Introducción
En los últimos años, el panorama del procesamiento del lenguaje natural (NLP, por sus siglas en inglés) ha experimentado una transformación notable, todo gracias a la llegada de los grandes modelos de lenguaje. Estos modelos sofisticados han abierto las puertas a una amplia gama de aplicaciones, que van desde la traducción de idiomas hasta el análisis de sentimientos e incluso la creación de chatbots inteligentes.
Pero su versatilidad distingue a estos modelos; ajustarlos para abordar tareas y dominios específicos se ha convertido en una práctica estándar, desbloqueando su verdadero potencial y elevando su rendimiento a nuevas alturas. En esta guía completa, nos adentraremos en el mundo del ajuste fino de los modelos de lenguajes grandes, cubriendo todo, desde lo básico hasta lo avanzado.
OBJETIVOS DE APRENDIZAJE
- Comprender el concepto y la importancia del ajuste fino en la adaptación de grandes modelos lingüísticos a tareas específicas.
- Descubra técnicas avanzadas de ajuste fino como multitarea, ajuste fino de instrucciones y ajuste fino de parámetros eficientes.
- Obtenga conocimientos prácticos de las aplicaciones del mundo real donde los modelos de lenguaje perfeccionados revolucionan las industrias.
- Aprenda paso a paso el proceso de ajuste fino de modelos lingüísticos grandes.
- Implementar el mecanismo de ajuste fino peft.
- Comprender la diferencia entre el ajuste fino estándar y el ajuste fino de instrucción.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Comprender los modelos de lenguaje preentrenados
Los modelos de lenguaje preentrenados son grandes redes neuronales entrenadas en vastos corpus de datos de texto, generalmente provenientes de Internet. El proceso de entrenamiento involucra la predicción de palabras faltantes o tokens en una oración o secuencia determinada, lo que imbuye al modelo con una comprensión profunda de la gramática, el contexto y la semántica. Al procesar miles de millones de oraciones, estos modelos pueden comprender las complejidades del lenguaje y capturar sus matices de manera efectiva.
Los ejemplos de modelos de lenguaje preentrenados populares incluyen BERT (Representaciones de codificador bidireccional de transformadores), GPT-3 (Transformador preentrenado generativo 3), RoBERTa (Un enfoque de preentrenamiento de BERT robustamente optimizado) y muchos más. Estos modelos son conocidos por su capacidad para realizar tareas como la generación de texto, la clasificación de sentimientos y la comprensión del idioma a un nivel impresionante de competencia.
Analicemos uno de los modelos de lenguaje en detalle.
GPT-3
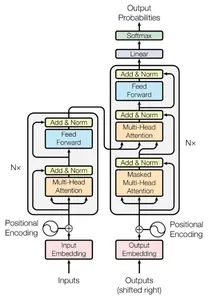
GPT-3 Generative Pre-trained Transformer 3 es una arquitectura de modelo de lenguaje innovadora que ha transformado la generación y comprensión del lenguaje natural. El modelo Transformer es la base de la arquitectura GPT-3, que incorpora varios parámetros para producir un rendimiento excepcional.
La arquitectura de GPT-3
Una pila de capas de codificador de Transformador forma GPT-3. Los mecanismos de autoatención de múltiples cabezales y las redes neuronales de avance conforman cada capa. Mientras que las redes feed-forward procesan y transforman las representaciones codificadas, el mecanismo de atención permite que el modelo reconozca dependencias y relaciones entre palabras.
La principal innovación de GPT-3 es su enorme tamaño, que le permite capturar una gran cantidad de conocimiento del idioma gracias a sus asombrosos 175 mil millones de parámetros.
