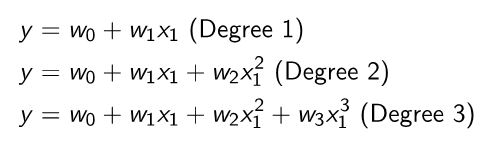Este artículo está basado en el capítulo del IA interpretable Libro de Ajay Thampi. 35% de descuento IA interpretable o cualquier otro producto de Manning ingresando bltopbots23 en el cuadro de código de descuento al finalizar la compra en manning.com.
Diagnóstico+ IA – Progresión de la diabetes
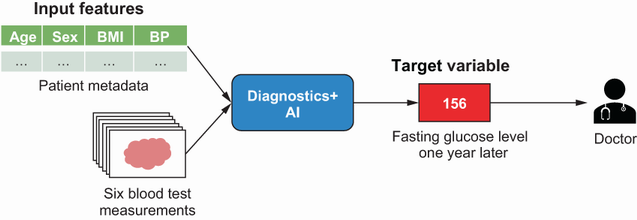
Imagine que está desarrollando una aplicación impulsada por IA que lo ayudará a diagnosticar enfermedades: Diagnostics+. A la clínica que le encargó la creación de la aplicación ahora le gustaría incursionar en la diabetes y determinar la progresión de la enfermedad para sus pacientes un año después de tomar la medición inicial. Esto se muestra en la Figura 1. La clínica ahora le ha asignado la tarea de crear un modelo para Diagnostics+ AI para predecir la progresión de la diabetes dentro de un año. Los médicos utilizarán esta predicción para determinar un plan de tratamiento adecuado para sus pacientes. Para ganarse la confianza de los médicos en el modelo, es importante no solo proporcionar una predicción precisa, sino también poder mostrar cómo llegó el modelo a esa predicción. Entonces, ¿cómo comenzarías con esta tarea?
Figura 1: Diagnóstico+ IA para la diabetes
Primero, veamos qué datos están disponibles. El centro Diagnostics+ ha recopilado datos de alrededor de 440 pacientes, que consisten en metadatos de pacientes como su edad, sexo, índice de masa corporal (IMC) y presión arterial (PA). También se realizaron análisis de sangre a estos pacientes y se recogieron las siguientes seis mediciones:
LDL (el colesterol malo)
HDL (el colesterol bueno)
Colesterol total
Hormona estimulante de la tiroides
Glaucoma de baja tensión
Glucosa en sangre en ayunas
Los datos también contienen los niveles de glucosa en ayunas para todos los pacientes un año después de que se tomó la medición inicial. Este es el destino del modelo. Ahora, ¿cómo formularías esto como un problema de aprendizaje automático? Dado que los datos etiquetados están disponibles donde se le dan 10 características de entrada y una variable objetivo que debe predecir, podemos formular este problema como un problema de aprendizaje supervisado. Dado que la variable objetivo es de valor real o continua, es una tarea de regresión. El objetivo es aprender una función que ayudará a predecir la variable objetivo dadas las características de entrada.
Ahora carguemos los datos en Python y exploremos qué tan correlacionadas están las características de entrada entre sí y con la variable de destino. Si las características de entrada están altamente correlacionadas con la variable de destino, entonces podemos usarlas para entrenar un modelo para hacer la predicción. Sin embargo, si no están correlacionados con la variable objetivo, tendremos que explorar más para determinar si hay algo de ruido en los datos. Los datos se pueden cargar en Python de la siguiente manera.
from sklearn.datasets import load_diabetes #A
diabetes = load_diabetes() #B
X, y = diabetes[‘data’], diabetes[‘target’] #C #A Import scikit-learn function to load open diabetes dataset
#B Load the diabetes dataset
#C Extract the features and the target variable
Ahora crearemos un DataFrame de pandas, que es una estructura de datos bidimensional que contiene todas las funciones y la variable de destino. El conjunto de datos de diabetes proporcionado por scikit-learn viene con nombres de características que no son fáciles de entender. Las seis mediciones de muestras de sangre se denominan s1, s2, s3, s4, s5 y s6 y es difícil para nosotros entender qué mide cada característica. Sin embargo, la documentación proporciona este mapeo y lo usaremos para cambiar el nombre de las columnas a algo que sea más comprensible.
feature_rename = {'age': 'Age', #A 'sex': 'Sex', #A 'bmi': 'BMI', #A 'bp': 'BP', #A 's1': 'Total Cholesterol', #A 's2': 'LDL', #A 's3': 'HDL', #A 's4': 'Thyroid', #A 's5': 'Glaucoma', #A 's6': 'Glucose'} #A df_data = pd.DataFrame(X, #B columns=diabetes['feature_names']) #C
df_data.rename(columns=feature_rename, inplace=True) #D
df_data['target'] = y #E #A: Mapping of feature names provided by scikit-learn to a more readable form
#B: Load all the features (X) into a DataFrame
#C: Use the scikit-learn feature names as column names
#D: Rename the scikit-learn feature names to a more readable form
#E: Include the target variable (y) as a separate column
Ahora calculemos la correlación por pares de columnas para que podamos determinar qué tan correlacionadas están cada una de las características de entrada entre sí y con la variable de destino. Esto se puede hacer en pandas fácilmente de la siguiente manera.
corr = df_data.corr()
De forma predeterminada, la función corr() en pandas calcula el coeficiente de correlación estándar o de Pearson. Este coeficiente mide la correlación lineal entre dos variables y tiene un valor entre +1 y -1. Si la magnitud del coeficiente es superior a 0.7, eso significa una correlación realmente alta. Si la magnitud del coeficiente está entre 0.5 y 0.7, eso significa una correlación moderadamente alta. Si la magnitud del coeficiente está entre 0.3 y 0.5, significa una correlación baja y una magnitud es inferior a 0.3, significa poca o ninguna correlación. Ahora podemos trazar la matriz de correlación en Python de la siguiente manera.
