Introducción
Las bases de datos vectoriales se han convertido en el lugar de referencia para almacenar e indexar las representaciones de datos estructurados y no estructurados. Estas representaciones son las incrustaciones de vectores generadas por los modelos de incrustación. Las tiendas de vectores se han convertido en una parte integral del desarrollo de aplicaciones con modelos de aprendizaje profundo, especialmente los modelos de lenguaje grande. En el panorama en constante evolución de Vector Stores, Qdrant es una de esas bases de datos de vectores que se introdujo recientemente y está repleta de funciones. Profundicemos y aprendamos más al respecto.
OBJETIVOS DE APRENDIZAJE
- Familiarizarse con la terminología de Qdrant para comprenderla mejor.
- Sumérgete en Qdrant Cloud y crea clusters
- Aprender a crear incrustaciones de nuestros documentos y almacenarlos en Qdrant Collections
- Explorando cómo funcionan las consultas en Qdrant
- Jugando con el filtrado en Qdrant para comprobar cómo funciona
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
¿Qué son las incrustaciones?
Las incrustaciones de vectores son un medio para expresar datos en forma numérica, es decir, como números en un espacio de n dimensiones o como un vector numérico, independientemente del tipo de datos: texto, fotos, audio, videos, etc. Las incrustaciones nos permiten para agrupar datos relacionados de esta manera. Ciertas entradas se pueden transformar en vectores utilizando ciertos modelos. Un conocido modelo de incrustación creado por Google que traduce palabras en vectores (los vectores son puntos con n dimensiones) se llama Word2Vec. Cada uno de los modelos de lenguaje grande tiene un modelo de incrustación que genera una incrustación para el LLM.
¿Para qué se utilizan las incrustaciones?
Una ventaja de traducir palabras a vectores es que permiten realizar comparaciones. Cuando se le dan dos palabras como entradas numéricas o incrustaciones de vectores, una computadora puede compararlas aunque no pueda compararlas directamente. Es posible agrupar palabras con incrustaciones comparables. Debido a que están relacionados entre sí, los términos Rey, Reina, Príncipe y Princesa aparecerán en un grupo.
En este sentido, las incrustaciones nos ayudan a localizar palabras que están relacionadas con un término determinado. Esto se puede usar en oraciones, donde ingresamos una oración y los datos proporcionados devuelven oraciones relacionadas. Esto sirve como base para numerosos casos de uso, incluidos chatbots, similitud de oraciones, detección de anomalías y búsqueda semántica. Los Chatbots que desarrollamos para responder preguntas basadas en un PDF o documento que proporcionamos hacen uso de esta noción de incrustación. Todos los modelos de lenguaje generativo grande utilizan este método para obtener contenido que esté conectado de manera similar a las consultas que se les proporcionan.
¿Qué son las bases de datos vectoriales?
Como se discutió, las incrustaciones son representaciones de cualquier tipo de datos, por lo general, los no estructurados en formato numérico en un espacio n-dimensional. Ahora, ¿dónde los almacenamos? Los RDMS tradicionales (Sistemas de gestión de bases de datos relacionales) no se pueden utilizar para almacenar estas incrustaciones de vectores. Aquí es donde entran en juego Vector Store / Vector Dabases. Las bases de datos de vectores están diseñadas para almacenar y recuperar incrustaciones de vectores de manera eficiente. Existen muchas tiendas de vectores, que se diferencian por los modelos de incrustación que admiten y el tipo de algoritmo de búsqueda que utilizan para obtener vectores similares.
¿Qué es Qdrant?
Qdrant es el nuevo motor de búsqueda de similitud de vectores y una base de datos vectorial, que proporciona un servicio listo para producción integrado en Rust, el lenguaje conocido por su seguridad. Qdrant viene con una API fácil de usar diseñada para almacenar, buscar y administrar puntos de alta dimensión (los puntos no son más que incrustaciones de vectores) enriquecidos con metadatos llamados cargas útiles. Estas cargas útiles se convierten en piezas valiosas de información, mejoran la precisión de la búsqueda y proporcionan datos valiosos para los usuarios. Si está familiarizado con otras bases de datos de vectores como Chroma, Payload es similar a los metadatos, contiene información sobre los vectores.
