Introducción
Datos la replicación también se conoce como replicación de base de datos, que consiste en copiar datos para garantizar que toda la información permanezca coherente en todos los recursos de datos en tiempo real. la replicación de datos es como una red de seguridad que evita que su información desaparezca o se pierda. En la mayoría de los casos, los datos se alteran. Está en constante cambio. Incluso si una réplica se encuentra al otro lado del mundo, los datos del almacenamiento principal se copian allí constantemente.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Índice del contenido
¿Qué es la replicación de datos?
El proceso de hacer varias copias de un dato y almacenarlas en diferentes ubicaciones permite una mejor accesibilidad a la red, tolerancia a fallas y copias de seguridad. Al igual que la duplicación de datos, la replicación de datos se puede aplicar a servidores y equipos individuales. Los duplicados de datos se pueden almacenar en el mismo sistema, servidores en el sitio y fuera del sitio, y hosts basados en la nube.
Replicación de datos en base de datos distribuida
Hacer numerosas copias de datos es el proceso de replicación de datos. Una vez hechas, estas réplicas, también llamadas copias, se almacenan en algunas ubicaciones para respaldo, tolerancia a fallas y accesibilidad mejorada a la red. Los datos replicados pueden almacenarse en servidores regionales y distantes, hosts basados en la nube o incluso en todos los servidores del mismo sistema.
El proceso de difundir datos de un servidor de origen a otros servidores de forma distribuida. base de datos se conoce como replicación de datos. Esto asegura que los usuarios puedan acceder a los datos que necesitan sin interferir con el trabajo de otros.
Propósito de la replicación de datos
Por las siguientes cinco razones, debe hacer una copia de seguridad de sus datos en la nube:
- Como mencionamos anteriormente, la replicación en la nube mantiene sus registros fuera del sitio y lejos de la ubicación de la empresa. Incluso si un incendio, una inundación o una tormenta dañan seriamente su instancia principal, etc., su instancia de respaldo está segura en la nube.
- Es menos costoso replicar información en la nube que hacerlo en su propio centro de entrada, y se puede utilizar para recuperar cualquier entrada y programas perdidos. Es posible que no sea necesario pagar las tarifas de hardware, mantenimiento o soporte asociadas con el funcionamiento de un segundo centro de almacenamiento.
- La escalabilidad bajo demanda es posible gracias a la replicación de datos en la nube. Si su empresa se expande, se contrae o se recupera, no tendrá que gastar dinero en hardware nuevo para mantener su instancia secundaria. Además, no hay contratos prolongados que lo aten.
- Tiene una amplia gama de opciones geográficas para replicar datos en la nube, según los requisitos de su organización, incluido tener una instancia de nube en la próxima ciudad del país.
¿Cómo se replica una base de datos?
Los organismos replicados pueden replicarse esporádicamente o con frecuencia. La arquitectura distribuida de las fuentes de datos de una empresa está involucrada. Los datos se replican y se distribuyen por igual entre todas las fuentes utilizando el sistema de gestión distribuida de la organización.
DDBMS, o sistemas de administración de bases de datos distribuidas, generalmente aseguran que cualquier alteración, adición o eliminación de los datos almacenados en una ubicación se reflejen automáticamente en los datos almacenados en todos los demás sitios. El sistema responsable de controlar el almacenamiento compartido resultante de la replicación del repositorio es un sistema de gestión de bases de datos compartidas o DDBMS.
Replicación completa de datos frente a replicación parcial
La replicación completa de la base de datos se produce cuando una base de datos principal se replica por completo en todas las instancias de las réplicas disponibles. Esta técnica minuciosa replica datos recién adquiridos, actualizados y obtenidos previamente para todos los destinos. Aunque este método es muy completo, la cantidad de datos que transfiere requiere una potencia de cálculo significativa, lo que sobrecarga la red.
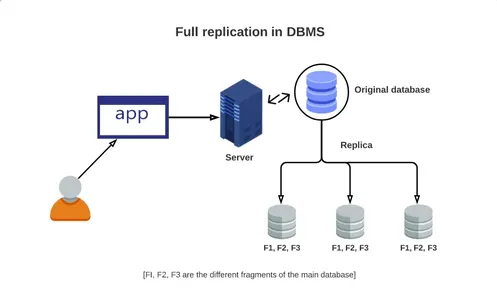
Por el contrario, para completar la replicación, la replicación parcial solo refleja un subconjunto de los datos, normalmente las actualizaciones más recientes. La replicación parcial aísla elementos de datos particulares según la importancia de los datos en un punto en particular. Por ejemplo, una empresa financiera importante con sede en Londres podría tener numerosas oficinas satélite en funcionamiento en todo el mundo, incluidas las de Boston, Kuala Lumpur, etc.