import matplotlib.pyplot as plt #A
import seaborn as sns #A
sns.set(style=’whitegrid’) #A
sns.set_palette(‘bright’) #A f, ax = plt.subplots(figsize=(10, 10)) #B
sns.heatmap( #C corr, #C vmin=-1, vmax=1, center=0, #C cmap="PiYG", #C square=True, #C ax=ax #C
) #C
ax.set_xticklabels( #D ax.get_xticklabels(), #D rotation=90, #D horizontalalignment='right' #D
); #D #A Import matplotlib and seaborn to plot the correlation matrix
#B Initialize a matplotlib plot with a predefined size
#C Use seaborn to plot a heatmap of the correlation coefficients
#D Rotate the labels on the x-axis by 90 degrees
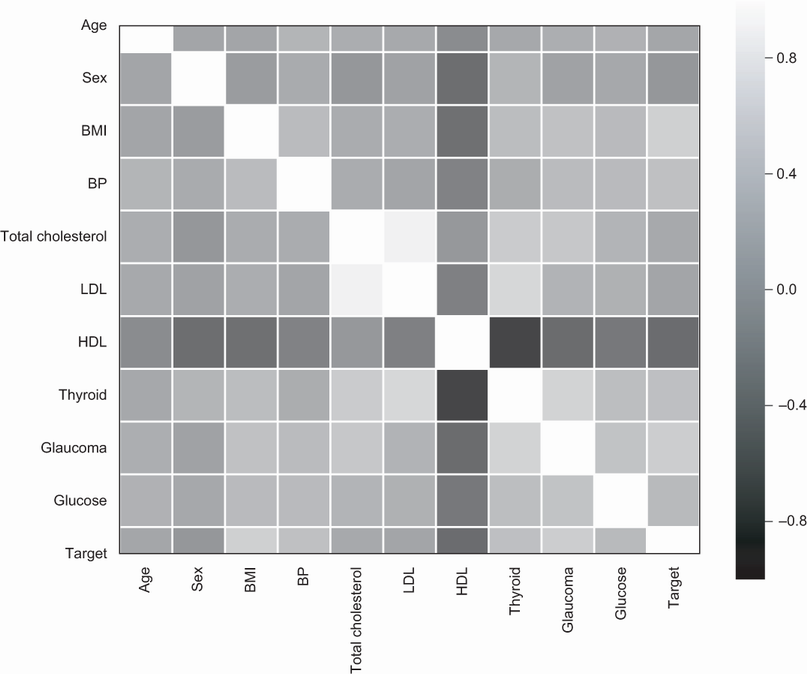
El gráfico resultante se muestra en la Figura 2. Primero, centrémonos en la última fila o en la última columna de la figura. Esto nos muestra la correlación de cada una de las entradas con la variable objetivo. Podemos ver que siete funciones, a saber, IMC, PA, colesterol total, HDL, tiroides, glaucoma y glucosa, tienen una correlación entre moderadamente alta y alta con la variable objetivo. También podemos observar que el colesterol bueno (HDL) también tiene una correlación negativa con la progresión de la diabetes. Esto significa que cuanto mayor sea el valor de HDL, menor será el nivel de glucosa en ayunas para el paciente un año después. Por lo tanto, las características parecen tener una señal bastante buena para poder predecir la progresión de la enfermedad y podemos seguir adelante y entrenar un modelo usándolas. Como ejercicio, observe cómo cada una de las características se correlaciona entre sí. El colesterol total, por ejemplo, parece muy relacionado con el colesterol malo, LDL.
Figura 2: Gráfica de correlación de las características y la variable objetivo para el conjunto de datos de diabetes
Modelos aditivos generalizados (GAM)
Imaginemos que ha estado experimentando con modelos para Diagnóstico+ y proyecciones de diabetes y ha descubierto algunas deficiencias. Probó un modelo de regresión lineal, pero no parecía manejar características que están altamente correlacionadas entre sí, como el colesterol total, LDL y HDL. Luego, probó un modelo de árbol de decisión, pero funcionó incluso peor que la regresión lineal y parecía haberse sobreajustado en sus datos de entrenamiento.
