjunto de ejemplos de entrada y salida para cada tarea, lo que permite generalizar el modelo a nuevas tareas en las que no se ha capacitado explícitamente, siempre que se proporcionen indicaciones para las tareas. El ajuste de instrucciones ayuda a mejorar la precisión y la eficacia de los modelos y es útil en situaciones en las que no hay grandes conjuntos de datos disponibles para tareas específicas.
Desde 2020 se ha realizado una gran cantidad de investigaciones sobre el ajuste de instrucciones, lo que ha producido una colección de diversas tareas, plantillas y métodos. Uno de los métodos de sintonización de instrucciones más destacados, Ajuste fino de los modelos de lenguaje (Flan), agrega estas colecciones disponibles públicamente en una Flan Collection para producir modelos ajustados en una amplia variedad de instrucciones. De esta manera, los modelos Flan multitarea son competitivos con los mismos modelos ajustados independientemente en cada tarea específica y pueden generalizar más allá de las instrucciones específicas vistas durante el entrenamiento para seguir las instrucciones en general.
Aprendizaje zero-shot
Aprendizaje zero-shot en NLP permite que un LLM pre-entrenado genere respuestas a tareas para las que no ha sido entrenado específicamente. En esta técnica, el modelo recibe un texto de entrada y un indicador que describe el resultado esperado del modelo en lenguaje natural. Los modelos preentrenados pueden usar su conocimiento para generar respuestas coherentes y relevantes incluso para indicaciones en las que no han sido entrenados específicamente. El aprendizaje de disparo cero puede reducir el tiempo y los datos necesarios al tiempo que mejora la eficiencia y la precisión de las tareas de PNL. El aprendizaje de disparo cero se utiliza en una variedad de tareas de PNL, como la respuesta a preguntas, el resumen y la generación de texto.
Aprendizaje de pocas oportunidades Implica entrenar a un modelo para realizar nuevas tareas proporcionando solo algunos ejemplos. Esto es útil cuando se dispone de datos etiquetados limitados para el entrenamiento. Aunque esta publicación se enfoca principalmente en el aprendizaje de disparo cero, los modelos a los que se hace referencia también son capaces de generar respuestas a las indicaciones de aprendizaje de disparo corto.
Flan-T5 modelo
Un popular modelo codificador-decodificador conocido como T5 (Transformador de transferencia de texto a texto) es uno de esos modelos que posteriormente se perfeccionó a través del método Flan para producir el Flan-T5 familia de modelos. Flan-T5 es un modelo ajustado a las instrucciones y, por lo tanto, es capaz de realizar varias tareas de NLP de cero intentos, así como tareas de aprendizaje en contexto de pocos intentos. Con las indicaciones apropiadas, puede realizar tareas de NLP de tiro cero, como resúmenes de texto, razonamiento de sentido común, inferencia de lenguaje natural, respuesta a preguntas, clasificación de oraciones y sentimientos, traducción y resolución de pronombres. Los ejemplos proporcionados en esta publicación se generan con la familia Flan-T5.
JumpStart proporciona una implementación conveniente de esta familia de modelos a través de Estudio Amazon SageMaker y el SDK de SageMaker. Esto incluye Flan-T5 Small, Flan-T5 Base, Flan-T5 Large, Flan-T5 XL y Flan-T5 XXL. Además, JumpStart proporciona tres versiones de Flan-T5 XXL en diferentes niveles de cuantificación:
- Flan-T5 XXL – El modelo completo, cargado en formato de punto flotante de precisión simple (FP32).
- Flan-T5 XXL FP16 – Una versión en formato de coma flotante de precisión media (FP16) del modelo completo. Esta implementación consume menos memoria GPU y realiza una inferencia más rápida que la versión FP32.
- Flan-T5 XXL BNB INT8 – Una versión cuantificada de 8 bits del modelo completo, cargada en el contexto de la GPU usando el
accelerateybitsandbytesbibliotecas Esta implementación brinda accesibilidad a este LLM en instancias con menos cómputo, como una instancia ml.g5.xlarge de GPU única.