Al estar escrito en Rust, Qdrant es una tienda Vectore rápida y confiable incluso bajo cargas pesadas. Lo que diferencia a Qdrant de otras bases de datos es la cantidad de API de cliente que proporciona. Actualmente, Qdrant es compatible con Python, TypeSciprt/JavaScript, Rust y Go. Viene con. Qdrant utiliza HSNW (Gráfico mundial pequeño navegable jerárquico) para la indexación de vectores y viene con muchas métricas de distancia como coseno, punto y euclidiana. Viene con una API de recomendación lista para usar.
Conozca la terminología de Qdrant
Para comenzar sin problemas con Qdrant, es una buena práctica familiarizarse con la terminología y los componentes principales utilizados en la base de datos vectorial de Qdrant.
Colecciones
Las colecciones son conjuntos de puntos con nombre, donde cada punto contiene un vector y una identificación y carga útil opcionales. Los vectores de la misma colección deben compartir la misma dimensionalidad y evaluarse con una única métrica elegida.
Métricas de distancia
Esenciales para medir qué tan cerca están los vectores entre sí, las métricas de distancia se seleccionan durante la creación de una Colección. Qdrant proporciona las siguientes métricas de distancia: punto, coseno y euclidiana.
Puntos
La entidad fundamental dentro de Qdrant, los puntos, consta de una incrustación de vectores, una identificación opcional y una carga útil asociada, donde
Identificación: Un identificador único para cada incrustación de vectores.
vector: Una representación de datos de alta dimensión, que puede ser en formatos estructurados o no estructurados, como imágenes, texto, documentos, PDF, vídeos, audio, etc.
carga útil: Un objeto JSON opcional que contiene datos asociados con un vector. Esto puede considerarse similar a los metadatos y podemos trabajar con esto para filtrar el proceso de búsqueda.
Almacenamiento
Qdrant ofrece dos opciones de almacenamiento:
- Almacenamiento en memoria: Almacena todos los vectores en RAM, optimizando la velocidad minimizando el acceso al disco para tareas de persistencia.
- Almacenamiento de mapas de memoria: Crea un espacio de direcciones virtuales vinculado a un archivo en el disco, equilibrando los requisitos de velocidad y persistencia.
Estos son los conceptos principales que debemos tener en cuenta para poder comenzar rápidamente con Qdrant.
Qdrant Cloud: creación de nuestro primer clúster
Qdrant proporciona un servicio en la nube escalable para almacenar y gestionar vectores. Incluso proporciona un clúster gratuito para siempre de 1 GB sin información de tarjeta de crédito. En esta sección, analizaremos el proceso de creación de una cuenta con Qdrant Cloud y la creación de nuestro primer clúster.
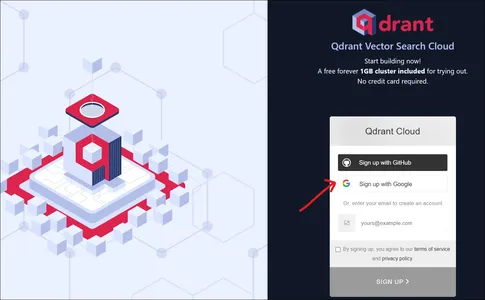
Al ir al sitio web de Qdrant, veremos una página de destino como la anterior. Podemos registrarnos en Qdrant con una cuenta de Google o con una cuenta de GitHub.
