
Imagen del autor
Uno de los campos que sustenta la ciencia de datos es el aprendizaje automático. Entonces, si desea ingresar a la ciencia de datos, comprender el aprendizaje automático es uno de los primeros pasos que debe dar.
¿Pero por dónde empiezas? Empiece por comprender la diferencia entre los dos tipos principales de algoritmos de aprendizaje automático. Sólo después de eso podremos hablar de algoritmos individuales que deberían estar en su lista de prioridades para aprender como principiante.
La principal distinción entre los algoritmos se basa en cómo aprenden.

Imagen del autor
Algoritmos de aprendizaje supervisado están entrenados en un conjunto de datos etiquetado. Este conjunto de datos sirve como supervisión (de ahí el nombre) para el aprendizaje porque algunos datos que contiene ya están etiquetados como respuesta correcta. Con base en esta información, el algoritmo puede aprender y aplicar ese aprendizaje al resto de los datos.
Por otra parte, algoritmos de aprendizaje no supervisados aprender en un conjunto de datos sin etiquetar, lo que significa que se dedican a encontrar patrones en los datos sin que los humanos den instrucciones.
Puedes leer más detalladamente sobre algoritmos de aprendizaje automático y tipos de aprendizaje.
También existen otros tipos de aprendizaje automático, pero no para principiantes.
Los algoritmos se emplean para resolver dos problemas principales distintos dentro de cada tipo de aprendizaje automático.
Nuevamente, hay algunas tareas más, pero no son para principiantes.

Imagen del autor
Tareas de aprendizaje supervisadas
Regresión es la tarea de predecir una valor numérico, lo cual se conoce como variable de resultado continua o variable dependiente. La predicción se basa en la(s) variable(s) predictora(s) o la(s) variable(s) independiente(s).
Piense en predecir los precios del petróleo o la temperatura del aire.
Clasificación se utiliza para predecir la categoría (clase) de los datos de entrada. El variable de resultado aquí está categórico o discreto.
Piense en predecir si el correo es spam o no o si el paciente contraerá una determinada enfermedad o no.
Tareas de aprendizaje no supervisadas
Clustering significa dividir datos en subconjuntos o grupos. El objetivo es agrupar los datos de la forma más natural posible. Esto significa que los puntos de datos dentro del mismo grupo son más similares entre sí que a los puntos de datos de otros grupos.
Reducción de dimensionalidad se refiere a reducir el número de variables de entrada en un conjunto de datos. Básicamente significa reducir el conjunto de datos a muy pocas variables sin dejar de capturar su esencia.
Aquí hay una descripción general de los algoritmos que cubriré.
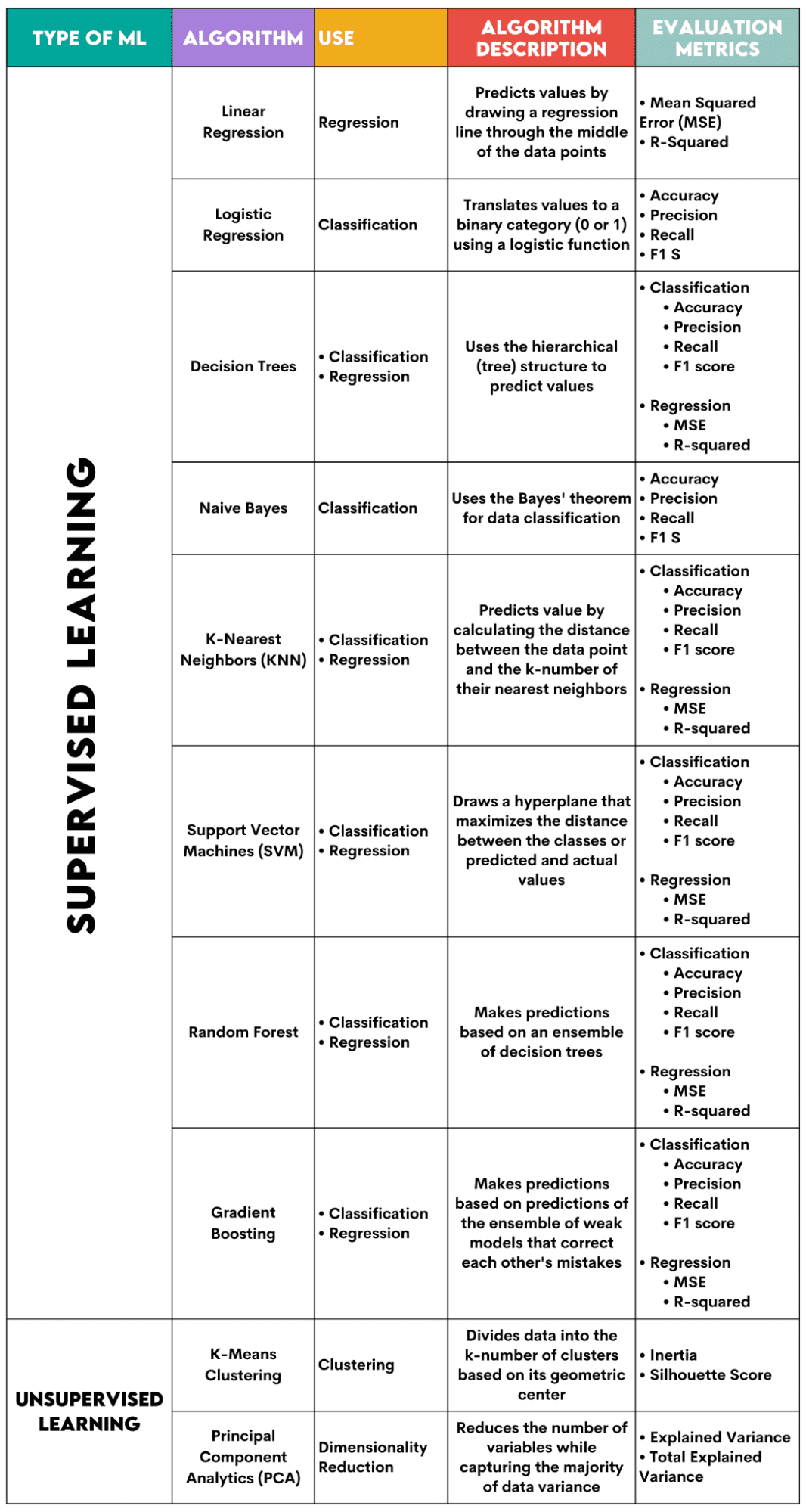
Imagen del autor
Algoritmos de aprendizaje supervisado
Al elegir el algoritmo para su problema, es importante saber para qué tarea se utiliza el algoritmo.
Como científico de datos, probablemente aplicará estos algoritmos en Python utilizando el biblioteca scikit-learn. Aunque hace (casi) todo por ti, es recomendable que conozcas al menos los principios generales del funcionamiento interno de cada algoritmo.
