La reciente llegada de los grandes modelos de lenguaje ha tomado al mundo por sorpresa. Ahora, la imaginación es el límite. Hoy, WavJourney puede automatizar el arte de contar historias. Con una sola indicación, WavJourney aprovecha el poder de los LLM para generar guiones de audio apasionantes, completos con una historia precisa, voces humanas realistas y música de fondo atractiva.
Para ver correctamente los poderes de generación de audio, considere el siguiente escenario. Solo necesitamos proporcionar una instrucción simple, que describa un escenario y una escena, y el modelo genera un guión de audio apasionante que resalta la relevancia suprema del contexto para la instrucción original.
INSTRUCCIÓN: Generar audio en el tema de ciencia ficción: Mars News informa que los humanos envían una sonda de la velocidad de la luz a Alpha Centauri. Comience con un presentador de noticias, seguido de un reportero que entrevista a un ingeniero jefe de una organización que construyó esta sonda, fundada por el Gobierno Unido de la Tierra y Marte, y termine nuevamente con el presentador de noticias.
AUDIO GENERADO: https://audio-agi.github.io/WavJourney_demopage/sci-fi/sci-fi%20news.mp4
Para comprender verdaderamente el funcionamiento interno de esta maravilla, profundicemos en la metodología y los detalles de implementación del proceso de generación.
La siguiente imagen resume el proceso completo en un diagrama de flujo simple.
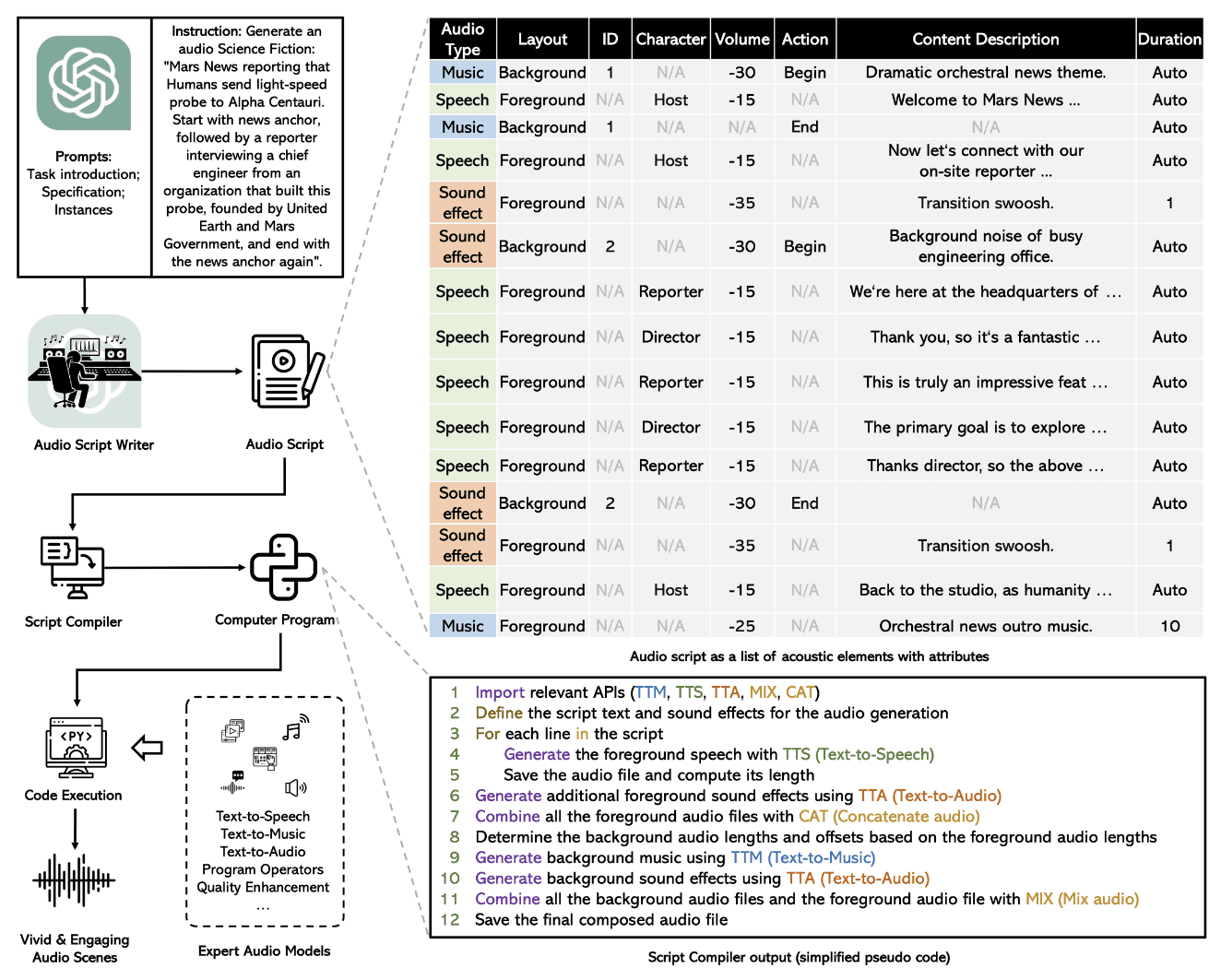
Imagen de Papel
El proceso de generación de audio de un extremo a otro se compone de múltiples submódulos, que se ejecutan secuencialmente para un modelo completo de texto a audio.
Generación de guiones de audio