Implementación del Código
Puede usar la API de OpenAI para interactuar con el modelo GPT-3 de openAI. Aquí hay un ejemplo de generación de texto usando GPT-3.
import openai # Set up your OpenAI API credentials
openai.api_key = 'YOUR_API_KEY' # Define the prompt for text generation
prompt = "A quick brown fox jumps" # Make a request to GPT-3 for text generation
response = openai.Completion.create( engine="text-davinci-003", prompt=prompt, max_tokens=100, temperature=0.6
) # Retrieve the generated text from the API response
generated_text = response.choices[0].text # Print the generated text
print(generated_text)
Ajuste fino: Adaptación de modelos a nuestras necesidades
Aquí está el giro: mientras que los modelos de lenguaje pre-entrenados son prodigiosos, no son inherentemente expertos en ninguna tarea específica. Pueden tener una increíble comprensión del idioma, pero necesitan algunos ajustes en tareas como el análisis de sentimientos, la traducción de idiomas o responder preguntas sobre dominios específicos.
Poner a punto es como dar un toque final a estos modelos versátiles. Imagine tener un amigo con múltiples talentos que se destaca en varias áreas, pero necesita que domine una habilidad en particular para una ocasión especial. Les darías una formación específica en esa área, ¿no? Eso es precisamente lo que hacemos con los modelos de lenguaje pre-entrenados durante el ajuste fino.
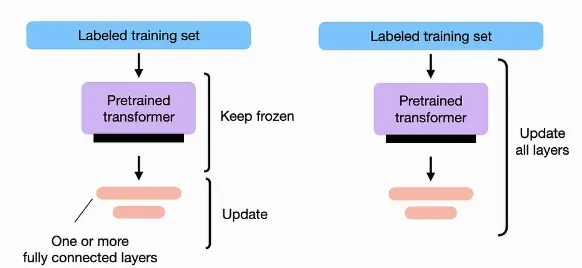
El ajuste fino implica entrenar el modelo previamente entrenado en un conjunto de datos más pequeño y específico de la tarea. Este nuevo conjunto de datos está etiquetado con ejemplos relevantes para la tarea de destino. Al exponer el modelo a estos ejemplos etiquetados, puede ajustar sus parámetros y representaciones internas para que se adapte bien a la tarea de destino.
La necesidad de un ajuste fino
Si bien los modelos de lenguaje preentrenados son notables, no son específicos de tareas por defecto. El ajuste fino es la adaptación de estos modelos de uso general para realizar tareas especializadas con mayor precisión y eficiencia. Cuando nos encontramos con una tarea específica de NLP, como el análisis de sentimientos para las reseñas de los clientes o la respuesta a preguntas para un dominio en particular, debemos ajustar el modelo previamente entrenado para comprender los matices de esa tarea y dominio específicos.
Los beneficios del ajuste fino son múltiples. En primer lugar, aprovecha los conocimientos adquiridos durante el entrenamiento previo, lo que ahorra una cantidad considerable de tiempo y recursos computacionales que, de otro modo, serían necesarios para entrenar un modelo desde cero. En segundo lugar, el ajuste fino nos permite desempeñarnos mejor en tareas específicas, ya que el modelo ahora está sintonizado con las complejidades y los matices del dominio para el que fue ajustado.
Proceso de ajuste fino: una guía paso a paso
El proceso de ajuste fino generalmente implica alimentar el conjunto de datos específico de la tarea al modelo previamente entrenado y ajustar sus parámetros a través de la retropropagación. El objetivo es minimizar la función de pérdida, que mide la diferencia entre las predicciones del modelo y las etiquetas de verdad en el terreno en el conjunto de datos. Este proceso de ajuste fino actualiza los parámetros del modelo, haciéndolo más especializado para su tarea objetivo.
Aquí veremos el proceso de ajuste fino de un modelo de lenguaje grande para el análisis de sentimientos. Usaremos la biblioteca Hugging Face Transformers, que brinda fácil acceso a modelos y utilidades previamente entrenados para realizar ajustes.
Paso 1: Cargue el modelo de lenguaje y el tokenizador preentrenados
El primer paso es cargar el modelo de lenguaje previamente entrenado y su tokenizador correspondiente. Para este ejemplo, usaremos el modelo 'base de destilería sin carcasa', una versión más ligera de BERT.
