Introducción
Apache Flume es un mecanismo de ingestión de herramienta/servicio/datos para recopilar, agregar y entregar grandes cantidades de datos de transmisión de diversas fuentes, como archivos de registro, eventos, etc., al almacenamiento de datos centralizado. Flume es una herramienta muy confiable, distribuida y personalizable. einsteinerupload de.
En este artículo, discutiremos sobre Apache Flume, Flume Architecture, instalación, instalación y configuración. Básicamente, los datos de múltiples fuentes se pueden transferir a sistemas centralizados de almacenamiento o procesamiento como HDFS, HBase y Spark utilizando la plataforma Flume, una plataforma distribuida, altamente confiable y escalable. Las aplicaciones que procesan y analizan big data usan Flume en el ecosistema Apache Hadoop.

OBJETIVOS DE APRENDIZAJE
Los objetivos de aprendizaje de este artículo son
- Comprender la arquitectura del canal.
- Instalación y configuración de canaletas.
- Fuentes de canal sumidero del canal y canales del canal.
- Dibuje luz sobre cómo mejorar el rendimiento del canal.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Índice del contenido
Arquitectura de canal Apache
La arquitectura de Flume consta de tres componentes principales: fuentes, canales y sumideros.
- Fuentes: Las fuentes son los componentes de la arquitectura de Flume que recopilan datos de varias fuentes, como archivos de registro, sockets de red o procesos del sistema. Flume proporciona varios tipos de fuentes integradas, incluidos exec, directorio de spooling y netcat. También se pueden desarrollar fuentes personalizadas para admitir la ingesta de varias fuentes de datos. Los datos recopilados por las fuentes generalmente no están estructurados y deben procesarse y transformarse antes de que puedan almacenarse o analizarse.
- Canales: Los canales son los búferes intermedios que almacenan y transportan datos entre fuentes y sumideros. Flume proporciona varios tipos de canales integrados: memoria, JDBC y archivo. Los canales se pueden configurar para que tengan diferentes propiedades, como el tamaño máximo de los eventos o la cantidad máxima de eventos almacenados. Los datos almacenados en los canales se pueden comprimir y cifrar, y se puede configurar para que sean duraderos o no.
- Fregaderos: Los sumideros son los destinos finales que reciben y procesan datos de los canales, como HDFS, HBase, Elasticsearch o Kafka. Flume proporciona varios tipos de sumideros incorporados, incluidos HDFS, HBase, Solr y Elasticsearch. También se pueden desarrollar sumideros personalizados para admitir la entrega a varios destinos de datos.
- agentes: Los agentes son los nodos lógicos en la arquitectura Flume. Son responsables de recibir datos de fuentes, almacenarlos en canales y entregarlos a sumideros. Un agente puede tener una o más fuentes, canales y sumideros. Los agentes Flume se pueden configurar para ejecutarse en varios nodos de manera distribuida para proporcionar escalabilidad y tolerancia a fallas.
- Evento: El evento es la unidad básica de datos en la arquitectura Flume. Un evento es una pieza de datos no estructurados que es generado por una fuente y transportado a través de canales a un sumidero. Los eventos pueden tener encabezados y cuerpos, que los interceptores pueden modificar y filtrar.
- Interceptador: Interceptor es un componente de la arquitectura Flume que puede modificar o filtrar eventos a medida que pasan por el flujo de datos. Los interceptores se pueden utilizar para enriquecer eventos con metadatos adicionales o filtrar eventos no deseados.

Instalación y configuración de Apache Flume
Pasos para instalar y configurar Flume
1. Descargar Flume: Descargue la última versión de Flume del sitio web de Apache Flume.
2. Instalar Java: Flume requiere que Java esté instalado en el sistema. Asegúrese de que Java esté instalado y configurado correctamente.
