A medida que Roblox ha crecido en los últimos 16 años, también lo ha hecho la escala y la complejidad de la infraestructura técnica que respalda millones de coexperiencias inmersivas en 3D. La cantidad de máquinas que brindamos soporte se ha más que triplicado en los últimos dos años, de aproximadamente 36,000 30 al 2021 de junio de 145,000 a casi 1,000 XNUMX en la actualidad. Para respaldar estas experiencias siempre activas para personas de todo el mundo se requieren más de XNUMX servicios internos. Para ayudarnos a controlar los costos y la latencia de la red, implementamos y administramos estas máquinas como parte de una infraestructura de nube privada híbrida y personalizada que se ejecuta principalmente en las instalaciones.
Nuestra infraestructura actualmente admite más de 70 millones de usuarios activos diarios en todo el mundo, incluidos los creadores que confían en Roblox. economia para sus negocios. Todos estos millones de personas esperan un nivel muy alto de confiabilidad. Dada la naturaleza inmersiva de nuestras experiencias, existe una tolerancia extremadamente baja a los retrasos o la latencia, y mucho menos a las interrupciones. Roblox es una plataforma de comunicación y conexión, donde las personas se reúnen en experiencias inmersivas en 3D. Cuando las personas se comunican como sus avatares en un espacio inmersivo, incluso los retrasos o fallos menores son más notorios que en un hilo de texto o una conferencia telefónica.
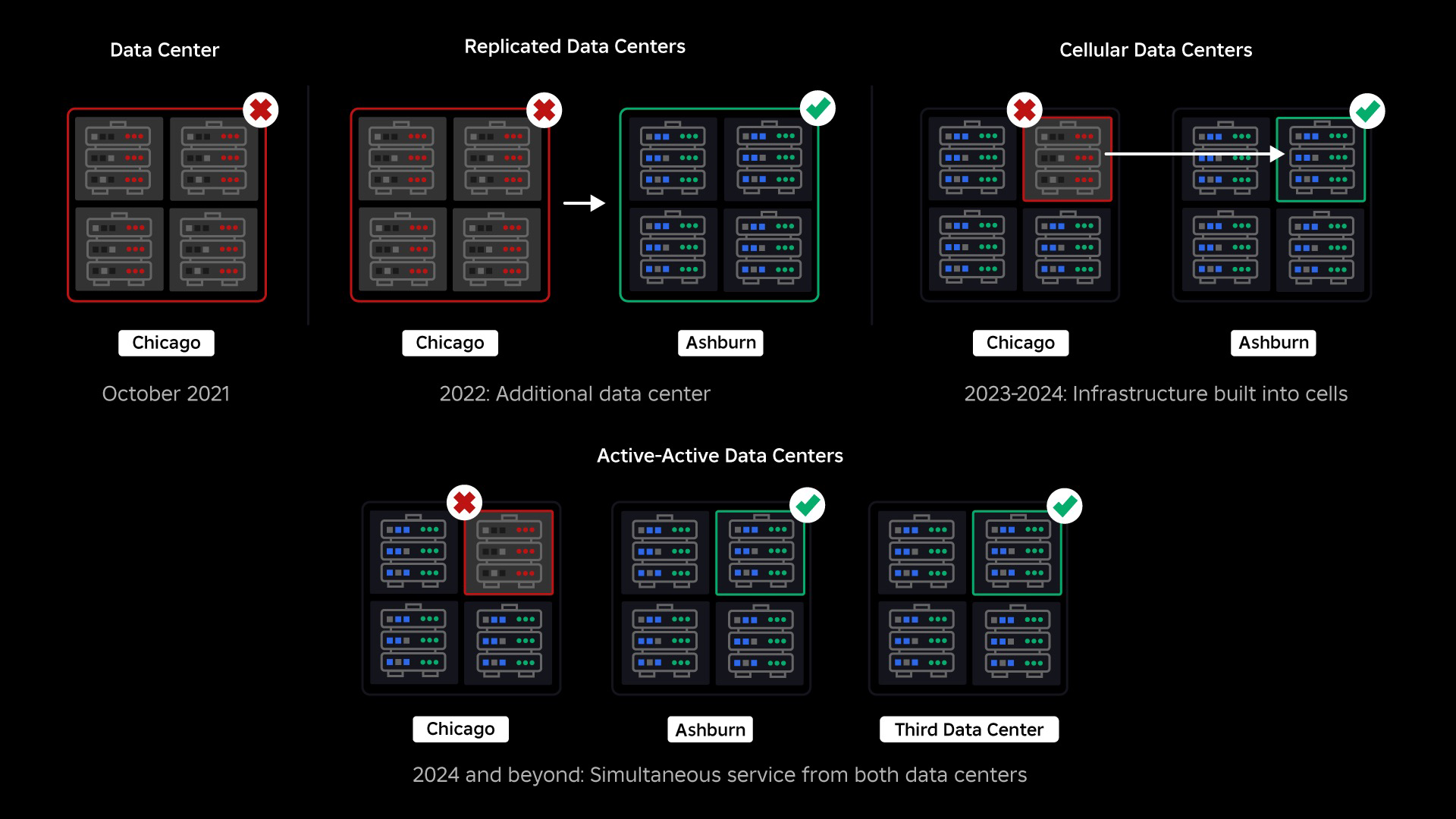
En octubre de 2021, experimentamos una interrupción en todo el sistema. Todo empezó siendo pequeño, con un problema en un componente de un centro de datos. Pero se propagó rápidamente mientras investigábamos y finalmente resultó en una interrupción de 73 horas. En ese momento, compartíamos ambos detalles sobre lo que pasó y algunos de nuestros primeros aprendizajes sobre el tema. Desde entonces, hemos estado estudiando esos aprendizajes y trabajando para aumentar la resiliencia de nuestra infraestructura