Los modelos de lenguaje grande (LLM) se pueden usar para analizar documentos complejos y proporcionar resúmenes y respuestas a preguntas. El cargo Adaptación de dominio Ajuste fino de modelos básicos en Amazon SageMaker JumpStart en datos financieros describe cómo ajustar un LLM utilizando su propio conjunto de datos. Una vez que tenga un LLM sólido, querrá exponer ese LLM a los usuarios comerciales para procesar nuevos documentos, que podrían tener cientos de páginas. En esta publicación, demostramos cómo construir una interfaz de usuario en tiempo real para permitir que los usuarios comerciales procesen un documento PDF de longitud arbitraria. Una vez que se procesa el archivo, puede resumir el documento o hacer preguntas sobre el contenido. La solución de muestra descrita en esta publicación está disponible en GitHub.
Trabajar con documentos financieros
Los estados financieros, como los informes de ganancias trimestrales y los informes anuales para los accionistas, suelen tener decenas o cientos de páginas. Estos documentos contienen mucho lenguaje repetitivo, como descargos de responsabilidad y lenguaje legal. Si desea extraer los puntos de datos clave de uno de estos documentos, necesita tiempo y cierta familiaridad con el lenguaje repetitivo para que pueda identificar los hechos interesantes. Y, por supuesto, no puede hacer preguntas a un LLM sobre un documento que nunca ha visto.
Los LLM que se utilizan para resumir tienen un límite en la cantidad de tokens (caracteres) que se pasan al modelo y, con algunas excepciones, normalmente no superan unos pocos miles de tokens. Eso normalmente impide la capacidad de resumir documentos más largos.
Nuestra solución maneja documentos que exceden la longitud máxima de secuencia de tokens de un LLM y pone ese documento a disposición del LLM para responder preguntas.
Resumen de la solución
Nuestro diseño tiene tres piezas importantes:
- Tiene una aplicación web interactiva para que los usuarios comerciales carguen y procesen archivos PDF.
- Utiliza la biblioteca langchain para dividir un PDF grande en partes más manejables
- Utiliza la técnica de recuperación de generación aumentada para permitir a los usuarios hacer preguntas sobre nuevos datos que el LLM no ha visto antes.
Como se muestra en el siguiente diagrama, usamos un front-end implementado con React JavaScript alojado en un Servicio de almacenamiento simple de Amazon (Amazon S3) cubeta liderada por Amazon CloudFront. La aplicación frontal permite a los usuarios cargar documentos PDF en Amazon S3. Una vez completada la carga, puede activar un trabajo de extracción de texto impulsado por Amazon Textil. Como parte del posprocesamiento, un AWS Lambda La función inserta marcadores especiales en el texto que indican los límites de la página. Cuando termine ese trabajo, puede invocar una API que resuma el texto o responda preguntas al respecto.

Debido a que algunos de estos pasos pueden llevar algún tiempo, la arquitectura utiliza un enfoque asíncrono desacoplado. Por ejemplo, la llamada para resumir un documento invoca una función Lambda que publica un mensaje en un Servicio de cola simple de Amazon (Amazon SQS) cola. Otra función de Lambda recoge ese mensaje e inicia un Servicio de contenedor elástico de Amazon (Amazon ECS) AWS Fargate tarea. La tarea de Fargate llama al Amazon SageMaker punto final de inferencia. Usamos una tarea de Fargate aquí porque resumir un PDF muy largo puede llevar más tiempo y memoria de lo que tiene disponible una función de Lambda. Cuando se realiza el resumen, la aplicación front-end puede recoger los resultados de un Amazon DynamoDB mesa.
Para resumir, usamos el modelo Summarize de AI21, uno de los modelos básicos disponibles a través de JumpStart de Amazon SageMaker. Aunque este modelo maneja documentos de hasta 10,000 40 palabras (aproximadamente 10,000 páginas), usamos el divisor de texto de langchain para asegurarnos de que cada llamada de resumen al LLM no tenga más de XNUMX XNUMX palabras. Para la generación de texto, usamos el modelo Medium de Cohere y usamos GPT-J para incrustaciones, ambos a través de JumpStart.