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification # Load the pre-trained tokenizer
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased') # Load the pre-trained model for sequence classification
model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-uncased')Paso 2: preparar el conjunto de datos de análisis de opinión
Necesitamos un conjunto de datos etiquetado con muestras de texto y los sentimientos correspondientes para el análisis de sentimientos. Vamos a crear un pequeño conjunto de datos con fines ilustrativos:
texts = ["I loved the movie. It was great!", "The food was terrible.", "The weather is okay."]
sentiments = ["positive", "negative", "neutral"]
A continuación, usaremos el tokenizador para convertir las muestras de texto en identificadores de token y las máscaras de atención que requiere el modelo.
# Tokenize the text samples
encoded_texts = tokenizer(texts, padding=True, truncation=True, return_tensors='pt') # Extract the input IDs and attention masks
input_ids = encoded_texts['input_ids']
attention_mask = encoded_texts['attention_mask'] # Convert the sentiment labels to numerical form
sentiment_labels = [sentiments.index(sentiment) for sentiment in sentiments]
Paso 3: agregar un encabezado de clasificación personalizado
El modelo de lenguaje preentrenado en sí mismo no incluye un encabezado de clasificación. Debemos agregar uno al modelo para realizar el análisis de sentimiento. En este caso, agregaremos una capa lineal simple.
import torch.nn as nn # Add a custom classification head on top of the pre-trained model
num_classes = len(set(sentiment_labels))
classification_head = nn.Linear(model.config.hidden_size, num_classes) # Replace the pre-trained model's classification head with our custom head
model.classifier = classification_head
Paso 4: afinar el modelo
Con el encabezado de clasificación personalizado en su lugar, ahora podemos ajustar el modelo en el conjunto de datos de análisis de sentimiento. Usaremos el optimizador AdamW y CrossEntropyLoss como función de pérdida.
import torch.optim as optim # Define the optimizer and loss function
optimizer = optim.AdamW(model.parameters(), lr=2e-5)
criterion = nn.CrossEntropyLoss() # Fine-tune the model
num_epochs = 3
for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(input_ids, attention_mask=attention_mask, labels=torch.tensor(sentiment_labels)) loss = outputs.loss loss.backward() optimizer.step()
¿Qué es el ajuste fino de instrucciones?
El ajuste fino de instrucciones es una técnica especializada para adaptar modelos de lenguaje grandes para realizar tareas específicas basadas en instrucciones explícitas. Mientras que el ajuste fino tradicional implica entrenar a un modelo en datos específicos de la tarea, el ajuste fino de instrucción va más allá al incorporar instrucciones o demostraciones de alto nivel para guiar el comportamiento del modelo.
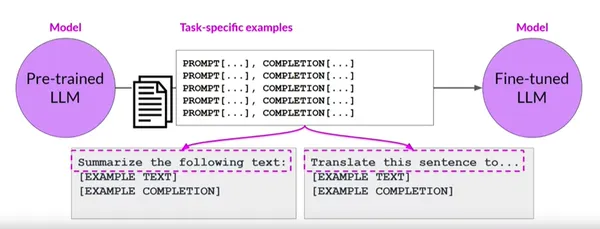
Este enfoque permite a los desarrolladores especificar los resultados deseados, alentar ciertos comportamientos o lograr un mejor control sobre las respuestas del modelo. En esta guía completa, exploraremos el concepto de perfeccionamiento de la instrucción y su implementación paso a paso.
Proceso de ajuste de instrucciones
¿Qué pasaría si pudiéramos ir más allá del ajuste fino tradicional y proporcionar instrucciones explícitas para guiar el comportamiento del modelo? El ajuste fino de instrucciones hace eso, ofreciendo un nuevo nivel de control y precisión sobre los resultados del modelo. Aquí exploraremos el proceso de instrucción ajustando modelos de lenguaje grandes para el análisis de sentimientos.
