Introducción
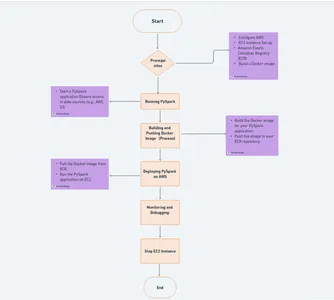
En big data y análisis avanzado, PySpark se ha convertido en una poderosa herramienta para procesar grandes conjuntos de datos y analizar datos distribuidos. La implementación de PySpark en aplicaciones de AWS en la nube puede cambiar las reglas del juego, ya que ofrece escalabilidad y flexibilidad para tareas con uso intensivo de datos. Amazon Web Services (AWS) proporciona una plataforma ideal para este tipo de implementaciones y, cuando se combina con contenedores Docker, se convierte en una solución perfecta y eficiente.

Sin embargo, implementar PySpark en una infraestructura de nube puede resultar complejo y desalentador. Las complejidades de configurar un entorno informático distribuido, configurar clústeres Spark y administrar recursos a menudo disuaden a muchos de aprovechar todo su potencial.
OBJETIVOS DE APRENDIZAJE
- Conozca los conceptos fundamentales de PySpark, AWS y Docker, lo que garantiza una base sólida para implementar clústeres de PySpark en la nube.
- Siga una guía completa paso a paso para configurar PySpark en AWS usando Docker, incluida la configuración de AWS, la preparación de imágenes de Docker y la administración de clústeres de Spark.
- Descubra estrategias para optimizar el rendimiento de PySpark en AWS, incluido el monitoreo, el escalado y el cumplimiento de las mejores prácticas para aprovechar al máximo sus flujos de trabajo de procesamiento de datos.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.

Requisitos previos
Antes de emprender el viaje para implementar PySpark en AWS utilizando Docker, asegúrese de cumplir con los siguientes requisitos previos:
🚀 Instalación local de PySpark: Para desarrollar y probar aplicaciones PySpark, es esencial tener PySpark instalado en su máquina local. Puede instalar PySpark siguiendo la documentación oficial de su sistema operativo. Esta instalación local servirá como su entorno de desarrollo, permitiéndole escribir y probar el código PySpark antes de implementarlo en AWS.
🌐 Cuenta de AWS: Necesitará una cuenta activa de AWS (Amazon Web Services) para acceder a la infraestructura y los servicios de la nube necesarios para la implementación de PySpark. Puede registrarse en el sitio web de AWS si no tiene una cuenta de AWS. Esté preparado para proporcionar su información de pago, aunque AWS ofrece un nivel gratuito con recursos limitados para nuevos usuarios.
???? Instalación de ventana acoplable: Docker es un componente fundamental en este proceso de implementación. Instale Docker en su máquina local siguiendo las instrucciones de instalación para el sistema operativo Ubuntu. Los contenedores Docker le permitirán encapsular e implementar sus aplicaciones PySpark de manera consistente.
Windows
- Visita el sitio web de
- Descargue nuestra Escritorio Docker para Windows instalador.
- Haga doble clic en el instalador para ejecutarlo.
- Siga las instrucciones del asistente de instalación.
- Una vez instalado, inicie Docker Desktop desde sus aplicaciones.
macOS
- Diríjase a la
- Descargue nuestra Docker Desktop para Mac instalador.
- Haga doble clic en el instalador para abrirlo.
- Arrastre el ícono de Docker a su carpeta de Aplicaciones.
- Inicie Docker desde sus aplicaciones.
Linux (Ubuntu)
1. Abra su terminal y actualice su administrador de paquetes:
sudo apt-get update2. Instale las dependencias necesarias:
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common3. Agregue la clave GPG oficial de Docker:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg4. Configure el repositorio de Docker:
echo "deb [signed-by=/usr/share/keyrings/docker-archive-keyring.gpg]
https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null5. Actualice el índice de su paquete nuevamente:
sudo apt-get update6. Instalar ventana acoplable:
sudo apt-get install -y docker-ce docker-ce-cli containerd.io7. Inicie y habilite el servicio Docker:
sudo systemctl start docker
sudo systemctl enable docker8. Verifique la instalación:
sudo docker --version**** Agregar líneas divididas en una línea
Vea un vídeo tutorial sobre la instalación de Docker
Configuración de AWS
Amazon Web Services (AWS) es la columna vertebral de nuestra implementación de PySpark y utilizaremos dos servicios esenciales, Elastic Container Registry (ECR) y Elastic Compute Cloud (EC2), para crear un entorno de nube dinámico.
