
Este artículo fue publicado originalmente en la página del autor blog y re-publicado a TOPBOTS con permiso del autor.
Modelos de lenguaje grandes como ChatGPT procesan y generan secuencias de texto dividiendo primero el texto en unidades más pequeñas llamadas fichas. En la imagen a continuación, cada bloque de color representa una ficha única. Palabras cortas o comunes como “usted”, “decir”, “fuerte” y “siempre” son su propia ficha, mientras que palabras más largas o menos comunes como “atroz”, “precoz” y “supercalifragilisticoespialidoso” se dividen en subpalabras más pequeñas.
Este proceso de tokenización no es uniforme en todos los idiomas, lo que genera disparidades en la cantidad de tokens producidos para expresiones equivalentes en diferentes idiomas. Por ejemplo, una oración en birmano o amárico puede requerir 10 veces más tokens que un mensaje similar en inglés.

Un ejemplo del mismo mensaje traducido a cinco idiomas y la cantidad correspondiente de tokens necesarios para tokenizar ese mensaje (usando el tokenizador de OpenAI). El texto proviene Conjunto de datos MASIVO de Amazon.
En este artículo, exploro el proceso de tokenización y cómo varía en diferentes idiomas:
- Análisis de distribuciones de tokens en un conjunto de datos paralelo de mensajes cortos que se han traducido a 52 idiomas diferentes
- Algunos idiomas, como el armenio o el birmano, requieren 9 a 10 veces más fichas que en inglés tokenizar mensajes comparables
- El impacto de esta disparidad lingüística
- Este fenómeno no es nuevo para la IA — esto es consistente con lo que observamos en el código Morse y las fuentes de computadora
Pruébelo usted mismo!
Pruebe el tablero exploratorio que hice, disponible en los espacios HuggingFace. Aquí, puede comparar las longitudes de token para diferentes idiomas y para diferentes tokenizadores (que no se exploró en este artículo, pero que exploro al lector para que lo haga por su cuenta).
MASIVO es un conjunto de datos paralelo introducido por Amazon que consta de 1 millón de textos breves paralelos y realistas traducidos en 52 idiomas y 18 dominios. usé el dev división del conjunto de datos, que consta de 2033 textos traducidos a cada uno de los idiomas. El conjunto de datos es disponible en HuggingFace y tiene licencia bajo el Licencia CC BY 4.0.
Si bien existen muchos otros tokenizadores de modelos de lenguaje, este artículo se centra principalmente en Tokenizador de codificación de pares de bytes (BPE) de OpenAI (usado por ChatGPT y GPT-4) por tres razones principales:
- En primer lugar, El artículo de Denys Linkov comparó varios tokenizadores y descubrió que el tokenizador de GPT-2 tenía la disparidad de longitud de token más alta entre los diferentes idiomas. Esto me llevó a concentrarme en los modelos OpenAI, incluidos GPT-2 y sus sucesores.
- En segundo lugar, dado que carecemos de información sobre el conjunto de datos de capacitación completo de ChatGPT, investigar los tokenizadores y los modelos de caja negra de OpenAI ayuda a comprender mejor sus comportamientos y resultados.
- Finalmente, la adopción generalizada de ChatGPT en varias aplicaciones (desde plataformas de aprendizaje de idiomas como Duolingo a aplicaciones de redes sociales como Snapchat) destaca la importancia de comprender los matices de tokenización para garantizar un procesamiento lingüístico equitativo en diversas comunidades lingüísticas.
Para calcular el número de tokens que contiene un texto, utilizo el cl100k_base tokenizador disponible en tik token, que es el tokenizador BPE utilizado por los modelos ChatGPT de OpenAI (`gpt-3.5-turbo` y `gpt-4`).