Ingeniería rápida para tareas de NLP de disparo cero en modelos Flan-T5
Ingeniería rápida se ocupa de crear indicaciones de alta calidad para guiar al modelo hacia las respuestas deseadas. Los avisos deben diseñarse en función de la tarea específica y el conjunto de datos que se utiliza. El objetivo aquí es proporcionar al modelo la información necesaria para generar respuestas de alta calidad y minimizar el ruido. Esto podría incluir palabras clave, contextos adicionales, preguntas y más. Por ejemplo, vea el siguiente código:
Un indicador bien diseñado puede hacer que el modelo sea más creativo y generalizado para que pueda adaptarse fácilmente a nuevas tareas. Las indicaciones también pueden ayudar a incorporar el conocimiento del dominio en tareas específicas y mejorar la interpretabilidad. La ingeniería rápida puede mejorar en gran medida el rendimiento de los modelos de aprendizaje de cero disparos y pocos disparos. La creación de indicaciones de alta calidad requiere una consideración cuidadosa de la tarea en cuestión, así como una comprensión profunda de las fortalezas y limitaciones del modelo.
En lo provisto cuaderno de ejemplo, cada tarea muestra al menos siete plantillas de solicitud y un conjunto completo de parámetros para controlar la salida del modelo, como la longitud máxima de la secuencia, la cantidad de secuencias de retorno y la cantidad de haces. Además, las plantillas de solicitud utilizadas son de la Repositorio Flan T5 GitHub, que consta de muchas plantillas utilizadas en Flan Collection. Esta colección de plantillas es útil para explorar cuando realiza su propia ingeniería rápida.
En la siguiente tabla, el modelo Flan-T5 XXL se usa para generar respuestas para varias tareas de NLP de disparo cero. La primera columna muestra la tarea, la segunda columna contiene el mensaje proporcionado al modelo (donde el texto de la plantilla está en negrita y el texto sin negrita es la entrada de ejemplo), y la tercera columna es la respuesta del modelo cuando se le consulta con el inmediato.
Tome la tarea de resumen como ejemplo: para crear un indicador de modelo, puede concatenar la plantilla Briefly summarize this paragraph: con el ejemplo de texto que desea resumir. Todas las tareas de esta tabla utilizaron los mismos parámetros de carga útil: max_length=150 para proporcionar un límite superior en el número de tokens de respuesta, no_repeat_ngram_size=5 para desalentar la repetición de n-gramas, y do_sample=False para deshabilitar el muestreo por repetibilidad. Analizamos las opciones de parámetros de carga útil disponibles al consultar el punto final con más detalle más adelante.
| Tarea | Solicitud (plantilla en negrita) | Salida del modelo |
| Resumen | Resume brevemente este párrafo: Amazon Comprehend utiliza procesamiento de lenguaje natural (NLP) para extraer información sobre el contenido de los documentos. Desarrolla conocimientos mediante el reconocimiento de entidades, frases clave, idioma, sentimientos y otros elementos comunes en un documento. Utilice Amazon Comprehend para crear nuevos productos basados en la comprensión de la estructura de los documentos. Por ejemplo, con Amazon Comprehend puede buscar en las fuentes de las redes sociales menciones de productos o escanear un repositorio de documentos completo en busca de frases clave. Puede acceder a las capacidades de análisis de documentos de Amazon Comprehend mediante la consola de Amazon Comprehend o mediante las API de Amazon Comprehend. Puede ejecutar análisis en tiempo real para cargas de trabajo pequeñas o puede iniciar trabajos de análisis asíncronos para grandes conjuntos de documentos. Puede utilizar los modelos previamente entrenados que proporciona Amazon Comprehend, o puede entrenar sus propios modelos personalizados para la clasificación y el reconocimiento de entidades. Todas las características de Amazon Comprehend aceptan documentos de texto UTF-8 como entrada. Además, la clasificación personalizada y el reconocimiento de entidades personalizadas aceptan archivos de imagen, archivos PDF y archivos de Word como entrada. Amazon Comprehend puede examinar y analizar documentos en una variedad de idiomas, según la característica específica. Para obtener más información, consulte Idiomas admitidos en Amazon Comprehend. La capacidad de idioma dominante de Amazon Comprehend puede examinar documentos y determinar el idioma dominante para una selección mucho más amplia de idiomas. |
Comprender las capacidades de Amazon Comprehend |
| Razonamiento de sentido común o razonamiento de lenguaje natural | La copa del mundo ha comenzado en Los Ángeles, Estados Unidos.nnBasándonos en el párrafo anterior, podemos concluir que "La copa del mundo se lleva a cabo en Estados Unidos.”?nn[”sí”, ”no”] | si |