Procesamiento de resumen
Al manejar documentos más grandes, necesitamos definir cómo dividir el documento en partes más pequeñas. Cuando recibimos los resultados de extracción de texto de Amazon Textract, insertamos marcadores para fragmentos de texto más grandes (un número configurable de páginas), páginas individuales y saltos de línea. Langchain se dividirá en función de esos marcadores y ensamblará documentos más pequeños que estén por debajo del límite de tokens. Ver el siguiente código:
El LLM en la cadena de resumen es un envoltorio delgado alrededor de nuestro punto final de SageMaker:
Respuesta a la pregunta
En el método de generación aumentada de recuperación, primero dividimos el documento en segmentos más pequeños. Creamos incrustaciones para cada segmento y las almacenamos en la base de datos vectorial Chroma de código abierto a través de la interfaz de langchain. Guardamos la base de datos en un Sistema de archivos elástico de Amazon (Amazon EFS) sistema de archivos para su uso posterior. Ver el siguiente código:
Cuando las incorporaciones están listas, el usuario puede hacer una pregunta. Buscamos en la base de datos de vectores los fragmentos de texto que más se acerquen a la pregunta:
Tomamos el fragmento coincidente más cercano y lo usamos como contexto para el modelo de generación de texto para responder la pregunta:
La experiencia del usuario
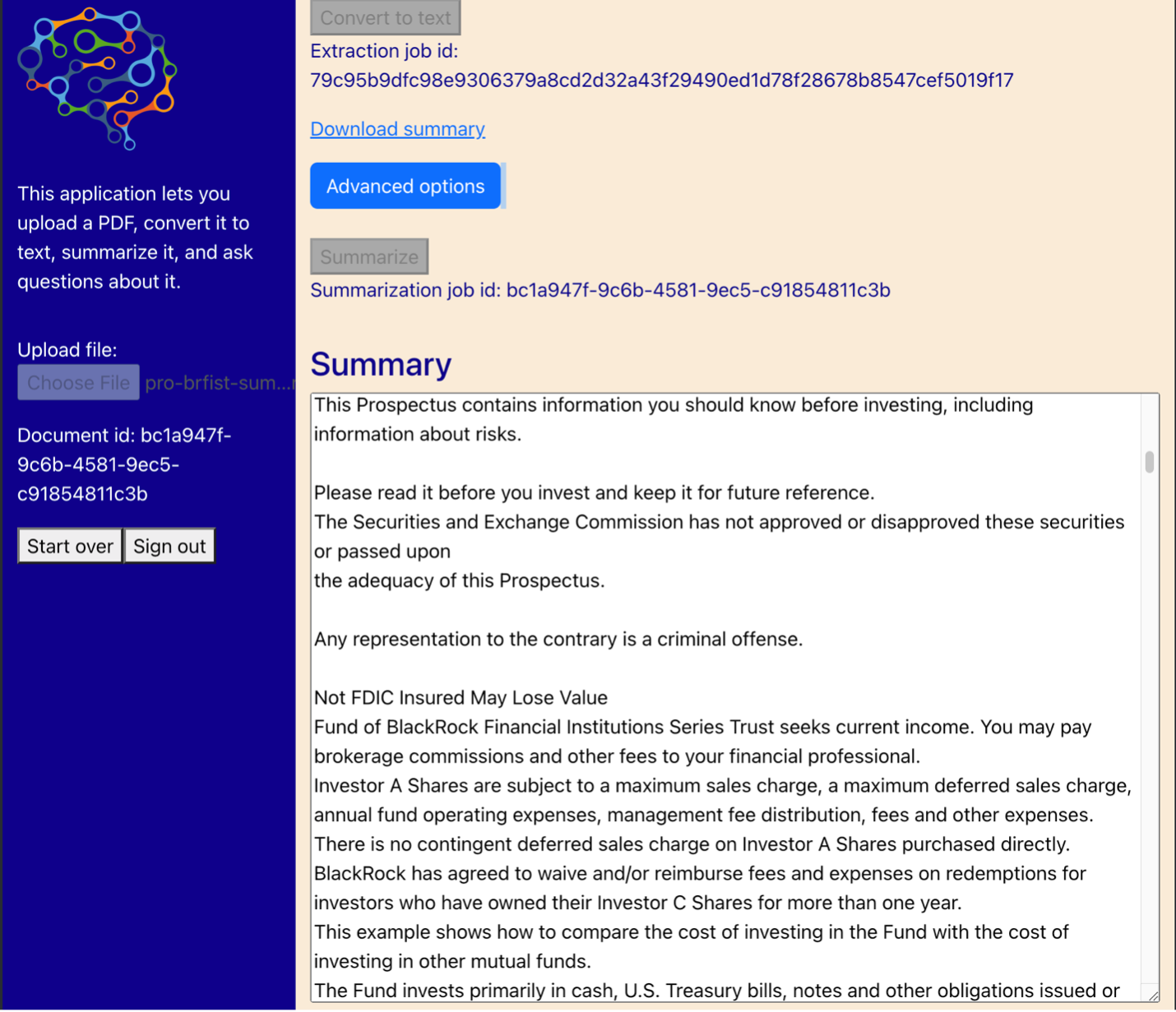
Aunque los LLM representan ciencia de datos avanzada, la mayoría de los casos de uso de LLM implican, en última instancia, la interacción con usuarios no técnicos. Nuestra aplicación web de ejemplo maneja un caso de uso interactivo donde los usuarios comerciales pueden cargar y procesar un nuevo documento PDF.