3. Configure las variables de entorno: Configure las variables de entorno para Java y Flume en el sistema. Por ejemplo, agregue las siguientes líneas al archivo .bashrc o .bash_profile:
export JAVA_HOME=/path/to/java
export PATH=$PATH:$JAVA_HOME/bin
export FLUME_HOME=/path/to/flume
export PATH=$PATH:$FLUME_HOME/bin4. Configurar canal: Flume se configura usando archivos de configuración escritos en el formato de propiedades. Cree un archivo de configuración llamado flume.conf en el directorio $FLUME_HOME/conf. Aquí hay una configuración de ejemplo para un agente de Flume simple que lee datos de un archivo y los escribe en la consola:
agent.sources = mysource
agent.channels = mychannel
agent.sinks = mysink agent.sources.mysource.type = exec
agent.sources.mysource.command = tail -F /var/log/syslog agent.sinks.mysink.type = logger agent.channels.mychannel.type = memory
agent.channels.mychannel.capacity = 1000
agent.channels.mychannel.transactionCapacity = 100 agent.sources.mysource.channels = mychannel
agent.sinks.mysink.channel = mychannel
Esta configuración define una fuente llamada "mysource" que lee datos de un archivo syslog usando la fuente de tipo "exec", un sumidero llamado "mysink" que registra datos en la consola usando el sumidero de tipo "logger" y un canal de memoria llamado " mychannel” que almacena eventos en la memoria. La fuente y el sumidero están conectados al canal mediante la propiedad de canales.
5. Canal de inicio: Inicie Flume ejecutando el siguiente comando en la terminal:
$ flume-ng agent -n agent -c $FLUME_HOME/conf -f $FLUME_HOME/conf/flume.confEste comando inicia un agente Flume con el nombre “agente”, usando el archivo de configuración ubicado en el directorio $FLUME_HOME/conf.
6. Verifique que Flume esté funcionando: Verifique que Flume se esté ejecutando revisando los archivos de registro en el directorio $FLUME_HOME/logs.
Fuentes de Apache Flume
- Fuente Avro: Esta fuente recibe datos a través de la red a través del protocolo Apache Avro. Se puede utilizar para recopilar datos de aplicaciones escritas en cualquier lenguaje de programación.
- Fuente Netcat: Esta fuente escucha en un socket de red y recibe datos como texto sin formato. Es útil para recopilar datos de fuentes que pueden enviar datos como texto sin formato a través de la red.
- Fuente de registro del sistema: Esta fuente recibe datos de los servidores Syslog. Es útil para recopilar datos de dispositivos de red, servidores Unix y otros dispositivos habilitados para Syslog.
- Fuente del directorio de colas: Esta fuente supervisa un directorio en busca de nuevos archivos y los lee a medida que se agregan al directorio. Es útil para recopilar datos de fuentes que escriben datos en archivos.
- Fuente HTTP: Esta fuente recibe datos a través de HTTP. Es útil para recopilar datos de servidores web, API RESTy otras fuentes habilitadas para HTTP.
- Fuente JMS: Esta fuente recibe datos de una cola JMS (Java Messaging Service). Es útil para recopilar datos de aplicaciones que envían datos a una cola JMS.
Fregaderos Apache Flume
- Fregadero HDFS: Este sumidero entrega los datos al sistema de archivos distribuidos de Hadoop (HDFS). Es útil para almacenar datos en Hadoop para su posterior procesamiento y análisis.
- Fregadero Kafka: Este sumidero entrega los datos al Apache Kafka sistema de mensajería Es útil para procesar datos en tiempo real usando Kafka.
- Sumidero de búsqueda elástica: Este sumidero entrega los datos al motor de búsqueda de ElasticSearch. Es útil para indexar y buscar los datos en tiempo real.
- Fregadero de rollo de archivo: Este sumidero entrega los datos a los archivos en el sistema de archivos local. Es útil para almacenar datos en un sistema de archivos local con fines de copia de seguridad y archivo.