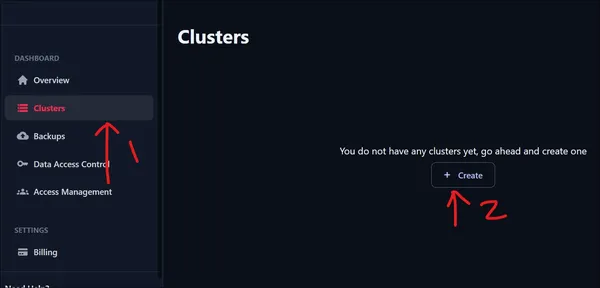
Después de iniciar sesión, se nos presentará la interfaz de usuario que se muestra arriba. Para crear un clúster, vaya al panel izquierdo y haga clic en la opción Clústeres en el Panel. Como acabamos de iniciar sesión, no tenemos ningún grupo. Haga clic en Crear clúster para crear un nuevo clúster.
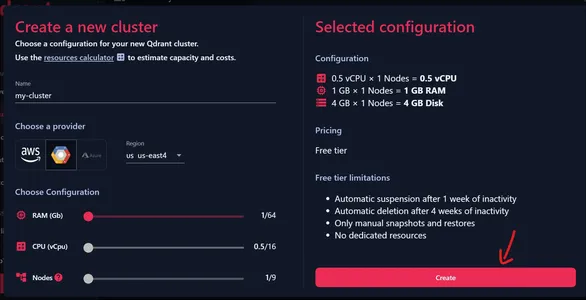
Ahora podemos proporcionar un nombre para nuestro clúster. Asegúrate de tener todas las Configuraciones establecidas en la posición inicial, porque esto nos da un Clúster libre. Podemos elegir uno de los proveedores mostrados arriba y elegir una de las regiones asociadas al mismo.
Verifique la configuración actual
Podemos ver a la izquierda la configuración actual, es decir, 0.5 vCPU, 1 GB de RAM y 4 GB de almacenamiento en disco. Haga clic en Crear para crear nuestro Cluster.
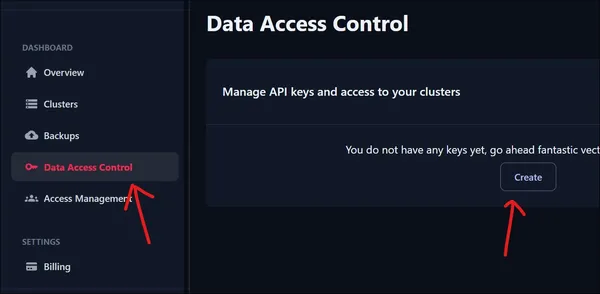
Para acceder a nuestro clúster recién creado necesitamos una clave API. Para crear una nueva clave API, diríjase a Control de acceso a datos en el Panel. Haga clic en el botón Crear para crear una nueva clave API.

Como se muestra arriba, se nos presentará un menú desplegable donde seleccionamos para qué clúster necesitamos crear la API. Como solo tenemos un clúster, lo seleccionamos y hacemos clic en el botón Aceptar.
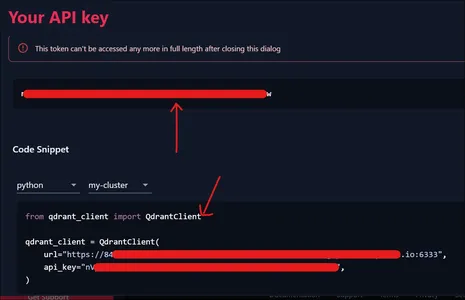
Luego se le presentará el token API que se muestra arriba. Además, si vemos la parte siguiente de la imagen, incluso se nos proporciona el fragmento de código para conectar nuestro clúster, que usaremos en la siguiente sección.
Qdrant – Manos a la obra
En esta sección, trabajaremos con la base de datos de vectores Qdrant. Primero, comenzaremos importando las bibliotecas necesarias.