ante los tipos de fallas que ocurren en todos los sistemas a gran escala debido a factores como picos de tráfico extremos, clima, fallas de hardware, errores de software o simplemente humanos cometiendo errores. Cuando ocurren estas fallas, ¿cómo nos aseguramos de que un problema en un solo componente o grupo de componentes no se extienda a todo el sistema? Esta pregunta ha sido nuestro enfoque durante los últimos dos años y, si bien el trabajo continúa, lo que hemos hecho hasta ahora ya está dando sus frutos. Por ejemplo, en la primera mitad de 2023, ahorramos 125 millones de horas de participación por mes en comparación con la primera mitad de 2022. Hoy compartimos el trabajo que ya hemos realizado, así como nuestra visión a largo plazo para construir un sistema de infraestructura más resiliente.
Construyendo un respaldo
Dentro de los sistemas de infraestructura a gran escala, las fallas a pequeña escala ocurren muchas veces al día. Si una máquina tiene un problema y debe ser puesta fuera de servicio, eso es manejable porque la mayoría de las empresas mantienen múltiples instancias de sus servicios back-end. Entonces, cuando una sola instancia falla, otras asumen la carga de trabajo. Para solucionar estos errores frecuentes, las solicitudes generalmente están configuradas para reintentar automáticamente si obtienen un error.
Esto se vuelve un desafío cuando un sistema o una persona lo reintenta de manera demasiado agresiva, lo que puede convertirse en una forma de que esas fallas de pequeña escala se propaguen por la infraestructura a otros servicios y sistemas. Si la red o un usuario lo reintenta con suficiente persistencia, eventualmente sobrecargará cada instancia de ese servicio, y potencialmente otros sistemas, a nivel mundial. Nuestra interrupción de 2021 fue el resultado de algo que es bastante común en sistemas a gran escala: una falla comienza pequeña y luego se propaga por el sistema y se hace tan grande que es difícil de resolver antes de que todo falle.
