
Cuán populares son los LLM a lo largo de las habilidades cognitivas humanas (fuente: análisis de incorporación semántica de aproximadamente 400k textos en línea relacionados con IA desde 2021)
Descargo de responsabilidad: Este artículo fue escrito sin el apoyo de ChatGPT.
En los últimos años, los modelos de lenguaje grande (LLM) como ChatGPT, T5 y LaMDA han desarrollado habilidades asombrosas para producir lenguaje humano. Somos rápidos en atribuir inteligencia a los modelos y algoritmos, pero ¿cuánto de esto es emulación y cuánto recuerda realmente la rica capacidad lingüística de los humanos? Cuando se enfrenta a los resultados seguros y de sonido natural de estos modelos, a veces es fácil olvidar que el lenguaje per se es solo la punta del iceberg de la comunicación. Todo su poder se despliega en combinación con una amplia gama de habilidades cognitivas complejas relacionadas con la percepción, el razonamiento y la comunicación. Si bien los humanos adquieren estas habilidades naturalmente del mundo que los rodea a medida que crecen, los aportes y las señales de aprendizaje para los LLM son bastante escasos. Se ven obligados a aprender sólo de la forma superficial del lenguaje, y su criterio de éxito no es la eficiencia comunicativa sino la reproducción de patrones lingüísticos de alta probabilidad.
En el contexto empresarial, esto puede dar lugar a malas sorpresas cuando se otorga demasiado poder a un LLM. Enfrentando sus propias limitaciones, no las admitirá y más bien gravitará hacia el otro extremo: producir contenido sin sentido, tóxico o incluso consejos peligrosos con un alto nivel de confianza. Por ejemplo, un asistente virtual médico impulsado por GPT-3 puede aconsejar a su usuario que se suicide en un momento determinado de la conversación.[ 4 ]
Teniendo en cuenta estos riesgos, ¿cómo podemos beneficiarnos de manera segura del poder de los LLM al integrarlos en el desarrollo de nuestro producto? Por un lado, es importante ser consciente de los puntos débiles inherentes y utilizar métodos rigurosos de evaluación y sondeo para identificarlos en casos de uso específicos, en lugar de depender de interacciones felices. Por otro lado, la carrera ha comenzado: todos los principales laboratorios de IA están plantando sus semillas para mejorar los LLM con capacidades adicionales, y hay mucho espacio para una mirada alegre hacia el futuro. En este artículo, analizaremos las limitaciones de los LLM y analizaremos los esfuerzos en curso para controlar y mejorar el comportamiento de LLM. Se supone un conocimiento básico del funcionamiento de los modelos de lenguaje; si es un novato, consulte este artículo.
Antes de sumergirnos en la tecnología, preparemos el escenario con un experimento mental, la "prueba del pulpo" propuesta por Emily Bender, para comprender cómo los humanos y los LLM ven el mundo de manera diferente.[ 1 ]
En la piel de un pulpo
Imagina que Anna y Maria están varadas en dos islas deshabitadas. Afortunadamente, han descubierto dos telégrafos y un cable submarino dejado por visitantes anteriores y comienzan a comunicarse entre ellos. Sus conversaciones son "escuchadas por casualidad" por un pulpo ingenioso que nunca ha visto el mundo sobre el agua, pero es excepcionalmente bueno en el aprendizaje estadístico. Recoge las palabras, los patrones sintácticos y los flujos de comunicación entre las dos damas y, por lo tanto, domina la forma externa de su lenguaje sin comprender cómo se basa en el mundo real. Como dijo una vez Ludwig Wittgenstein, "los límites del lenguaje son los límites de mi mundo". conocimiento del mundo por encima del agua.
Si este contenido educativo en profundidad es útil para usted, suscríbase a nuestra lista de correo de IA ser alertado cuando lancemos nuevo material.
En algún momento, escuchar no es suficiente. Nuestro pulpo decide tomar el control, corta el cable del lado de María y comienza a charlar con Anna. La pregunta interesante es, ¿cuándo detectará Anna el cambio? Siempre que las dos partes intercambien bromas sociales, existe una posibilidad razonable de que Anna no sospeche nada. Su pequeña charla podría continuar de la siguiente manera:
R: Hola María!