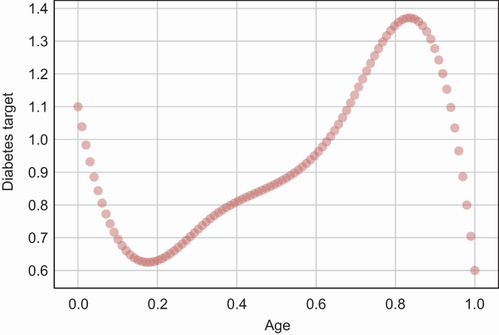
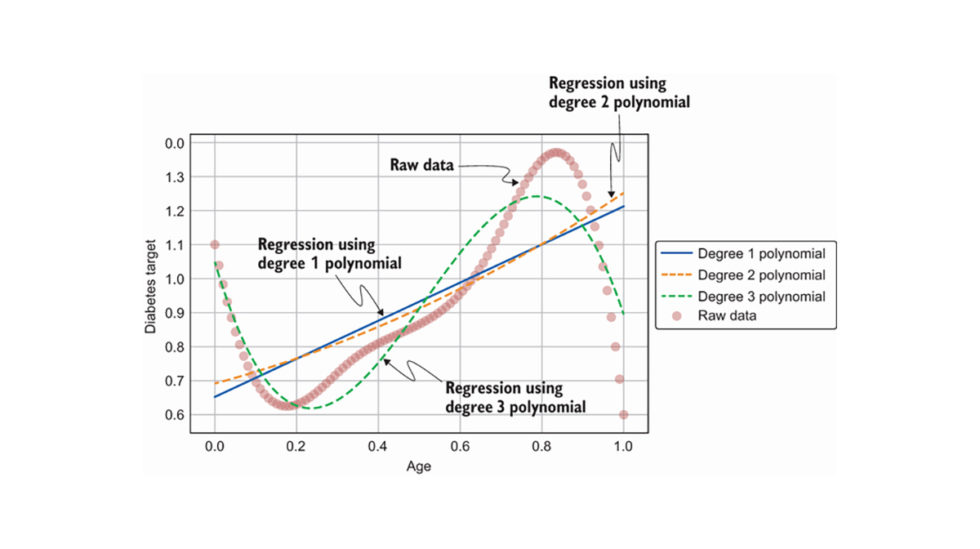
Usando algunos datos imaginarios de la diabetes, echemos un vistazo más de cerca a la situación. La Figura 3 muestra un ejemplo artificial de una relación no lineal entre la edad y la variable objetivo, donde ambas variables están normalizadas. ¿Cómo modelarías mejor esta relación sin sobreajustar? Un enfoque posible es extender el modelo de regresión lineal donde la variable objetivo se modela como un nth polinomio de grado del conjunto de características. Esta forma de regresión se llama regresión polinomial.
Figura 3: Ilustración de una relación no lineal para Diagnostics+ AI
La regresión polinomial para polinomios de varios grados se muestra en las siguientes ecuaciones. En las ecuaciones a continuación, estamos considerando solo una característica para modelar la variable objetivo . El polinomio de grado 1 es lo mismo que la regresión lineal. Para el polinomio de grado 2, agregaríamos una característica adicional que es el cuadrado de . Para el polinomio de grado 3, agregaríamos dos características adicionales, una que es el cuadrado de y el otro que es el cubo de .
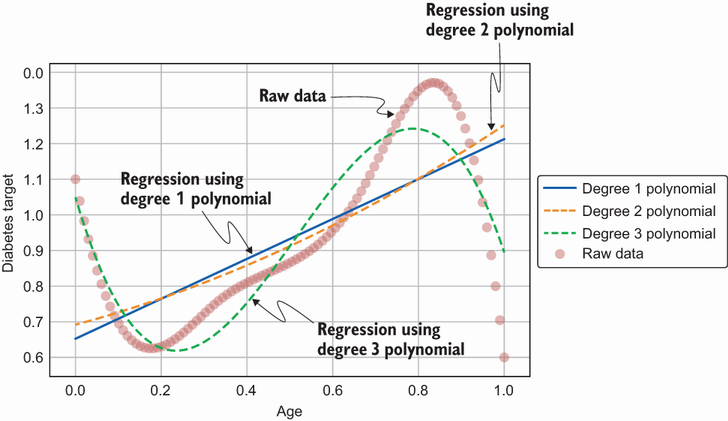
Los pesos para el modelo de regresión polinomial se pueden obtener usando el mismo algoritmo que la regresión lineal, es decir, el método de mínimos cuadrados usando descenso de gradiente. El mejor ajuste aprendido por cada uno de los tres polinomios se muestra en la Figura 4. Podemos ver que el polinomio de grado 3 se ajusta mejor a los datos sin procesar que los grados 2 y 1. Podemos interpretar un modelo de regresión polinomial de la misma manera que una regresión lineal ya que el El modelo es esencialmente una combinación lineal de las características, incluidas las características de mayor grado.
Figura 4: Regresión polinomial para modelar una relación no lineal
Sin embargo, la regresión polinomial tiene algunas limitaciones. La complejidad del modelo aumenta a medida que aumenta el número de características o la dimensión del espacio de características. Por lo tanto, tiene una tendencia a sobreajustarse en los datos. También es difícil determinar el grado de cada característica en el polinomio, especialmente en un espacio de características de mayor dimensión.
Entonces, ¿qué modelo se puede aplicar para superar todas estas limitaciones y eso es interpretable? ¡Ingrese, modelos aditivos generalizados (GAM)! Los GAM son modelos con un poder predictivo medio-alto y que son altamente interpretables. Las relaciones no lineales se modelan usando funciones de suavizado para cada característica y añadiéndolas todas. Esto se muestra en la siguiente ecuación.
En la ecuación anterior, cada función tiene su propia función de suavizado asociada que modela mejor la relación entre esa función y el objetivo. Hay muchos tipos de funciones de suavizado entre las que puede elegir, pero una función de suavizado ampliamente utilizada se llama splines de regresión ya que son prácticos y computacionalmente eficientes. Me centraré en splines de regresión a lo largo del libro. ¡Profundicemos ahora en el mundo de los GAM usando splines de regresión!
Splines de regresión
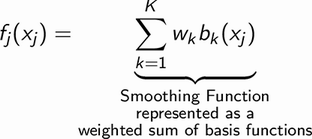
Los splines de regresión se representan como una suma ponderada de funciones lineales o polinómicas. Estas funciones polinómicas también se conocen como funciones base. Esto se muestra matemáticamente a continuación. En la ecuación, es la función que modela la relación entre la característica y la variable objetivo. Esta función se representa como una suma ponderada de funciones base donde el peso se representa como y la función base se representa como . En el contexto de los GAM, la función se llama función de suavizado.