| pregunta contestando |
Respuesta basada en el contexto: nnEl Kindle más nuevo e innovador hasta la fecha le permite tomar notas en millones de libros y documentos, escribir listas y diarios, y más. Para los lectores que siempre han deseado poder escribir en sus libros electrónicos, el nuevo Kindle de Amazon les permite hacer precisamente eso. Kindle Scribe es el primer Kindle para leer y escribir y permite a los usuarios complementar sus libros y documentos con notas, listas y más. Aquí encontrará todo lo que necesita saber sobre Kindle Scribe, incluidas las preguntas más frecuentes. El Kindle Scribe facilita la lectura y escritura como lo haría en papel El Kindle Scribe cuenta con una pantalla sin reflejos de 10.2 pulgadas (la más grande de todos los dispositivos Kindle), una resolución nítida de 300 ppp y 35 luces LED frontales que se ajustan automáticamente a su entorno. Personaliza aún más tu experiencia con la luz cálida ajustable, los tamaños de fuente, el espacio entre líneas y más. Viene con su elección de lápiz básico o lápiz premium, que usa para escribir en la pantalla como lo haría en papel. También se adhieren magnéticamente a su Kindle y nunca necesitan cargarse. Premium Pen incluye un borrador dedicado y un botón de acceso directo personalizable. El Kindle Scribe tiene la mayor cantidad de opciones de almacenamiento de todos los dispositivos Kindle: elija entre 8 GB, 16 GB o 32 GB para adaptarse a su nivel de lectura y escritura.nn¿Cuáles son las características clave del nuevo Kindle? |
Pantalla de 10.2 pulgadas sin reflejos |
| Clasificación de oraciones o sentimientos | Revisión: nEsta película es genial y una vez más nos deslumbra y deleita.n¿Esta oración de reseña de película es negativa o positiva?nOPCIONES:n-positivo n-negativo | positivo |
| Traducción | mi nombre es arturonnTraducir a Alemán | Mi nombre es Arthur |
| resolución de pronombre | Allen hizo reír a su amigo Xin cuando le contó un chiste divertido.nn¿Quién es? he refiriéndose a?nn(A)Allen n(B)Xin | Allen |
| Generación de títulos a partir de un artículo |
El Kindle más nuevo e innovador hasta la fecha le permite tomar notas en millones de libros y documentos, escribir listas y diarios, y más. Para los lectores que siempre han deseado poder escribir en sus libros electrónicos, el nuevo Kindle de Amazon les permite hacer precisamente eso. Kindle Scribe es el primer Kindle para leer y escribir y permite a los usuarios complementar sus libros y documentos con notas, listas y más. Aquí encontrará todo lo que necesita saber sobre Kindle Scribe, incluidas las preguntas más frecuentes. El Kindle Scribe facilita la lectura y escritura como lo haría en papel El Kindle Scribe cuenta con una pantalla sin reflejos de 10.2 pulgadas (la más grande de todos los dispositivos Kindle), una resolución nítida de 300 ppp y 35 luces LED frontales que se ajustan automáticamente a su entorno. Personaliza aún más tu experiencia con la luz cálida ajustable, los tamaños de fuente, el espacio entre líneas y más. Viene con su elección de lápiz básico o lápiz premium, que usa para escribir en la pantalla como lo haría en papel. También se adhieren magnéticamente a su Kindle y nunca necesitan cargarse. Premium Pen incluye un borrador dedicado y un botón de acceso directo personalizable. El Kindle Scribe tiene la mayor cantidad de opciones de almacenamiento de todos los dispositivos Kindle: elija entre 8 GB, 16 GB o 32 GB para adaptarse a su nivel de lectura y escritura. nnDame un buen título para el artículo anterior. |
Todo lo que necesita saber sobre el nuevo Kindle Scribe |
| Generación de artículos imaginarios a partir de un título | Título: "La universidad tiene nuevas instalaciones próximamente“\nDado el título anterior de un artículo imaginario, imagina el artículo.n | La Universidad de Filipinas (UP) está lista para construir un nuevo edificio para su Facultad de Medicina y Ciencias de la Salud (CMHS) en el campus de la Universidad de Santo Tomas (UST) en la ciudad de Bacolod. El edificio de CMHS, que estará ubicado en el campus de la UST, será el primer edificio construido por la universidad en el campus de la UST. El edificio de CMMS será el primero de su tipo en el país, según el Vicepresidente de Administración y Finanzas de la UP, Dr. José L. Alcalá. El edificio de la CMMH será el segundo edificio construido por la UP en la UST. El primer edificio, que se terminó en 2008, es la UP |
Acceda a modelos ajustados con instrucciones Flan-T5 en SageMaker
JumpStart ofrece tres vías para comenzar a usar estos modelos Flan ajustados por instrucciones: modelos básicos de JumpStart, Studio y SageMaker SDK. Las siguientes secciones ilustran el aspecto de cada una de estas vías y describen cómo acceder a ellas.