O: Hola Ana, ¿cómo estás?
R: Gracias, estoy bien, ¡acabo de disfrutar un desayuno de coco!
O: Tienes suerte, no hay cocos en mi isla. ¿Cuáles son tus planes?
R: Quería ir a nadar pero tengo miedo de que haya tormenta. ¿Y usted?
O: Estoy desayunando ahora y haré un poco de carpintería después.
A: ¡Que tengas un buen día, hablamos más tarde!
O: ¡Adiós!
Sin embargo, a medida que su relación se profundiza, su comunicación también crece en intensidad y sofisticación. En las próximas secciones, llevaremos al pulpo a través de un par de escenas de la vida en la isla que requieren el dominio del conocimiento del sentido común, el contexto comunicativo y el razonamiento. A medida que avanzamos, también examinaremos los enfoques para incorporar inteligencia adicional en los agentes, ya sean pulpos ficticios o LLM, que originalmente solo se entrenan desde la forma superficial del lenguaje.
Inyectar conocimiento mundial en los LLM
Una mañana, Anna está planeando un viaje de caza e intenta pronosticar el clima para el día. Como el viento viene de la dirección de María, le pide a "María" un informe sobre las condiciones climáticas actuales como información importante. Al estar atrapado en aguas profundas, nuestro pulpo se avergüenza de describir las condiciones climáticas. Incluso si tuviera la oportunidad de mirar al cielo, no sabría a qué términos meteorológicos específicos como "lluvia", "viento", "nublado", etc. se refieren en el mundo real. Inventa desesperadamente algunos datos meteorológicos. Más tarde ese día, mientras caza en el bosque, Anna es sorprendida por una peligrosa tormenta eléctrica. Ella atribuye su fracaso para predecir la tormenta a la falta de conocimiento meteorológico más que a una alucinación deliberada de su compañero de conversación.
En la superficie, los LLM pueden reflejar con veracidad una gran cantidad de hechos reales sobre el mundo. Sin embargo, su conocimiento se limita a conceptos y hechos que encontraron explícitamente en los datos de entrenamiento. Incluso con grandes datos de entrenamiento, este conocimiento no puede ser completo. Por ejemplo, podría pasar por alto el conocimiento específico del dominio que se requiere para los casos de uso comercial. Otra limitación importante, por ahora, es la actualidad de la información. Dado que los modelos de lenguaje carecen de una noción de contexto temporal, no pueden trabajar con información dinámica como el clima actual, los precios de las acciones o incluso la fecha actual.
Este problema se puede resolver mediante la "inyección" sistemática de conocimientos adicionales en el LLM. Esta nueva entrada puede provenir de varias fuentes, como bases de datos externas estructuradas (por ejemplo, FreeBase o WikiData), fuentes de datos específicas de la empresa y API. Una posibilidad de inyectarlo es a través de redes adaptadoras que se “enchufan” entre las capas de LLM para aprender los nuevos conocimientos:[ 2 ]
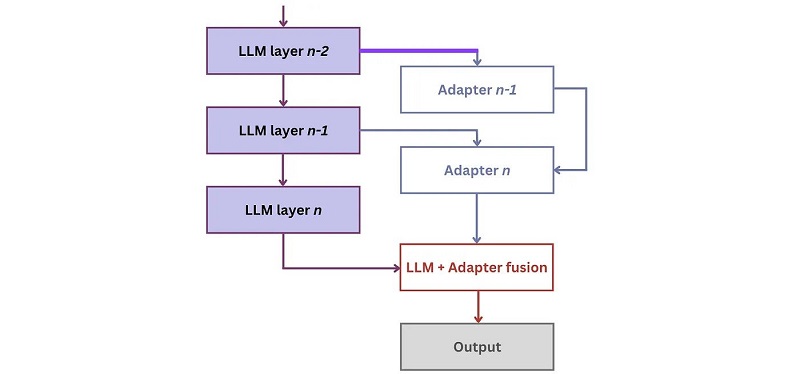
El entrenamiento de esta arquitectura ocurre en dos pasos, a saber memorización y utilización:
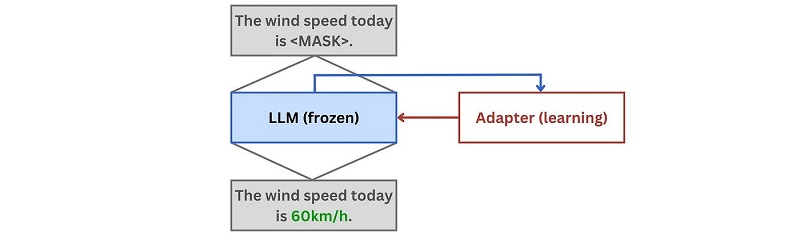
