Nos complace anunciar una nueva versión del Operadores de Amazon SageMaker para Kubernetes usando el Controladores de AWS para Kubernetes (ACK). ACK es un marco para crear controladores personalizados de Kubernetes, donde cada controlador se comunica con una API de servicio de AWS. Estos controladores permiten a los usuarios de Kubernetes aprovisionar recursos de AWS como depósitos, bases de datos o colas de mensajes simplemente utilizando la API de Kubernetes.
tortugitas v1.2.9 de los operadores ACK de SageMaker agrega soporte para componentes de inferencia, que hasta ahora solo estaban disponibles a través de la API de SageMaker y los kits de desarrollo de software (SDK) de AWS. Los componentes de inferencia pueden ayudarle a optimizar los costos de implementación y reducir la latencia. Con las nuevas capacidades del componente de inferencia, puede implementar uno o más modelos básicos (FM) en el mismo Amazon SageMaker endpoint y controlar cuántos aceleradores y cuánta memoria se reserva para cada FM. Esto ayuda a mejorar la utilización de recursos, reduce los costos de implementación del modelo en promedio en un 50 % y le permite escalar puntos finales junto con sus casos de uso. Para más detalles, ver Amazon SageMaker agrega nuevas capacidades de inferencia para ayudar a reducir la latencia y los costos de implementación del modelo básico.
La disponibilidad de componentes de inferencia a través del controlador SageMaker permite a los clientes que utilizan Kubernetes como plano de control aprovechar los componentes de inferencia mientras implementan sus modelos en SageMaker.
En esta publicación, mostramos cómo utilizar los operadores ACK de SageMaker para implementar componentes de inferencia de SageMaker.
¿Cómo funciona ACK?
Demostrar cómo funciona ACK, veamos un ejemplo usando Servicio de almacenamiento simple de Amazon (Amazon S3). En el siguiente diagrama, Alice es nuestra usuaria de Kubernetes. Su aplicación depende de la existencia de un depósito S3 llamado my-bucket.
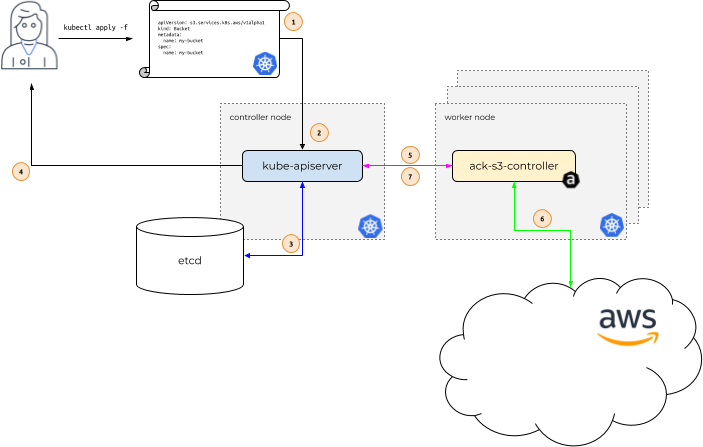
El flujo de trabajo consta de los siguientes pasos:
- Alice emite una llamada a
kubectl apply, pasando un archivo que describe un Kubernetes recurso personalizado describiendo su cubo S3.kubectl applypasa este archivo, llamado manifiesto, al servidor API de Kubernetes que se ejecuta en el nodo del controlador de Kubernetes. - El servidor API de Kubernetes recibe el manifiesto que describe el depósito S3 y determina si Alice tiene permisos para crear un recurso personalizado de tipo
s3.services.k8s.aws/Buckety que el recurso personalizado tenga el formato adecuado. - Si Alice está autorizada y el recurso personalizado es válido, el servidor API de Kubernetes escribe el recurso personalizado en su
etcdAlmacén de datos. - Luego le responde a Alice que se ha creado el recurso personalizado.
- En este punto, el servicio ACK controlador para Amazon S3, que se ejecuta en un nodo trabajador de Kubernetes dentro del contexto de un Kubernetes normal Vaina, se le notifica que un nuevo recurso personalizado de tipo
s3.services.k8s.aws/Bucketse ha creado. - El controlador de servicio ACK para Amazon S3 luego se comunica con la API de Amazon S3 y llama al API CreateBucket de S3 para crear el depósito en AWS.