- Fregadero de colmena: Este sumidero entrega los datos a Colmena Apache, un almacenamiento de datos y un lenguaje de consulta similar a SQL para Hadoop. Es útil para procesar y analizar datos usando Hive.
- Fregadero JDBC: Este sumidero entrega los datos a una base de datos relacional mediante JDBC. Es útil para almacenar datos en una base de datos relacional para su posterior procesamiento y análisis.
Canales de canal
Los canales de canal pueden ser de dos tipos: canales basados en memoria y canales basados en archivos.
- Canales basados en memoria: Los canales basados en memoria almacenan eventos en la memoria, lo que los hace más rápidos que los canales basados en archivos. Son útiles cuando el volumen de datos que se procesa es lo suficientemente pequeño como para caber en la memoria.
- Canales basados en archivos: Los canales basados en archivos almacenan eventos en el disco, lo que los hace más lentos que los canales basados en memoria, pero les permite manejar grandes volúmenes de datos que no caben en la memoria.
Los canales de canal tienen una capacidad configurable, determinando el número máximo de eventos que se pueden almacenar en el canal en un momento dado. Si el canal se llena, se descartarán nuevos eventos hasta que haya espacio disponible. Para evitar esto, es importante configurar adecuadamente la capacidad del canal en función del volumen de datos que se procesa.
Los canales Flume también admiten varios mecanismos transaccionales para garantizar que los eventos se entreguen al sumidero de manera confiable y consistente. Por ejemplo, los canales basados en archivos utilizan un registro de escritura anticipada (WAL) para garantizar que los eventos no se pierdan en caso de falla del sistema.

Ajuste del rendimiento del canal
Para lograr un rendimiento óptimo, es importante ajustar Flume en función de los requisitos de la tarea de recopilación y entrega de datos.
- Use las fuentes y sumideros apropiados: Elija las fuentes y los sumideros apropiados en función de los requisitos de la tarea de recopilación y entrega de datos. El uso de la fuente y el sumidero correctos puede mejorar significativamente el rendimiento.
- Usa varios canales: Los canales Flume amortiguan y almacenan los eventos que están siendo procesados por las fuentes y los sumideros. El uso de varios canales puede aumentar el paralelismo de la canalización de Flume y mejorar el rendimiento.
- Aumentar la capacidad del canal: Por defecto, los canales Flume tienen una capacidad pequeña. El aumento de la capacidad del canal puede mejorar el rendimiento de la canalización de Flume al reducir la cantidad de eventos que se descartan debido al desbordamiento del búfer.
- Utilice canales basados en la memoria: Flume proporciona canales basados en disco y en memoria. Los canales basados en memoria son más rápidos que los canales basados en disco y se recomiendan para entornos de alto rendimiento.
- Usar compresión: Flume proporciona soporte integrado para la compresión. Habilitar la compresión puede reducir el tamaño de los datos que se transfieren y mejorar el rendimiento de la canalización de Flume.
- Ajuste el tamaño del lote: Flume procesa eventos en lotes. Ajustar el tamaño del lote en función de los requisitos de la tarea de recopilación y entrega de datos puede mejorar el rendimiento.
- Utilice el equilibrio de carga: Si varios agentes de Flume están procesando datos, utilice el equilibrio de carga para distribuir la carga de trabajo de manera uniforme entre los agentes. Esto puede mejorar el rendimiento general de la tubería Flume.
Aplicación de canal
Flume se puede utilizar para recopilar información de dispositivos de Internet de las cosas (IoT), como sensores o dispositivos domésticos inteligentes, y almacenarla en una base de datos centralizada.
Flume se puede utilizar para recopilar información de sitios web como Twitter y Facebook y luego almacenarla en una base de datos centralizada para su análisis.
Estas son algunas de las aplicaciones de Flume. Estos datos son útiles para el análisis futuro de la empresa y las próximas estrategias de mercado.