1. Durante memorización, el LLM se congela y las redes de adaptador aprenden los nuevos hechos de la base de conocimientos. La señal de aprendizaje se proporciona a través del modelado de lenguaje enmascarado, mediante el cual se ocultan partes de los hechos y los adaptadores aprenden a reproducirlos:
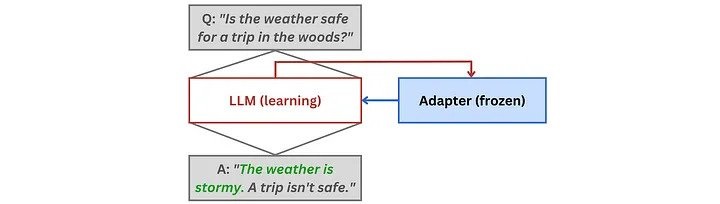
2. Durante utilización, el LM aprende a aprovechar los hechos memorizados por los adaptadores en las respectivas tareas posteriores. Aquí, a su vez, se congelan las redes de adaptadores mientras se optimizan los pesos del modelo:
Durante la inferencia, el estado oculto que el LLM proporciona al adaptador se fusiona con la salida del adaptador mediante una función de fusión para producir la respuesta final.
Si bien la inyección de conocimiento a nivel de arquitectura permite una capacitación modular eficiente de redes de adaptadores más pequeños, la modificación de la arquitectura también requiere una habilidad y un esfuerzo de ingeniería considerables. La alternativa más fácil es la inyección de nivel de entrada, donde el modelo se ajusta directamente a los nuevos hechos (cf. [ 3 ] para un ejemplo). La desventaja es el costoso ajuste necesario después de cada cambio; por lo tanto, no es adecuado para fuentes de conocimiento dinámicas. Se puede encontrar una descripción completa de los enfoques de inyección de conocimiento existentes en este artículo.
La inyección de conocimiento lo ayuda a desarrollar inteligencia de dominio, que se está convirtiendo en un diferenciador clave para los productos verticales de IA. Además, puede usarlo para establecer la trazabilidad, de modo que el modelo pueda señalar al usuario las fuentes de información originales. Más allá de la inyección de conocimiento estructurado, se están realizando esfuerzos para integrar información y conocimiento multimodal en los LLM. Por ejemplo, en abril de 2022, DeepMind presentó Flamingo, un modelo de lenguaje visual que puede ingerir texto, imágenes y video sin problemas.[ 5 ] Al mismo tiempo, Google está trabajando en Socratic Models, un marco modular en el que se pueden componer múltiples modelos previamente entrenados, es decir, a través de indicaciones multimodales, para intercambiar información entre sí.[ 6 ]
Adoptar el contexto y la intención comunicativos
Como Anna quiere compartir no solo sus pensamientos sobre la vida, sino también los deliciosos cocos de su isla con María, inventa una catapulta de coco. Le envía a María instrucciones detalladas sobre cómo lo hizo y le pide instrucciones para optimizarlo. En el extremo receptor, el pulpo no llega a dar una respuesta significativa. Incluso si tuviera una forma de construir la catapulta bajo el agua, no sabe a qué se refieren palabras como cuerda y coco y, por lo tanto, no puede reproducir físicamente y mejorar el experimento. Así que simplemente dice: “¡Buena idea, gran trabajo! ¡Necesito ir a cazar ahora, adiós!”. Anna está molesta por la respuesta poco cooperativa, pero también necesita continuar con sus actividades diarias y se olvida del incidente.