Ejemplos
Hay tres categorías principales de replicación de datos: transaccional, de fusión e instantánea.
1. Replicación transaccional
Este tipo de replicación de base de datos permite que los datos de una base de datos principal dupliquen datos en tiempo real en una instancia de réplica al reflejar estos cambios en el orden en que se produjeron en la base de datos principal. Mejora la confiabilidad. La replicación toma una "instantánea" de los datos en el principal y usa esa instantánea como referencia para saber qué más se debe copiar. La replicación transaccional permite el seguimiento y la distribución de cambios.
Debido a la naturaleza gradual de este proceso, la replicación transaccional no es la mejor opción cuando se busca una alternativa de repositorio de respaldo. La replicación transaccional es una buena opción cuando los datos cambian con frecuencia desde una sola ubicación, cuando se requiere coherencia en tiempo real en todas las ubicaciones de datos, cuando se debe tener en cuenta cada minuto de cambio además de la consecuencia general del cambio, y cuando los datos con frecuencia cambios desde un solo lugar.
2. Replicación de instantáneas
La replicación de instantáneas, como su nombre indica, copia datos del principal a la réplica "capturándolos" en un momento específico. Cuando los datos se envían desde el principal a la réplica, la replicación de instantáneas, como una fotografía, captura cómo se ven los datos en ese momento preciso, pero ignora los cambios posteriores. Como resultado, evite utilizar la replicación de instantáneas para crear una copia de seguridad.
La replicación de instantáneas no tendrá acceso a los datos actualizados si se produce un error de almacenamiento. Puede comenzar con una instantánea para mantener la coherencia, pero asegúrese de que todos los cambios realizados en el principal se propaguen a todas las réplicas.
Por otro lado, este enfoque es bastante útil para la recuperación de datos después de una eliminación no intencional. Imagínese que es similar a su historial de versiones de Google Docs. ¿No sería bueno continuar trabajando en su presentación como lo estaba hace cuatro horas? Puede volver a hacer clic en esa versión, o "instantánea", de hace cuatro horas y ver cómo se ve su información si Google Docs toma una instantánea de su trabajo a intervalos de una hora.
3. Fusión de replicación
Este método generalmente comienza con una instantánea de la información, la distribuye entre sus réplicas y mantiene la sincronización de datos en todo el sistema. A diferencia de otros tipos de replicación, la replicación de fusión permite actualizaciones de datos individuales de cada nodo mientras integra esas actualizaciones en un todo único y coherente.
Debes determinar los aspectos más relevantes a disponer en tu situación. Las tecnologías de replicación de repositorios se pueden seleccionar en función de elementos como el precio, las características y la accesibilidad. Una empresa debe comprometerse a realizar los pagos. El objetivo es encontrar las mejores soluciones de replicación de repositorios para el proyecto dentro del presupuesto asignado.
Algunas de las principales herramientas de replicación de datos son las siguientes:
4. Rúbrica
Rubrik es un servicio que ofrece copias de seguridad rápidas, archivado, recuperación inmediata, análisis y gestión de copias para gestionar y realizar copias de seguridad de datos en la nube. Incluye tecnologías de centro de datos de vanguardia y ofrece copias de seguridad simplificadas. Una interfaz de usuario fácil de usar simplifica la asignación de tareas a cualquier grupo de usuarios. Dependiendo del caso de uso, puede ser necesario integrar varios clústeres en un solo tablero. Sin embargo, esto tiene algunas restricciones.
5. Compartirplex
SharePlex es una tecnología diferente de replicación de repositorios de replicación en tiempo real. El programa es increíblemente adaptable y compatible con una amplia gama de almacenamiento. Una técnica de cola de mensajes hace posible el tránsito rápido de datos y es muy escalable. Tanto el método de la herramienta para recopilar datos de cambio como sus servicios de monitoreo tienen algunos inconvenientes.
6. Datos de Hevo
A medida que la capacidad de las empresas para recopilar datos se desarrolla enormemente, los equipos de datos son cruciales para guiar las decisiones basadas en datos. Todavía tienen problemas para crear una fuente única de verdad a partir de los diversos datos en su almacén. Debido a las canalizaciones rotas, la mala calidad de los datos, las fallas, los errores y la falta de control y visibilidad sobre el flujo de datos, la integración de datos es una molestia. Más de 1000 equipos de datos utilizan la plataforma de canalización de datos de Hevo para agregar datos de forma rápida y eficaz de más de 150 fuentes. Millones de eventos de datos de aplicaciones SaaS, repositorios, almacenamiento de archivos y fuentes de transmisión se pueden copiar instantáneamente gracias a la arquitectura tolerante a fallas de Hevo.
