Introducción
La máquina de vectores de soporte (SVM) de una clase es una variante de la SVM tradicional. Está diseñado específicamente para detectar anomalías. Su objetivo principal es localizar casos que se desvíen notablemente de la norma. A diferencia de lo convencional Aprendizaje automático (Machine learning & LLM) Modelos centrados en la clasificación binaria o multiclase, el SVM de una clase se especializa en la detección de valores atípicos o novedosos dentro de conjuntos de datos. En este artículo, aprenderá en qué se diferencia la máquina de vectores de soporte (SVM) de clase única de la SVM tradicional. También aprenderá cómo funciona OC-SVM y cómo implementarlo. También aprenderá sobre sus hiperparámetros.
OBJETIVOS DE APRENDIZAJE
- Para entender las anomalías
- Obtenga más información sobre SVM de una clase
- Comprenda en qué se diferencia de la máquina de vectores de soporte (SVM) tradicional
- Hiperparámetros de OC-SVM en Sklearn
- Cómo detectar anomalías usando OC-SVM
- Casos de uso de SVM de una clase
Tabla de contenidos.
Comprender las anomalías
Las anomalías son observaciones o instancias que se desvían significativamente del comportamiento normal de un conjunto de datos. Estas desviaciones pueden manifestarse de diversas formas, como valores atípicos, ruido, errores o patrones inesperados. Las anomalías suelen ser fascinantes porque pueden representar conocimientos valiosos. Podrían proporcionar información como la identificación de transacciones fraudulentas, la detección de mal funcionamiento de los equipos o el descubrimiento de fenómenos novedosos. La detección de valores atípicos y de novedades identifica anomalías y observaciones anormales o poco comunes.
Lea también Una guía integral sobre la detección de anomalías
SVM de una clase
Introducción a las máquinas de vectores de soporte (SVM)
Máquinas de vectores de soporte (SVM) son un popular algoritmo de aprendizaje supervisado para tareas de clasificación y regresión. Las SVM funcionan encontrando el hiperplano óptimo que separa diferentes clases en el espacio de características y al mismo tiempo maximiza el margen entre ellas. Este hiperplano se basa en un subconjunto de puntos de datos de entrenamiento llamados vectores de soporte.
SVM de una clase frente a SVM tradicional
- Las SVM de una clase representan una variante del algoritmo SVM tradicional empleado principalmente para tareas de detección de novedades y valores atípicos. A diferencia de las SVM tradicionales, que manejan tareas de clasificación binaria, One-Class SVM se entrena exclusivamente en puntos de datos de una única clase, conocida como clase objetivo. SVM de una clase tiene como objetivo aprender una función de decisión o límite que encapsule la clase objetivo en el espacio de características, modelando efectivamente el comportamiento normal de los datos.
- Las SVM tradicionales tienen como objetivo encontrar un límite de decisión que maximice el margen entre diferentes clases, permitiendo una clasificación óptima de nuevos puntos de datos. Por otro lado, One-Class SVM busca encontrar un límite que encapsule la clase objetivo y al mismo tiempo minimice el riesgo de incluir valores atípicos o instancias novedosas fuera de este límite.
- Las SVM tradicionales requieren datos etiquetados con instancias de múltiples clases, lo que las hace adecuadas para tareas de clasificación supervisadas. Por el contrario, una SVM One-Class permite la aplicación en escenarios donde solo están disponibles datos de la clase objetivo, lo que la hace muy adecuada para tareas de detección de anomalías y detección de novedades sin supervisión.
Más información: Clasificación de una clase utilizando máquinas de vectores de soporte
Ambos difieren en sus formulaciones de margen suave y en la forma en que las usan:
(El margen suave en SVM se utiliza para permitir cierto grado de clasificación errónea)
SVM de una clase tiene como objetivo descubrir un hiperplano con margen máximo dentro del espacio de características separando los datos mapeados del origen. En un conjunto de datos Dn = {x1,. . . , xn} con xi ∈ X (xi es una característica) y n dimensiones:
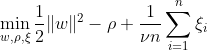
Esta ecuación representa la formulación del problema principal para OC-SVM, donde w es el hiperplano de separación, ρ es el desplazamiento desde el origen y ξi son variables de holgura. Permiten un margen suave pero penalizan las violaciones ξi. Un hiperparámetro ν ∈ (0, 1] controla el efecto de la variable de holgura y debe ajustarse según las necesidades. El objetivo es minimizar la norma de w mientras se penalizan las desviaciones del margen. Además, esto permite que una fracción de los datos caen dentro del margen o en el lado equivocado del hiperplano.