Cuando usamos el lenguaje, lo hacemos con un propósito específico, que es nuestro intención comunicativa. Por ejemplo, la intención comunicativa puede ser transmitir información, socializar o pedirle a alguien que haga algo. Si bien los dos primeros son bastante sencillos para un LLM (siempre y cuando haya visto la información requerida en los datos), el último ya es más desafiante. Olvidémonos del hecho de que el LLM no tiene la capacidad de actuar en el mundo real y nos limitamos a tareas en su ámbito del idioma: escribir un discurso, una carta de solicitud, etc. El LLM no solo necesita combinar y estructurar el información relacionada de manera coherente, pero también debe establecer el tono emocional adecuado en términos de criterios suaves como la formalidad, la creatividad, el humor, etc.
Hacer la transición de la generación de lenguaje clásico a reconocer y responder a intenciones comunicativas específicas es un paso importante para lograr una mejor aceptación de los sistemas NLP orientados al usuario, especialmente en la IA conversacional. Un método para esto es el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF), que se implementó recientemente en ChatGPT ([ 7 ]) pero tiene una historia más larga en el aprendizaje de preferencias humanas.[ 8 ] En pocas palabras, RLHF "redirige" el proceso de aprendizaje del LLM desde la sencilla pero artificial tarea de predicción del siguiente token hacia el aprendizaje de las preferencias humanas en una situación comunicativa dada. Estas preferencias humanas están codificadas directamente en los datos de entrenamiento: durante el proceso de anotación, a los humanos se les presentan indicaciones y escriben la respuesta deseada o clasifican una serie de respuestas existentes. Luego, el comportamiento del LLM se optimiza para reflejar la preferencia humana. Técnicamente, RLHF se realiza en tres pasos:
- Pre-entrenamiento y puesta a punto de un LLM inicial: Un LLM se forma con un objetivo clásico de pre-entrenamiento. Además, se puede ajustar con datos anotados por humanos (como en el caso de InstructGPT y ChatGPT).
- Capacitación modelo de recompensa: El modelo de recompensa se entrena en base a anotaciones humanas que reflejan preferencias comunicativas en una situación dada. Específicamente, a los humanos se les presentan múltiples resultados para un mensaje dado y los clasifican según su idoneidad. El modelo aprende a recompensar los resultados de mayor rango y penalizar los resultados de menor rango. La recompensa es un único número escalar, lo que lo hace compatible con el aprendizaje por refuerzo en el siguiente paso.
- Aprendizaje reforzado: la política es el LLM inicial, mientras que la función de recompensa combina dos puntajes para una entrada de texto dada:
- La puntuación del modelo de recompensa que garantiza que el texto responde a la intención comunicativa.
- Una penalización por generar textos que están demasiado lejos de la salida inicial de LLM (por ejemplo, Divergencia de Kullback-Leibler), asegurándose de que el texto sea semánticamente significativo.
Por lo tanto, el LLM está ajustado para producir salidas útiles que maximizan las preferencias humanas en una situación comunicativa dada, por ejemplo usando Optimización de políticas próximas (OPP).
Para una introducción más profunda a RLHF, consulte los excelentes materiales de Huggingface (artículo y video).
La metodología RLHF tuvo un éxito alucinante con ChatGPT, especialmente en las áreas de IA conversacional y creación de contenido creativo. De hecho, no solo conduce a conversaciones más auténticas y significativas, sino que también puede "sesgar" positivamente el modelo hacia los valores éticos al tiempo que mitiga los resultados poco éticos, discriminatorios o incluso peligrosos. Sin embargo, lo que a menudo no se dice en medio del entusiasmo por RLHF es que, si bien no presenta avances tecnológicos significativos, su megapotencia proviene del esfuerzo de anotación humana lineal. RLHF es prohibitivamente costoso en términos de datos etiquetados, el cuello de botella conocido para todos los esfuerzos de aprendizaje supervisado y de refuerzo. Más allá de las clasificaciones humanas para los resultados de LLM, los datos de OpenAI para ChatGPT también incluyen respuestas escritas por humanos a las indicaciones que se utilizan para ajustar el LLM inicial. Es obvio que solo las grandes empresas comprometidas con la innovación en IA pueden permitirse el presupuesto necesario para el etiquetado de datos a esta escala.