!pip install sentence-transformers
!pip install qdrant_clientLa primera línea instala la biblioteca Python transformador de oraciones. La biblioteca de transformadores de oraciones se utiliza para generar incrustaciones de oraciones, texto e imágenes. Podemos usar esta biblioteca para importar diferentes modelos de incrustación para crear incrustaciones. La siguiente declaración instala el cliente qdrant para Python. Comencemos creando nuestro cliente.
from qdrant_client import QdrantClient
client = QdrantClient(
url="YOUR CLUSTER URL",
api_key="YOUR API KEY",
)
QdrantCliente
En lo anterior, instanciamos el cliente importando el QdrantCliente clase y proporcionando la URL del clúster y el API Key que acabamos de crear hace un tiempo. A continuación, incorporaremos nuestro modelo de incrustación.
# bringing in our embedding model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')En el código anterior, hemos utilizado el Transformador de oraciones clase y creó una instancia de un modelo. El modelo de incrustación que hemos tomado es el todo-mpnet-base-v2. Este es un modelo de incrustación de vectores de uso general muy popular. Este modelo aceptará texto y generará un 768 dimensiones vector. Definamos nuestros datos.
# data
documents = [
"""Elephants, the largest land mammals, exhibit remarkable intelligence and
social bonds, relying on their powerful trunks for communication and various
tasks like lifting objects and gathering food.""",
""" Penguins, flightless birds adapted to life in the water, showcase strong
social structures and exceptional parenting skills. Their sleek bodies
enable efficient swimming, and they endure
harsh Antarctic conditions in tightly-knit colonies. """,
"""Cars, versatile modes of transportation, come in various shapes and
sizes, from compact city cars to powerful sports vehicles, offering a
range of features for different preferences and needs.""",
"""Motorbikes, nimble two-wheeled machines, provide a thrilling and
liberating riding experience, appealing to enthusiasts who appreciate
speed, agility, and the open road.""",
"""Tigers, majestic big cats, are solitary hunters with distinctive
striped fur. Their powerful build and stealthy movements make them
formidable predators, but their populations are threatened
due to habitat loss and poaching."""
]
En lo anterior, tenemos una variable llamada documentos y contiene una lista de 5 cadenas (tomemos cada una de ellas como un solo documento). Cada cadena de datos está relacionada con un tema en particular. Algunos datos están relacionados con elementos y otros datos están relacionados con automóviles. Creemos incrustaciones para los datos.
# embedding the data
embeddings = model.encode(documents)
print(embeddings.shape)Usamos la codificar() función del objeto modelo para codificar nuestros datos. Para codificar, pasamos directamente la lista de documentos al codificar() funciona y almacena las incrustaciones de vectores resultantes en la variable de incrustaciones. Incluso estamos imprimiendo la forma de las incrustaciones, que aquí imprimirán (5, 768). Esto se debe a que tenemos 5 puntos de datos, es decir, 5 documentos y para cada documento, se crea una incrustación vectorial de 768 dimensiones.
Crea tu colección
Ahora crearemos nuestra Colección.
from qdrant_client.http.models import VectorParams, Distance
client.create_collection(
collection_name = "my-collection",
vectors_config = VectorParams(size=768,distance=Distance.COSINE)
)
- Para crear una Colección, trabajamos con la función create_collection() del objeto cliente, y con el botón "nombre_colección“, pasamos el nombre de nuestra colección, es decir, “mi-colección”
- Parámetros vectoriales: Esta clase de qdrant es para la configuración vectorial, como cuál es el tamaño de incrustación del vector, cuál es la métrica de distancia, etc.
- Distancia: Esta clase de qdrant es para definir qué métrica de distancia usar para consultar vectores
- Ahora al vector_config variable pasamos nuestra Configuración, que es el tamaño de las incrustaciones de vectores, es decir 786, y la métrica de distancia que queremos usar, que es COSENO
Agregar incrustaciones de vectores
Ahora hemos creado con éxito nuestra Colección. Ahora agregaremos nuestras incrustaciones de vectores a esta colección.
from qdrant_client.http.models import Batch
client.upsert (
collection_name = "my-collection",
points = Batch(
ids = [1,2,3,4,5],
payloads= [
{"category":"animals"},
{"category":"animals"},
{"category":"automobiles"},
{"category":"automobiles"},
{"category":"animals"}
],
vectors = embeddings.tolist()
)
)
- Para agregar datos a qdrant llamamos al insertar() método y pase el nombre de la colección y los puntos. Como hemos aprendido anteriormente, un punto consta de vectores, un índice opcional y cargas útiles. El Lote La clase de qdrant nos permite agregar datos en lotes en lugar de agregarlos uno por uno.