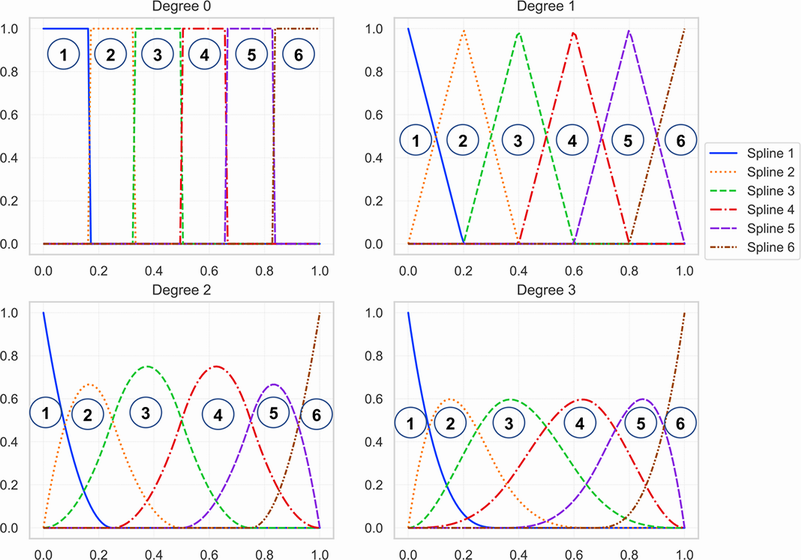
Ahora bien, ¿qué es una función base? Una función base es una familia de transformaciones que se pueden utilizar para capturar una forma general o una relación no lineal. Para las splines de regresión, como su nombre indica, las splines se utilizan como función base. Un spline es un polinomio de grado derivadas continuas. Será mucho más fácil entender las splines usando una ilustración. La Figura 3 muestra splines de varios grados. El gráfico superior izquierdo muestra la spline más simple de grado 0, a partir de la cual se pueden generar splines de mayor grado. Como puede ver en el gráfico superior izquierdo, se han colocado seis splines en una cuadrícula. La idea es dividir la distribución de los datos en porciones y ajustar una spline en cada una de esas porciones. Entonces, en esta ilustración, los datos se han dividido en seis partes y estamos modelando cada parte como una spline de grado 0.
Se puede generar una spline de grado 1, que se muestra en el gráfico superior derecho, convolucionando una spline de grado 0 consigo misma. La convolución es una operación matemática que toma dos funciones y crea una tercera función que representa la correlación de la primera función y una copia retrasada de la segunda función. Cuando convolucionamos una función consigo misma, esencialmente observamos la correlación de la función con una copia retrasada de sí misma. Hay una buena entrada de blog de Christopher Olah en circunvoluciones. Esto animación en Wikipedia también le dará una buena comprensión intuitiva. Al convolucionar una spline de grado 0 consigo misma, obtenemos una spline de grado 1 que tiene forma triangular, y tiene un 0 continuoth derivada de orden.
Si ahora convolucionamos una spline de grado 1 consigo misma, obtendremos una spline de grado 2 que se muestra en el gráfico inferior izquierdo. Esta spline de grado 2 tiene un 1 continuost derivada de orden. De manera similar, podemos obtener una spline de grado 3 convolucionando una spline de grado 2 y esta tiene una curva continua de 2nd derivada de orden. En general, un grado spline tiene un continuo derivado. en el límite como tiende a infinito, obtendremos un spline que tiene la forma de una distribución gaussiana. En la práctica, grado 3 or estrías cúbicas se utilizan ya que pueden capturar la mayoría de las formas generales.
Como se mencionó anteriormente, en la Figura 5 hemos dividido la distribución de datos en seis partes y hemos colocado seis splines en la cuadrícula. En la ecuación matemática anterior, el número de porciones o splines se representa como variable . La idea detrás de las splines de regresión es aprender los pesos de cada una de las splines para poder modelar la distribución de los datos en cada una de las porciones. El número de porciones o splines en la cuadrícula, , es tambien llamado grados de libertad. En general, si colocamos estos splines en una grilla, tendremos puntos de división, también conocidos como nudos.
Figura 5: Ilustración de Splines de Grado 0, Grado 1, Grado 2 y Grado 3
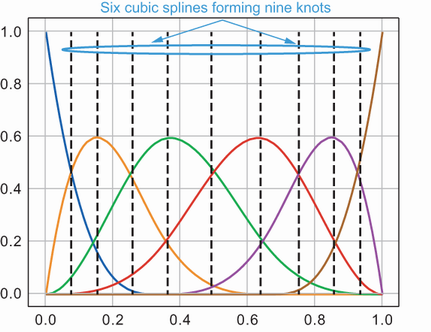
Ahora hagamos zoom en las splines cúbicas como se muestra en la Figura 6. Podemos ver que hay 6 splines o 6 grados de libertad que dan como resultado 9 puntos de división o nudos.