Paso 1: Cargue el modelo de lenguaje y el tokenizador preentrenados
Para comenzar, carguemos el modelo de lenguaje previamente entrenado y su tokenizador. Usaremos GPT-3, un modelo de lenguaje de última generación, para este ejemplo.
from transformers import GPT2Tokenizer, GPT2ForSequenceClassification # Load the pre-trained tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2') # Load the pre-trained model for sequence classification
model = GPT2ForSequenceClassification.from_pretrained('gpt2')
Paso 2: preparar los datos de instrucción y el conjunto de datos de análisis de opinión
Para el ajuste fino de las instrucciones, necesitamos aumentar el conjunto de datos de análisis de sentimiento con instrucciones explícitas para el modelo. Vamos a crear un pequeño conjunto de datos para la demostración:
texts = ["I loved the movie. It was great!", "The food was terrible.", "The weather is okay."]
sentiments = ["positive", "negative", "neutral"]
instructions = ["Analyze the sentiment of the text and identify if it is positive.", "Analyze the sentiment of the text and identify if it is negative.", "Analyze the sentiment of the text and identify if it is neutral."]
A continuación, tokenicemos los textos, los sentimientos y las instrucciones usando el tokenizador:
# Tokenize the texts, sentiments, and instructions
encoded_texts = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
encoded_instructions = tokenizer(instructions, padding=True, truncation=True, return_tensors='pt') # Extract input IDs, attention masks, and instruction IDs
input_ids = encoded_texts['input_ids']
attention_mask = encoded_texts['attention_mask']
instruction_ids = encoded_instructions['input_ids']
Paso 3: personalice la arquitectura del modelo con instrucciones
Para incorporar instrucciones durante el ajuste fino, necesitamos personalizar la arquitectura del modelo. Podemos hacer esto concatenando los ID de instrucción con los ID de entrada:
import torch # Concatenate instruction IDs with input IDs and adjust attention mask
input_ids = torch.cat([instruction_ids, input_ids], dim=1)
attention_mask = torch.cat([torch.ones_like(instruction_ids), attention_mask], dim=1)
Paso 4: ajuste el modelo con instrucciones
Con las instrucciones incorporadas, ahora podemos ajustar el modelo GPT-3 en el conjunto de datos aumentado. Durante el ajuste fino, las instrucciones guiarán el comportamiento del análisis de sentimiento del modelo.
import torch.optim as optim # Define the optimizer and loss function
optimizer = optim.AdamW(model.parameters(), lr=2e-5)
criterion = torch.nn.CrossEntropyLoss() # Fine-tune the model
num_epochs = 3
for epoch in range(num_epochs): optimizer.zero_grad() outputs = model(input_ids, attention_mask=attention_mask, labels=torch.tensor(sentiments)) loss = outputs.loss loss.backward() optimizer.step()
El ajuste fino de instrucciones lleva el poder del ajuste fino tradicional al siguiente nivel, permitiéndonos controlar el comportamiento de grandes modelos de lenguaje con precisión. Al proporcionar instrucciones explícitas, podemos guiar la salida del modelo y lograr resultados más precisos y personalizados.
Diferencias clave entre los dos enfoques
El ajuste fino estándar implica entrenar un modelo en un conjunto de datos etiquetados, perfeccionando sus habilidades para realizar tareas específicas de manera efectiva. Pero si queremos proporcionar instrucciones explícitas para guiar el comportamiento del modelo, entra en juego el ajuste fino de instrucciones que ofrece un control y una adaptabilidad sin igual.
Estas son las diferencias críticas entre el ajuste fino de instrucciones y el ajuste fino estándar.
- Requerimientos de datos: El ajuste fino estándar se basa en una cantidad significativa de datos etiquetados para la tarea específica, mientras que el ajuste fino de instrucciones se beneficia de la guía proporcionada por instrucciones explícitas, lo que lo hace más adaptable con datos etiquetados limitados.
- Control y Precisión: El ajuste fino de las instrucciones permite a los desarrolladores especificar los resultados deseados, alentar ciertos comportamientos o lograr un mejor control sobre las respuestas del modelo. Es posible que el ajuste fino estándar no ofrezca este nivel de control.