- ids: Estamos dando a nuestros documentos una identificación. Actualmente, damos un rango de valores del 1 al 5 porque tenemos 5 documentos en nuestra lista.
- cargas útiles: Como hemos visto antes, el carga útil contiene información sobre los vectores, como metadatos. Lo proporcionamos en pares clave-valor. Para cada documento hemos proporcionado un carga útil aquí, asignamos la información de categoría para cada documento.
- vectores: Estas son las incrustaciones de vectores de los documentos. Lo convertimos en una lista a partir de una matriz numerosa y la alimentamos.
Entonces, después de ejecutar este código, las incrustaciones de vectores se agregan a la Colección. Para verificar si se han agregado, podemos visitar el panel de la nube que proporciona Qdrant Cloud. Para eso hacemos lo siguiente:
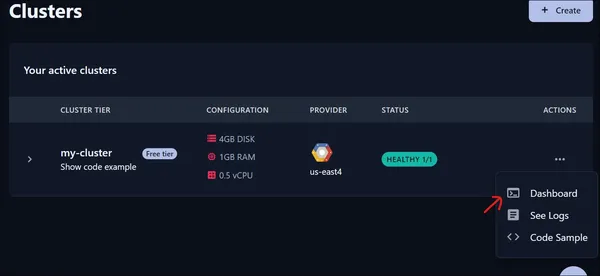
Hacemos clic en el panel y luego se abre una nueva página.
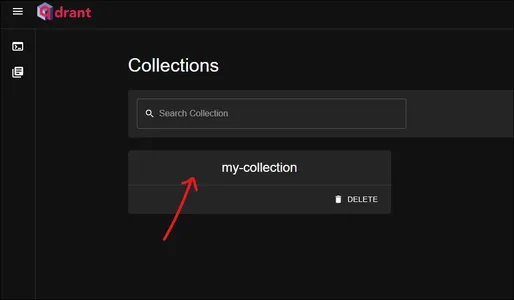
Este es el panel de qdrant. Consulta nuestro “mi colección”colección aquí. Haga clic en él para ver lo que contiene.

En la nube de Qdrant, observamos que nuestros Puntos (vectores + carga útil + ID) de hecho se están agregando a nuestra Colección dentro de nuestro Clúster. En la sección de seguimiento, aprenderemos cómo consultar estos vectores.
Consultando la base de datos de vectores Qdrant
En esta sección, consultaremos la base de datos de vectores e incluso intentaremos agregar algunos filtros para obtener un resultado filtrado. Para consultar nuestra base de datos de vectores qdrant, primero debemos crear un vector de consulta, lo cual podemos hacer de la siguiente manera:
query = model.encode(['Animals live in the forest'])Incrustación de consultas
Lo siguiente creará nuestro pregunta incrustación. Luego, usando esto, consultaremos nuestra tienda de vectores para obtener las incrustaciones de vectores más relevantes.
client.search(
collection_name = "my-collection",
query_vector = query[0],
limit = 4
)
Consulta de busqueda
Para consultar utilizamos el buscar() método del objeto cliente y pásele lo siguiente:
- nombre_colección: El nombre de nuestra Colección
- vector_consulta: El vector de consulta en el que queremos buscar en el almacén de vectores.