- Después de comunicarse con la API de Amazon S3, el controlador del servicio ACK llama al servidor API de Kubernetes para actualizar el recurso personalizado. estado con información que recibió de Amazon S3.
Componentes claves
Las nuevas capacidades de inferencia se basan en los puntos finales de inferencia en tiempo real de SageMaker. Como antes, crea el punto final de SageMaker con una configuración de punto final que define el tipo de instancia y el recuento de instancias inicial para el punto final. El modelo está configurado en una nueva construcción, un componente de inferencia. Aquí, usted especifica la cantidad de aceleradores y la cantidad de memoria que desea asignar a cada copia de un modelo, junto con los artefactos del modelo, la imagen del contenedor y la cantidad de copias del modelo que se implementarán.
Puede utilizar las nuevas capacidades de inferencia de Estudio Amazon SageMaker, la SDK de SageMaker Python, SDK de AWSy Interfaz de línea de comandos de AWS (AWS CLI). También cuentan con el apoyo de Formación en la nube de AWS. Ahora también puedes usarlos con Operadores de SageMaker para Kubernetes.
Resumen de la solución
Para esta demostración, utilizamos el controlador SageMaker para implementar una copia del Modelo Dolly v2 7B y una copia del Modelo FLAN-T5 XXL del desplegable Hub modelo de cara abrazada en un punto final en tiempo real de SageMaker utilizando las nuevas capacidades de inferencia.
Requisitos previos
Para seguir adelante, debe tener un clúster de Kubernetes con el controlador SageMaker ACK v1.2.9 o superior instalado. Para obtener instrucciones sobre cómo aprovisionar un Servicio Amazon Elastic Kubernetes (Amazon EKS) con Nube informática elástica de Amazon (Amazon EC2) Nodos administrados por Linux mediante eksctl, consulte Introducción a Amazon EKS – eksctl. Para obtener instrucciones sobre cómo instalar el controlador SageMaker, consulte Aprendizaje automático con el controlador ACK SageMaker.
Necesita acceso a instancias aceleradas (GPU) para alojar los LLM. Esta solución utiliza una instancia de ml.g5.12xlarge; puede verificar la disponibilidad de estas instancias en su cuenta de AWS y solicitarlas según sea necesario mediante una solicitud de aumento de cuotas de servicio, como se muestra en la siguiente captura de pantalla.

Crear un componente de inferencia
Para crear su componente de inferencia, defina el EndpointConfig, Endpoint, Modely InferenceComponent Archivos YAML, similares a los que se muestran en esta sección. Usar kubectl apply -f <yaml file> para crear los recursos de Kubernetes.
Puede enumerar el estado del recurso a través de kubectl describe <resource-type>; por ejemplo, kubectl describe inferencecomponent.
También puede crear el componente de inferencia sin un recurso de modelo. Consulte la guía proporcionada en el Documentación de la API para más información.
EndpointConfig YAML
El siguiente es el código para el archivo EndpointConfig:
Punto final YAML
El siguiente es el código para el archivo Endpoint:
Modelo YAML
El siguiente es el código para el archivo de modelo:
YAML de componentes de inferencia
En los siguientes archivos YAML, dado que la instancia ml.g5.12xlarge viene con 4 GPU, asignamos 2 GPU, 2 CPU y 1,024 MB de memoria a cada modelo:
Invocar modelos
Ahora puedes invocar los modelos usando el siguiente código:
Actualizar un componente de inferencia
Para actualizar un componente de inferencia existente, puede actualizar los archivos YAML y luego usar kubectl apply -f <yaml file>. El siguiente es un ejemplo de un archivo actualizado:
Eliminar un componente de inferencia
Para eliminar un componente de inferencia existente, use el comando kubectl delete -f <yaml file>.
Disponibilidad y precios
Las nuevas capacidades de inferencia de SageMaker están disponibles hoy en las regiones de AWS EE. UU. Este (Ohio, Norte de Virginia), EE. UU. Oeste (Oregón), Asia Pacífico (Yakarta, Mumbai, Seúl, Singapur, Sydney, Tokio), Canadá (Central), Europa ( Frankfurt, Irlanda, Londres, Estocolmo), Medio Oriente (EAU) y América del Sur (São Paulo). Para obtener detalles sobre precios, visite Precios de Amazon SageMaker.
