Introducción
La llegada de la IA y el aprendizaje automático ha revolucionado la forma en que interactuamos con la información, haciendo que sea más fácil de recuperar, comprender y utilizar. En esta guía práctica, exploramos la creación de un sofisticado asistente de preguntas y respuestas impulsado por LLamA2 y LLamAIndex, aprovechando modelos de lenguaje y marcos de indexación de última generación para navegar por un mar de documentos PDF sin esfuerzo. Este tutorial está diseñado para brindar a los desarrolladores, científicos de datos y entusiastas de la tecnología las herramientas y el conocimiento para construir un sistema de generación aumentada de recuperación (RAG) que se apoye sobre los hombros de los gigantes en el dominio de la PNL.
En nuestra búsqueda por desmitificar la creación de un asistente de preguntas y respuestas impulsado por IA, esta guía sirve como un puente entre conceptos teóricos complejos y su aplicación práctica en escenarios del mundo real. Al integrar la comprensión avanzada del lenguaje de LLamA2 con las eficientes capacidades de recuperación de información de LLamAIndex, nuestro objetivo es construir un sistema que responda preguntas con precisión y profundice nuestra comprensión del potencial y los desafíos dentro del campo de la PNL. Este artículo sirve como una hoja de ruta integral para entusiastas y profesionales, destacando la sinergia entre los modelos de vanguardia y las demandas en constante evolución de la tecnología de la información.

OBJETIVOS DE APRENDIZAJE
- Desarrolle un sistema RAG utilizando el modelo LLamA2 de Hugging Face.
- Integre múltiples documentos PDF.
- Indexar documentos para una recuperación eficiente.
- Elaborar un sistema de consulta.
- Cree un asistente robusto capaz de responder varias preguntas.
- Centrarse en la implementación práctica en lugar de solo en los aspectos teóricos.
- Participe en codificación práctica y aplicaciones del mundo real.
- Haga que el complejo mundo de la PNL sea accesible y atractivo.
Tabla de contenidos.
Modelo LLamA2
LLamA2 es un modelo de innovación en el procesamiento del lenguaje natural, que amplía los límites de lo que es posible con los modelos de lenguaje. Su arquitectura, diseñada para brindar eficiencia y efectividad, permite una comprensión y generación de texto similar a la humana sin precedentes. A diferencia de sus predecesores como BERT y GPT, LLamA2 ofrece un enfoque más matizado para procesar el lenguaje, lo que lo hace particularmente apto para tareas que requieren una comprensión profunda, como responder preguntas. Su utilidad en diversas tareas de PNL, desde el resumen hasta la traducción, muestra su versatilidad y capacidad para abordar desafíos lingüísticos complejos.

Entendiendo LLamAIndex
La indexación es la columna vertebral de cualquier sistema eficiente de recuperación de información. LLamAIndex, un marco diseñado para la indexación y consulta de documentos, se destaca por proporcionar una forma perfecta de gestionar grandes colecciones de documentos. No se trata sólo de almacenar información; se trata de hacerlo accesible y recuperable en un abrir y cerrar de ojos.

No se puede subestimar la importancia de LLamAIndex, ya que permite el procesamiento de consultas en tiempo real a través de extensas bases de datos, lo que garantiza que nuestro asistente de preguntas y respuestas pueda proporcionar respuestas rápidas y precisas extraídas de una base de conocimientos integral.
Tokenización e incrustaciones
El primer paso para comprender los modelos lingüísticos implica dividir el texto en partes manejables, un proceso conocido como tokenización. Esta tarea fundamental es crucial para preparar los datos para su posterior procesamiento. Después de la tokenización, entra en juego el concepto de incrustaciones, que traduce palabras y oraciones en vectores numéricos.