WavJourney utiliza el modelo GPT-4 con una plantilla de aviso predefinida para generar el script. Las plantillas de mensajes restringen la salida a un formato JSON simple, que un programa de computadora puede analizar fácilmente más adelante. Cada guión tiene 3 tipos de audio diferentes como se muestra en la imagen de arriba: Speech, efectos sonorosy música. Luego, cada tipo de audio se puede ejecutar como audio de primer plano o superponerse como efecto de sonido de fondo sobre otro audio. Otros atributos, como la descripción del contenido, la duración y el carácter, son atributos suficientes para definir formalmente una configuración de audio para la generación de guiones.
Análisis de guiones
Luego, el script de salida pasa a través de un programa informático que analiza la información relevante del formato de script JSON predefinido. Asocia cada descripción y carácter a un audio de voz preestablecido. Este proceso ayuda a dividir el proceso de generación de audio en pasos separados, que incluyen conversión de texto a voz, música y adición de sonido.
Generación de audio
El script analizado se ejecuta como un programa Python. Primero se genera el habla en primer plano que se superpone con música de fondo y efectos de sonido. Para la generación de voz, el modelo utiliza el pre-entrenado Ladrido modelo y un Fijador de voz Modelo de restauración para mejorar la calidad del audio. AudioLDM y generación de música Los modelos se utilizan para efectos de sonido y superposiciones de música. Las salidas de los tres modelos se combinan para la salida de audio final.
El proceso mantiene el contexto de los scripts generados y puede solicitarse de manera similar a los modelos GPT. Puede modificar fácilmente el script generado utilizando comentarios humanos y capacidades de chat de los modelos GPT.
Agregar detalles específicos y efectos de sonido no podría haber sido más fácil que esto. El siguiente diagrama de flujo muestra lo sencillo que es agregar o modificar detalles específicos del script generado.