En el momento de nuestra interrupción, teníamos un centro de datos activo (con componentes dentro que actuaban como respaldo). Necesitábamos la capacidad de realizar una conmutación por error manualmente a un nuevo centro de datos cuando un problema provocaba la caída del existente. Nuestra primera prioridad era asegurarnos de tener una implementación de respaldo de Roblox, por lo que creamos ese respaldo en un nuevo centro de datos, ubicado en una región geográfica diferente. Eso agregó protección para el peor de los casos: una interrupción que se propague a suficientes componentes dentro de un centro de datos que se vuelva completamente inoperable. Ahora tenemos un centro de datos que maneja cargas de trabajo (activo) y otro en espera, que sirve como respaldo (pasivo). Nuestro objetivo a largo plazo es pasar de esta configuración activo-pasivo a una configuración activo-activo, en la que ambos centros de datos manejan cargas de trabajo, con un equilibrador de carga que distribuye las solicitudes entre ellos en función de la latencia, la capacidad y el estado. Una vez que esto esté implementado, esperamos tener una confiabilidad aún mayor para todo Roblox y poder fallar casi instantáneamente en lugar de varias horas. 
Pasar a una infraestructura celular
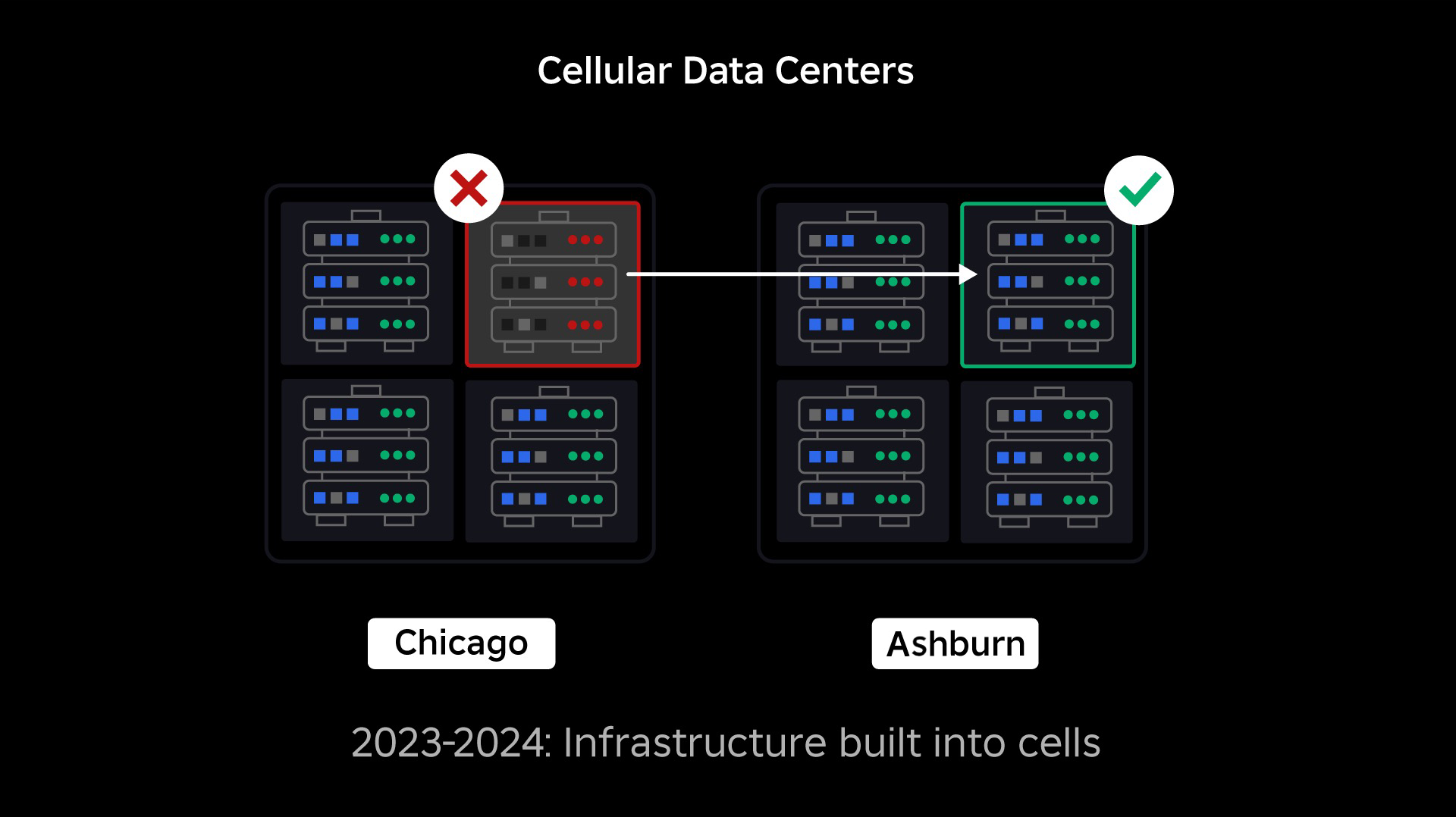
Nuestra siguiente prioridad fue crear muros resistentes contra explosiones dentro de cada centro de datos para reducir la posibilidad de que fallara todo un centro de datos. Las células (algunas empresas las llaman clústeres) son esencialmente un conjunto de máquinas y son la forma en que creamos estos muros. Replicamos servicios tanto dentro como entre celdas para mayor redundancia. En última instancia, queremos que todos los servicios de Roblox se ejecuten en celdas para que puedan beneficiarse tanto de fuertes barreras contra explosiones como de redundancia. Si una celda ya no funciona, se puede desactivar de forma segura. La replicación entre celdas permite que el servicio siga ejecutándose mientras se repara la celda. En algunos casos, la reparación celular puede significar un reaprovisionamiento completo de la célula. En toda la industria, limpiar y reaprovisionar una máquina individual, o un pequeño conjunto de máquinas, es bastante común, pero hacerlo para una celda completa, que contiene aproximadamente 1,400 máquinas, no lo es.