- Aprendiendo de las instrucciones: El ajuste fino de las instrucciones requiere un paso adicional de incorporación de instrucciones en la arquitectura del modelo, lo que no ocurre con el ajuste fino estándar.
Introducción al olvido catastrófico: un desafío peligroso
A medida que navegamos en el mundo de los ajustes finos, nos encontramos con el peligroso desafío del olvido catastrófico. Este fenómeno ocurre cuando el ajuste fino del modelo en una nueva tarea borra u 'olvida' el conocimiento adquirido durante el pre-entrenamiento. El modelo pierde su comprensión de la estructura más amplia del lenguaje, ya que se enfoca únicamente en la nueva tarea.
Imagine nuestro modelo de lenguaje como la bodega de carga de un barco llena de varios contenedores de conocimiento, cada uno de los cuales representa diferentes matices lingüísticos. Durante el entrenamiento previo, estos contenedores se llenan cuidadosamente con la comprensión del idioma. La tripulación del barco reorganiza los contenedores cuando nos acercamos a una nueva tarea y comenzamos a afinar. Vacían algunos para dejar espacio para nuevos conocimientos específicos de la tarea. Desafortunadamente, se pierde parte del conocimiento original, lo que lleva a un olvido catastrófico.
Mitigar el olvido catastrófico: salvaguardar el conocimiento
Para navegar en las aguas del olvido catastrófico, necesitamos estrategias para salvaguardar el valioso conocimiento capturado durante la formación previa. Hay dos enfoques posibles.
Ajuste fino multitarea: aprendizaje progresivo
Aquí introducimos gradualmente la nueva tarea en el modelo. Inicialmente, el modelo se enfoca en el conocimiento previo al entrenamiento e incorpora lentamente los datos de la nueva tarea, minimizando el riesgo de olvido catastrófico.
El ajuste fino de la instrucción multitarea adopta un nuevo paradigma al entrenar simultáneamente modelos de lenguaje en múltiples tareas. En lugar de ajustar el modelo para una tarea a la vez, proporcionamos instrucciones explícitas para cada tarea, guiando el comportamiento del modelo durante el ajuste.
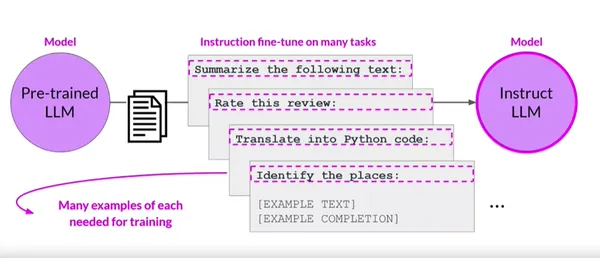
Beneficios del ajuste fino de la instrucción multitarea
- Transferencia de conocimiento: El modelo obtiene información y conocimiento de diferentes dominios mediante la capacitación en múltiples tareas, lo que mejora su comprensión general del idioma.
- Representaciones compartidas: El ajuste fino de las instrucciones multitarea permite que el modelo comparta representaciones entre tareas. Este intercambio de conocimientos mejora las capacidades de generalización del modelo.
- Eficiencia: La capacitación en múltiples tareas al mismo tiempo reduce el costo y el tiempo computacional en comparación con el ajuste fino de cada tarea individualmente.
Ajuste fino eficiente de parámetros: Transferencia de aprendizaje
Aquí congelamos ciertas capas del modelo durante el ajuste fino. Al congelar las primeras capas responsables de la comprensión fundamental del idioma, preservamos el conocimiento central mientras solo ajustamos las capas posteriores para la tarea específica.
Entendiendo PEFT
La memoria es necesaria para un ajuste fino completo para almacenar el modelo y varios otros parámetros relacionados con el entrenamiento. Debe poder asignar memoria para los estados del optimizador, los gradientes, las activaciones hacia adelante y la memoria temporal durante todo el proceso de capacitación, incluso si su computadora puede soportar el peso del modelo de cientos de gigabytes para los modelos más grandes. Estas piezas adicionales pueden ser mucho más grandes que el modelo y rápidamente superan las capacidades del hardware de consumo.