Registro de cuenta de AWS
Si aún no lo has hecho, dirígete al Página de registro de AWS para crear una cuenta. Siga el proceso de registro, proporcione la información necesaria y esté preparado con sus detalles de pago si desea explorar más allá de la capa gratuita de AWS.
Nivel gratuito de AWS
Para aquellos nuevos en AWS, aproveche la capa gratuita de AWS, que ofrece recursos y servicios limitados sin costo durante 12 meses. Esta es una excelente manera de explorar AWS sin incurrir en cargos.
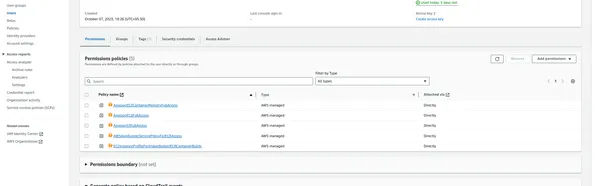
Clave de acceso y clave secreta de AWS
Necesitará un ID de clave de acceso y una clave de acceso secreta para interactuar con AWS mediante programación. Sigue estos pasos para generarlos:
- Inicie sesión en la Consola de administración de AWS.
- Navegue hasta el servicio Gestión de identidad y acceso (IAM).
- Haga clic en "Usuarios" en el panel de navegación izquierdo.
- Cree un nuevo usuario o seleccione uno existente.
- En la pestaña "Credenciales de seguridad", genere una clave de acceso.
- Anote el ID de la clave de acceso y la clave de acceso secreta, ya que las usaremos más adelante.
- Después de hacer clic en usuario
Registro de contenedor elástico (ECR)
ECR es un servicio de registro de contenedores Docker administrado proporcionado por AWS. Será nuestro repositorio para almacenar imágenes de Docker. Puede configurar su ECR siguiendo estos pasos:
- En la Consola de administración de AWS, navegue hasta el servicio Amazon ECR.
- Cree un nuevo repositorio, asígnele un nombre y configure los ajustes del repositorio.
- Anote el URI de su repositorio ECR; lo necesitará para insertar imágenes en Docker.
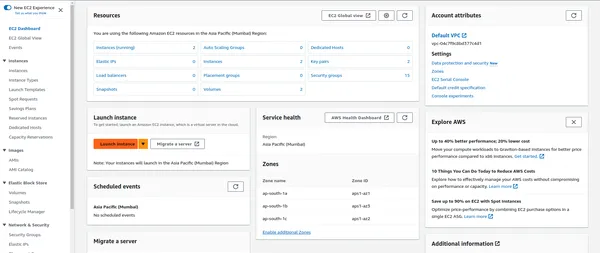
Nube de computación elástica (EC2)
EC2 proporciona capacidad informática escalable en la nube y alojará sus aplicaciones PySpark. Para configurar una instancia EC2:
- En la Consola de administración de AWS, navegue hasta el servicio EC2.
- Inicie una nueva instancia EC2 y elija el tipo de instancia que se adapte a su carga de trabajo.
- Configure los detalles de la instancia y las opciones de almacenamiento.
- Cree o seleccione un par de claves existente para conectarse de forma segura a su instancia EC2.