Modelos de cimentación JumpStart
Los desarrolladores pueden utilizar la interfaz visual de la Modelos de cimentación JumpStart, al que se accede a través de la consola de SageMaker, para probar modelos Flan ajustados por instrucciones sin escribir una sola línea de código. Este patio de recreo proporciona un cuadro de texto de solicitud de entrada junto con controles para varios parámetros utilizados durante la inferencia. Esta característica se encuentra actualmente en una vista previa cerrada, y verá Solicitar acceso botón en lugar de modelos si no tiene acceso. Como se ve en las siguientes capturas de pantalla, puede acceder a los modelos básicos en el panel de navegación de la consola de SageMaker. Elegir Ver modelo en la tarjeta del modelo Flan-T5 XL para acceder a la interfaz de usuario.
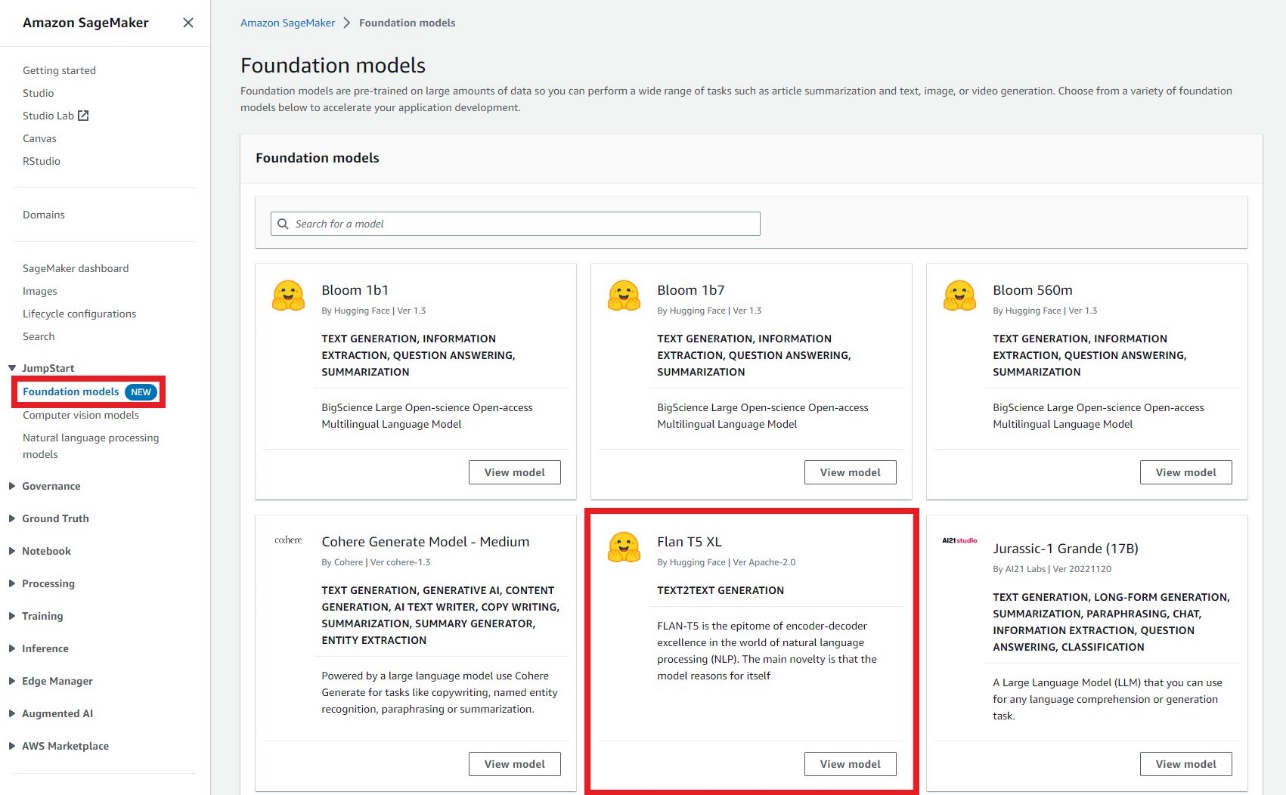
Puede usar esta interfaz de usuario flexible para probar una demostración del modelo.