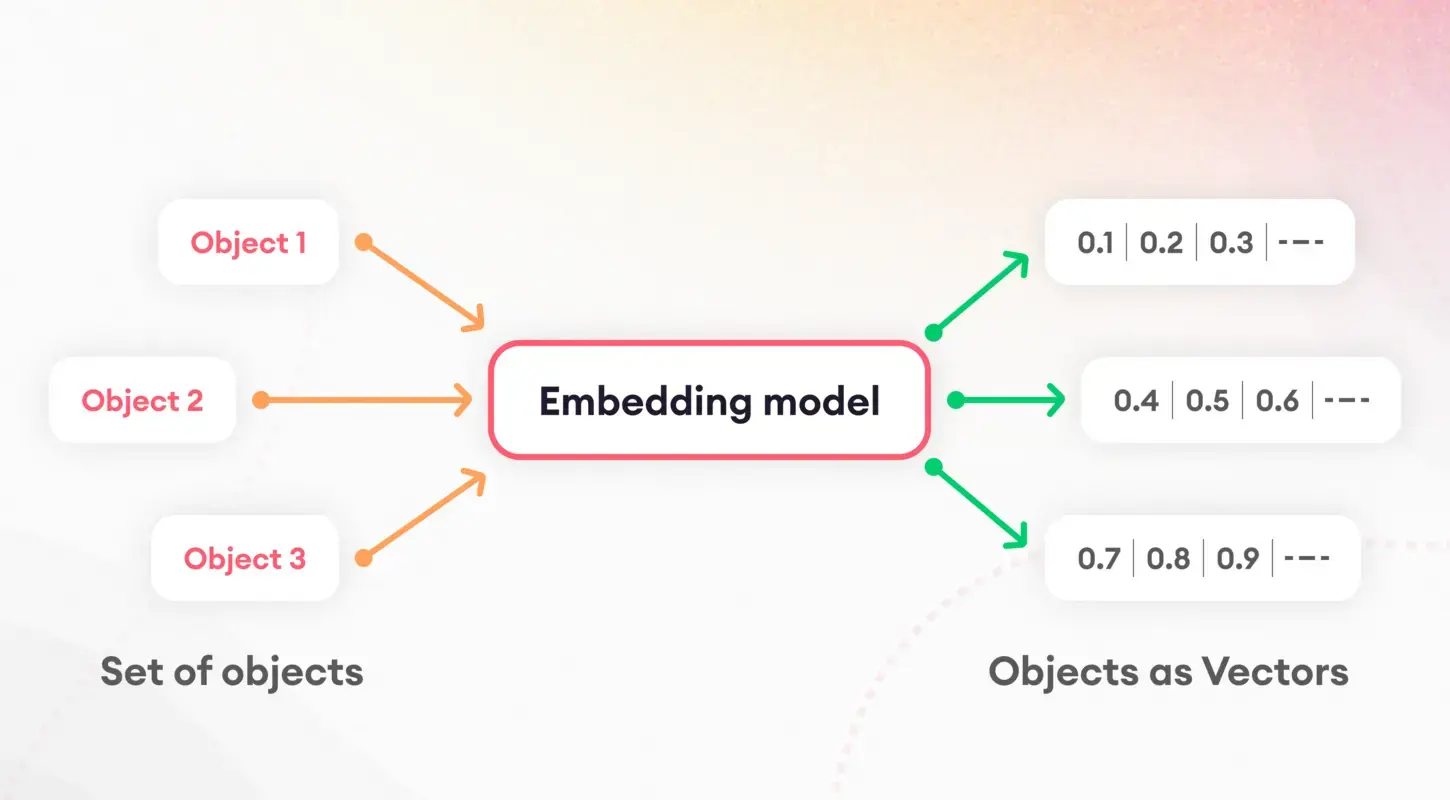
Estas incorporaciones capturan la esencia de las características lingüísticas, permitiendo a los modelos discernir y utilizar las propiedades semánticas subyacentes del texto. En particular, las incrustaciones de oraciones desempeñan un papel fundamental en tareas como la similitud y recuperación de documentos, y forman la base de nuestra estrategia de indexación.
Cuantización del modelo
La cuantificación del modelo presenta una estrategia para mejorar el rendimiento y la eficiencia de nuestro asistente de preguntas y respuestas. Al reducir la precisión de los cálculos numéricos del modelo, podemos disminuir significativamente su tamaño y acelerar los tiempos de inferencia. Si bien introduce un equilibrio entre precisión y eficiencia, este proceso es especialmente valioso en entornos con recursos limitados, como dispositivos móviles o aplicaciones web. Mediante una aplicación cuidadosa, la cuantificación nos permite mantener altos niveles de precisión mientras nos beneficiamos de una latencia reducida y requisitos de almacenamiento.
ServiceContext y motor de consultas
ServiceContext dentro de LLamAIndex es un centro central para administrar recursos y configuraciones, lo que garantiza que nuestro sistema funcione sin problemas y de manera eficiente. El pegamento mantiene unida nuestra aplicación, permitiendo una integración perfecta entre los modelo LLamA2, el proceso de incrustación y los documentos indexados. Por otro lado, el motor de consultas es el caballo de batalla que procesa las consultas de los usuarios, aprovechando los datos indexados para obtener información relevante rápidamente. Esta configuración dual garantiza que nuestro asistente de preguntas y respuestas pueda manejar fácilmente consultas complejas y brindar respuestas rápidas y precisas a los usuarios.