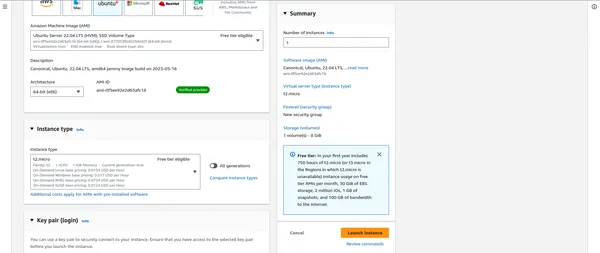
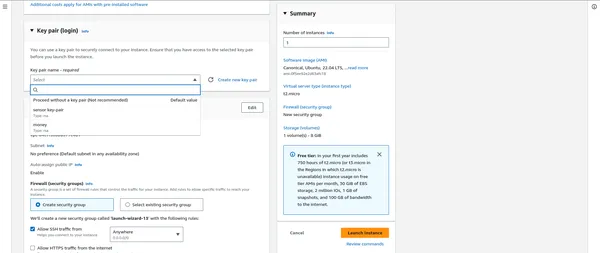
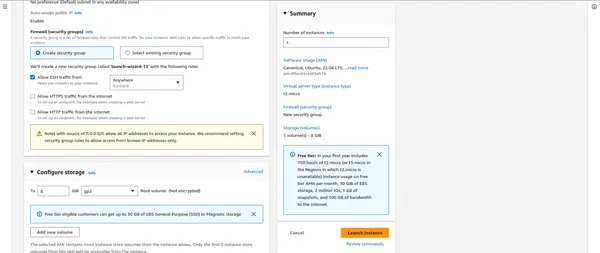
“””” AQUÍ IMPORTANTE DESPUÉS DE ESO ADJUNTAR LOS GRUPOS DE SEGURIDAD “”””
Almacenamiento de los valores de configuración de AWS para uso futuro
AWS_ACCESS_KEY_ID: AKIAYOURSAMPLEACCESSKEY
AWS_ECR_LOGIN_URI: 123456789012.dkr.ecr.region.amazonaws.com
AWS_REGION: us-east-1
AWS_SECRET_ACCESS_KEY: YOURSAMPLESECRETACCESSKEY12345
ECR_REPOSITORY_NAME: your-ecr-repository-nameConfigurar secretos y variables de GitHub
Ahora que tiene listos los valores de configuración de AWS, es hora de configurarlos de forma segura en su repositorio de GitHub utilizando secretos y variables de GitHub. Esto agrega una capa adicional de seguridad y conveniencia a su proceso de implementación de PySpark.
Siga estos pasos para configurar sus valores de AWS:
Acceda a su repositorio de GitHub
- Puede simplemente navegar a su repositorio de GitHub, donde aloja su proyecto PySpark.
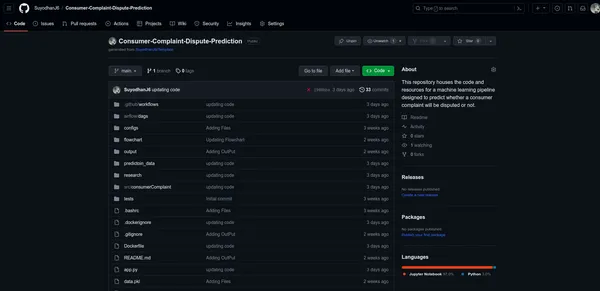
Acceder a la configuración del repositorio
- Dentro de su repositorio, haga clic en la pestaña "Configuración".
Gestión de secretos
- En la barra lateral izquierda, encontrarás una opción llamada "Secretos". Haga clic en él para acceder a la interfaz de administración de secretos de GitHub.
Agregar un nuevo secreto
- Aquí puede agregar sus valores de configuración de AWS como secretos.
- Haga clic en "Nuevo secreto del repositorio" para crear un nuevo secreto.
- Para cada valor de AWS, cree un secreto con un nombre que corresponda al propósito del valor (por ejemplo, “AWS_ACCESS_KEY_ID”, “AWS_SECRET_ACCESS_KEY”, “AWS_REGION”, etc.).
- Ingrese el valor real en el campo "Valor".
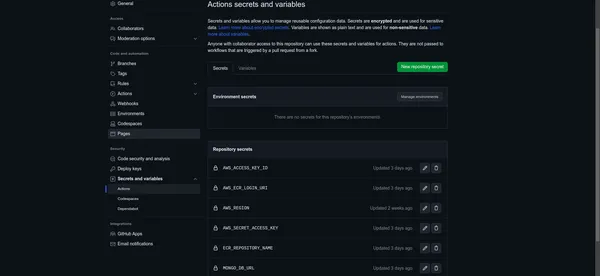
Guarda tus secretos
- Haga clic en el botón "Agregar secreto" para cada valor para guardarlo como un secreto de GitHub.
Con sus secretos de AWS almacenados de forma segura en GitHub, puede hacer referencia a ellos fácilmente en sus flujos de trabajo de GitHub Actions y acceder de forma segura a los servicios de AWS durante la implementación.
Mejores Prácticas
- Los secretos de GitHub están cifrados y solo pueden acceder a ellos usuarios autorizados con los permisos necesarios. Esto garantiza la seguridad de sus valores confidenciales de AWS.
- Al utilizar los secretos de GitHub, evita exponer información confidencial directamente en su código o archivos de configuración, lo que mejora la seguridad de su proyecto.
Sus valores de configuración de AWS ahora están configurados de forma segura en su repositorio de GitHub, lo que los hace disponibles para su flujo de trabajo de implementación de PySpark.