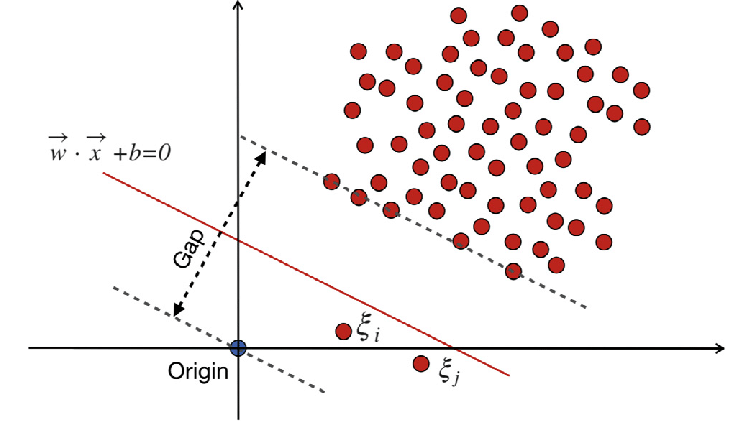
WX + b =0 es el límite de decisión y las variables de holgura penalizan las desviaciones.
Máquinas de vectores de soporte tradicionales (SVM)
Las máquinas de vectores de soporte tradicionales (SVM) utilizan la formulación de margen suave para errores de clasificación errónea. O utilizan puntos de datos que se encuentran dentro del margen o en el lado equivocado del límite de decisión.
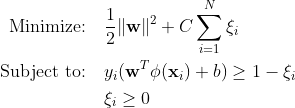
Lugar:
w es el vector de peso.
b es el término de sesgo.
ξi son variables de holgura que permiten una optimización del margen suave.
C es el parámetro de regularización que controla el equilibrio entre maximizar el margen y minimizar el error de clasificación.
ϕ (xi) representa la función de mapeo de características.
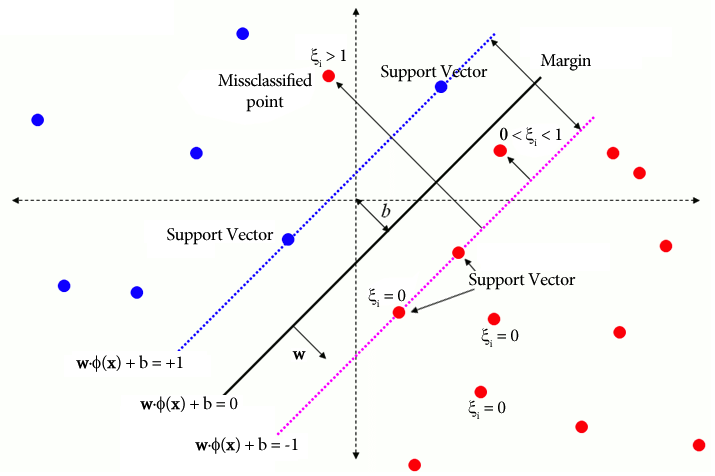
En SVM tradicional, un método de aprendizaje supervisado que se basa en etiquetas de clases para la separación incorpora variables de holgura para permitir un cierto nivel de clasificación errónea. El objetivo principal de SVM es separar puntos de datos de distintas clases utilizando el límite de decisión WX + b = 0. El valor de las variables de holgura varía según la ubicación de los puntos de datos: se establecen en 0 si los puntos de datos están ubicados más allá de los márgenes. Si el punto de datos reside dentro del margen, las variables de holgura oscilan entre 0 y 1 y se extienden más allá del margen opuesto si son mayores que 1.
