Pegamento AWS es un servicio de integración de datos sin servidor que puede utilizar para catalogar datos y prepararse para el análisis. Con AWS Glue, puede descubrir sus datos, desarrollar scripts para transformar fuentes en destinos y programar y ejecutar trabajos de extracción, transformación y carga (ETL) en un entorno sin servidor. Los trabajos de AWS Glue son responsables de ejecutar la lógica de procesamiento de datos.
Una característica importante de los trabajos de AWS Glue es la capacidad de utilizar teclas de marcador para procesar datos de forma incremental. Cuando se ejecuta un trabajo de AWS Glue, lee datos de una fuente de datos y los procesa. Se pueden especificar una o más columnas de la tabla de origen como claves de marcador. La columna debe tener valores crecientes o decrecientes secuencialmente sin espacios. Estos valores se utilizan para marcar el último registro procesado en un lote. La siguiente ejecución del trabajo se reanuda desde ese punto. Esto le permite procesar grandes cantidades de datos de forma incremental. Sin claves de marcadores de trabajos, los trabajos de AWS Glue tendrían que reprocesar todos los datos durante cada ejecución. Esto puede llevar mucho tiempo y ser costoso. Al utilizar claves de marcadores, los trabajos de AWS Glue pueden reanudar el procesamiento desde donde lo dejaron, ahorrando tiempo y reduciendo costos.
Esta publicación explica cómo utilizar varias columnas como claves de marcadores de trabajo en un trabajo de AWS Glue con una conexión JDBC al almacén de datos de origen. También demuestra cómo parametrizar las columnas de claves de marcadores y los nombres de las tablas en las opciones de conexión del trabajo de AWS Glue.
Esta publicación está dirigida a arquitectos e ingenieros de datos que diseñan y construyen canalizaciones ETL en AWS. Se espera que usted tenga un conocimiento básico de la Consola de administración de AWS, pegamento AWS, Servicio de base de datos relacional de Amazon (Amazon RDS)y Reloj en la nube de Amazon registros
Resumen de la solución
Para implementar esta solución, completamos los siguientes pasos:
- Crear una Amazon RDS para PostgreSQL ejemplo.
- Cree dos tablas e inserte datos de muestra.
- Cree y ejecute un trabajo de AWS Glue para extraer datos de la instancia de base de datos de RDS para PostgreSQL utilizando varias claves de marcadores de trabajo.
- Cree y ejecute un trabajo de AWS Glue parametrizado para extraer datos de diferentes tablas con claves de marcadores independientes
El siguiente diagrama ilustra los componentes de esta solución.

Implementar la solución
Para esta solución, proporcionamos un Formación en la nube de AWS Plantilla que configura los servicios incluidos en la arquitectura, para permitir implementaciones repetibles. Esta plantilla crea los siguientes recursos:
- Una instancia de RDS para PostgreSQL
- An Servicio de almacenamiento simple de Amazon (Amazon S3) depósito para almacenar los datos extraídos de la instancia de RDS para PostgreSQL
- An Gestión de identidades y accesos de AWS (IAM) función para AWS Glue
- Dos trabajos de AWS Glue con marcadores de trabajo habilitados para extraer datos de forma incremental de la instancia de RDS para PostgreSQL
Para implementar la solución, complete los siguientes pasos:
- Elige
 para iniciar la pila de CloudFormation:
para iniciar la pila de CloudFormation: - Ingrese un nombre de pila.
- Seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM con nombres personalizados.
- Elige Crear pila.
- Espere hasta que se complete la creación de la pila, como se muestra en la consola de AWS CloudFormation.

- Cuando la pila esté completa, copie los scripts de AWS Glue en el depósito S3
job-bookmark-keys-demo-<accountid>. - Abierto AWS CloudShell.
- Ejecute los siguientes comandos y reemplace
<accountid>con su ID de cuenta de AWS:
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-2907/glue/scenario_1_job.py s3://job-bookmark-keys-demo-<accountid>/scenario_1_job.py
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-2907/glue/scenario_2_job.py s3://job-bookmark-keys-demo-<accountid>/scenario_2_job.py
Agregue datos de muestra y ejecute trabajos de AWS Glue
En esta sección, nos conectamos a la instancia de RDS para PostgreSQL a través de AWS Lambda y crear dos tablas. También insertamos datos de muestra en ambas tablas.
- En la consola Lambda, elija Clave en el panel de navegación.
- Elige la función
LambdaRDSDDLExecute.
- Elige Probar y elige invocar para que la función Lambda inserte los datos.

Las dos tablas producto y dirección se crearán con datos de muestra, como se muestra en la siguiente captura de pantalla.

Ejecute el trabajo de AWS Glue multiple_job_bookmark_keys
ejecutamos el multiple_job_bookmark_keys Trabajo de AWS Glue dos veces para extraer datos de la tabla de productos de la instancia de RDS para PostgreSQL. En la primera ejecución, se extraerán todos los registros existentes. Luego insertamos nuevos registros y ejecutamos el trabajo nuevamente. El trabajo debería extraer solo los registros recién insertados en la segunda ejecución.
- En la consola de AWS Glue, elija Empleo en el panel de navegación.
- elige el trabajo
multiple_job_bookmark_keys. - Elige Ejecutar para ejecutar el trabajo y elegir el Ron pestaña para monitorear el progreso del trabajo.
- Elija el Registros de salida hipervínculo debajo Registros de CloudWatch una vez finalizado el trabajo.

- Elija el flujo de registro en la siguiente ventana para ver los registros de salida impresos.