Comprender la estructura del código
Para implementar PySpark de manera efectiva en AWS usando Docker, es esencial comprender la estructura del código de su proyecto. Analicemos los componentes que componen el código base:
├── .github
│ ├── workflows
│ │ ├── build.yml
├── airflow
├── configs
├── consumerComplaint
│ ├── cloud_storage
│ ├── components
│ ├── config
│ │ ├── py_sparkmanager.py
│ ├── constants
│ ├── data_access
│ ├── entity
│ ├── exceptions
│ ├── logger
│ ├── ml
│ ├── pipeline
│ ├── utils
├── output
│ ├── .png
├── prediction_data
├── research
│ ├── jupyter_notebooks
├── saved_models
│ ├── model.pkl
├── tests
├── venv
├── Dockerfile
├── app.py
├── requirements.txt
├── .gitignore
├── .dockerignore
Código de aplicación (app.py)
- app.py es su script Python principal responsable de ejecutar la aplicación PySpark.
- Es el punto de entrada para sus trabajos de PySpark y sirve como núcleo de su aplicación.
- Puede personalizar este script para definir sus canales de procesamiento de datos, programación de trabajos y más.
Dockerfile
- El Dockerfile contiene instrucciones para crear una imagen de Docker para su aplicación PySpark.
- Especifica la imagen base, agrega las dependencias necesarias, copia el código de la aplicación en el contenedor y configura el entorno de ejecución.
- Este archivo juega un papel crucial en la creación de contenedores de su aplicación para una implementación perfecta.
Requisitos (requisitos.txt)
- requisitos.txt enumera los paquetes de Python y las dependencias necesarias para su aplicación PySpark.
- Estos paquetes se instalan dentro del contenedor Docker para garantizar que su aplicación se ejecute sin problemas.
Flujos de trabajo de acciones de GitHub
- Los flujos de trabajo de GitHub Actions se definen en .github/workflows/ dentro del repositorio de su proyecto.
- Automatizan los procesos de construcción, prueba e implementación.
- Los archivos de flujo de trabajo, como main.yml, describen los pasos a ejecutar cuando ocurren eventos específicos, como envíos de código o solicitudes de extracción.
Construya py_sparkmanager.py
import os
from dotenv import load_dotenv
from pyspark.sql import SparkSession # Load environment variables from .env
load_dotenv() access_key_id = os.getenv("AWS_ACCESS_KEY_ID")
secret_access_key = os.getenv("AWS_SECRET_ACCESS_KEY") # Initialize SparkSession
spark_session = SparkSession.builder.master('local[*]').appName('consumer_complaint') .config("spark.executor.instances", "1") .config("spark.executor.memory", "6g") .config("spark.driver.memory", "6g") .config("spark.executor.memoryOverhead", "8g") .config('spark.jars.packages', "com.amazonaws:aws-java-sdk:1.7.4, org.apache.hadoop:hadoop-aws:2.7.3") .getOrCreate() # Configure SparkSession for AWS S3 access
spark_session._jsc.hadoopConfiguration().set("fs.s3a.awsAccessKeyId", access_key_id)
spark_session._jsc.hadoopConfiguration().set("fs.s3a.awsSecretAccessKey", secret_access_key)
spark_session._jsc.hadoopConfiguration().set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
spark_session._jsc.hadoopConfiguration().set("com.amazonaws.services.s3.enableV4", "true")
spark_session._jsc.hadoopConfiguration().set("fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.BasicAWSCredentialsProvider")
spark_session._jsc.hadoopConfiguration().set("fs.s3a.endpoint", "ap-south-1.amazonaws.com")
spark_session._jsc.hadoopConfiguration().set("fs.s3.buffer.dir", "tmp")
Este código configura su SparkSession, lo configura para el acceso a AWS S3 y carga las credenciales de AWS a partir de variables de entorno, lo que le permite trabajar con los servicios de AWS sin problemas en su aplicación PySpark.
Preparación de imágenes de PySpark Docker (IMP)
Esta sección explorará cómo crear imágenes de Docker que encapsulan su aplicación PySpark, haciéndola portátil, escalable y lista para su implementación en AWS. Los contenedores Docker brindan un entorno consistente para sus aplicaciones PySpark, lo que garantiza una ejecución perfecta en diversas configuraciones.
Dockerfile
La clave para crear imágenes de Docker para PySpark es un Dockerfile bien definido. Este archivo especifica las instrucciones para configurar el entorno del contenedor, incluidas las dependencias de Python y PySpark.