Tanto las SVM tradicionales como las SVM One-Class con formulaciones de margen suave tienen como objetivo minimizar la norma del vector de peso. Aún así, difieren en sus objetivos y en cómo manejan los errores de clasificación o las desviaciones del límite de decisión. Las SVM tradicionales optimizan la precisión de la clasificación para evitar el sobreajuste, mientras que las SVM de una clase se centran en modelar la clase objetivo y controlar la proporción de valores atípicos o instancias novedosas.
Lea también La guía AZ para máquinas de vectores de soporte
Hiperparámetros importantes en SVM de una clase
- nú: Este es un hiperparámetro crucial en One-Class SVM, que controla la proporción de valores atípicos permitidos. Establece un límite superior para la fracción de errores de entrenamiento y un límite inferior para la fracción de vectores de soporte. Normalmente oscila entre 0 y 1, donde los valores más bajos implican un margen más estricto y pueden capturar menos valores atípicos, mientras que los valores más altos son más permisivos. El valor predeterminado es 0.5.
- núcleo: La función del núcleo determina el tipo de límite de decisión que utiliza SVM. Las opciones comunes incluyen "lineal", "rbf" (función de base radial gaussiana), "poli" (polinomio) y "sigmoide". El núcleo 'rbf' se utiliza a menudo porque puede capturar de forma eficaz relaciones complejas no lineales.
- gama: Este es un parámetro para hiperplanos no lineales. Define cuánta influencia tiene un solo ejemplo de entrenamiento. Cuanto mayor sea el valor gamma, más cerca deben estar los demás ejemplos para verse afectados. Este parámetro es específico del kernel RBF y normalmente está configurado en 'auto', cuyo valor predeterminado es 1/n_features.
- parámetros del kernel (grado, coef0): Estos parámetros son para núcleos polinomiales y sigmoideos. 'grado' es el grado de la función central polinómica y 'coef0' es el término independiente de la función central. Es posible que sea necesario ajustar estos parámetros para lograr un rendimiento óptimo.
- tol: Este es el criterio de parada. El algoritmo se detiene cuando la brecha de dualidad es menor que la tolerancia. Es un parámetro que controla la tolerancia del criterio de parada.
Principio de funcionamiento de SVM de clase única
Funciones del kernel en SVM de clase única
Las funciones del kernel desempeñan un papel crucial en One-Class SVM al permitir que el algoritmo opere en espacios de características de dimensiones superiores sin calcular explícitamente las transformaciones. En One-Class SVM, al igual que en las SVM tradicionales, las funciones del kernel se utilizan para medir la similitud entre pares de puntos de datos en el espacio de entrada. Las funciones de kernel comunes utilizadas en One-Class SVM incluyen kernels gaussianos (RBF), polinomiales y sigmoideos. Estos núcleos asignan el espacio de entrada original a un espacio de dimensiones superiores, donde los puntos de datos se vuelven linealmente separables o exhiben patrones más distintos, lo que facilita el aprendizaje. Al elegir una función del kernel adecuada y ajustar sus parámetros, One-Class SVM puede capturar de manera efectiva relaciones complejas y estructuras no lineales en los datos, mejorando su capacidad para detectar anomalías o valores atípicos.
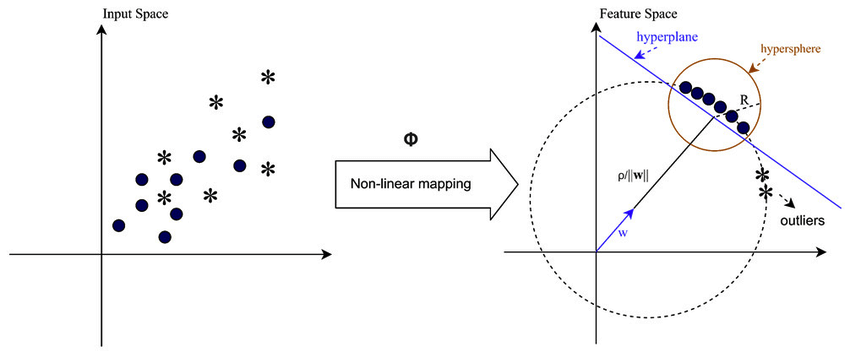
En los casos en los que los datos no son separables linealmente, como cuando se trata de patrones complejos o superpuestos, las máquinas de vectores de soporte (SVM) pueden emplear un núcleo de función de base radial (RBF) para segregar los valores atípicos del resto de los datos de manera efectiva. El kernel RBF transforma los datos de entrada en un espacio de características de mayor dimensión que se puede separar mejor.