Figura 6: Ilustración de splines y nudos
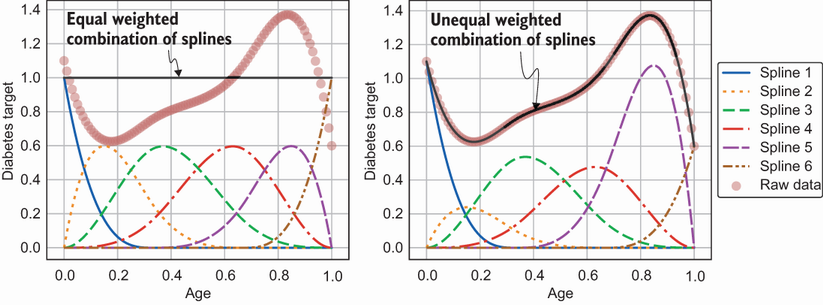
Ahora, para capturar una forma general, necesitaremos tomar una suma ponderada de las splines. Usaremos splines cúbicos aquí. En la Figura 7, estamos usando las mismas 6 estrías superpuestas para crear 9 nudos. Para el gráfico de la izquierda, he establecido los mismos pesos para las 6 splines. Como puedes imaginar, si tomamos una suma igualmente ponderada de las 6 splines, obtendremos una línea recta horizontal. Esta es una ilustración de un mal ajuste a los datos sin procesar. Sin embargo, para el gráfico de la derecha, he tomado una suma ponderada desigual de las 6 splines generando una forma que se ajusta perfectamente a los datos sin procesar. Esto muestra el poder de las splines de regresión y los GAM. Al aumentar el número de splines o al dividir los datos en más porciones, tendremos la capacidad de modelar relaciones no lineales más complejas. En los GAM basados en splines de regresión, modelamos individualmente las relaciones no lineales de cada característica con la variable de destino y luego las sumamos todas para llegar a la predicción final.
Figura 7: Splines para modelar una relación no lineal
En la Figura 7, los pesos se determinaron mediante prueba y error para describir mejor los datos sin procesar. Pero, ¿cómo determina algorítmicamente los pesos para una spline de regresión que captura mejor la relación entre las características y el objetivo? Recuerde de lo anterior que una spline de regresión es una suma ponderada de funciones de base o splines. Este es esencialmente un problema de regresión lineal y puede aprender los pesos utilizando el método de mínimos cuadrados y descenso de gradiente. Sin embargo, necesitaríamos especificar el número de nudos o grados de libertad. Podemos tratar esto como un hiperparámetro y determinarlo usando una técnica llamada validación cruzada. Mediante la validación cruzada, eliminaríamos una parte de los datos y ajustaríamos una spline de regresión con una cierta cantidad de nudos predeterminados en los datos restantes. Este spline de regresión luego se evalúa en el conjunto reservado. El número óptimo de nudos es el que da como resultado el mejor rendimiento en el conjunto sostenido.
En GAM, puede sobreajustar fácilmente aumentando el número de splines o grados de libertad. Si el número de splines es alto, la función de suavizado resultante, que es una suma ponderada de las splines, sería bastante 'ondulada', es decir, comenzaría a ajustar parte del ruido en los datos. ¿Cómo podemos controlar esta ondulación o evitar el sobreajuste? Esto se puede hacer a través de una técnica llamada regularización. En la regularización, agregaríamos un término a la función de costo de mínimos cuadrados que cuantifica la ondulación. La ondulación de una función de suavizado se puede cuantificar tomando la integral del cuadrado de los 2nd Derivada de orden de la función. Luego, usando un hiperparámetro (también llamado parámetro de regularización) representado por , podemos ajustar la intensidad de la ondulación. Un valor alto para penaliza fuertemente la ondulación. podemos determinar de la misma manera determinamos otros hiperparámetros mediante validación cruzada.
Resumen de GAM
Un GAM es un modelo poderoso en el que la variable de destino se representa como una suma de funciones de suavizado que representan la relación de cada una de las características y el objetivo. La función de suavizado se puede utilizar para capturar cualquier relación no lineal. Esto se muestra matemáticamente de nuevo a continuación.
Es un modelo de caja blanca, ya que podemos ver fácilmente cómo cada característica se transforma en la salida mediante la función de suavizado. Una forma común de representar la función de suavizado es usar splines de regresión. Un spline de regresión se representa como una simple suma ponderada de funciones de base. Una función base que se usa ampliamente para GAM es el spline cúbico. Al aumentar el número de splines o grados de libertad, podemos dividir la distribución de datos en pequeñas porciones y modelar cada porción por partes. De esta manera podemos capturar relaciones no lineales bastante complejas. El algoritmo de aprendizaje esencialmente tiene que determinar los pesos para el spline de regresión. Podemos hacer esto de la misma manera que la regresión lineal usando el método de mínimos cuadrados y descenso de gradiente. Podemos determinar el número de splines utilizando la técnica de validación cruzada. A medida que aumenta el número de splines, los GAM tienden a sobreajustarse en los datos. Podemos protegernos contra esto usando la técnica de regularización. Usando un parámetro de regularización, podemos controlar la cantidad de ondulación. Más alto asegura una función más suave. El parámetro también se puede determinar mediante validación cruzada.
Los GAM también se pueden usar para modelar interacciones entre variables. GA2M es un tipo de GAM que modela interacciones por pares. Se muestra matemáticamente a continuación.
Con la ayuda de los expertos en la materia (SME), los médicos del ejemplo de Diagnostics+, puede determinar qué interacciones de funciones deben modelarse. También puede observar la correlación entre las características para comprender qué características deben modelarse juntas.