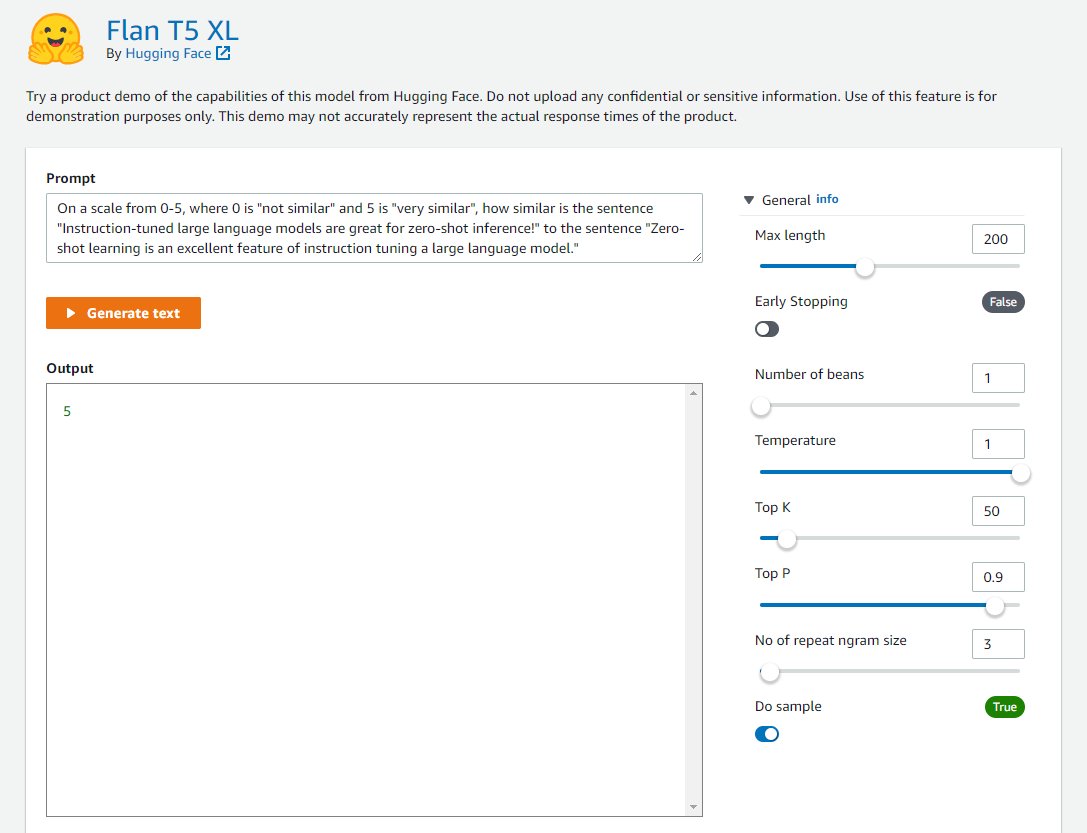
Estudio SageMaker
También puede acceder a estos modelos a través de la Página de destino de JumpStart en el estudio. En esta página, se enumeran las soluciones de aprendizaje automático de extremo a extremo disponibles, los modelos preentrenados y los cuadernos de ejemplo.

Puede elegir una tarjeta modelo Flan-T5 para implementar un punto final modelo a través de la interfaz de usuario.