Ventajas
La replicación de los datos puede dar a los usuarios un acceso constante a la información. También aumenta el número de usuarios simultáneos que acceden a los datos. Las redundancias de datos se eliminan combinando bases de datos y actualizando bases de datos esclavas con datos parciales. Además, la replicación de datos acelera el acceso a la base de datos.
1. Disponibilidad y confiabilidad de los datos
La replicación de datos garantiza que los datos sean accesibles. Esto es especialmente útil para las empresas multinacionales con oficinas repartidas por todo el mundo. Como resultado, los datos siguen estando accesibles para otros sitios en caso de falla de hardware o cualquier otro problema en un lugar.
2. Eficiencia del servidor
La replicación de datos puede mejorar y acelerar el rendimiento del servidor. Los usuarios pueden obtener datos mucho más rápido cuando las empresas operan varias copias de datos en varios servidores. Además, los administradores pueden usar menos ciclos de procesador en el servidor principal para actividades de escritura que consumen muchos recursos cuando todas las operaciones de lectura de datos se enrutan a una réplica.
3. Rendimiento de red más eficiente
Al recuperar los datos necesarios del sitio donde se completa la transacción, mantener copias de los mismos datos en muchas ubicaciones puede reducir la latencia de acceso a los datos.
4. Asistencia de análisis de datos
Las empresas que se centran en gran medida en los datos suelen replicar información de varias fuentes en sus repositorios de datos, incluidos los almacenes de datos o los lagos de datos. Esto facilita la finalización de proyectos conjuntos por parte del equipo de análisis, que se distribuye en numerosos sitios.
5. Rendimiento mejorado del sistema de prueba
La duplicación simplifica la difusión y sincronización de datos para los sistemas de prueba que exigen un acceso rápido para una toma de decisiones más rápida.
Desventajas
El mantenimiento de la replicación de datos requiere mucho hardware y espacio de almacenamiento. La replicación es costosa y mantener la infraestructura para mantener la consistencia de los datos es un desafío. También hace que más componentes de software sean vulnerables a problemas de seguridad y privacidad.
La replicación ofrece numerosos beneficios, pero también debe haber un equilibrio entre ellos en una organización. El mayor obstáculo para mantener datos consistentes en una organización es la falta de recursos:
1. Precios más altos
Mayores gastos generales de almacenamiento y procesamiento resultan del mantenimiento de copias duplicadas de los mismos datos en varios lugares y sistemas de bases de datos distribuidos.
2. Restricciones de tiempo
El personal interno debe dedicar tiempo a administrar el proceso de duplicación para garantizar que los datos copiados sean compatibles con los datos originales.
3. Ancho de banda
El tráfico de red puede aumentar como resultado de mantener la coherencia entre las réplicas de datos.
4. Datos poco fiables
Es posible que esto solo sea un problema durante unas pocas horas, o que sus datos pierdan la sincronización por completo. Los administradores de bases de datos deben asegurarse continuamente de que los datos se actualicen para abordar este problema. El método de replicación de datos debe pensarse minuciosamente, ponerse en práctica, evaluarse y pulirse según sea necesario.
Conclusión
Este artículo explica detalladamente cada estrategia de replicación de datos y proporciona toda la información que necesita saber. Brinda una descripción general rápida de una variedad de ideas relacionadas, lo que ayuda a los usuarios a comprenderlas mejor y ponerlas en uso para la replicación y recuperación de datos de la manera más efectiva. También se discutieron las dificultades que tienen muchos ingenieros de datos y, lo que es más importante, cómo una herramienta de replicación de datos puede ayudar a los equipos de datos a hacer un mejor uso de su tiempo y recursos. La replicación de datos tiene ventajas obvias. Las empresas deben estar preparadas para las dificultades que trae consigo la expansión del número de fuentes y destinos. Por lo tanto, es crucial implementar un mecanismo de replicación de datos escalable y confiable.
Los puntos clave de este artículo son los siguientes:
- Debido a que los datos se almacenan en muchos lugares, los usuarios pueden recuperarlos de los servidores más cercanos y experimentar una latencia más baja.
- Las empresas pueden distribuir el tráfico entre varios servidores gracias a la replicación de datos, que mejora el rendimiento del servidor y alivia la carga en los servidores individuales.
- La recuperación ante desastres y la protección de datos eficaces se proporcionan mediante la replicación de datos. Debido a la disponibilidad de datos, se podrían desperdiciar millones de dólares cada hora que una fuente de datos crucial no funcione.
- Las empresas pueden utilizar varias técnicas según el caso de uso y la arquitectura de datos actual.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/02/a-deep-dive-into-data-replication-most-effective-way-to-protect-your-data/