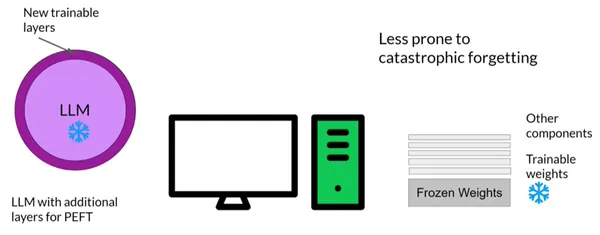
Las técnicas de ajuste fino de parámetros eficientes solo actualizan un pequeño subconjunto de parámetros en lugar del ajuste fino completo, que actualiza cada peso del modelo durante el aprendizaje supervisado. Algunas técnicas de ruta se concentran en ajustar una parte de los parámetros del modelo existente, como capas o componentes específicos, mientras congelan la mayoría de los pesos del modelo. Otros métodos agregan algunos parámetros o capas nuevos y solo ajustan los nuevos componentes; no afectan los pesos del modelo original. La mayoría, si no todos, los pesos LLM se mantienen congelados mediante PEFT. Como resultado, en comparación con el LLM original, hay muchos menos parámetros entrenados.
¿Por qué PEFT?
PEFT potencia los modelos de parámetros eficientes con un rendimiento impresionante, revolucionando el panorama de la PNL. Aquí hay algunas razones por las que usamos PEFT.
- Costos Computacionales Reducidos: PEFT requiere menos GPU y tiempo de GPU, lo que lo hace más accesible y rentable para entrenar modelos de lenguaje grandes.
- Tiempos de entrenamiento más rápidos: Con PEFT, los modelos terminan el entrenamiento más rápido, lo que permite iteraciones rápidas y una implementación más rápida en aplicaciones del mundo real.
- Requisitos de hardware más bajos: PEFT funciona de manera eficiente con GPU más pequeñas y requiere menos memoria, lo que lo hace factible para entornos con recursos limitados.
- Rendimiento de modelado mejorado: PEFT produce modelos más robustos y precisos para diversas tareas al reducir el sobreajuste.
- Almacenamiento eficiente en el espacio: Con pesos compartidos entre tareas, PEFT minimiza los requisitos de almacenamiento, optimizando la implementación y la gestión del modelo.
Ajuste fino con PEFT
Si bien congela la mayoría de los LLM preentrenados, PEFT solo se acerca al ajuste fino de algunos parámetros del modelo, lo que reduce significativamente los costos computacionales y de almacenamiento. Esto también resuelve el problema del olvido catastrófico, que se observó durante el ajuste completo de los LLM.
En regímenes de datos bajos, los enfoques PEFT también han demostrado ser superiores al ajuste fino y generalizar mejor a escenarios fuera del dominio.
Cargando el modelo
Carguemos el modelo opt-6.7b aquí; su peso en el Hub es de aproximadamente 13 GB con precisión media (float16). Requerirá unos 7GB de memoria si los cargamos en 8 bits.
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import torch
import torch.nn as nn
import bitsandbytes as bnb
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM model = AutoModelForCausalLM.from_pretrained( "facebook/opt-6.7b", load_in_8bit=True, device_map='auto',
) tokenizer = AutoTokenizer.from_pretrained("facebook/opt-6.7b")
Postprocesamiento en el modelo
Congelemos todas nuestras capas y emitamos la norma de capa en float32 para lograr estabilidad antes de aplicar un procesamiento posterior al modelo de 8 bits para habilitar el entrenamiento. También proyectamos la salida de la capa final en float32 por las mismas razones.
for param in model.parameters(): param.requires_grad = False # freeze the model - train adapters later if param.ndim == 1: param.data = param.data.to(torch.float32) model.gradient_checkpointing_enable() # reduce number of stored activations
model.enable_input_require_grads() class CastOutputToFloat(nn.Sequential): def forward(self, x): return super().forward(x).to(torch.float32)
model.lm_head = CastOutputToFloat(model.lm_head)
Usando LoRA
Cargue un PeftModel, usaremos adaptadores de bajo rango (LoRA) usando la función de utilidad get_peft_model de Peft.