Vectores de margen y soporte
El concepto de vectores de margen y soporte en One-Class SVM es similar al de las SVM tradicionales. El margen se refiere a la región entre el límite de decisión (hiperplano) y los puntos de datos más cercanos de cada clase. En One-Class SVM, el margen representa la región donde se encuentran la mayoría de los puntos de datos que pertenecen a la clase objetivo. Maximizar el margen es crucial para One-Class SVM, ya que ayuda a generalizar bien los nuevos puntos de datos y mejora la solidez del modelo. Los vectores de soporte son los puntos de datos que se encuentran en el margen o dentro del mismo y contribuyen a definir el límite de decisión.
En One-Class SVM, los vectores de soporte son los puntos de datos de la clase objetivo más cercanos al límite de decisión. Estos vectores de soporte juegan un papel importante en la determinación de la forma y orientación del límite de decisión y, por tanto, en el rendimiento general del modelo SVM One-Class. Al identificar los vectores de soporte, One-Class SVM aprende efectivamente la representación de la clase objetivo en el espacio de características y construye un límite de decisión que encapsula la mayoría de los puntos de datos mientras minimiza el riesgo de incluir valores atípicos o instancias novedosas.
¿Cómo se pueden detectar anomalías utilizando SVM de clase única?
Detección de anomalías utilizando SVM (máquina de vectores de soporte) de una clase mediante técnicas de detección de novedades y de detección de valores atípicos:
Detección de valores atípicos
Implica identificar observaciones en los datos de entrenamiento que se desvían significativamente del resto, a menudo denominadas valores atípicos. Estimadores para detección de valores atípicos El objetivo es ajustar las áreas donde los datos de entrenamiento están más concentrados, sin tener en cuenta estas observaciones desviadas.
from sklearn.svm import OneClassSVM
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from sklearn.inspection import DecisionBoundaryDisplay