Conclusión
En esta publicación, mostramos cómo usar los operadores ACK de SageMaker para implementar componentes de inferencia de SageMaker. ¡Encienda su clúster de Kubernetes e implemente sus FM utilizando las nuevas capacidades de inferencia de SageMaker hoy!
Acerca de los autores
 Rajesh Ramchander es ingeniero principal de ML en servicios profesionales en AWS. Ayuda a los clientes en varias etapas de su viaje hacia AI/ML y GenAI, desde aquellos que recién están comenzando hasta aquellos que están liderando su negocio con una estrategia que prioriza la IA.
Rajesh Ramchander es ingeniero principal de ML en servicios profesionales en AWS. Ayuda a los clientes en varias etapas de su viaje hacia AI/ML y GenAI, desde aquellos que recién están comenzando hasta aquellos que están liderando su negocio con una estrategia que prioriza la IA.
 Amit Arora es un arquitecto especialista en inteligencia artificial y aprendizaje automático en Amazon Web Services, que ayuda a los clientes empresariales a utilizar servicios de aprendizaje automático basados en la nube para escalar rápidamente sus innovaciones. También es profesor adjunto en el programa de análisis y ciencia de datos de MS en la Universidad de Georgetown en Washington DC.
Amit Arora es un arquitecto especialista en inteligencia artificial y aprendizaje automático en Amazon Web Services, que ayuda a los clientes empresariales a utilizar servicios de aprendizaje automático basados en la nube para escalar rápidamente sus innovaciones. También es profesor adjunto en el programa de análisis y ciencia de datos de MS en la Universidad de Georgetown en Washington DC.
 Suryansh Singh es ingeniero de desarrollo de software en AWS SageMaker y trabaja en el desarrollo de soluciones de infraestructura distribuida de aprendizaje automático para clientes de AWS a escala.
Suryansh Singh es ingeniero de desarrollo de software en AWS SageMaker y trabaja en el desarrollo de soluciones de infraestructura distribuida de aprendizaje automático para clientes de AWS a escala.
 Saurabh Trikande es gerente sénior de productos para Amazon SageMaker Inference. Le apasiona trabajar con clientes y está motivado por el objetivo de democratizar el aprendizaje automático. Se enfoca en los desafíos principales relacionados con la implementación de aplicaciones de ML complejas, modelos de ML de múltiples inquilinos, optimizaciones de costos y hacer que la implementación de modelos de aprendizaje profundo sea más accesible. En su tiempo libre, a Saurabh le gusta caminar, aprender sobre tecnologías innovadoras, seguir TechCrunch y pasar tiempo con su familia.
Saurabh Trikande es gerente sénior de productos para Amazon SageMaker Inference. Le apasiona trabajar con clientes y está motivado por el objetivo de democratizar el aprendizaje automático. Se enfoca en los desafíos principales relacionados con la implementación de aplicaciones de ML complejas, modelos de ML de múltiples inquilinos, optimizaciones de costos y hacer que la implementación de modelos de aprendizaje profundo sea más accesible. En su tiempo libre, a Saurabh le gusta caminar, aprender sobre tecnologías innovadoras, seguir TechCrunch y pasar tiempo con su familia.
 Juana Liu es ingeniero de desarrollo de software en el equipo de Amazon SageMaker. Su trabajo actual se centra en ayudar a los desarrolladores a alojar de manera eficiente modelos de aprendizaje automático y mejorar el rendimiento de la inferencia. Le apasiona el análisis de datos espaciales y el uso de IA para resolver problemas sociales.
Juana Liu es ingeniero de desarrollo de software en el equipo de Amazon SageMaker. Su trabajo actual se centra en ayudar a los desarrolladores a alojar de manera eficiente modelos de aprendizaje automático y mejorar el rendimiento de la inferencia. Le apasiona el análisis de datos espaciales y el uso de IA para resolver problemas sociales.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/use-kubernetes-operators-for-new-inference-capabilities-in-amazon-sagemaker-that-reduce-llm-deployment-costs-by-50-on-average/