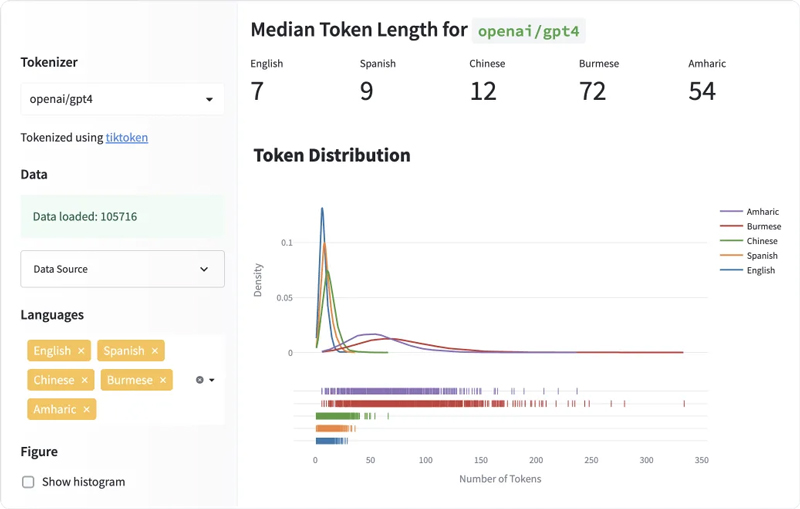
Algunos idiomas tokenizan consistentemente a longitudes más largas
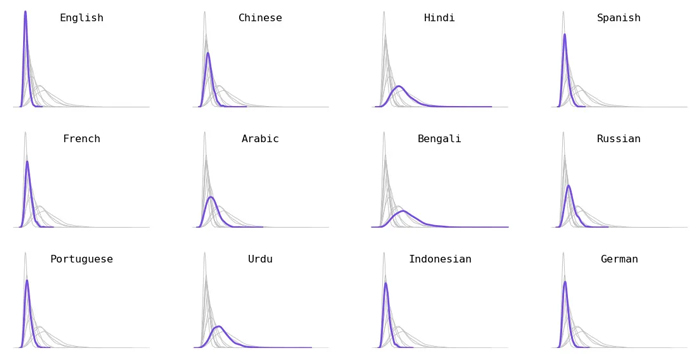
El siguiente gráfico de distribución compara la distribución de longitudes de token para cinco idiomas. La curva para el inglés es alta y angosta, lo que significa que los textos en inglés se tokenizan consistentemente en un número menor de tokens. Por otro lado, la curva para idiomas como el hindi y el birmano es corta y ancha, lo que significa que estos idiomas tokenizan los textos en muchos más tokens.
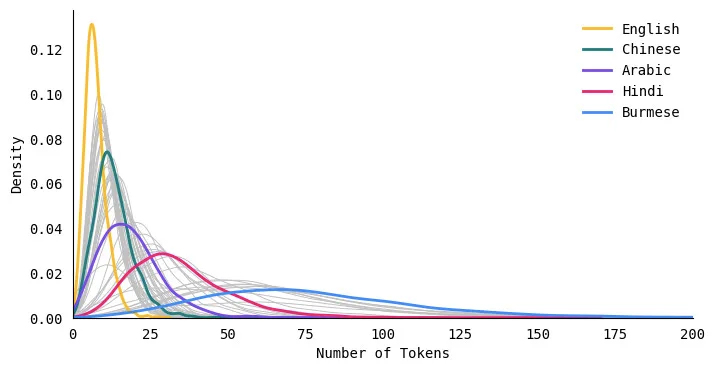
El inglés tiene la longitud media de token más corta
Para cada idioma, calculé la longitud mediana del token para todos los textos en el conjunto de datos. El siguiente gráfico compara un subconjunto de los idiomas. Los textos en inglés tenían la longitud mediana más pequeña de 7 tokens y los textos en birmano tenían la longitud mediana más grande de 72 tokens. Las lenguas romances como el español, el francés y el portugués tendían a dar como resultado una cantidad similar de fichas que el inglés.
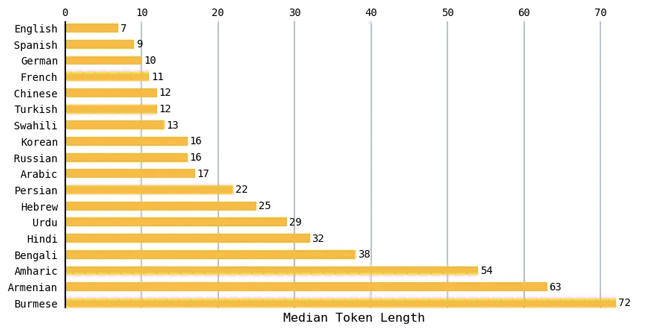
Como el inglés tenía la longitud media de token más corta, calculé la relación entre la longitud media de token de los otros idiomas y la del inglés. Idiomas como el hindi y el bengalí (más de 800 millones de personas hablan cualquiera de estos idiomas) dieron como resultado una longitud de token promedio de aproximadamente 5 veces la del inglés. La proporción es 9 veces la del inglés para el armenio y más de 10 veces la del inglés para el birmano. En otras palabras, para expresar el mismo sentimiento, algunos idiomas requieren hasta 10 veces más tokens.