# Load data
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
# Define estimators (One-Class SVM)
estimators_hard_margin = {
"Hard Margin OCSVM": OneClassSVM(nu=0.01, gamma=0.35), # Very small nu for hard margin
}
estimators_soft_margin = {
"Soft Margin OCSVM": OneClassSVM(nu=0.25, gamma=0.35), # Nu between 0 and 1 for soft margin
}
# Plotting setup
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
colors = ["tab:blue", "tab:orange", "tab:red"]
legend_lines = []
# Hard Margin OCSVM
ax = axs[0]
for color, (name, estimator) in zip(colors, estimators_hard_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Hard Margin Outlier detection (wine recognition)",
)
# Soft Margin OCSVM
ax = axs[1]
legend_lines = []
for color, (name, estimator) in zip(colors, estimators_soft_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Soft Margin Outlier detection (wine recognition)",
)
plt.tight_layout()
plt.show()
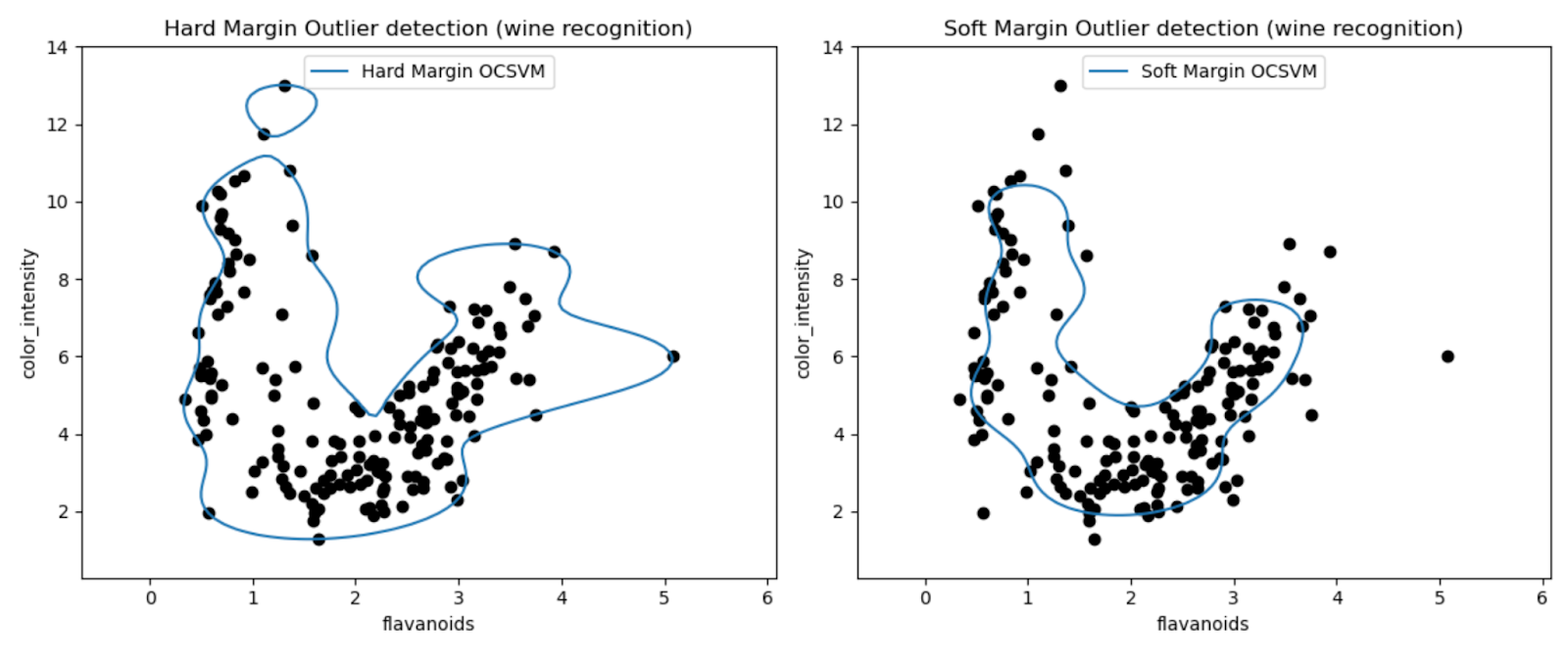
Los gráficos nos permiten inspeccionar visualmente el rendimiento de los modelos SVM de clase única en la detección de valores atípicos en el conjunto de datos de Wine.
Al comparar los resultados de los modelos SVM One-Class de margen duro y margen suave, podemos observar cómo la elección de la configuración del margen (parámetro nu) afecta la detección de valores atípicos.
El modelo de margen estricto con un valor nu muy pequeño (0.01) probablemente dé como resultado un límite de decisión más conservador. Envuelve estrechamente la mayoría de los puntos de datos y potencialmente clasifica menos puntos como valores atípicos.
Por el contrario, el modelo de margen blando con un valor nu mayor (0.35) probablemente dé como resultado un límite de decisión más flexible. Permitiendo así un margen más amplio y potencialmente capturando más valores atípicos.
Detección de novedades
Por otro lado, lo aplicamos cuando los datos de entrenamiento están libres de valores atípicos y el objetivo es determinar si una nueva observación es rara, es decir, muy diferente de las observaciones conocidas. Esta última observación aquí se llama novedad.