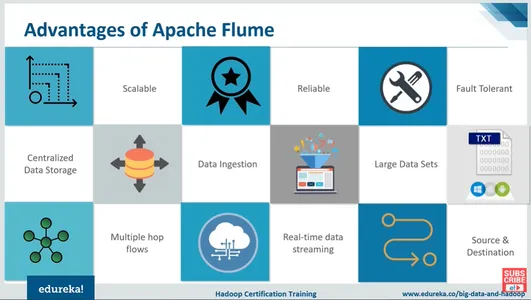
Ventajas de Apache Flume
Muchas ventajas de Apache Flume incluyen escalabilidad, confiabilidad y centralización; Tiene grandes conjuntos de datos, tiene transmisión de datos en tiempo real y muchos más.
- Fuente abierta: Apache Flume es un sistema distribuido de código abierto. Por lo tanto, está disponible de forma gratuita.
- Barato: Es menos costoso de instalar y operar. Su mantenimiento es muy económico.
- Escalable: Está diseñado para manejar cantidades masivas de datos de manera distribuida. Se puede configurar para operar en varios servidores en un grupo, lo que le permite manejar cantidades crecientes de datos sin perder rendimiento.
- Ingestión de datos: La integridad de los datos está protegida por métodos integrados en Flume, como la verificación de errores y la validación de datos, que ayudan a garantizar que los datos no se pierdan ni cambien durante la transmisión.
- Tolerancia a fallos: Tiene la capacidad de encontrar el error. Contiene técnicas para mover información a través de muchos nodos en el clúster y para cada operación fallida y asegurarse de que los datos no se pierdan debido a una falla.
- De confianza: Estas características anteriores hacen de Apache Flume una herramienta confiable para datos.
Haga clic aquí para más detalles
Desventajas de Apache Flume
- Escalado limitado: La escalabilidad de Apache Flume suele ser baja porque puede ser difícil para cualquier empresa dimensionar el hardware de un Apache Flume estándar y, por lo general, es un proceso de prueba y error. Como resultado, la escalabilidad de Flume se ve frecuentemente cuestionada.
- Duplicación: Apache Flume no garantiza que todos los mensajes recibidos sean completamente únicos. Es posible que aparezcan mensajes duplicados en ciertas situaciones.
- Problemas de confiabilidad a veces: Si la tienda de respaldo no se elige sabiamente, entonces puede haber problemas de escalabilidad y confiabilidad.
Estas son algunas de las desventajas de Flume
Conclusión
En conclusión, Flume es una buena herramienta de ingesta y procesamiento de datos que puede manejar cantidades masivas de datos de varias fuentes y conectarse con Hadoop y otras tecnologías de big data sin problemas. Los usuarios pueden escalar según sea necesario, adaptar los flujos de datos y configurar canalizaciones de datos rápidamente. Las sólidas funciones de gestión de datos de Flume para garantizar la seguridad y disponibilidad de los datos, y su conexión con otras herramientas permite a los usuarios realizar análisis avanzados y obtener información valiosa. En última instancia, Flume puede ayudar a las empresas a administrar y obtener información de sus datos para promover la innovación y el progreso económico.
- Podemos almacenar los datos en cualquiera de los almacenamientos centralizados usando Apache Flume (HBase, HDFS).
- Cuando la tasa de datos entrantes supera la tasa a la que se pueden escribir en el destino, Flume funciona como un puente entre los productores de datos y los almacenes centralizados, lo que garantiza un flujo continuo de datos.
- Flume incluye la capacidad de enrutamiento contextual.
- Las transacciones de Flume se basan en canales, y cada comunicación requiere dos transacciones (un remitente y un receptor). Garantiza una transmisión de mensajes consistente.
- Flume es una aplicación confiable, tolerante a fallas, escalable, administrada y adaptable.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/03/a-dive-into-apache-flume-installation-setup-and-configuration/