Con la ayuda de una comunidad inteligente, la mayoría de los cuellos de botella finalmente se resuelven. En el pasado, la comunidad de Deep Learning resolvió la escasez de datos con la autosupervisión: LLM de capacitación previa mediante la predicción del siguiente token, una señal de aprendizaje que está disponible "gratis" ya que es inherente a cualquier texto. La comunidad de aprendizaje por refuerzo utiliza algoritmos como codificadores automáticos variacionales o redes antagónicas generativas para generar datos sintéticos, con diversos grados de éxito. Para hacer que RLHF sea ampliamente accesible, también tendremos que encontrar una manera de obtener datos comunicativos de recompensas y/o construirlos de manera autosupervisada o automatizada. Una posibilidad es utilizar conjuntos de datos de clasificación que están disponibles "en la naturaleza", por ejemplo, conversaciones de Reddit o Stackoverflow donde los usuarios califican las respuestas a las preguntas. Más allá de las calificaciones simples y las etiquetas de pulgares arriba/abajo, algunos sistemas de IA conversacionales también permiten al usuario editar directamente la respuesta para demostrar el comportamiento deseado, lo que crea una señal de aprendizaje más diferenciada.
Modelado de procesos de razonamiento
Finalmente, Anna enfrenta una emergencia. Ella es perseguida por un oso enojado. Presa del pánico, agarra un par de palos de metal y le pide a María que le diga cómo defenderse. Por supuesto, el pulpo no tiene idea de lo que quiere decir Anna. No solo nunca se ha enfrentado a un oso, sino que tampoco sabe cómo comportarse en un ataque de oso y cómo los palos pueden ayudar a Anna. Resolver una tarea como esta no solo requiere la capacidad de mapear con precisión entre palabras y objetos en el mundo real, sino también razonar sobre cómo se pueden aprovechar estos objetos. El pulpo fracasa miserablemente y Anna descubre el delirio en el encuentro letal.
Ahora, ¿y si María todavía estuviera allí? La mayoría de los humanos pueden razonar lógicamente, incluso si existen grandes diferencias individuales en el dominio de esta habilidad. Usando el razonamiento, María podría resolver la tarea de la siguiente manera:
Premisa 1 (basada en la situación): Anna tiene un par de palos de metal.
Premisa 2 (basada en el conocimiento del sentido común): Los osos se sienten intimidados por el ruido.
Conclusión : Anna puede intentar usar sus palos para hacer ruido y asustar al oso.
Los LLM a menudo producen resultados con una cadena de razonamiento válida. Sin embargo, en una inspección más cercana, la mayor parte de esta coherencia es el resultado del aprendizaje de patrones en lugar de una combinación deliberada y novedosa de hechos. DeepMind ha estado en la búsqueda de resolver la causalidad durante años, y un intento reciente es el marco de razonamiento fiel para responder preguntas.[ 9 ] La arquitectura consta de dos LLM: uno para la selección de premisas relevantes y otro para inferir la respuesta final y concluyente a la pregunta. Cuando se le solicita una pregunta y su contexto, el LLM de selección primero selecciona las declaraciones relacionadas de su corpus de datos y las pasa al LLM de inferencia. El LLM de inferencia deduce nuevas declaraciones y las agrega al contexto. Este proceso de razonamiento iterativo llega a su fin cuando todas las declaraciones se alinean en una cadena de razonamiento coherente que proporciona una respuesta completa a la pregunta:
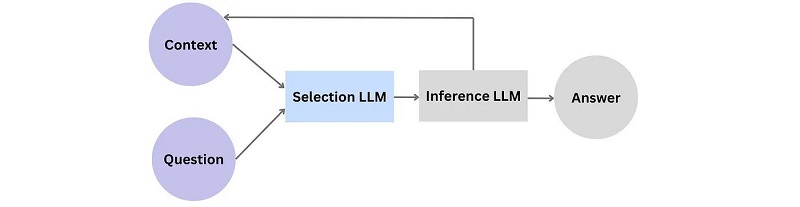
A continuación se muestra la cadena de razonamiento para nuestro incidente en la isla:

Más allá de esta capacidad general de razonar lógicamente, los humanos también acceden a toda una caja de herramientas de habilidades de razonamiento más específicas. Un ejemplo clásico es el cálculo matemático. Los LLM pueden producir estos cálculos hasta cierto nivel; por ejemplo, los LLM modernos pueden realizar sumas de 2 o 3 dígitos con confianza. Sin embargo, comienzan a fallar sistemáticamente cuando aumenta la complejidad, por ejemplo, cuando se agregan más dígitos o se deben realizar múltiples operaciones para resolver una tarea matemática. Y las tareas “verbales” formuladas en lenguaje natural (por ejemplo, “Tenía 10 mangos y perdí 3. ¿Cuántos mangos me quedan?”) son mucho más desafiantes que los cálculos explícitos (”diez menos tres es igual...”). Si bien el rendimiento de LLM se puede mejorar aumentando el tiempo de capacitación, los datos de capacitación y los tamaños de los parámetros, el uso de una calculadora simple seguirá siendo la alternativa más confiable.
Al igual que los niños que aprenden explícitamente las leyes de las matemáticas y otras ciencias exactas, los LLM también pueden beneficiarse de las reglas codificadas. Esto suena como un caso para la IA neurosimbólica y, de hecho, los sistemas modulares como MRKL (pronunciado "milagro") de AI21 Labs dividen la carga de trabajo de comprender la tarea, ejecutar el cálculo y formular el resultado de salida entre diferentes modelos.[ 12 ] MRKL son las siglas de Modular Reasoning, Knowledge and Language y combina módulos de IA de una manera pragmática plug-and-play, alternando entre conocimiento estructurado, métodos simbólicos y modelos neuronales. Volviendo a nuestro ejemplo, para realizar cálculos matemáticos, primero se ajusta un LLM para extraer los argumentos formales de una tarea de aritmética verbal (números, operandos, paréntesis). Luego, el cálculo en sí se "enruta" a un módulo matemático determinista, y el resultado final se formatea en lenguaje natural utilizando el LLM de salida.
A diferencia de los LLM monolíticos de caja negra, los complementos de razonamiento crean transparencia y confianza, ya que descomponen el proceso de "pensamiento" en pasos individuales. Son particularmente útiles para respaldar caminos de decisión y acción complejos y de varios pasos. Por ejemplo, pueden ser utilizados por asistentes virtuales que hacen recomendaciones basadas en datos y necesitan realizar múltiples pasos de análisis y agregación para llegar a una conclusión.
Conclusión y conclusiones
En este artículo, proporcionamos una descripción general de los enfoques para complementar la inteligencia de los LLM. Resumamos nuestras pautas para maximizar los beneficios de los LLM y las posibles mejoras:
- Hazlos fallar: No se deje engañar por los resultados iniciales: los modelos de lenguaje pueden producir resultados impresionantes cuando comienza a trabajar con ellos y, de todos modos, los humanos tenemos la tendencia a atribuir demasiada inteligencia a las máquinas. Ponte en el papel de un usuario mezquino y adversario y explora los puntos débiles. Haga esto desde el principio, antes de que se haya puesto demasiada piel en el juego.
- Evaluación y sondeo dedicado: El diseño de su tarea de formación y el procedimiento de evaluación son de vital importancia. En la medida de lo posible, debe reflejar el contexto del uso del lenguaje natural. Conociendo las trampas de los LLM, dedique su evaluación a ellos.
- Benefíciese de la IA neurosimbólica: La IA simbólica no está descartada: en el contexto de un negocio o producto individual, establecer algunos de sus conocimientos de dominio en piedra puede ser un enfoque eficiente para aumentar la precisión. Le permite controlar el comportamiento del LLM donde es crucial para su negocio, mientras sigue desplegando su poder para generar lenguaje basado en un amplio conocimiento externo.