import numpy as np
from sklearn import svm
# Generate train data
np.random.seed(30)
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
import matplotlib.font_manager
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, ax = plt.subplots()
# generate grid for the boundary display
xx, yy = np.meshgrid(np.linspace(-5, 5, 10), np.linspace(-5, 5, 10))
X = np.concatenate([xx.reshape(-1, 1), yy.reshape(-1, 1)], axis=1)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
cmap="PuBu",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
levels=[0, 10000],
colors="palevioletred",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contour",
ax=ax,
levels=[0],
colors="darkred",
linewidths=2,
)
s = 40
b1 = ax.scatter(X_train[:, 0], X_train[:, 1], c="white", s=s, edgecolors="k")
b2 = ax.scatter(X_test[:, 0], X_test[:, 1], c="blueviolet", s=s, edgecolors="k")
c = ax.scatter(X_outliers[:, 0], X_outliers[:, 1], c="gold", s=s, edgecolors="k")
plt.legend(
[mlines.Line2D([], [], color="darkred"), b1, b2, c],
[
"learned frontier",
"training observations",
"new regular observations",
"new abnormal observations",
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11),
)
ax.set(
xlabel=(
f"error train: {n_error_train}/200 ; errors novel regular: {n_error_test}/40 ;"
f" errors novel abnormal: {n_error_outliers}/40"
),
title="Novelty Detection",
xlim=(-5, 5),
ylim=(-5, 5),
)
plt.show()

- Genere un conjunto de datos sintéticos con dos grupos de puntos de datos. Haga esto generándolos con una distribución normal alrededor de dos centros diferentes: (2, 2) y (-2, -2) para datos de tren y prueba. Genere aleatoriamente veinte puntos de datos de manera uniforme dentro de una región cuadrada que va de -4 a 4 en ambas dimensiones. Estos puntos de datos representan observaciones anormales o valores atípicos que se desvían significativamente del comportamiento normal observado en los datos del tren y de la prueba.