Implicaciones de la disparidad del lenguaje de tokenización
En general, requerir más tokens (para tokenizar el mismo mensaje en un idioma diferente) significa:
- Está limitado por la cantidad de información que puede poner en el indicador (porque la ventana de contexto es fija). A partir de marzo de 2023, GPT-3 podría recibir hasta 4 4 tokens y GPT-8 podría recibir hasta 32 XNUMX o XNUMX XNUMX tokens en su entrada [1]
- cuesta mas dinero
- Se tarda más en correr
Los modelos de OpenAI se utilizan cada vez más en países donde el inglés no es el idioma dominante. Según SimilarWeb.com, Estados Unidos solo representó el 10% del tráfico enviado a ChatGPT en enero-marzo de 2023.
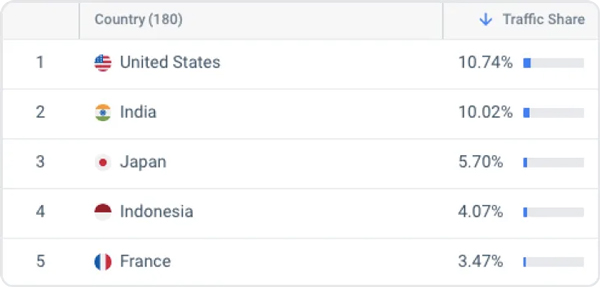
Además, se utilizó ChatGPT en Pakistán para conceder la libertad bajo fianza en un caso de secuestro de menores y en Japón para tareas administrativas. A medida que ChatGPT y modelos similares se integran cada vez más en productos y servicios en todo el mundo, es crucial comprender y abordar tales desigualdades.
Disparidad lingüística en el procesamiento del lenguaje natural
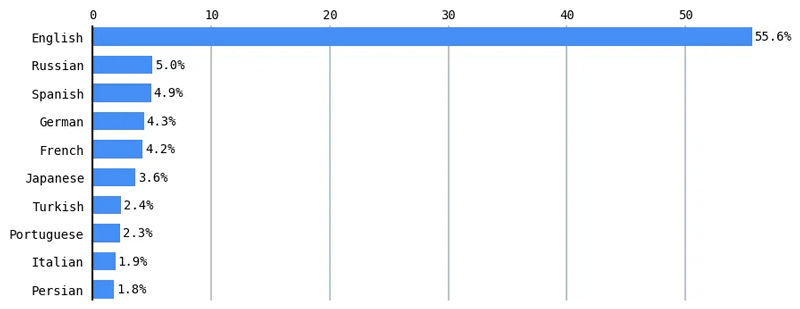
Esta brecha digital en el procesamiento del lenguaje natural (NLP) es un área activa de investigación. El 70% de los trabajos de investigación publicados en una conferencia de lingüística computacional solo evaluaron el inglés.[2] Los modelos multilingües funcionan peor en varias tareas de PNL en idiomas con pocos recursos que en idiomas con muchos recursos, como el inglés.[3] De acuerdo a W3Techs (World Wide Web Technology Surveys), el inglés domina más de la mitad (55.6 %) del contenido de Internet.[4]
Del mismo modo, el inglés constituye más del 46% del corpus Common Crawl (miles de millones de páginas web de Internet rastreado durante más de una década), cuyas versiones se han utilizado para entrenar muchos lenguajes grandes, como T5 de Google y GPT-3 de OpenAI (y probablemente ChatGPT y GPT-4). Common Crawl representa el 60 % de los datos de entrenamiento de GPT-3.[5]
Abordar la brecha digital en NLP es crucial para garantizar una representación y un rendimiento lingüísticos equitativos en las tecnologías impulsadas por IA. Cerrar esta brecha requiere un esfuerzo concertado de investigadores, desarrolladores y lingüistas para priorizar e invertir en el desarrollo de idiomas de bajos recursos, fomentando un panorama lingüístico más inclusivo y diverso en el ámbito del procesamiento del lenguaje natural.
Ejemplo histórico: representar la tipografía china usando el código Morse
Tal disparidad de costos tecnológicos para diferentes idiomas no es nueva para la IA o incluso para la informática.
Hace más de cien años, la telegrafía, una tecnología revolucionaria de su tiempo ("el Internet de su era"), enfrentó desigualdades lingüísticas similares a las que vemos en los grandes modelos lingüísticos actuales. A pesar de sus promesas de intercambio abierto y colaboración, la telegrafía exhibió discrepancias en velocidad y costo entre idiomas. Por ejemplo, codificar y transmitir un mensaje en chino (en comparación con un mensaje equivalente en inglés) fue
- 2 veces más caro
- Tardó de 15 a 20 veces más
¿Te suena familiar?