FROM python:3.8.5-slim-buster
# Use an Ubuntu base image
FROM ubuntu:20.04 # Set JAVA_HOME and install OpenJDK 8
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
RUN apt-get update -y && apt-get install -y openjdk-8-jdk && apt-get install python3-pip -y && apt-get clean && rm -rf /var/lib/apt/lists/* # Set environment variables for your application
ENV AIRFLOW_HOME="/app/airflow"
ENV PYSPARK_PYTHON=/usr/bin/python3
ENV PYSPARK_DRIVER_PYTHON=/usr/bin/python3 # Create a directory for your application and set it as the working directory
WORKDIR /app # Copy the contents of the current directory to the working directory in the container
COPY . /app # Install Python dependencies from requirements.txt
RUN pip3 install -r requirements.txt # Set the entry point to run your app.py script
CMD ["python3", "app.py"]
Creación de la imagen de Docker
Una vez que tenga su Dockerfile listo, puede crear la imagen de Docker usando el siguiente comando:
docker build -t your-image-nameReemplaza nombre-de-su-imagen con el nombre y la versión deseados para su imagen de Docker.
Verificación de la imagen local
Después de crear la imagen, puede enumerar sus imágenes de Docker locales usando el siguiente comando:
docker images docker ps -a docker system dfEjecutando PySpark en Docker
Con su imagen de Docker preparada, puede continuar y ejecutar su aplicación PySpark en un contenedor Docker. Utilice el siguiente comando:
docker run -your-image-name“”” EN ALGÚN MOMENTO la ventana acoplable ejecuta el COMANDO NO FUNCIONA SIGA EL COMANDO A CONTINUACIÓN. “””
docker run 80:8080 your-image-name docker run 8080:8080 your-image-name
Implementación de PySpark en AWS
Esta sección le explicará cómo implementar su aplicación PySpark en AWS utilizando contenedores Docker. Esta implementación implicará el lanzamiento de instancias de Amazon Elastic Compute Cloud (EC2) para crear un clúster de PySpark.
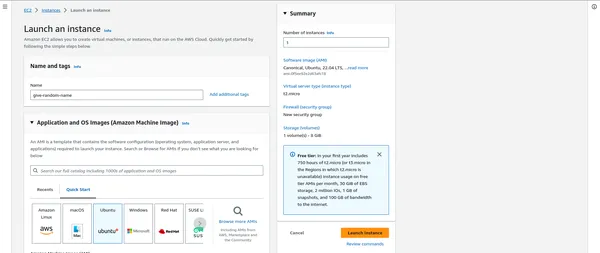
Lanzar instancias EC2
- En el Panel de EC2, haga clic en "Iniciar instancias".
- Puede seleccionar una imagen de máquina de Amazon (AMI) que se adapte a sus necesidades, a menudo basada en Linux.
- Dependiendo de su carga de trabajo, elija el tipo de instancia (por ejemplo, m5.large, c5.xlarge).
- Configure los detalles de la instancia, incluida la cantidad de instancias en su clúster.
- Agregue almacenamiento, etiquetas y grupos de seguridad según sea necesario.
Esto es todo lo que mencioné anteriormente.
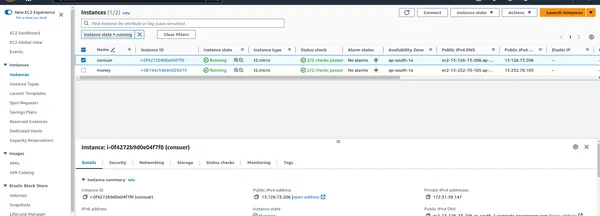
Conéctese a instancias EC2
- Una vez que se ejecutan las instancias, puede acceder mediante SSH a ellas para administrar su clúster PySpark.
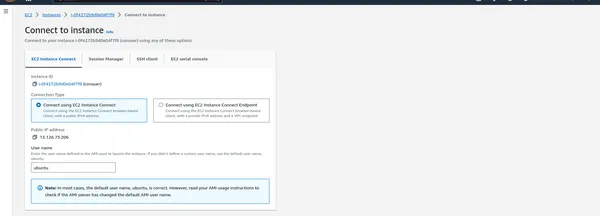
Escriba el siguiente comando
Descargue el script de instalación de Docker
curl -fsSL https://get.docker.com -o get-docker.shEjecute el script de instalación de Docker con privilegios de root
sudo sh get-docker.shAgregue el usuario actual al grupo de Docker (reemplace 'ubuntu' con su nombre de usuario)
sudo usermod -aG docker ubuntuActive los cambios ejecutando una nueva sesión de shell o usando 'newgrp'
newgrp dockerConstruyendo un ejecutor autohospedado de GitHub
Configuraremos un ejecutor autohospedado para GitHub Actions, responsable de ejecutar sus flujos de trabajo de CI/CD. Un ejecutor autohospedado se ejecuta en su infraestructura y es una buena opción para ejecutar flujos de trabajo que requieren configuraciones específicas o acceso a recursos locales.