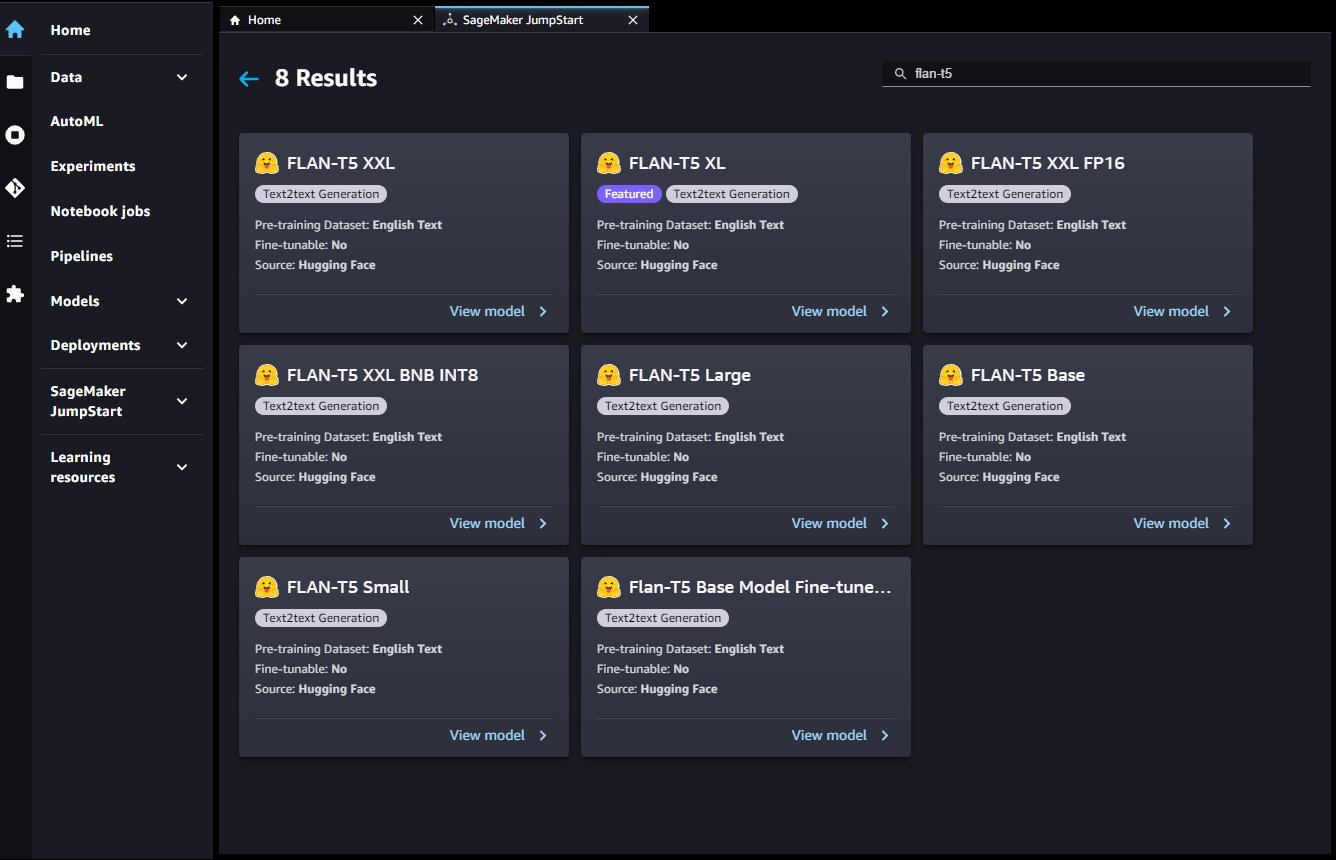
Una vez que su punto de conexión se haya iniciado correctamente, puede iniciar un cuaderno Jupyter de ejemplo que demuestre cómo consultar ese punto de conexión.