- límitar: ¿Cuántos resultados de búsqueda queremos que tenga? buscar() función para limitar también
Ejecutar el código producirá el siguiente resultado:
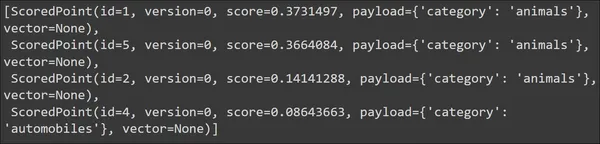
Vemos que para nuestra consulta, los documentos más recuperados son de la categoría animales. Así podemos decir que la búsqueda es efectiva. Ahora probemos con alguna otra consulta para que nos dé resultados diferentes. Los vectores no se muestran ni se recuperan de forma predeterminada, por lo que está configurado en Ninguno.
query = model.encode(['Vehicles are polluting the world'])
client.search(
collection_name = "my-collection",
query_vector = query[0],
limit = 3
)

Consulta Relacionada con Vehículos
Esta vez hemos dado un pregunta relacionado con vehículos la base de datos vectorial pudo recuperar con éxito los documentos de la categoría correspondiente (automóvil) en la parte superior. ¿Y ahora qué pasa si queremos hacer algún filtrado? Podemos hacer esto mediante:
from qdrant_client.http.models import Filter, FieldCondition, MatchValue
query = model.encode(['Animals live in the forest'])
custom_filter = Filter(
must = [
FieldCondition(
key = "category",
match = MatchValue(
value="animals"
),
)
]
)
- En primer lugar, estamos creando nuestra consulta incrustada/vectorial.
- Aquí importamos el Filtrar, Condición de campoy Valor de coincidencia clases de la biblioteca qdrant.
- Filtrar: Utilice esta clase para crear un objeto Filtro
- Condición archivada: Esta clase es para crear el filtrado, como por ejemplo sobre lo que queremos filtrar en nuestra búsqueda.
- Valor de coincidencia: Esta clase es para indicar qué valor para una clave determinada queremos que filtre el vector qdrant db
Entonces, en el código anterior, básicamente estamos diciendo que estamos creando un Filtrar que comprueba el Condición de campo que la clave”categoría"En el carga útil partidos(Valor de coincidencia) el valor "animales”. Esto parece un poco grande para un filtro simple, pero este enfoque hará que nuestro código esté más estructurado cuando estemos tratando con un carga útil contiene mucha información y queremos filtrar según varias claves. Ahora usemos el filtro en nuestra búsqueda.
client.search(
collection_name = "my-collection",
query_vector = query[0],
query_filter = custom_filter,
limit = 4
)
Filtro_consulta
Aquí, esta vez, incluso cedemos un filtro_consulta variable que toma en cuenta la Filtro personalizado que hemos definido. Tenga en cuenta que hemos mantenido un límite de 4 para recuperar los 4 documentos coincidentes principales. La consulta está relacionada con los animales. Al ejecutar el código se obtendrá el siguiente resultado:

En el resultado, hemos recibido solo los 3 documentos más cercanos, aunque tenemos 5 documentos. Esto se debe a que hemos configurado nuestro filtro para elegir solo las categorías de animales y solo hay 3 documentos con esa categoría. De esta manera podemos almacenar las incrustaciones de vectores en la nube qdrant, realizar una búsqueda de vectores en estos vectores de incrustación, recuperar los más cercanos e incluso aplicar filtros para filtrar la salida:
Aplicaciones
Las siguientes aplicaciones pueden ser Qdrant Vector Database:
- Sistemas de recomendación: Qdrant puede impulsar motores de recomendación al hacer coincidir de manera eficiente vectores de alta dimensión, lo que lo hace adecuado para recomendaciones de contenido personalizadas en plataformas como servicios de transmisión, comercio electrónico o redes sociales.
- Recuperación de imágenes y multimedia: Aprovechando la capacidad de Qdrant para manejar vectores que representan imágenes y contenido multimedia, las aplicaciones pueden implementar funcionalidades efectivas de búsqueda y recuperación para bases de datos de imágenes o archivos multimedia.