La función calcula e imprime el número total de parámetros entrenables y todos los parámetros en un modelo dado. Junto con el porcentaje de parámetros entrenables, brinda una descripción general de la complejidad del modelo y los requisitos de recursos para el entrenamiento.
def print_trainable_parameters(model): # Prints the number of trainable parameters in the model. trainable_params = 0 all_param = 0 for _, param in model.named_parameters(): all_param += param.numel() if param.requires_grad: trainable_params += param.numel() print( f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}" ) Esto utiliza la biblioteca Peft para crear un modelo LoRA con ajustes de configuración específicos, incluidos abandono, sesgo y tipo de tarea. Luego obtiene los parámetros entrenables del modelo e imprime el número total de parámetros entrenables y todos los parámetros, junto con el porcentaje de parámetros entrenables.
from peft import LoraConfig, get_peft_model config = LoraConfig( r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM"
) model = get_peft_model(model, config)
print_trainable_parameters(model)
Entrenando el modelo
Esto utiliza las bibliotecas Hugging Face Transformers and Datasets para entrenar un modelo de lenguaje en un conjunto de datos determinado. Utiliza la clase 'transformers.Trainer' para definir la configuración de entrenamiento, incluido el tamaño del lote, la tasa de aprendizaje y otras configuraciones relacionadas con el entrenamiento, y luego entrena el modelo en el conjunto de datos especificado.
import transformers
from datasets import load_dataset
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples['quote']), batched=True) trainer = transformers.Trainer( model=model, train_dataset=data['train'], args=transformers.TrainingArguments( per_device_train_batch_size=4, gradient_accumulation_steps=4, warmup_steps=100, max_steps=200, learning_rate=2e-4, fp16=True, logging_steps=1, output_dir='outputs' ), data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
Aplicaciones del mundo real de LLM de ajuste fino
Examinaremos más de cerca algunos emocionantes casos de uso del mundo real de ajuste fino de modelos de lenguaje grande, donde los avances de NLP están transformando industrias y potenciando soluciones innovadoras.
- Análisis de los sentimientos: El ajuste fino de los modelos de lenguaje para el análisis de sentimientos permite a las empresas analizar los comentarios de los clientes, las reseñas de productos y los sentimientos de las redes sociales para comprender la percepción del público y tomar decisiones basadas en datos.
- Reconocimiento de entidad nombrada (NER): Al ajustar los modelos para NER, las entidades como nombres, fechas y ubicaciones se pueden extraer automáticamente del texto, lo que permite aplicaciones como la recuperación de información y la categorización de documentos.
- Traducción de idiomas: Los modelos ajustados se pueden utilizar para la traducción automática, rompiendo las barreras del idioma y permitiendo una comunicación fluida en diferentes idiomas.
- Chatbots y Asistentes Virtuales: Al ajustar los modelos de lenguaje, los chatbots y los asistentes virtuales pueden proporcionar respuestas más precisas y contextualmente relevantes, mejorando las experiencias de los usuarios.
- Análisis de textos médicos: Los modelos ajustados pueden ayudar a analizar documentos médicos, registros de salud electrónicos y literatura médica, ayudando a los profesionales de la salud en el diagnóstico y la investigación.
- Análisis financiero: Los modelos de lenguaje de ajuste fino se pueden utilizar en el análisis del sentimiento financiero, la predicción de tendencias del mercado y la generación de informes financieros a partir de grandes conjuntos de datos.
- Análisis de Documentos Legales: Los modelos ajustados pueden ayudar en el análisis de documentos legales, la revisión de contratos y el resumen automatizado de documentos, lo que ahorra tiempo y esfuerzo a los profesionales legales.