Implementación
Profundicemos en la implementación. Tenga en cuenta que he utilizado Google Colab para crear este proyecto.
!pip install pypdf
!pip install -q transformers einops accelerate langchain bitsandbytes
!pip install sentence_transformers
!pip install llama_indexEstos comandos preparan el escenario instalando las bibliotecas necesarias, incluidos transformadores para la interacción del modelo y sentencias_transformadores para incrustaciones. La instalación de llama_index es crucial para nuestro marco de indexación.
A continuación, inicializamos nuestros componentes (asegúrese de crear una carpeta llamada "datos" en la sección Archivos en Google Colab y luego cargue el PDF en la carpeta):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.prompts.prompts import SimpleInputPrompt
# Reading documents and setting up the system prompt
documents = SimpleDirectoryReader("/content/data").load_data()
system_prompt = """
You are a Q&A assistant. Your goal is to answer questions based on the given documents.
"""
query_wrapper_prompt = SimpleInputPromptDespués de configurar nuestro entorno y leer los documentos, elaboramos un mensaje del sistema para guiar las respuestas del modelo LLamA2. Esta plantilla es fundamental para garantizar que el resultado del modelo se alinee con nuestras expectativas de precisión y relevancia.
!huggingface-cli login
El comando anterior es una puerta de entrada para acceder al vasto repositorio de modelos de Hugging Face. Requiere un token para la autenticación.
Es necesario visitar el siguiente enlace: Abrazando la cara (asegúrese de iniciar sesión primero en Hugging Face), luego cree un nuevo token, proporcione un nombre para el proyecto, seleccione Tipo como leído y luego haga clic en Generar un token.
Este paso subraya la importancia de proteger y personalizar su entorno de desarrollo.
import torch
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.0, "do_sample": False},
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
model_name="meta-llama/Llama-2-7b-chat-hf",
device_map="auto",
model_kwargs={"torch_dtype": torch.float16, "load_in_8bit":True}
)Aquí, inicializamos el modelo LLamA2 con parámetros específicos diseñados para nuestro sistema de preguntas y respuestas. Esta configuración resalta la versatilidad del modelo y su capacidad para adaptarse a diferentes contextos y aplicaciones.
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.embeddings.langchain import LangchainEmbedding
embed_model = LangchainEmbedding(
HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2"))La elección del modelo de incrustación es fundamental para capturar la esencia semántica de nuestros documentos. Al emplear Sentence Transformers, nos aseguramos de que nuestro sistema pueda medir con precisión la similitud y relevancia del contenido textual, mejorando así la eficacia del proceso de indexación.
service_context = ServiceContext.from_defaults(
chunk_size=1024,
llm=llm,
embed_model=embed_model
)Se crea una instancia de ServiceContext con la configuración predeterminada, vinculando nuestro modelo LLamA2 e incrustando el modelo dentro de un marco cohesivo. Este paso garantiza que todos los componentes del sistema estén armonizados y listos para operaciones de indexación y consulta.
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()Estas líneas marcan la culminación de nuestro proceso de configuración, donde indexamos nuestros documentos y preparamos el motor de consultas. Esta configuración es fundamental para la transición de la preparación de datos a información procesable, lo que permite a nuestro asistente de preguntas y respuestas responder consultas basadas en el contenido indexado.
response = query_engine.query("Give me a Summary of the PDF in 10 pointers.")
print(response)Finalmente, probamos nuestro sistema consultando resúmenes e información derivada de nuestra colección de documentos. Esta interacción demuestra la utilidad práctica de nuestro asistente de preguntas y respuestas y muestra la perfecta integración de LLamA2, LLamAIndex y el sistema subyacente. tecnologías de PNL que lo hacen posible.
Salida:

Implicaciones éticas y legales
El desarrollo de sistemas de preguntas y respuestas impulsados por IA pone en primer plano varias consideraciones éticas y legales. Es fundamental abordar los posibles sesgos en los datos de capacitación, así como garantizar la equidad y neutralidad en las respuestas. Además, el cumplimiento de las normas de privacidad de datos es primordial, ya que estos sistemas a menudo manejan información confidencial. Los desarrolladores deben afrontar estos desafíos con diligencia e integridad, comprometiéndose con principios éticos que salvaguarden a los usuarios y la integridad de la información proporcionada.
Direcciones futuras y desafíos
El campo de los sistemas de preguntas y respuestas está lleno de oportunidades para la innovación, desde interacciones multimodales hasta aplicaciones de dominios específicos. Sin embargo, estos avances conllevan sus propios desafíos, incluida la ampliación para dar cabida a grandes colecciones de documentos y garantizar la diversidad en las consultas de los usuarios. El desarrollo y perfeccionamiento continuo de modelos como LLamA2 y marcos de indexación como LLamAIndex son fundamentales para superar estos obstáculos y ampliar los límites de lo que es posible en PNL.