Para que esto funcione, estas celdas deben ser en gran medida uniformes, de modo que podamos mover cargas de trabajo de una celda a otra de manera rápida y eficiente. Hemos establecido ciertos requisitos que los servicios deben cumplir antes de ejecutarse en una celda. Por ejemplo, los servicios deben estar en contenedores, lo que los hace mucho más portátiles y evita que alguien realice cambios de configuración a nivel del sistema operativo. Hemos adoptado una filosofía de infraestructura como código para las celdas: en nuestro repositorio de código fuente, incluimos la definición de todo lo que hay en una celda para que podamos reconstruirla rápidamente desde cero utilizando herramientas automatizadas.
Actualmente, no todos los servicios cumplen con estos requisitos, por lo que hemos trabajado para ayudar a los propietarios de servicios a cumplirlos siempre que sea posible y hemos creado nuevas herramientas para facilitar la migración de servicios a celdas cuando estén listos. Por ejemplo, nuestra nueva herramienta de implementación “divide” automáticamente la implementación de un servicio en todas las celdas, de modo que los propietarios del servicio no tengan que pensar en la estrategia de replicación. Este nivel de rigor hace que el proceso de migración sea mucho más desafiante y requiera más tiempo, pero la recompensa a largo plazo será un sistema en el que:
- Es mucho más fácil contener una falla y evitar que se propague a otras células;
- Nuestros ingenieros de infraestructura pueden ser más eficientes y moverse más rápidamente; y
- Los ingenieros que crean los servicios a nivel de producto que finalmente se implementan en las celdas no necesitan saber ni preocuparse por en qué celdas se ejecutan sus servicios.
Resolviendo desafíos más grandes
De manera similar a la forma en que se utilizan las puertas cortafuegos para contener las llamas, las celdas actúan como fuertes muros contra explosiones dentro de nuestra infraestructura para ayudar a contener cualquier problema que esté provocando una falla dentro de una sola celda. Con el tiempo, todos los servicios que componen Roblox se implementarán de forma redundante dentro y entre las células. Una vez que se complete este trabajo, los problemas aún podrían propagarse lo suficiente como para dejar inoperable una celda entera, pero sería extremadamente difícil que un problema se propague más allá de esa celda. Y si logramos que las células sean intercambiables, la recuperación será mucho más rápida porque podremos realizar una conmutación por error a una celda diferente y evitar que el problema afecte a los usuarios finales.