Finalmente, una vez entrenado el algoritmo, debes evaluar su rendimiento. Para eso, cada algoritmo tiene algunas métricas estándar.
1. Regresión lineal
Usado para: Regresión
Descripción: La regresión lineal dibuja una línea recta llamada línea de regresión entre las variables. Esta línea pasa aproximadamente por el medio de los puntos de datos, minimizando así el error de estimación. Muestra el valor previsto de la variable dependiente en función del valor de las variables independientes.
Métricas de evaluación:
- Error cuadrático medio (MSE): Representa el promedio del error al cuadrado, siendo el error la diferencia entre los valores reales y previstos. Cuanto menor sea el valor, mejor será el rendimiento del algoritmo.
- R-cuadrado: Representa el porcentaje de varianza de la variable dependiente que puede predecir la variable independiente. Para esta medida, debes esforzarte por acercarte lo más posible a 1.
2. Regresión logística
Usado para: Clasificación
Descripción: Utiliza un función logística para traducir los valores de datos a una categoría binaria, es decir, 0 o 1. Esto se hace usando el umbral, generalmente establecido en 0.5. El resultado binario hace que este algoritmo sea perfecto para predecir resultados binarios, como SÍ/NO, VERDADERO/FALSO o 0/1.
Métricas de evaluación:
- Precisión: La relación entre las predicciones correctas y totales. Cuanto más cerca de 1, mejor.
- Precisión: la medida de la precisión del modelo en predicciones positivas; Se muestra como la relación entre las predicciones positivas correctas y el total de resultados positivos esperados. Cuanto más cerca de 1, mejor.
- Recuerde: también mide la precisión del modelo en predicciones positivas. Se expresa como una relación entre las predicciones positivas correctas y el total de observaciones realizadas en la clase. Lea más sobre estas métricas esta página.
- Puntuación F1: La media armónica de la recuperación y precisión del modelo. Cuanto más cerca de 1, mejor.
3. Árboles de decisión
Usado para: Regresión y clasificación
Descripción: Árboles de decisión Son algoritmos que utilizan la estructura jerárquica o de árbol para predecir un valor o una clase. El nodo raíz representa todo el conjunto de datos, que luego se ramifica en nodos de decisión, se bifurca y sale según los valores de las variables.
Métricas de evaluación:
- Exactitud, precisión, recuperación y puntuación F1 -> para clasificación
- MSE, R cuadrado -> para regresión
4. Bayes ingenuo
Usado para: Clasificación
Descripción: Esta es una familia de algoritmos de clasificación que utilizan Teorema de Bayes, lo que significa que asumen la independencia entre características dentro de una clase.
Métricas de evaluación:
- Exactitud
- Precisión
- Recordar
- Puntuación F1
5. K-vecinos más cercanos (KNN)
Usado para: Regresión y clasificación
Descripción: Calcula la distancia entre los datos de prueba y el k-número de los puntos de datos más cercanos a partir de los datos de entrenamiento. Los datos de prueba pertenecen a una clase con un mayor número de "vecinos". Respecto a la regresión, el valor predicho es el promedio de los k puntos de entrenamiento elegidos.