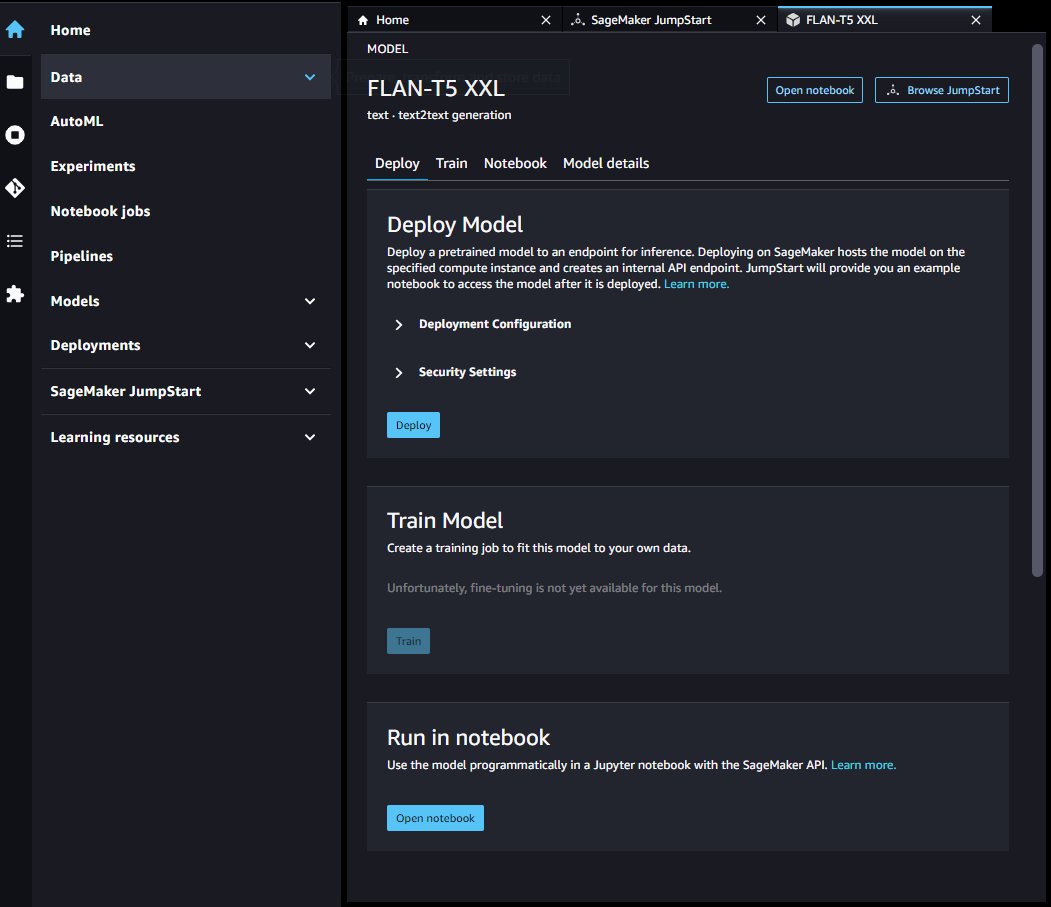
SDK de SageMaker Python
Por último, puede implementar mediante programación un punto final a través del SDK de SageMaker. Deberá especificar el ID de modelo de su modelo deseado en el centro de modelos de SageMaker y el tipo de instancia utilizado para la implementación. El URI del modelo, que contiene el script de inferencia, y el URI del contenedor de Docker se obtienen a través del SDK de SageMaker. Estos URI los proporciona JumpStart y se pueden usar para inicializar un objeto de modelo de SageMaker para su implementación. Ver el siguiente código:
Ahora que el punto final está implementado, puede consultar el punto final para producir texto generado. Considere una tarea de resumen como ejemplo, donde desea producir un resumen del siguiente texto:
Debe proporcionar este texto dentro de una carga JSON al invocar el punto final. Esta carga útil de JSON puede incluir cualquier parámetro de inferencia deseado que ayude a controlar la longitud, la estrategia de muestreo y las restricciones de la secuencia del token de salida. Mientras que la biblioteca de transformadores define una lista completa de parámetros de carga útil disponibles, muchos parámetros de carga útil importantes se definen de la siguiente manera:
- longitud máxima – El modelo genera texto hasta que la longitud de salida (que incluye la longitud del contexto de entrada) alcanza
max_length. Si se especifica, debe ser un entero positivo. - num_return_sequences – El número de secuencias de salida devueltas. Si se especifica, debe ser un entero positivo.
- num_vigas – El número de haces utilizados en la búsqueda codiciosa. Si se especifica, debe ser un número entero mayor o igual que
num_return_sequences. - no_repeat_ngram_size – El modelo asegura que una secuencia de palabras de
no_repeat_ngram_sizeno se repite en la secuencia de salida. Si se especifica, debe ser un entero positivo mayor que 1. - temperatura – Controla la aleatoriedad en la salida. Una temperatura más alta da como resultado una secuencia de salida con palabras de baja probabilidad y una temperatura más baja da como resultado una secuencia de salida con palabras de alta probabilidad. Si
temperaturees igual a 0, da como resultado una decodificación codiciosa. Si se especifica, debe ser un valor flotante positivo. - parada_temprana - Si
True, la generación de texto finaliza cuando todas las hipótesis de haz alcanzan el token de fin de frase. Si se especifica, debe ser booleano. - hacer_muestra - Si
True, muestra la siguiente palabra según la probabilidad. Si se especifica, debe ser booleano. - top_k – En cada paso de la generación de texto, muestree solo el
top_kpalabras más probables. Si se especifica, debe ser un entero positivo. - arriba_p – En cada paso de la generación de texto, muestree del conjunto de palabras más pequeño posible con probabilidad acumulativa
top_p. Si se especifica, debe ser un valor flotante entre 0 y 1. - dispersores – Fijar el estado aleatorio para la reproducibilidad. Si se especifica, debe ser un número entero.