Configurar el ejecutor autohospedado
- Haga clic en Configuración
- Haga clic en Acción -> Corredor
- Haga Clic en Nuevo corredor autohospedado
Escriba el siguiente comando en la máquina EC2
- Crear una carpeta: este comando crea un directorio llamado action-runner y cambia el directorio actual a esta carpeta recién creada.
$ mkdir actions-runner && cd actions-runner
- Descargue el paquete de ejecución más reciente: este comando descarga el paquete de ejecución de GitHub Actions para Linux x64. Especifica la URL del paquete a descargar y lo guarda con el nombre de archivo acciones-runner-linux-x64-2.309.0.tar.gz.
$ curl -o actions-runner-linux-x64-2.309.0.tar.gz -L https://github.com/actions/runner/releases/download/v2.309.0/actions-runner-linux-x64-2.309.0.tar.gz
- Opcional: Validar el hash: este comando verifica la integridad del paquete descargado validando su hash. Calcula el hash SHA-256 del paquete descargado y lo compara con un hash conocido y esperado. Si coinciden, el paquete se considera válido.
$ echo "2974243bab2a282349ac833475d241d5273605d3628f0685bd07fb5530f9bb1a actions-runner-linux-x64-2.309.0.tar.gz" | shasum -a 256 -c
- Extraiga el instalador: este comando extrae el contenido del paquete descargado, que es un tarball (archivo comprimido).
$ tar xzf ./actions-runner-linux-x64-2.309.0.tar.gz
- Último paso, ejecútelo: este comando inicia el ejecutor con los ajustes de configuración proporcionados. Configura el ejecutor para ejecutar flujos de trabajo de GitHub Actions para el repositorio especificado.
$ ./run.sh
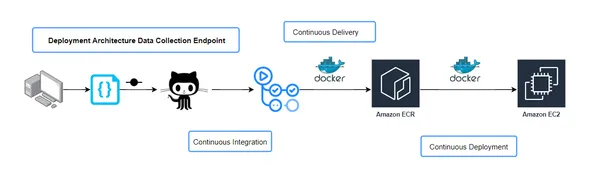
Configuración del flujo de trabajo de integración continua y entrega continua (CICD)
En una canalización de CI/CD, el archivo build.yaml es crucial para definir los pasos necesarios para compilar e implementar su aplicación. Este archivo de configuración especifica el flujo de trabajo para su proceso de CI/CD, incluido cómo se crea, prueba e implementa el código. Profundicemos en los aspectos críticos de la configuración de build.yaml y su importancia:
Descripción general del flujo de trabajo
El archivo build.yaml describe las tareas ejecutadas durante la canalización de CI/CD. Define los pasos para la integración continua, que implica construir y probar su aplicación y la entrega continua, donde la aplicación se implementa en varios entornos.
Integración continua (CI)
Esta fase suele incluir tareas como compilación de código, pruebas unitarias y comprobaciones de calidad del código. El archivo build.yaml especifica las herramientas, scripts y comandos necesarios para realizar estas tareas. Por ejemplo, podría desencadenar la ejecución de pruebas unitarias para garantizar la calidad del código.
Entrega continua (CD)
Después de una CI exitosa, la fase de CD implica implementar la aplicación en diferentes entornos, como prueba o producción. El archivo build.yaml especifica cómo debe realizarse la implementación, incluido dónde y cuándo implementarla y qué configuraciones usar.
Manejo de dependencia
El archivo build.yaml suele incluir detalles sobre las dependencias del proyecto. Define dónde obtener bibliotecas o dependencias externas, lo que puede ser crucial para la construcción e implementación exitosa de la aplicación.
Variables de entorno
Los flujos de trabajo de CI/CD a menudo requieren configuraciones específicas del entorno, como claves API o cadenas de conexión. El archivo build.yaml puede definir cómo se configuran estas variables de entorno para cada etapa de la canalización.