La telegrafía fue “diseñada ante todo y sobre todo para las lenguas alfabéticas occidentales, sobre todo el inglés.”[6] El código Morse asignó diferentes longitudes y costos a los puntos y rayas, lo que resultó en un sistema rentable para el inglés. Sin embargo, el idioma chino, que se basa en ideogramas, enfrentó desafíos en la telegrafía. Un francés llamado Viguier ideó un sistema de mapeo de caracteres chinos al código Morse.
Esencialmente, cada ideograma chino se asignó a un código de cuatro dígitos, que luego se tradujo al código Morse. Esto llevó mucho tiempo buscando los códigos en el libro de códigos (que carecía de correlaciones significativas) y fue más costoso de transmitir (ya que cada carácter estaba representado por cuatro dígitos y un solo dígito era más costoso de transmitir que una sola letra). Esta práctica puso al idioma chino en desventaja en comparación con otros idiomas en términos de velocidad y costo telegráfico.
Otro ejemplo: Inequidad en la representación de fuentes
Inicialmente, traté de visualizar los 52 idiomas en una sola nube de palabras. Terminé con algo como esto, donde la mayoría de los idiomas no se representaban correctamente.

Esto me llevó a la madriguera de un conejo al tratar de encontrar una fuente que pudiera representar todos los scripts de idiomas. Fui a Google Fonts para encontrar esta fuente perfecta y descubrí que no existía. A continuación se muestra una captura de pantalla que muestra cómo se representarían estos 52 idiomas en 3 fuentes diferentes de Google Fonts.

Para generar la nube de palabras al comienzo de este artículo, descargué manualmente los 17 archivos de fuente necesarios para representar todos los scripts de idiomas y mostrar las palabras de una en una. Si bien obtuve el efecto deseado, fue mucho más trabajo de lo que habría sido si, por ejemplo, todos mis idiomas usaran la misma escritura (como el alfabeto latino).
En este artículo, exploré la disparidad del lenguaje en los modelos de lenguaje al observar cómo procesan el texto a través de la tokenización.
- Usando un conjunto de datos de textos paralelos traducidos a 52 idiomas, mostré que algunos idiomas requieren hasta 10 veces más tokens para expresar el mismo mensaje en inglés.
- Compartí un panel de control donde puede explorar diferentes idiomas y tokenizadores
- Discutí los impactos de esta disparidad en ciertos idiomas en términos de rendimiento, costo monetario y tiempo.
- Mostré cómo este patrón de disparidad tecnológica lingüística no es nuevo, comparando el fenómeno con el caso histórico del código Morse chino y la telegrafía.
Las disparidades lingüísticas en la tokenización de la PNL revelan un problema apremiante en la IA: la equidad y la inclusión. Dado que los modelos como ChatGPT se entrenan predominantemente en inglés, los idiomas de escritura no indoeuropeos y no latinos enfrentan barreras debido a los costos de tokenización prohibitivos. Abordar estas disparidades es esencial para garantizar un futuro más inclusivo y accesible para la inteligencia artificial, lo que en última instancia beneficiará a diversas comunidades lingüísticas en todo el mundo.
Apéndice
Tokenización de codificación de pares de bytes
En el ámbito del procesamiento del lenguaje natural, los tokenizadores juegan un papel crucial al permitir que los modelos de lenguaje procesen y comprendan el texto. Diferentes modelos usan diferentes métodos para tokenizar una oración, como dividirla en palabras, en caracteres o en partes de palabras (también conocidas como subpalabras; por ejemplo, dividir "constantemente" en "constante" y "ly").
Una tokenización común se llama Codificación de pares de bytes (BPE). Esta es la codificación utilizada por OpenAI para sus modelos ChatGPT. BPE está destinado a descomponer palabras raras en subpalabras significativas mientras mantiene intactas las palabras de uso frecuente. Puede encontrar una explicación completa del algoritmo BPE en el Curso HuggingFace Transformers.