En el mundo real, el ajuste fino de los modelos lingüísticos grandes ha encontrado aplicaciones en diversas industrias, lo que permite a las empresas e investigadores aprovechar las capacidades de NLP para una amplia gama de tareas, lo que lleva a una mayor eficiencia, una mejor toma de decisiones y experiencias de usuario enriquecidas.
Conclusión
El ajuste fino de modelos de lenguajes grandes ha surgido como una técnica poderosa para adaptar estos modelos pre-entrenados a tareas y dominios específicos. A medida que avanza el campo de la PNL, los ajustes finos seguirán siendo cruciales para desarrollar aplicaciones y modelos de lenguaje de vanguardia.
Esta completa guía nos ha llevado en un viaje esclarecedor a través del mundo del ajuste fino de los grandes modelos de lenguaje. Comenzamos por comprender la importancia del ajuste fino, que complementa la capacitación previa y permite que los modelos lingüísticos se destaquen en tareas específicas. Elegir el modelo pre-entrenado correcto es crucial, y exploramos modelos populares. Nos sumergimos en técnicas avanzadas como el ajuste fino multitarea, el ajuste fino eficiente de parámetros y el ajuste fino de instrucciones, que superan los límites de la eficiencia y el control en la PNL. Además, exploramos aplicaciones del mundo real, siendo testigos de cómo los modelos ajustados revolucionan el análisis de sentimientos, la traducción de idiomas, los asistentes virtuales, el análisis médico, las predicciones financieras y más.
Puntos clave
- El ajuste fino complementa el entrenamiento previo, potenciando los modelos de lenguaje para tareas específicas, lo que lo hace crucial para las aplicaciones de vanguardia.
- Las técnicas avanzadas como la multitarea, la eficiencia de parámetros y el ajuste fino de instrucciones superan los límites de NLP, mejorando el rendimiento y la adaptabilidad del modelo.
- Adoptar el ajuste fino revoluciona las aplicaciones del mundo real, transformando la forma en que entendemos los datos textuales, desde el análisis de sentimientos hasta los asistentes virtuales.
Con el poder del ajuste fino, navegamos por el vasto océano del lenguaje con precisión y creatividad, transformando la forma en que interactuamos y entendemos el mundo del texto. Entonces, aproveche las posibilidades y libere todo el potencial de los modelos de lenguaje a través del ajuste fino, donde el futuro de la PNL se forma con cada modelo ajustado con precisión.
Preguntas frecuentes
R1: El ajuste fino es la adaptación de modelos de lenguaje previamente entrenados a tareas y dominios específicos. Complementa el entrenamiento previo y permite que los modelos se destaquen en contextos particulares, haciéndolos más poderosos y efectivos para aplicaciones del mundo real.
A2: El ajuste fino de tareas múltiples implica entrenar un modelo en múltiples tareas relacionadas simultáneamente, mejorando su capacidad para transferir conocimientos entre tareas. El ajuste fino de instrucciones introduce mensajes o instrucciones durante el entrenamiento, lo que permite un control detallado sobre el comportamiento del modelo.
R3: El ajuste fino eficiente de los parámetros reduce los recursos informáticos necesarios, lo que lo hace más accesible para entornos de bajos recursos y mantiene un rendimiento comparable al ajuste fino estándar.
R4: Si bien el ajuste fino puede dar lugar a un sobreajuste en conjuntos de datos pequeños, las técnicas como la detención anticipada, el abandono y el aumento de datos pueden mitigar este riesgo y promover la generalización a nuevos datos.
R5: En escenarios con datos etiquetados limitados, transferir el aprendizaje de tareas relacionadas o aprovechar el entrenamiento previo en conjuntos de datos similares puede ayudar a mejorar el rendimiento y la adaptabilidad del modelo. Además, las técnicas de aumento de datos y aprendizaje de pocos disparos pueden ser útiles para escenarios de bajos recursos.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/08/fine-tuning-large-language-models/