- Esforzarse por una arquitectura flexible: En la superficie, los LLM a veces se sienten como cajas negras. Sin embargo, como hemos visto, existen numerosos enfoques, y estarán disponibles en el futuro, no solo para afinar, sino también para "ajustar" su comportamiento y aprendizaje internos. Utilice modelos y soluciones de código abierto si tiene la capacidad técnica; esto le permitirá adaptar y maximizar el valor agregado de los LLM en su producto.
E incluso con las mejoras descritas, los LLM están muy por detrás de la comprensión humana y el uso del lenguaje: simplemente carecen de la sinergia única, poderosa y misteriosa del conocimiento cultural, la intuición y la experiencia que los humanos acumulan a lo largo de sus vidas. Según Yann LeCun, "está claro que estos modelos están condenados a una comprensión superficial que nunca se aproximará al pensamiento completo que vemos en los humanos".[ 11 ] Al usar IA, es importante apreciar las maravillas y la complejidad que encontramos en el lenguaje y la cognición. Mirando las máquinas inteligentes desde la distancia correcta, podemos diferenciar entre las tareas que se les pueden delegar y las que seguirán siendo privilegio de los humanos en el futuro previsible.
Referencias
[1] Emily M. Bender y Alexander Koller. 2020. Escalando hacia NLU: sobre el significado, la forma y la comprensión en la era de los datos. En Actas de la 58a Reunión Anual de la Asociación de Lingüística Computacional, páginas 5185–5198, en línea. Asociación de Lingüística Computacional.
[2] Emelin, Denis y Bonadiman, Daniele y Alqahtani, Sawsan y Zhang, Yi y Mansour, Saab. (2022). Inyectar conocimiento de dominio en modelos de lenguaje para sistemas de diálogo orientados a tareas. 10.48550/arXiv.2212.08120.
[3] Fiódor Moiseev et al. 2022. HABILIDAD: Infusión de conocimiento estructurado para modelos de lenguaje grandes. En Actas de la Conferencia de 2022 del Capítulo de América del Norte de la Asociación de Lingüística Computacional: Tecnologías del lenguaje humano, páginas 1581–1588, Seattle, Estados Unidos. Asociación de Lingüística Computacional.
[4] Ryan Daws. 2020. El chatbot médico que usa GPT-3 de OpenAI le dijo a un paciente falso que se suicidara. Recuperado el 13 de enero de 2022.
[5] Mente Profunda. 2022. Abordar múltiples tareas con un solo modelo de lenguaje visual. Recuperado el 13 de enero de 2022.
[6] Zeng et al. 2022. Modelos socráticos: composición de razonamiento multimodal de tiro cero con lenguaje. Preimpresión.
[7] IA abierta. 2022. ChatGPT: Optimización de modelos de lenguaje para el diálogo. Recuperado el 13 de enero de 2022.
[8] Christiano et al. 2017. Aprendizaje de refuerzo profundo a partir de preferencias humanas.
[9] Creswell y Shanahan. 2022. Razonamiento fiel utilizando grandes modelos de lenguaje. Mente profunda.
[10] Karpas et al. 2022. Sistemas MRKL: una arquitectura neurosimbólica modular que combina grandes modelos de lenguaje, fuentes de conocimiento externas y razonamiento discreto. Laboratorios AI21.
[11] Jacob Browning y Yann LeCun. 2022. AI y los límites del lenguaje. Recuperado el 13 de enero de 2022.
[12] Karpas et al. 2022. Sistemas MRKL: una arquitectura neurosimbólica modular que combina grandes modelos de lenguaje, fuentes de conocimiento externas y razonamiento discreto.
Todas las imágenes, a menos que se indique lo contrario, son del autor.
Este artículo se publicó originalmente el Hacia la ciencia de datos y re-publicado a TOPBOTS con permiso del autor.
¿Disfrutas este artículo? Regístrese para obtener más actualizaciones de investigación de IA.
Le informaremos cuando publiquemos más artículos de resumen como este.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.topbots.com/overcoming-the-limitations-of-large-language-models/