- Aplicaciones de procesamiento del lenguaje natural (PLN): El soporte de Qdrant para incrustaciones de vectores lo hace valioso para tareas de PNL, como búsqueda semántica, comparación de similitudes de documentos y recomendación de contenido en aplicaciones que manejan grandes cantidades de conjuntos de datos textuales.
- Detección de anomalías: La búsqueda de vectores de alta dimensión de Qdrant se puede utilizar en sistemas de detección de anomalías. Al comparar los vectores que representan el comportamiento normal con los datos entrantes, se pueden identificar anomalías en campos como la seguridad de la red o el monitoreo industrial.
- Búsqueda y emparejamiento de productos: En las plataformas de comercio electrónico, Qdrant puede mejorar las capacidades de búsqueda de productos al hacer coincidir vectores que representan características del producto, facilitando recomendaciones de productos precisas y eficientes basadas en las preferencias del usuario.
- Filtrado basado en contenidos en redes sociales: La búsqueda vectorial de Qdrant se puede aplicar en redes sociales para filtrado basado en contenido. Los usuarios pueden obtener contenido relevante basado en la similitud de las representaciones vectoriales, lo que mejora la participación del usuario.
Conclusión
A medida que crece la demanda de una representación eficiente de los datos, Qdrant se destaca por ser un motor de búsqueda de similitudes vectoriales repleto de funciones de código abierto, escrito en el lenguaje robusto y centrado en la seguridad, Rust. Qdrant incluye todas las métricas de distancia populares y proporciona una forma sólida de filtrar nuestra búsqueda de vectores. Con sus ricas funciones, arquitectura nativa de la nube y terminología sólida, Qdrant abre las puertas a una nueva era en la tecnología de búsqueda de similitudes vectoriales. Aunque es nuevo en el campo, proporciona bibliotecas cliente para muchos lenguajes de programación y proporciona una nube que escala eficientemente con el tamaño.
Puntos clave
Algunas de las conclusiones clave incluyen:
- Fabricado en Rust, Qdrant garantiza velocidad y confiabilidad, incluso bajo cargas pesadas, lo que lo convierte en la mejor opción para almacenes de vectores de alto rendimiento.
- Lo que distingue a Qdrant es su soporte para API de cliente, dirigido a desarrolladores en Python, TypeScript/JavaScript, Rust y Go.
- Qdrant aprovecha el algoritmo HSNW y ofrece diferentes métricas de distancia, incluidas Dot, Cosine y Euclidiana, lo que permite a los desarrolladores elegir la métrica que se alinee con sus casos de uso específicos.
- Qdrant realiza una transición fluida a la nube con un servicio de nube escalable, que brinda una opción de exploración de nivel gratuito. Su arquitectura nativa de la nube garantiza un rendimiento óptimo, independientemente del volumen de datos.
Preguntas frecuentes
R: Qdrant es un motor de búsqueda de similitudes de vectores y una tienda de vectores escrito en Rust. Se destaca por su velocidad, confiabilidad y soporte completo para el cliente, ya que proporciona API para Python, TypeScript/JavaScript, Rust y Go.
R: Qdrant utiliza el algoritmo HSNW y proporciona diferentes métricas de distancia como punto, coseno y euclidiana. Los desarrolladores pueden elegir la métrica que se alinee con sus casos de uso específicos al crear colecciones.
R: Los componentes importantes incluyen colecciones, métricas de distancia, puntos (vectores, ID opcionales y cargas útiles) y opciones de almacenamiento (en memoria y mapa de memoria).
R: Sí, Qdrant se integra perfectamente con los servicios en la nube, proporcionando una solución en la nube escalable. La arquitectura nativa de la nube garantiza un rendimiento óptimo, lo que permite realizar cambios según los distintos volúmenes de datos y necesidades computacionales.
R: Qdrant permite filtrar la información de la carga útil. Los usuarios pueden definir filtros utilizando la biblioteca Qdrant, dando condiciones basadas en claves de carga útil y valores para refinar los resultados de búsqueda.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/11/a-deep-dive-into-qdrant-the-rust-based-vector-database/