Notificaciones y alertas
En caso de fallas o problemas durante el proceso de CI/CD, las notificaciones y alertas son esenciales. El archivo build.yaml puede configurar cómo y a quién se envían estas alertas, lo que garantiza que los problemas se solucionen con prontitud.
Artefactos y resultados
Dependiendo del flujo de trabajo de CI/CD, el archivo build.yaml puede especificar qué artefactos o resultados de compilación deben generarse y dónde deben almacenarse. Estos artefactos se pueden utilizar para implementaciones o pruebas adicionales.
Al comprender el archivo build.yaml y sus componentes, puede administrar y personalizar de manera efectiva su flujo de trabajo de CI/CD para satisfacer las necesidades de su proyecto. Es el modelo para todo el proceso de automatización, desde cambios de código hasta implementaciones de producción.
Canalización de CI/CD
Puede personalizar aún más el contenido según los detalles específicos de su configuración de build.yaml y cómo encaja en su canal de CI/CD.
name: workflow on: push: branches: - main paths-ignore: - 'README.md' permissions: id-token: write contents: read jobs: integration: name: Continuous Integration runs-on: ubuntu-latest steps: - name: Checkout Code uses: actions/checkout@v3 - name: Lint code run: echo "Linting repository" - name: Run unit tests run: echo "Running unit tests" build-and-push-ecr-image: name: Continuous Delivery needs: integration runs-on: ubuntu-latest steps: - name: Checkout Code uses: actions/checkout@v3 - name: Install Utilities run: | sudo apt-get update sudo apt-get install -y jq unzip - name: Configure AWS credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ${{ secrets.AWS_REGION }} - name: Login to Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v1 - name: Build, tag, and push image to Amazon ECR id: build-image env: ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }} ECR_REPOSITORY: ${{ secrets.ECR_REPOSITORY_NAME }} IMAGE_TAG: latest run: | # Build a docker container and # push it to ECR so that it can # be deployed to ECS. docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG . docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG echo "::set-output name=image::$ECR_REGISTRY/$ECR_REPOSITORY :$IMAGE_TAG" Continuous-Deployment: needs: build-and-push-ecr-image runs-on: self-hosted steps: - name: Checkout uses: actions/checkout@v3 - name: Configure AWS credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ${{ secrets.AWS_REGION }} - name: Login to Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v1 - name: Pull latest images run: | docker pull ${{secrets.AWS_ECR_LOGIN_URI}}/${{ secrets. ECR_REPOSITORY_NAME }}:latest - name: Stop and remove sensor container if running run: | docker ps -q --filter "name=sensor" | grep -q . && docker stop sensor && docker rm -fv sensor - name: Run Docker Image to serve users run: | docker run -d -p 80:8080 --name=sensor -e 'AWS_ACCESS_KEY_ID= ${{ secrets.AWS_ACCESS_KEY_ID }} ' -e 'AWS_SECRET_ACCESS_KEY=${{ secrets.AWS_SECRET_ACCESS_KEY }}' -e 'AWS_REGION=${{ secrets.AWS_REGION }}' ${{secrets.AWS_ECR_LOGIN_URI}}/ ${{ secrets.ECR_REPOSITORY_NAME }}:latest - name: Clean previous images and containers run: | docker system prune -fNota: Todas las líneas divididas se unen como una sola
Si ocurre algún problema, siga el repositorio de GitHub que mencioné la última vez.
Trabajo de implementación continua:
- Este trabajo depende del “Trabajo de creación y envío de imágenes ECR” y está configurado para ejecutarse en un ejecutor autohospedado.
- Verifica el código y configura las credenciales de AWS.
- Inicia sesión en Amazon ECR.
- Extrae la última imagen de Docker del repositorio ECR especificado.
- Detiene y elimina un contenedor Docker llamado "sensor" si se está ejecutando.
- Ejecuta un contenedor Docker llamado "sensor" con la configuración especificada, las variables de entorno y la imagen de Docker extraída anteriormente.
- Finalmente, limpia imágenes y contenedores de Docker anteriores mediante la poda del sistema Docker.
Automatizar la ejecución del flujo de trabajo en cambios de código
Para que todo el proceso de CI/CD sea fluido y responda a los cambios de código, puede configurar su repositorio para activar el flujo de trabajo cuando el código se confirma automáticamente o se envía. Cada vez que guarde y envíe cambios a su repositorio, la canalización de CI/CD comenzará a hacer su magia.