Inmersión más profunda en la distribución de tokens para idiomas
Aumenté el conjunto de datos MASIVO de Amazon usando información sobre cada uno de los 52 idiomas usando la sección de cuadro de información de la página de Wikipedia de ese idioma, obteniendo información como escritura (por ejemplo, alfabeto latino, árabe) y la región geográfica principal en la que predomina el idioma (si corresponde) . También uso metadatos de Atlas mundial de estructuras lingüísticas para obtener información como familia lingüística (por ejemplo, indoeuropeo, chino-tibetano).[7]
Tenga en cuenta que los siguientes análisis en este artículo confirman las suposiciones hechas por Wikipedia, The World Atlas of Language Structures y por el conjunto de datos Amazon MASSIVE. Como no soy un experto en lingüística, tuve que suponer que cualquier cosa en Wikipedia y el Atlas mundial se aceptaba canónicamente como correcta con respecto a la región geográfica dominante o la familia de idiomas.
Además, hay debates sobre lo que constituye un idioma frente a un dialecto. Por ejemplo, mientras que los idiomas como el chino y el árabe tienen diferentes formas que las personas pueden no entender, todavía se les llama idiomas únicos. Por otro lado, el hindi y el urdu son muy similares y, a veces, se agrupan en un solo idioma llamado hindustani. Debido a estos desafíos, debemos tener cuidado al decidir qué cuenta como idioma o dialecto.
Desglose por idioma. Elegí el 12 idiomas más hablados (una combinación de hablantes de primer y segundo idioma).
Desglose por familia lingüística. Las lenguas indoeuropeas (p. ej., sueco, francés), las lenguas austronesias (p. ej., indonesio, tagalo) y las lenguas urálicas (p. ej., húngaro, finlandés) dieron como resultado fichas más cortas. Los idiomas dravidianos (p. ej., tamil, kannada) tendían a tener fichas más largas.

Desglose por principales regiones geográficas. No todos los idiomas eran específicos de una sola región geográfica (como el árabe, el inglés y el español, que se distribuyen en muchas regiones); estos idiomas se eliminaron de esta sección. Los idiomas que se hablan principalmente en Europa tienden a tener una longitud de símbolo más corta, mientras que los idiomas que se hablan principalmente en Oriente Medio, Asia Central y el Cuerno de África tienden a tener una longitud de símbolo más larga.

Desglose por guión de redacción. Aparte de los alfabetos latino, árabe y cirílico, todos los demás idiomas usan su propia escritura única. Si bien este último combina muchas secuencias de comandos únicas muy diferentes (como las secuencias de comandos coreanas, hebreas y georgianas), estas secuencias de comandos únicas definitivamente tokenizan valores más largos. En comparación con los scripts basados en latín, que tokenizan a valores más cortos.

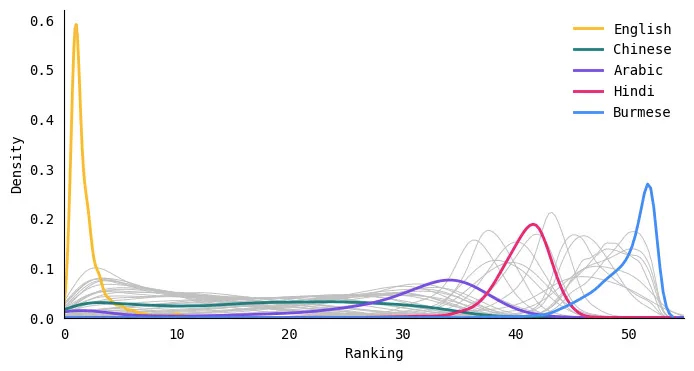
El inglés casi siempre ocupa el puesto número 1
Para cada texto en el conjunto de datos, clasifiqué todos los idiomas según la cantidad de tokens: el idioma con menos tokens ocupó el puesto n.º 1 y el que tenía más tokens ocupó el puesto n.º 52. Luego, tracé la distribución de cada idioma clasificación. Esencialmente, esto debería mostrar cómo se compara la longitud del token de cada idioma con los otros idiomas en este conjunto de datos. En la figura a continuación, etiqueté algunos de los idiomas (los otros idiomas aparecen como líneas grises en el fondo).
Si bien hubo algunos casos en los que los tokens de algunos idiomas fueron menores que los del inglés (como algunos ejemplos en indonesio o noruego), el inglés casi siempre ocupó el primer lugar. ¿Esto es una sorpresa para alguien? Lo que más me sorprendió fue que no había un #2 o #3 claro. Los textos en inglés producen consistentemente los tokens más cortos y la clasificación fluctúa un poco más para otros idiomas.