- La frontera aprendida se refiere al límite de decisión aprendido por el modelo SVM de una clase. Este límite separa las regiones del espacio de características donde el modelo considera que los puntos de datos son normales de los valores atípicos.
- El gradiente de color de azul a blanco en los contornos representa los distintos grados de confianza o certeza que el modelo SVM de clase única asigna a diferentes regiones en el espacio de características, y los tonos más oscuros indican una mayor confianza al clasificar los puntos de datos como "normales". El azul oscuro indica regiones con fuertes indicios de ser "normales" según la función de decisión del modelo. A medida que el color se vuelve más claro en el contorno, el modelo está menos seguro de clasificar los puntos de datos como "normales".
- El gráfico representa visualmente cómo el modelo SVM de clase única puede distinguir entre observaciones regulares y anormales. El límite de decisión aprendido separa las regiones de observaciones normales y anormales. SVM de una clase para la detección de novedades demuestra su eficacia a la hora de identificar observaciones anormales en un conjunto de datos determinado.
Para nu=0.5:
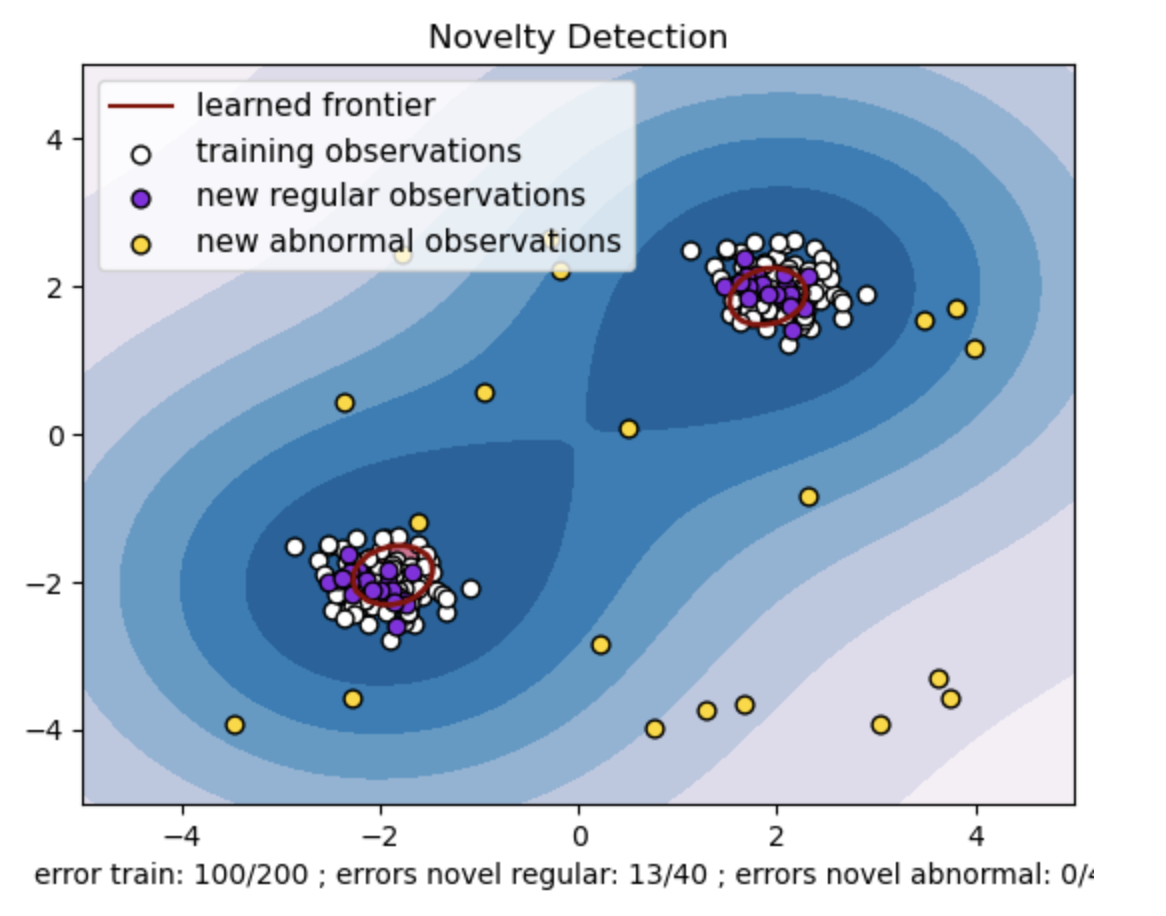
El valor "nu" en SVM de una clase juega un papel crucial en el control de la fracción de valores atípicos tolerados por el modelo. Afecta directamente la capacidad del modelo para identificar anomalías y, por tanto, influye en la predicción. Podemos ver que el modelo permite clasificar erróneamente 100 puntos de entrenamiento. Un valor más bajo de nu implica una restricción más estricta sobre la fracción permitida de valores atípicos. La elección de nu influye en el rendimiento del modelo a la hora de detectar anomalías. También requiere un ajuste cuidadoso basado en los requisitos específicos de la aplicación y las características del conjunto de datos.
Para gamma=0.5 y nu=0.5
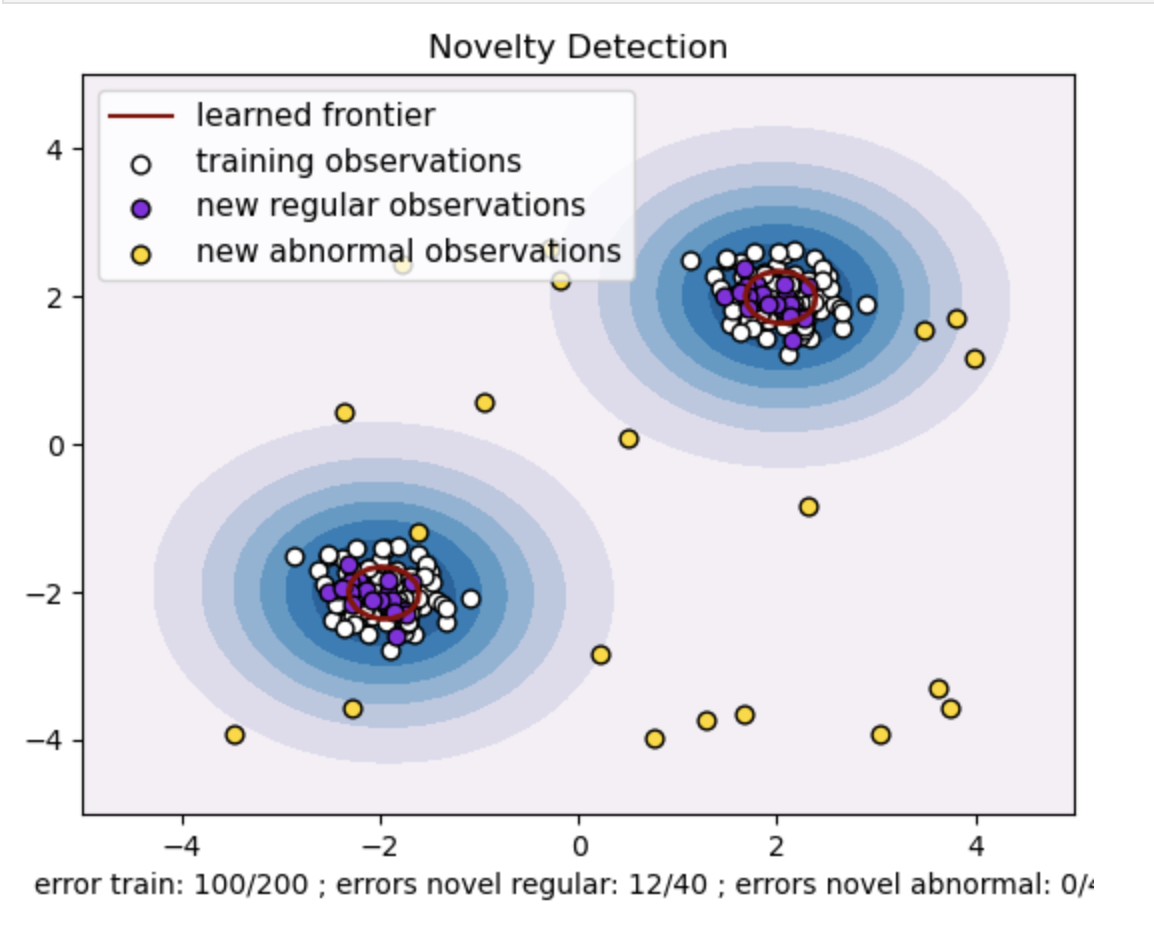