En Python, hay un paquete llamado pyGAM que puede usar para crear y entrenar GAM. Está inspirado en la implementación de GAM en el popular paquete mgcv en R. Puede instalar pyGAM en su entorno Python usando el paquete pip de la siguiente manera.
pip install pygam
GAM para Diagnóstico+ Diabetes
Ahora volvamos al ejemplo de Diagnóstico+ para entrenar un GAM para predecir la progresión de la diabetes usando las 10 funciones. Es importante señalar que el sexo del paciente es un rasgo categórico o discreto. No tiene sentido modelar esta característica utilizando una función de suavizado. Podemos tratar tales características categóricas en GAM como términos factoriales. El GAM se puede entrenar usando el paquete pyGAM de la siguiente manera. Consulte el principio del artículo para conocer el código que carga el conjunto de datos de diabetes y lo divide en los conjuntos de entrenamiento y prueba.
from pygam import LinearGAM #A
from pygam imports #B
from pygam import f #C # Load data using the code snippet in Section 2.2 gam = LinearGAM(s(0) + #D f(1) + #E s(2) + #F s(3) + #G s(4) + #H s(5) + #I s(6) + #J s(7) + #K s(8) + #L s(9), #M n_splines=35) #N gam.gridsearch(X_train, y_train) #O y_pred = gam.predict(X_test) #P mae = np.mean(np.abs(y_test - y_pred)) #Q #A Import the LinearGAM class from pygam that can be used to train a GAM for regression tasks
#B Import the smoothing term function to be used for numerical features
#C Import the factor term function to be used for categorical features
#D Cubic spline term for the Age feature
#E Factor term for the Sex feature which is categorical
#F Cubic splineterm for the BMI feature
#G Cubic spline term for the BP feature
#H Cubic spline term for the Total Cholesterol feature
#I Cubic spline term for the LDL feature
#J Cubic spline term for the HDL feature
#K Cubic spline term for the Thyroid feature
#L Cubic spline term for the Glaucoma feature
#M Cubic spline term for the Glucose feature
#N Maximum number of splines to be used for each feature
#O Using grid search to perform training and cross-validation to determine the number of splines, the regularization parameter lambda and the optimum weights for the regression splines for each feature
#P Use trained GAM model to predict on the test
#Q Evaluate the performance of the model on the test set using the MAE metric
Ahora para el momento de la verdad! ¿Cómo se desempeñó el GAM? El rendimiento MAE del GAM es 41.4, una mejora bastante buena en comparación con los modelos de árbol de decisión y regresión lineal. En la Tabla 3 se resume una comparación del rendimiento de los 1 modelos. También incluí el rendimiento de un modelo de referencia que Diagnostics+ y los médicos han estado usando en el que observaron la mediana de la progresión de la diabetes en todos los pacientes. Todos los modelos se comparan con la línea de base para mostrar la mejora que los modelos brindan a los médicos. ¡Parece que GAM es el mejor modelo en todas las métricas de rendimiento!
MAE
RMSE
MAPE
Base
62.2
74.7
51.6
Regresión lineal
42.8 (-19.4)
53.8 (-20.9)
37.5 (-14.1)
Árbol de decisión
48.6 (-13.6)
60.5 (-14.2)
44.4 (-7.2)
GAM
41.4 (-20.8)
52.2 (-22.5)
35.7 (-15.9)
Tabla 1: Comparación de rendimiento de regresión lineal, árbol de decisiones y GAM frente a una línea de base para diagnósticos+ IA
Ahora hemos visto el poder predictivo de los GAM. Potencialmente, podríamos obtener una mejora adicional en el rendimiento al modelar las interacciones de las características, especialmente las características del colesterol entre sí y con otras características que potencialmente están altamente correlacionadas, como el IMC. Como ejercicio, le recomiendo encarecidamente que intente modelar las interacciones de características utilizando GAM.
Los GAM son de caja blanca y se pueden interpretar fácilmente. En la siguiente sección, veremos cómo se pueden interpretar los GAM.
GAMs para Tareas de Clasificación
Los GAM también se pueden usar para entrenar un clasificador binario usando la función de enlace logístico donde la respuesta puede ser 0 o 1. En el paquete pyGAM, puede usar el GAM logístico para problemas de clasificación binaria.
from pygam import LogisticGAM gam = LogisticGAM() gam.gridsearch(X_train, y_train)
Interpretación de GAM
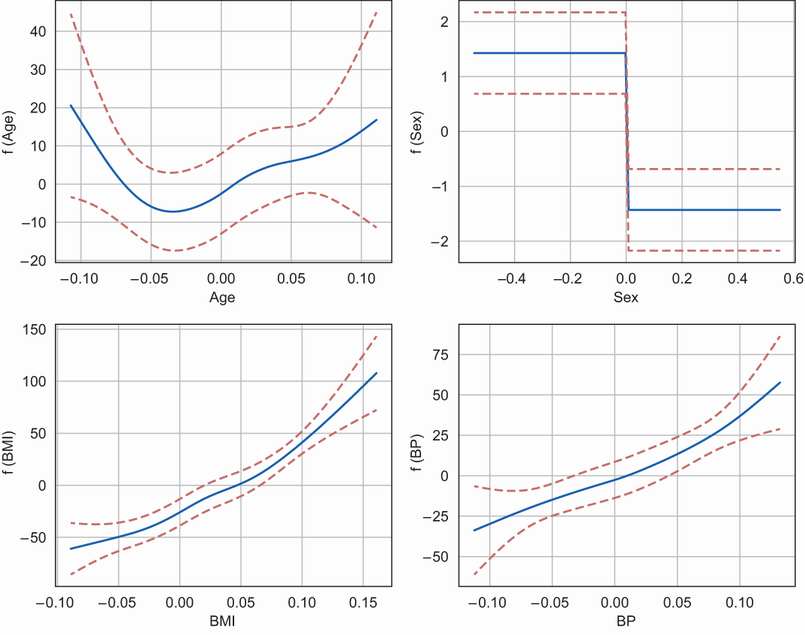
Aunque cada función de suavizado se obtiene como una combinación lineal de funciones básicas, la función de suavizado final para cada característica no es lineal y, por lo tanto, no podemos interpretar los pesos de la misma manera que una regresión lineal. Sin embargo, podemos visualizar fácilmente los efectos de cada función en el objetivo utilizando gráficas de dependencia parcial o efectos parciales. La dependencia parcial analiza el efecto de cada característica al marginar al resto. Es altamente interpretable ya que podemos ver el efecto promedio de cada valor de característica en la variable de destino. Podemos ver si la respuesta del objetivo a la función es lineal, no lineal, monotónica o no monotónica. La Figura 8 muestra el efecto de cada uno de los metadatos del paciente en la variable objetivo. También se ha trazado el intervalo de confianza del 95 % alrededor de ellos. Esto nos ayudará a determinar la sensibilidad del modelo a los puntos de datos con un tamaño de muestra bajo.