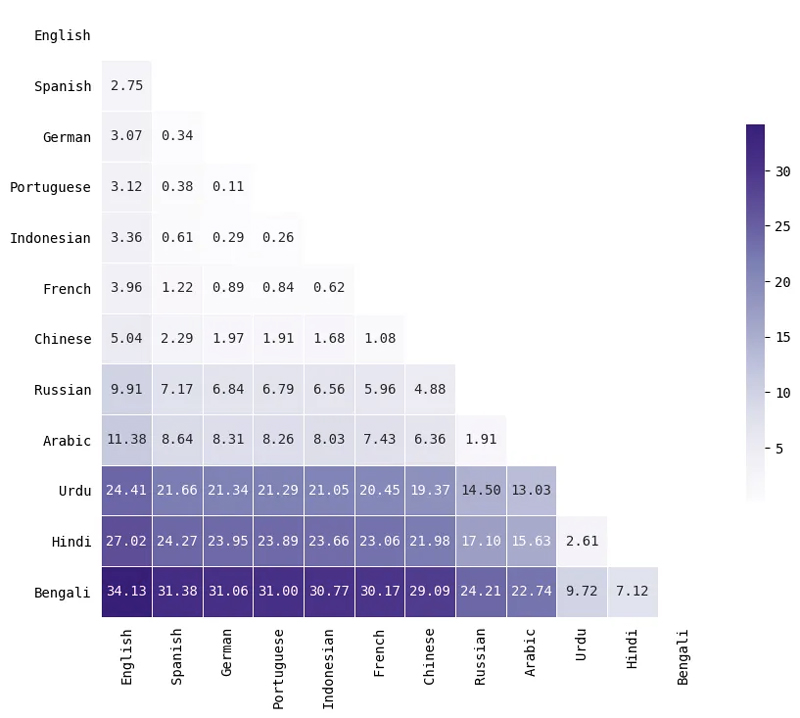
Cuantificación de las diferencias en las distribuciones de tokens utilizando la distancia del motor de la tierra
Para cuantificar cuán diferente era la distribución de la longitud del token entre dos idiomas, calculé el distancia del movimiento de tierra (También conocido como el distancia de Wasserstein) entre dos distribuciones. Esencialmente, esta métrica calcula la cantidad mínima de "trabajo" requerido para transformar una distribución en otra. Los valores más grandes significan que las distribuciones están más separadas (más diferentes), mientras que los valores más pequeños significan que las distribuciones son bastante similares.
Aquí hay un pequeño subconjunto de idiomas. Tenga en cuenta que la distancia no dice nada sobre la longitud de los tokens, solo cuán similar es la distribución de longitudes de tokens para dos idiomas. Por ejemplo, el árabe y el ruso tienen distribuciones similares aunque los idiomas mismos no son similares en un sentido lingüístico.
1. IA abierta. “Modelos”. API OpenAI. Archivado del original el 17 de marzo de 2023. Consultado el 18 de marzo de 2023.
2. Sebastian Ruder, Ivan Vulic y Anders Søgaard. 2022. Sesgo de cuadrado uno en PNL: hacia una exploración multidimensional de la variedad de investigación. En Hallazgos de la Asociación de Lingüística Computacional: ACL 2022, páginas 2340–2354, Dublín, Irlanda. Asociación de Lingüística Computacional.
3. Shijie Wu y Mark Dredze. 2020. ¿Todos los idiomas son iguales en el BERT multilingüe?. En Actas del 5º Taller sobre Aprendizaje de Representación para PNL, páginas 120–130, en línea. Asociación de Lingüística Computacional.
4. Estadísticas de uso de idiomas de contenido para sitios web”. Archivado del original el 30 de abril de 2023.
5. Marrón, Tom, et al. “Los modelos lingüísticos son aprendices de pocas oportunidades”. Avances en los sistemas de procesamiento de información neuronal. 33 (2020): 1877 – 1901.
6. Jin Tsu. Reino de los personajes: la revolución lingüística que hizo a China moderna. Nueva York: Riverhead Books, 2022 (pág. 124).
7. Dryer, Matthew S. & Haspelmath, Martin (eds.) 2013. WALS Online (v2020.3) [Conjunto de datos]. Zenodo. https://doi.org/10.5281/zenodo.7385533. Disponible en línea en https://wals.info, Consultado el 2023–04–30.
¿Disfrutas este artículo? Regístrese para obtener más actualizaciones de investigación de IA.
Le informaremos cuando publiquemos más artículos de resumen como este.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- EVM Finanzas. Interfaz unificada para finanzas descentralizadas. Accede Aquí.
- Grupo de medios cuánticos. IR/PR amplificado. Accede Aquí.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.topbots.com/all-languages-are-not-tokenized-equal/