El siguiente diagrama muestra la interfaz de usuario. Un usuario comienza cargando un PDF. Una vez que el documento se almacena en Amazon S3, el usuario puede iniciar el trabajo de extracción de texto. Cuando se completa, el usuario puede invocar la tarea de resumen o hacer preguntas. La interfaz de usuario expone algunas opciones avanzadas, como el tamaño de fragmento y la superposición de fragmentos, que serían útiles para los usuarios avanzados que están probando la aplicación en documentos nuevos.
Próximos pasos
Los LLM brindan importantes capacidades de recuperación de información nueva. Los usuarios comerciales necesitan un acceso conveniente a esas capacidades. Hay dos direcciones para el trabajo futuro a considerar:
- Aproveche los poderosos LLM ya disponibles en los modelos básicos de Jumpstart. Con solo unas pocas líneas de código, nuestra aplicación de muestra podría implementar y utilizar LLM avanzados de AI21 y Cohere para generar y resumir texto.
- Haga que estas capacidades sean accesibles para usuarios no técnicos. Un requisito previo para procesar documentos PDF es extraer texto del documento, y los trabajos de resumen pueden tardar varios minutos en ejecutarse. Eso requiere una interfaz de usuario simple con capacidades de procesamiento de back-end asincrónicas, que es fácil de diseñar utilizando servicios nativos de la nube como Lambda y Fargate.
También notamos que un documento PDF es información semiestructurada. Las señales importantes, como los encabezados de las secciones, son difíciles de identificar mediante programación, ya que dependen del tamaño de las fuentes y otros indicadores visuales. Identificar la estructura subyacente de la información ayuda al LLM a procesar los datos con mayor precisión, al menos hasta que los LLM puedan manejar entradas de longitud ilimitada.
Conclusión
En esta publicación, mostramos cómo crear una aplicación web interactiva que permite a los usuarios comerciales cargar y procesar documentos PDF para resumir y responder preguntas. Vimos cómo aprovechar los modelos básicos de Jumpstart para acceder a LLM avanzados y utilizar técnicas de generación aumentada de división y recuperación de texto para procesar documentos más largos y ponerlos a disposición del LLM como información.
En este momento, no hay razón para no poner estas poderosas capacidades a disposición de sus usuarios. Le animamos a que empiece a utilizar el Modelos de base Jumpstart .
Acerca del autor.
 Randy DeFauw es un Arquitecto Principal Principal de Soluciones en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión artificial para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el espacio tecnológico, desde ingeniería de software hasta gestión de productos. En ingresó al espacio Big Data en 2013 y continúa explorando esa área. Está trabajando activamente en proyectos en el espacio ML y se ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
Randy DeFauw es un Arquitecto Principal Principal de Soluciones en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión artificial para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el espacio tecnológico, desde ingeniería de software hasta gestión de productos. En ingresó al espacio Big Data en 2013 y continúa explorando esa área. Está trabajando activamente en proyectos en el espacio ML y se ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/use-a-generative-ai-foundation-model-for-summarization-and-question-answering-using-your-own-data/