Lo complicado es separar estas celdas lo suficiente como para reducir la oportunidad de propagar errores y, al mismo tiempo, mantener el rendimiento y la funcionalidad. En un sistema de infraestructura complejo, los servicios necesitan comunicarse entre sí para compartir consultas, información, cargas de trabajo, etc. A medida que replicamos estos servicios en células, debemos reflexionar sobre cómo gestionamos la comunicación cruzada. En un mundo ideal, redirigimos el tráfico de una célula enferma a otras células sanas. Pero, ¿cómo gestionamos una “consulta sobre la muerte”, una que es causando ¿Una célula no es saludable? Si redirigimos esa consulta a otra celda, puede hacer que esa celda deje de estar en buen estado justo en la forma que estamos tratando de evitar. Necesitamos encontrar mecanismos para desviar el tráfico "bueno" de las células en mal estado y al mismo tiempo detectar y silenciar el tráfico que está provocando que las células se vuelvan en mal estado.
A corto plazo, hemos implementado copias de servicios informáticos en cada celda informática para que la mayoría de las solicitudes al centro de datos puedan ser atendidas por una sola celda. También equilibramos la carga del tráfico entre celdas. Mirando más allá, hemos comenzado a construir un proceso de descubrimiento de servicios de próxima generación que será aprovechado por una malla de servicios, que esperamos completar en 2024. Esto nos permitirá implementar políticas sofisticadas que permitirán la comunicación entre células solo cuando no afectará negativamente a las celdas de conmutación por error. También llegará en 2024 un método para dirigir solicitudes dependientes a una versión de servicio en la misma celda, lo que minimizará el tráfico entre celdas y, por lo tanto, reducirá el riesgo de propagación de fallas entre celdas.
En su punto máximo, más del 70 por ciento de nuestro tráfico de servicios back-end se sirve desde celdas y hemos aprendido mucho sobre cómo crear celdas, pero anticipamos más investigaciones y pruebas a medida que continuamos migrando nuestros servicios hasta 2024 y más allá de. A medida que avancemos, estos muros explosivos se volverán cada vez más fuertes.
Migrar una infraestructura siempre activa
Roblox es una plataforma global que brinda soporte a usuarios de todo el mundo, por lo que no podemos mover servicios durante las horas de menor actividad o durante el "tiempo de inactividad", lo que complica aún más el proceso de migrar todas nuestras máquinas a las celdas y nuestros servicios para ejecutarse en esas celdas. . Tenemos millones de experiencias siempre activas que necesitan seguir siendo compatibles, incluso cuando trasladamos las máquinas en las que se ejecutan y los servicios que las respaldan. Cuando comenzamos este proceso, no teníamos decenas de miles de máquinas sin usar y disponibles para migrar estas cargas de trabajo.
Sin embargo, teníamos una pequeña cantidad de máquinas adicionales que compramos en previsión de un crecimiento futuro. Para empezar, construimos nuevas células utilizando esas máquinas y luego les migramos cargas de trabajo. Valoramos la eficiencia y la confiabilidad, por lo que en lugar de salir a comprar más máquinas una vez que nos quedamos sin máquinas “de repuesto”, construimos más celdas limpiando y reaprovisionando las máquinas de las que habíamos migrado. Luego migramos cargas de trabajo a esas máquinas reaprovisionadas y comenzamos el proceso nuevamente. Este proceso es complejo: a medida que las máquinas se reemplazan y se liberan para integrarlas en células, no se liberan de manera ideal y ordenada. Están físicamente fragmentados en las salas de datos, lo que nos permite aprovisionarlos de forma gradual, lo que requiere un proceso de desfragmentación a nivel de hardware para mantener las ubicaciones del hardware alineadas con dominios de fallas físicas a gran escala.