En SVM de una clase, el hiperparámetro gamma representa el coeficiente del núcleo para el núcleo 'rbf'. Este hiperparámetro influye en la forma del límite de decisión y, en consecuencia, afecta el rendimiento predictivo del modelo.
Cuando gamma es alta, un único ejemplo de entrenamiento limita su influencia a sus inmediaciones. Esto crea un límite de decisión más localizado. Por lo tanto, los puntos de datos deben estar más cerca de los vectores de soporte para pertenecer a la misma clase.
Conclusión
El uso de One-Class SVM para la detección de anomalías y la detección de valores atípicos y novedosos ofrece una solución sólida en varios dominios. Esto ayuda en escenarios donde los datos de anomalías etiquetadas son escasos o no están disponibles. Por lo tanto, es particularmente valioso en aplicaciones del mundo real donde las anomalías son raras y difíciles de definir explícitamente. Sus casos de uso se extienden a diversos dominios, como la ciberseguridad y el diagnóstico de fallas, donde las anomalías tienen consecuencias. Sin embargo, si bien One-Class SVM presenta numerosos beneficios, es necesario configurar los hiperparámetros de acuerdo con los datos para obtener mejores resultados, lo que a veces puede resultar tedioso.
Preguntas frecuentes
A. One-Class SVM construye un hiperplano (o una hiperesfera en dimensiones superiores) que encapsula los puntos de datos normales. Este hiperplano está posicionado para maximizar el margen entre los datos normales y el límite de decisión. Los puntos de datos se clasifican como normales (dentro del límite) o anomalías (fuera del límite) durante las pruebas o la inferencia.
R. La SVM de una clase es ventajosa porque no requiere datos etiquetados para anomalías durante el entrenamiento. Puede aprender de un conjunto de datos que contiene solo instancias regulares, lo que lo hace adecuado para escenarios donde las anomalías son raras y resulta difícil obtener ejemplos etiquetados para el entrenamiento.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2024/03/one-class-svm-for-anomaly-detection/