Al automatizar la ejecución del flujo de trabajo, se asegura de que su aplicación permanezca actualizada con los últimos cambios sin intervención manual. Esta automatización puede mejorar significativamente la eficiencia del desarrollo y proporcionar retroalimentación rápida sobre los cambios de código, lo que facilita la detección y resolución de problemas en las primeras etapas del ciclo de desarrollo.
Para configurar la ejecución automatizada del flujo de trabajo en cambios de código, siga estos pasos:
git add . git commit -m "message" git push origin mainConclusión
En esta guía completa, lo guiamos a través del complejo proceso de implementación de PySpark en AWS utilizando EC2 y ECR. Al utilizar la contenedorización y la integración y entrega continuas, este enfoque proporciona una solución sólida y adaptable para gestionar tareas de procesamiento y análisis de datos a gran escala. Si sigue los pasos descritos en este blog, podrá aprovechar todo el poder de PySpark en un entorno de nube, aprovechando la escalabilidad y flexibilidad que ofrece AWS.
Es importante señalar que AWS presenta muchas opciones de implementación, desde EC2 y ECR hasta servicios especializados como EMR. La elección del método depende en última instancia de los requisitos únicos de su proyecto. Ya sea que prefiera el enfoque de contenedorización que se muestra aquí u opte por un servicio de AWS diferente, la clave es aprovechar las capacidades de PySpark de manera efectiva en sus aplicaciones basadas en datos. Con AWS como plataforma, está bien equipado para desbloquear todo el potencial de PySpark, marcando el comienzo de una nueva era de análisis y procesamiento de datos. Explore servicios como EMR si se alinean mejor con sus preferencias y casos de uso específicos, ya que AWS proporciona un conjunto de herramientas diverso para implementar PySpark para satisfacer las necesidades únicas de sus proyectos.
Puntos clave
- La implementación de PySpark en AWS con Docker agiliza el procesamiento de big data y ofrece escalabilidad y automatización.
- Las GitHub Actions simplifican el proceso de CI/CD, lo que permite una implementación de código perfecta.
- Aprovechar los servicios de AWS como EC2 y ECR garantiza una gestión sólida del clúster PySpark.
- Este tutorial lo prepara para aprovechar el poder de la computación en la nube para tareas que requieren un uso intensivo de datos.
Preguntas frecuentes
R. PySpark es la biblioteca de Python para Apache Spark, un marco de procesamiento de datos extenso y robusto. La implementación de PySpark en AWS ofrece soluciones escalables y flexibles para tareas con uso intensivo de datos, lo que la convierte en una opción ideal para el análisis de datos distribuidos.
R. Si bien puede ejecutar PySpark localmente, se recomienda la implementación en la nube para manejar grandes conjuntos de datos de manera eficiente. AWS proporciona la infraestructura y las herramientas necesarias para escalar las aplicaciones PySpark.
R. Utilice GitHub Secrets para almacenar las credenciales de AWS y acceder a ellas de forma segura en su flujo de trabajo. Esto garantiza que sus credenciales permanezcan protegidas y no queden expuestas en su código.
R. Los contenedores Docker ofrecen un entorno consistente en diferentes plataformas, lo que garantiza que su aplicación PySpark se ejecute de la misma manera en desarrollo, pruebas y producción. También simplifican el proceso de creación e implementación de aplicaciones PySpark.
El costo de ejecutar PySpark en AWS depende de varios factores, incluido el tipo y la cantidad de instancias EC2 utilizadas, el almacenamiento de datos, la transferencia de datos y más. Monitorear su uso de AWS y optimizar los recursos para administrar los costos de manera eficiente es esencial.
Recursos para el aprendizaje adicional
- Repositorio de GitHub: Acceda al código fuente completo y a las configuraciones utilizadas en este tutorial en la página Repositorio de GitHub de predicción de disputas de quejas del consumidor.
- Documentación de Docker: Profundice en Docker y la contenedorización explorando el documentación oficial de Docker. Encontrará guías completas, mejores prácticas y consejos para dominar Docker.
- Documentación de acciones de GitHub: Libere todo el poder de GitHub Actions consultando el Documentación de acciones de GitHub. Este recurso lo ayudará a crear, personalizar y automatizar sus flujos de trabajo.
- Documentación oficial de PySpark: Para un conocimiento profundo de PySpark, simplemente puede explorar el documentación oficial de PySpark. Obtenga información sobre API, funciones y bibliotecas para el procesamiento de big data.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/11/what-are-the-best-practices-for-deploying-pyspark-on-aws/