Una parte de nuestro equipo de ingeniería de infraestructura se centra en migrar cargas de trabajo existentes de nuestro entorno heredado o "pre-celda" a las celdas. Este trabajo continuará hasta que hayamos migrado miles de servicios de infraestructura diferentes y miles de servicios de back-end a células recién construidas. Esperamos que esto lleve todo el próximo año y posiblemente hasta 2025, debido a algunos factores que complican la situación. En primer lugar, este trabajo requiere la construcción de herramientas sólidas. Por ejemplo, necesitamos herramientas para reequilibrar automáticamente una gran cantidad de servicios cuando implementamos una nueva celda, sin afectar a nuestros usuarios. También hemos visto servicios que se construyeron con suposiciones sobre nuestra infraestructura. Necesitamos revisar estos servicios para que no dependan de cosas que podrían cambiar en el futuro a medida que avancemos hacia las células. También implementamos una forma de buscar patrones de diseño conocidos que no funcionarán bien con la arquitectura celular, así como un proceso de prueba metódico para cada servicio que se migra. Estos procesos nos ayudan a evitar cualquier problema que surja en el usuario debido a que un servicio es incompatible con las celdas.
Hoy en día, las células gestionan cerca de 30,000 máquinas. Es solo una fracción de nuestra flota total, pero hasta ahora ha sido una transición muy fluida sin ningún impacto negativo para los jugadores. Nuestro objetivo final es que nuestros sistemas logren un tiempo de actividad del usuario del 99.99 por ciento cada mes, lo que significa que no interrumpiríamos más del 0.01 por ciento de las horas de participación. En toda la industria, el tiempo de inactividad no se puede eliminar por completo, pero nuestro objetivo es reducir cualquier tiempo de inactividad de Roblox a un grado que sea casi imperceptible.
Prepararnos para el futuro a medida que escalamos
Si bien nuestros primeros esfuerzos están teniendo éxito, nuestro trabajo con las células está lejos de terminar. A medida que Roblox siga creciendo, seguiremos trabajando para mejorar la eficiencia y la resiliencia de nuestros sistemas a través de esta y otras tecnologías. A medida que avancemos, la plataforma será cada vez más resistente a los problemas, y cualquier problema que surja debería volverse progresivamente menos visible y perjudicial para las personas en nuestra plataforma.
En resumen, a la fecha tenemos:
- Construyó un segundo centro de datos y logró con éxito el estado activo/pasivo.
- Creamos células en nuestros centros de datos activos y pasivos y migramos con éxito más del 70 por ciento de nuestro tráfico de servicios back-end a estas células.
- Establecer los requisitos y las mejores prácticas que necesitaremos seguir para mantener todas las células uniformes a medida que continuamos migrando el resto de nuestra infraestructura.
- Se inició un proceso continuo de construcción de "paredes explosivas" más fuertes entre las células.
A medida que estas celdas se vuelvan más intercambiables, habrá menos diafonía entre las celdas. Esto abre algunas oportunidades muy interesantes para nosotros en términos de aumentar la automatización en torno al monitoreo, la resolución de problemas e incluso el cambio automático de cargas de trabajo.
En septiembre también comenzamos a realizar experimentos activo/activo en nuestros centros de datos. Este es otro mecanismo que estamos probando para mejorar la confiabilidad y minimizar los tiempos de conmutación por error. Estos experimentos ayudaron a identificar una serie de patrones de diseño de sistemas, en gran medida relacionados con el acceso a datos, que debemos reelaborar a medida que avanzamos hacia la plena actividad activa. En general, el experimento fue lo suficientemente exitoso como para dejarlo funcionando para el tráfico de un número limitado de nuestros usuarios.
Estamos entusiasmados de seguir impulsando este trabajo para brindar mayor eficiencia y resiliencia a la plataforma. Este trabajo en células e infraestructura activa-activa, junto con nuestros otros esfuerzos, nos permitirá convertirnos en una empresa de servicios públicos confiable y de alto rendimiento para millones de personas y continuar escalando mientras trabajamos para conectar a mil millones de personas en tiempo real. tiempo.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/