Estudios de casos y ejemplos
Las implementaciones en el mundo real de sistemas de preguntas y respuestas, como robots de servicio al cliente y herramientas educativas, subrayan la versatilidad y el impacto de tecnologías como LLamA2 y LLamAIndex. Estos estudios de caso demuestran las aplicaciones prácticas de la IA en diversas industrias y destacan las historias de éxito y las lecciones aprendidas, proporcionando información valiosa para desarrollos futuros.
Conclusión
Esta guía ha recorrido el panorama de la creación de un asistente de preguntas y respuestas basado en PDF, desde los conceptos fundamentales de LLamA2 y LLamAIndex hasta los pasos prácticos de implementación. A medida que continuamos explorando y ampliando las capacidades de la IA en la recuperación y el procesamiento de información, el potencial para transformar nuestra interacción con el conocimiento es ilimitado. Armado con estas herramientas y conocimientos, el viaje hacia sistemas más inteligentes y con mayor capacidad de respuesta apenas comienza.
Puntos clave
- Revolucionando la interacción de la información: la integración de la IA y el aprendizaje automático, ejemplificada por LLamA2 y LLamAIndex, ha transformado la forma en que accedemos y utilizamos la información, allanando el camino para sofisticados asistentes de preguntas y respuestas capaces de navegar sin esfuerzo por vastas colecciones de documentos PDF.
- Puente práctico entre teoría y aplicación: esta guía cierra la brecha entre los conceptos teóricos y la implementación práctica, capacitando a los desarrolladores y entusiastas de la tecnología para crear sistemas de generación aumentada de recuperación (RAG) que aprovechen los modelos de PNL y los marcos de indexación de última generación.
- Importancia de una indexación eficiente: LLamAIndex desempeña un papel crucial en la recuperación eficiente de información mediante la indexación de vastas colecciones de documentos. Esto garantiza respuestas rápidas y precisas a las consultas de los usuarios y mejora la funcionalidad general del asistente de preguntas y respuestas.
- Optimización del rendimiento y la eficiencia: técnicas como la cuantificación de modelos mejoran el rendimiento y la eficiencia de los asistentes de preguntas y respuestas, lo que permite reducir la latencia y los requisitos de almacenamiento sin comprometer la precisión.
- Consideraciones éticas y direcciones futuras: el desarrollo de sistemas de preguntas y respuestas basados en IA requiere abordar las implicaciones éticas y legales, incluida la mitigación de prejuicios y la privacidad de los datos. De cara al futuro, los avances en los sistemas de preguntas y respuestas presentan oportunidades para la innovación y al mismo tiempo plantean desafíos en la escalabilidad y diversidad de las consultas de los usuarios.
Preguntas frecuentes
Respuesta. LLamA2 ofrece un enfoque más matizado para el procesamiento del lenguaje, permitiendo tareas de comprensión profunda, como responder preguntas. Su arquitectura prioriza la eficiencia y la eficacia, lo que la hace versátil en diversas tareas de PNL.
Respuesta. LLamAIndex es un marco para la indexación y consulta de documentos, que facilita el procesamiento de consultas en tiempo real en extensas bases de datos. Garantiza que los asistentes de preguntas y respuestas puedan recuperar rápidamente información relevante de bases de conocimiento completas.
Respuesta. Las incrustaciones, en particular las incrustaciones de oraciones, capturan la esencia semántica del contenido textual, lo que permite medir con precisión la similitud y relevancia. Esto mejora la eficacia del proceso de indexación, mejorando la capacidad del asistente para proporcionar respuestas relevantes.
Respuesta. La cuantificación del modelo optimiza el rendimiento y la eficiencia al reducir el tamaño de los cálculos numéricos, disminuyendo así la latencia y los requisitos de almacenamiento. Si bien introduce un equilibrio entre precisión y eficiencia, es valioso en entornos con recursos limitados.
Respuesta. Los desarrolladores deben abordar los posibles sesgos en los datos de capacitación, garantizar la equidad y neutralidad en las respuestas y cumplir con las regulaciones de privacidad de datos. Mantener los principios éticos protege a los usuarios y mantiene la integridad de la información proporcionada por el asistente de preguntas y respuestas.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2024/04/a-hands-on-guide-to-creating-a-pdf-based-qa-assistant-with-llama-and-llamaindex/