Veamos ahora un par de características en la Figura 8, a saber, IMC y BP. El efecto del IMC en la variable objetivo se muestra en el gráfico inferior izquierdo. En el eje x, vemos los valores normalizados de IMC y en el eje y, vemos el efecto que tiene el IMC en la progresión de la diabetes del paciente. Vemos que a medida que aumenta el IMC, también aumenta el efecto sobre la progresión de la diabetes. Vemos una tendencia similar para la PA que se muestra en el gráfico inferior derecho. Vemos que a mayor PA, mayor impacto en la progresión de la diabetes. Si observamos las líneas internas de confianza del 95% (las líneas discontinuas en la Figura 8), vemos una confianza interna más amplia alrededor de los extremos superior e inferior del IMC y la PA. Esto se debe a que hay menos muestras de pacientes en este rango de valores, lo que genera una mayor incertidumbre en la comprensión de los efectos de estas características en esos rangos.
Figura 8: Efecto de cada uno de los metadatos del paciente en la variable objetivo
El código para generar la Figura 8 es el siguiente.
grid_locs1 = [(0, 0), (0, 1), #A (1, 0), (1, 1)] #A
fig, ax = plt.subplots(2, 2, figsize=(10, 8)) #B
for i, feature in enumerate(feature_names[:4]): #C gl = grid_locs1[i] #D XX = gam.generate_X_grid(term=i) #E ax[gl[0], gl[1]].plot(XX[:, i], gam.partial_dependence(term=i, X=XX)) #F ax[gl[0], gl[1]].plot(XX[:, i], gam.partial_dependence(term=i, X=XX, width=.95)[1], c='r', ls='--') #G ax[gl[0], gl[1]].set_xlabel('%s' % feature) #H ax[gl[0], gl[1]].set_ylabel('f ( %s )' % feature) #H #A Locations of the 4 graphs in the 2x2 matplotlib grid
#B Create 2x2 grid of matplotlib graphs
#C Iterate through the 4 patient metadata features
#D Get location of feature in the 2x2 grid
#E Generate the partial dependence of the feature values with the target marginalizing on the other features
#F Plot the partial dependence values as a solid line
#G Plot the 95% confidence interval around the partial dependence values as a dashed line
#H Add labels for the x and y axes
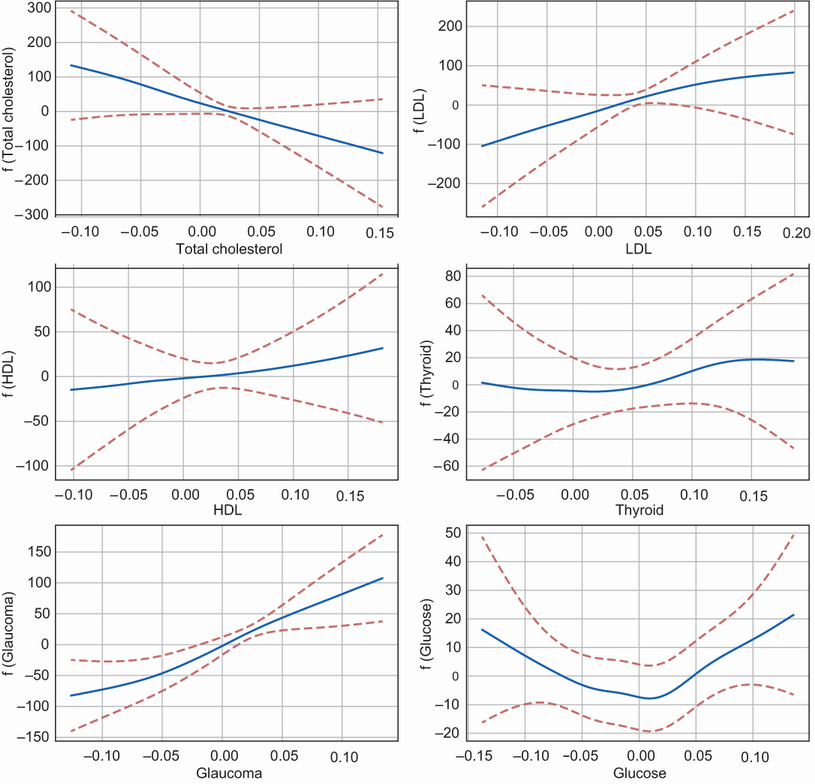
La figura 9 muestra el efecto de cada una de las 6 mediciones de análisis de sangre en el objetivo. Como ejercicio, observe los efectos que tienen características como el colesterol total, LDL, HDL y glaucoma en la progresión de la diabetes. ¿Qué puede decir sobre el impacto de valores más altos de LDL (o colesterol malo) en la variable objetivo? ¿Por qué un colesterol total más alto tiene un impacto menor en la variable objetivo? Para responder a estas preguntas, veamos algunos casos de pacientes con valores de colesterol muy altos. El fragmento de código a continuación lo ayudará a acercarse a esos pacientes.