Métricas de evaluación:
- Exactitud, precisión, recuperación y puntuación F1 -> para clasificación
- MSE, R cuadrado -> para regresión
6. Máquinas de vectores de soporte (SVM)
Usado para: Regresión y clasificación
Descripción: Este algoritmo dibuja una hiperplano para separar diferentes clases de datos. Está ubicado a la mayor distancia de los puntos más cercanos de cada clase. Cuanto mayor sea la distancia del punto de datos al hiperplano, más pertenece a su clase. Para la regresión, el principio es similar: el hiperplano maximiza la distancia entre los valores previstos y reales.
Métricas de evaluación:
- Exactitud, precisión, recuperación y puntuación F1 -> para clasificación
- MSE, R cuadrado -> para regresión
7. Bosque aleatorio
Usado para: Regresión y clasificación
Descripción: El algoritmo del bosque aleatorio utiliza un conjunto de árboles de decisión, que luego forman un bosque de decisión. La predicción del algoritmo se basa en la predicción de muchos árboles de decisión. Los datos se asignarán a la clase que reciba la mayor cantidad de votos. Para la regresión, el valor predicho es un promedio de los valores predichos de todos los árboles.
Métricas de evaluación:
- Exactitud, precisión, recuperación y puntuación F1 -> para clasificación
- MSE, R cuadrado -> para regresión
8. Aumento de gradiente
Usado para: Regresión y clasificación
Descripción: Estos algoritmos Utilice un conjunto de modelos débiles, y cada modelo posterior reconozca y corrija los errores del modelo anterior. Este proceso se repite hasta que se minimice el error (función de pérdida).
Métricas de evaluación:
- Exactitud, precisión, recuperación y puntuación F1 -> para clasificación
- MSE, R cuadrado -> para regresión
Algoritmos de aprendizaje no supervisados
9. Agrupación de K-Means
Usado para: Clustering
Descripción: El algoritmo divide el conjunto de datos en grupos de k números, cada uno representado por su centroide o centro geométrico. A través del proceso iterativo de dividir datos en un número k de grupos, el objetivo es minimizar la distancia entre los puntos de datos y el centroide de su grupo. Por otro lado, también intenta maximizar la distancia de estos puntos de datos desde el centroide de los otros grupos. En pocas palabras, los datos que pertenecen al mismo grupo deben ser lo más similares posible y tan diferentes como los datos de otros grupos.
Métricas de evaluación:
- Inercia: la suma de la distancia al cuadrado de la distancia de cada punto de datos desde el centroide del grupo más cercano. Cuanto menor sea el valor de inercia, más compacto será el grupo.
- Puntaje de silueta: Mide la cohesión (la similitud de los datos dentro de su propio grupo) y la separación (la diferencia de los datos con otros grupos) de los grupos. El valor de esta puntuación oscila entre -1 y +1. Cuanto mayor sea el valor, mejor coincidirán los datos con su grupo y peor coincidirán con otros grupos.
10. Análisis de componentes principales (PCA)
Usado para: Reducción de dimensionalidad
Descripción: El algoritmo reduce el número de variables utilizadas mediante la construcción de nuevas variables (componentes principales) y al mismo tiempo intenta maximizar la varianza capturada de los datos. En otras palabras, limita los datos a sus componentes más comunes sin perder la esencia de los datos.
Métricas de evaluación:
- Variación explicada: el porcentaje de la varianza cubierta por cada componente principal.
- Variación total explicada: el porcentaje de la varianza cubierta por todos los componentes principales.
El aprendizaje automático es una parte esencial de la ciencia de datos. Con estos diez algoritmos, cubrirá las tareas más comunes en el aprendizaje automático. Por supuesto, esta descripción general sólo le brinda una idea general de cómo funciona cada algoritmo. Así que esto es sólo el comienzo.
Ahora necesitas aprender cómo implementar estos algoritmos en Python y resolver problemas reales. En eso, recomiendo usar scikit-learn. No solo porque es una biblioteca ML relativamente fácil de usar sino también por su materiales extensos sobre algoritmos de ML.
Nate Rosidi Es científico de datos y en estrategia de producto. También es profesor adjunto de análisis y es el fundador de StrataScratch, una plataforma que ayuda a los científicos de datos a prepararse para sus entrevistas con preguntas reales de las principales empresas. Nate escribe sobre las últimas tendencias en el mercado profesional, brinda consejos para entrevistas, comparte proyectos de ciencia de datos y cubre todo lo relacionado con SQL.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/a-beginner-guide-to-the-top-10-machine-learning-algorithms?utm_source=rss&utm_medium=rss&utm_campaign=a-beginners-guide-to-the-top-10-machine-learning-algorithms