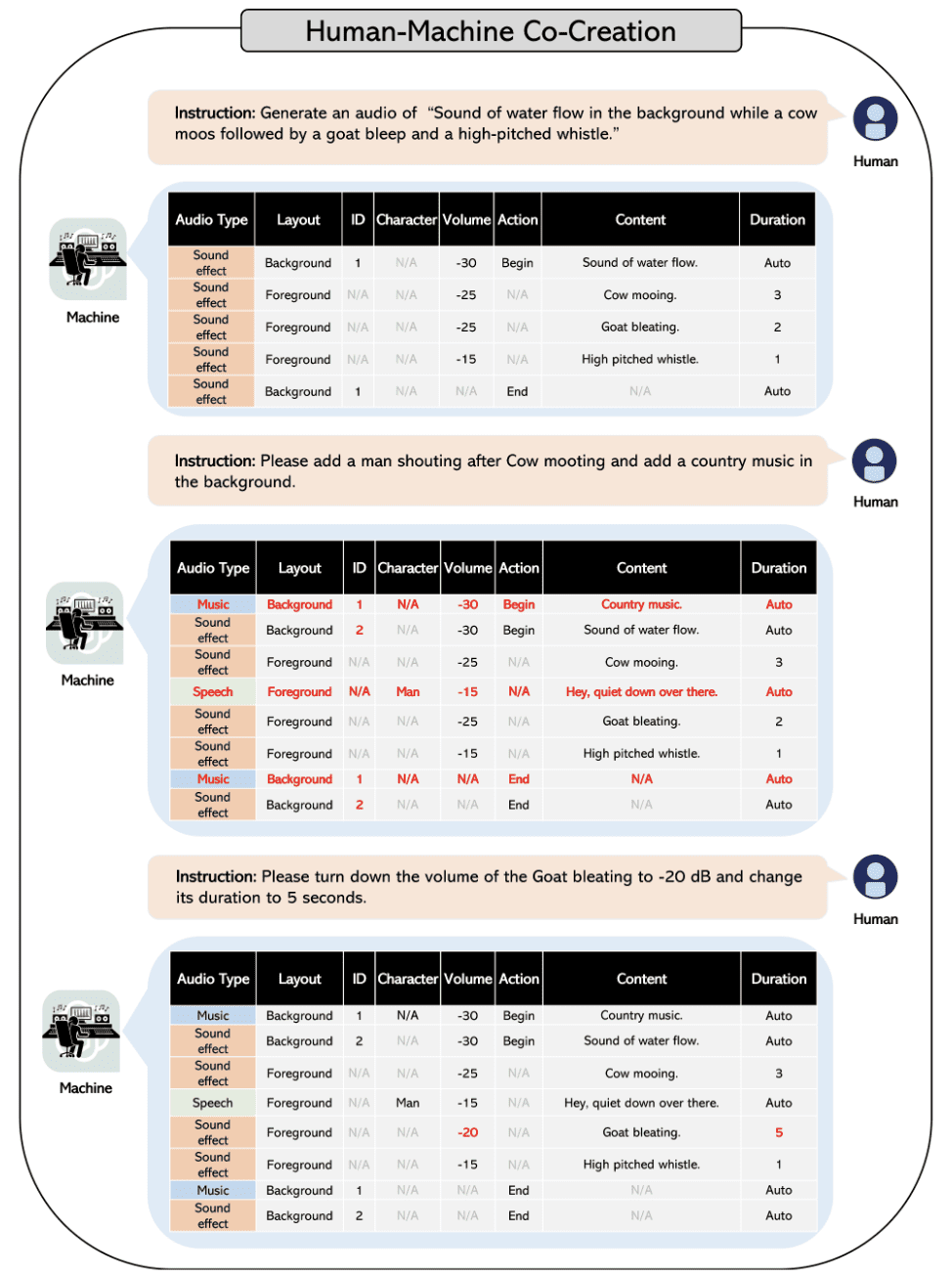
Imagen de Papel
El modelo de generación de audio puede cambiar las reglas del juego para la industria del entretenimiento. El proceso tiene la capacidad de generar narrativas e historias atractivas, que pueden utilizarse con fines educativos y de entretenimiento, automatizando tediosos procesos de generación de videos y locuciones.
Para una comprensión detallada, revise la aquí. El código pronto estará disponible en GitHub.
muhammad arham es un ingeniero de aprendizaje profundo que trabaja en visión artificial y procesamiento de lenguaje natural. Ha trabajado en la implementación y optimización de varias aplicaciones de IA generativa que alcanzaron las listas de éxitos mundiales en Vyro.AI. Está interesado en construir y optimizar modelos de aprendizaje automático para sistemas inteligentes y cree en la mejora continua.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.kdnuggets.com/wavjourney-a-journey-into-the-world-of-audio-storyline-generation?utm_source=rss&utm_medium=rss&utm_campaign=wavjourney-a-journey-into-the-world-of-audio-storyline-generation