Si ejecuta el código anterior, verá solo 1 paciente de 442 que tiene una lectura de colesterol total superior a 0.15 y una lectura de LDL superior a 0.19. El nivel de glucosa en ayunas para este paciente un año después (la variable objetivo) parece ser 84, que está en el rango normal. Esto podría explicar por qué en la Figura 9 vemos un efecto negativo muy grande para el colesterol total en la variable objetivo para un rango mayor a 0.15. El efecto negativo del colesterol total parece ser mayor que el efecto positivo que parece tener el colesterol LDL malo sobre el objetivo. El intervalo de confianza parece mucho más amplio en este rango de valores. Es posible que el modelo se haya sobreajustado en este registro de paciente atípico y, por lo tanto, no debemos leer demasiado sobre estos efectos. Al observar estos efectos, podemos identificar casos o rangos de valores donde el modelo está seguro de la predicción y casos donde hay una alta incertidumbre. Para casos de alta incertidumbre, podemos volver al centro de diagnóstico para recopilar más datos del paciente para tener una muestra representativa.
Figura 9: Efecto de cada una de las mediciones de análisis de sangre en la variable objetivo
El código para generar la Figura 9 es el siguiente.
grid_locs2 = [(0, 0), (0, 1), #A (1, 0), (1, 1), #A (2, 0), (2, 1)] #A
fig2, ax2 = plt.subplots(3, 2, figsize=(12, 12)) #B
for i, feature in enumerate(feature_names[4:]): #C idx = i + 4 #D gl = grid_locs2[i] #D XX = gam.generate_X_grid(term=idx) #E ax2[gl[0], gl[1]].plot(XX[:, idx], gam.partial_dependence(term=idx, X=XX)) #F ax2[gl[0], gl[1]].plot(XX[:, idx], gam.partial_dependence(term=idx, X=XX, width=.95)[1], c='r', ls='--') #G ax2[gl[0], gl[1]].set_xlabel('%s' % feature) #H ax2[gl[0], gl[1]].set_ylabel('f ( %s )' % feature) #H #A Locations of the 6 graphs in the 3x2 matplotlib grid
#B Create 3x2 grid of matplotlib graphs
#C Iterate through the 6 blood test measurement features
#D Get location of feature in the 3x2 grid
#E Generate the partial dependence of the feature values with the target marginalizing on the other features
#F Plot the partial dependence values as a solid line
#G Plot the 95% confidence interval around the partial dependence values as a dashed line
#H Add labels for the x and y axes
A través de las Figuras 8 y 9, podemos obtener una comprensión mucho más profunda del efecto marginal de cada uno de los valores de las características en el objetivo. Los gráficos de dependencia parcial son útiles para depurar cualquier problema con el modelo. Al trazar el intervalo de confianza del 95 % alrededor de los valores de dependencia parcial, también podemos ver puntos de datos con un tamaño de muestra bajo. Si los valores de características con un tamaño de muestra bajo tienen un efecto dramático en el objetivo, entonces podría haber un problema de sobreajuste. También podemos visualizar la 'movimiento' de la función de suavizado para determinar si el modelo se ha ajustado al ruido de los datos. Podemos solucionar estos problemas de sobreajuste aumentando el valor del parámetro de regularización. Estas parcelas de dependencia parcial también se pueden compartir con las pymes, en este caso médicos, para su validación, lo que ayudará a ganar su confianza.
Limitaciones de los GAM
Hasta ahora hemos visto las ventajas de los GAM en términos de poder predictivo e interpretabilidad. Los GAM tienen tendencia a sobreajustarse, aunque esto se puede superar con la regularización. Sin embargo, existen otras limitaciones que debe tener en cuenta:
Los GAM son sensibles a valores de características fuera del rango en el conjunto de entrenamiento y tienden a perder su poder predictivo cuando se exponen a valores atípicos.
Para tareas de misión crítica, los GAM a veces pueden tener un poder predictivo limitado, en cuyo caso es posible que deba considerar modelos de caja negra más potentes.
Eso es todo por este artículo.
Si desea obtener más información sobre el libro, puede consultar su contenido en la plataforma liveBook basada en navegador. esta página.
¿Disfrutas este artículo? Regístrese para obtener más actualizaciones de investigación de IA.
Le informaremos cuando publiquemos más artículos de resumen como este.
para modelar la variable objetivo
. El polinomio de grado 1 es lo mismo que la regresión lineal. Para el polinomio de grado 2, agregaríamos una característica adicional que es el cuadrado de
es la función que modela la relación entre la característica
y la variable objetivo. Esta función se representa como una suma ponderada de funciones base donde el peso se representa como
y la función base se representa como
. En el contexto de los GAM, la función

derivadas continuas. Será mucho más fácil entender las splines usando una ilustración. La Figura 3 muestra splines de varios grados. El gráfico superior izquierdo muestra la spline más simple de grado 0, a partir de la cual se pueden generar splines de mayor grado. Como puede ver en el gráfico superior izquierdo, se han colocado seis splines en una cuadrícula. La idea es dividir la distribución de los datos en porciones y ajustar una spline en cada una de esas porciones. Entonces, en esta ilustración, los datos se han dividido en seis partes y estamos modelando cada parte como una spline de grado 0.
. La idea detrás de las splines de regresión es aprender los pesos de cada una de las splines para poder modelar la distribución de los datos en cada una de las porciones. El número de porciones o splines en la cuadrícula,
puntos de división, también conocidos como nudos.
, podemos ajustar la intensidad de la ondulación. Un valor alto para