El trabajo de AWS Glue extrajo todos los registros del producto de la tabla de origen. Realiza un seguimiento de la última combinación de valores en las columnas.product_idyversionA continuación, ejecutamos otra función Lambda para insertar un nuevo registro. Elproduct_id45 ya existe, pero el registro insertado tendrá una nueva versión como 2, haciendo que la combinación aumente secuencialmente. - Ejecute el
LambdaRDSDDLExecute_incrementalFunción lambda para insertar el nuevo registro en elproductmesa.
- Ejecute el trabajo de AWS Glue
multiple_job_bookmark_keysnuevamente después de insertar el registro y esperar a que se realice correctamente. - Elija el hipervínculo Registros de salida en Registros de CloudWatch.
- Elija la secuencia de registro en la siguiente ventana para ver impreso solo el registro recién insertado.
El trabajo extrae sólo aquellos registros que tienen una combinación mayor que los registros extraídos anteriormente.

Ejecute el trabajo de AWS Glue parametriised_job_bookmark_keys
Ahora ejecutamos el trabajo parametrizado de AWS Glue que toma el nombre de la tabla y la columna de clave de marcador como parámetros. Ejecutamos este trabajo para extraer datos de diferentes tablas manteniendo marcadores separados.
La primera ejecución será para la tabla de direcciones con bookmarkkey as address_id. Estos ya están llenos de los parámetros del trabajo.
- En la consola de AWS Glue, elija Empleo en el panel de navegación.
- elige el trabajo
parameterised_job_bookmark_keys. - Elige Ejecutar para ejecutar el trabajo y elegir el Ron pestaña para monitorear el progreso del trabajo.
- Elija el Registros de salida hipervínculo debajo Registros de CloudWatch una vez finalizado el trabajo.

- Elija el flujo de registro en la siguiente ventana para ver todos los registros de la tabla de direcciones impresos.

- En Menú de acciones, escoger Ejecutar con parámetros.
- Ampliar la opción Parámetros de trabajo .
- Cambie los valores de los parámetros del trabajo de la siguiente manera:
- Clave
--bookmarkkeycon valorproduct_id - Clave
--table_namecon valorproduct - El nombre del depósito S3 no cambia (
job-bookmark-keys-demo-<accountnumber>)
- Clave
- Elige Ejecutar trabajo para ejecutar el trabajo y elegir el Ron pestaña para monitorear el progreso del trabajo.
- Elija el Registros de salida hipervínculo debajo Registros de CloudWatch una vez finalizado el trabajo.
- Elija el flujo de registro para ver todos los registros de la tabla de productos impresos.
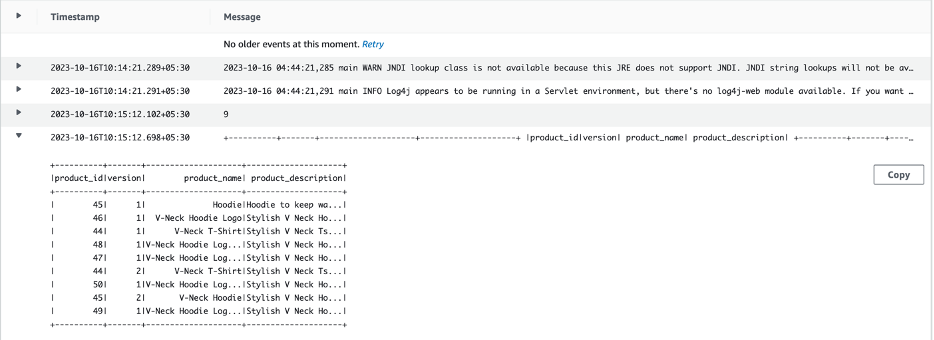
El trabajo mantiene marcadores separados para cada una de las tablas al extraer los datos del almacén de datos de origen. Esto se logra agregando el nombre de la tabla al nombre del trabajo y a los contextos de transformación en el script del trabajo de AWS Glue.
Limpiar
Para evitar incurrir en cargos futuros, complete los siguientes pasos:
- En la consola de Amazon S3, elija cubos en el panel de navegación.
- Seleccione el depósito con claves de marcador de trabajo en su nombre.
- Elige Vacío para eliminar todos los archivos y carpetas que contiene.
- En la consola de CloudFormation, elija Stacks en el panel de navegación.
- Seleccione la pila que creó para implementar la solución y elija Borrar.
Conclusión
Esta publicación demostró pasar más de una columna de una tabla como jobBookmarkKeys en una conexión JDBC a un trabajo de AWS Glue. También explicó cómo se puede realizar un trabajo de AWS Glue parametrizado para extraer datos de varias tablas manteniendo sus respectivos marcadores. Como siguiente paso, puede probar la extracción de datos incrementales cambiando los datos en las tablas de origen.
Acerca de los autores
 Durga Prasad es un consultor líder sénior que permite a los clientes crear sus soluciones de análisis de datos en AWS. Es un amante del café y le gusta jugar al bádminton.
Durga Prasad es un consultor líder sénior que permite a los clientes crear sus soluciones de análisis de datos en AWS. Es un amante del café y le gusta jugar al bádminton.
 Murali Reddy es consultor principal en Amazon Web Services (AWS) y ayuda a los clientes a crear e implementar soluciones de análisis de datos. Cuando no está trabajando, Murali es un ávido ciclista y le encanta explorar nuevos lugares.
Murali Reddy es consultor principal en Amazon Web Services (AWS) y ayuda a los clientes a crear e implementar soluciones de análisis de datos. Cuando no está trabajando, Murali es un ávido ciclista y le encanta explorar nuevos lugares.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/use-multiple-bookmark-keys-in-aws-glue-jdbc-jobs/