Podemos especificar cualquier subconjunto de estos parámetros al invocar un punto final. A continuación, mostramos un ejemplo de cómo invocar un punto final con estos argumentos:
Este bloque de código genera una muestra de secuencia de salida similar al siguiente texto:
Limpiar
Para evitar cargos continuos, elimine los extremos de inferencia de SageMaker. Puede eliminar los puntos finales a través de la consola de SageMaker o desde el cuaderno de Studio con los siguientes comandos:
Conclusión
En esta publicación, brindamos una descripción general de los beneficios del aprendizaje de disparo cero y describimos cómo la ingeniería rápida puede mejorar el rendimiento de los modelos ajustados por instrucción. También mostramos cómo implementar fácilmente un modelo Flan T5 ajustado por instrucciones desde JumpStart y proporcionamos ejemplos para demostrar cómo puede realizar diferentes tareas de NLP utilizando el extremo del modelo Flan T5 implementado en SageMaker.
Lo alentamos a implementar un modelo Flan T5 de JumpStart y crear sus propias indicaciones para los casos de uso de NLP.
Para obtener más información sobre JumpStart, consulte lo siguiente:
Sobre los autores
 Dra. Xin Huang es un científico aplicado para los algoritmos integrados de Amazon SageMaker JumpStart y Amazon SageMaker. Se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación se encuentran en el área del procesamiento del lenguaje natural, el aprendizaje profundo explicable en datos tabulares y el análisis sólido de la agrupación de espacio-tiempo no paramétrica. Ha publicado muchos artículos en conferencias ACL, ICDM, KDD y la revista Royal Statistical Society: Serie A.
Dra. Xin Huang es un científico aplicado para los algoritmos integrados de Amazon SageMaker JumpStart y Amazon SageMaker. Se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación se encuentran en el área del procesamiento del lenguaje natural, el aprendizaje profundo explicable en datos tabulares y el análisis sólido de la agrupación de espacio-tiempo no paramétrica. Ha publicado muchos artículos en conferencias ACL, ICDM, KDD y la revista Royal Statistical Society: Serie A.
 Vivek Gangasani es arquitecto sénior de soluciones de aprendizaje automático en Amazon Web Services. Trabaja con empresas emergentes de aprendizaje automático para crear e implementar aplicaciones de IA/ML en AWS. Actualmente se enfoca en brindar soluciones para MLOps, ML Inference y low-code ML. Ha trabajado en proyectos en diferentes dominios, incluidos el procesamiento del lenguaje natural y la visión artificial.
Vivek Gangasani es arquitecto sénior de soluciones de aprendizaje automático en Amazon Web Services. Trabaja con empresas emergentes de aprendizaje automático para crear e implementar aplicaciones de IA/ML en AWS. Actualmente se enfoca en brindar soluciones para MLOps, ML Inference y low-code ML. Ha trabajado en proyectos en diferentes dominios, incluidos el procesamiento del lenguaje natural y la visión artificial.
 Dr.Kyle Ulrich es un científico aplicado con el Algoritmos integrados de Amazon SageMaker equipo. Sus intereses de investigación incluyen algoritmos escalables de aprendizaje automático, visión artificial, series temporales, no paramétricos bayesianos y procesos gaussianos. Su doctorado es de la Universidad de Duke y ha publicado artículos en NeurIPS, Cell y Neuron.
Dr.Kyle Ulrich es un científico aplicado con el Algoritmos integrados de Amazon SageMaker equipo. Sus intereses de investigación incluyen algoritmos escalables de aprendizaje automático, visión artificial, series temporales, no paramétricos bayesianos y procesos gaussianos. Su doctorado es de la Universidad de Duke y ha publicado artículos en NeurIPS, Cell y Neuron.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/zero-shot-prompting-for-the-flan-t5-foundation-model-in-amazon-sagemaker-jumpstart/

