
Imagen del autor
En el mundo actual basado en datos, el análisis y la información de datos le ayudan a aprovecharlos al máximo y a tomar mejores decisiones. Desde la perspectiva de una empresa, proporciona una ventaja competitiva y personaliza todo el proceso.
Este tutorial explorará la biblioteca Python más potente. pandas, y discutiremos las funciones más importantes de esta biblioteca que son importantes para el análisis de datos. Los principiantes también pueden seguir este tutorial debido a su simplicidad y eficiencia. Si no tiene Python instalado en su sistema, puede utilizar Google Colaboratory.
Puede descargar el conjunto de datos de ese liga.
import pandas as pd
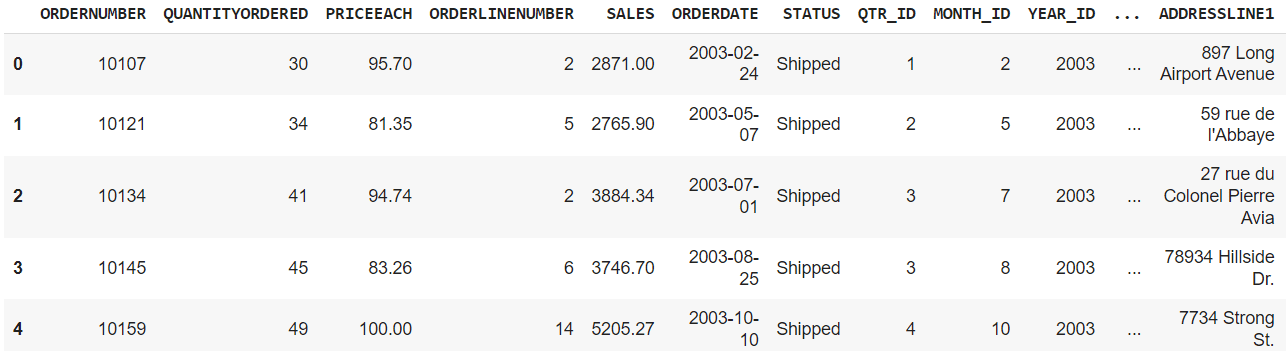
df = pd.read_csv("kaggle_sales_data.csv", encoding="Latin-1") # Load the data df.head() # Show first five rows
Salida:
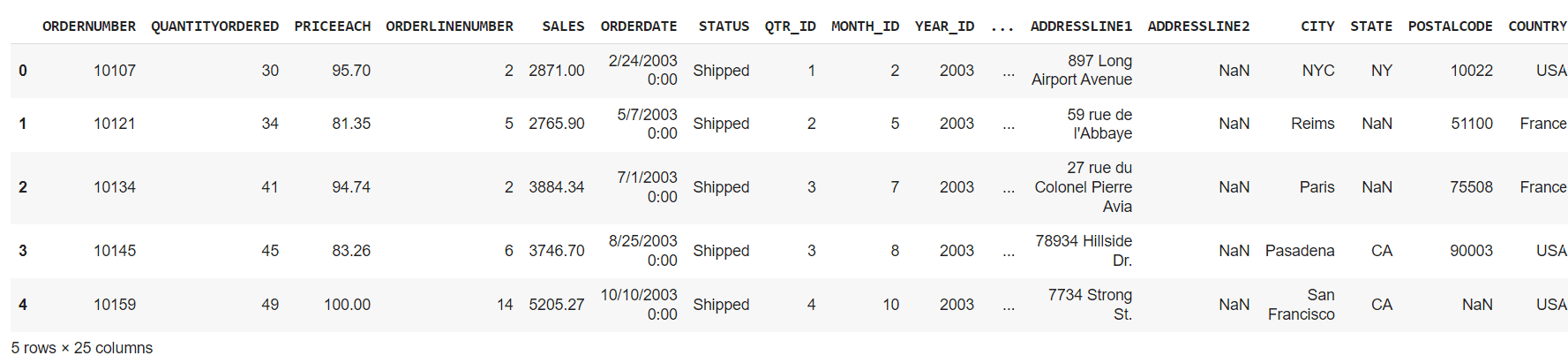
En esta sección, analizaremos varias funciones que le ayudarán a obtener más información sobre sus datos. Como verlo u obtener la media, el promedio, el mínimo/máximo u obtener información sobre el marco de datos.
1. Visualización de datos
-
df.head(): Muestra las primeras cinco filas de los datos de muestra.
-
df.tail(): Muestra las últimas cinco filas de los datos de muestra.

-
df.sample(n): Muestra el número aleatorio de n filas en los datos de muestra.
df.sample(6)
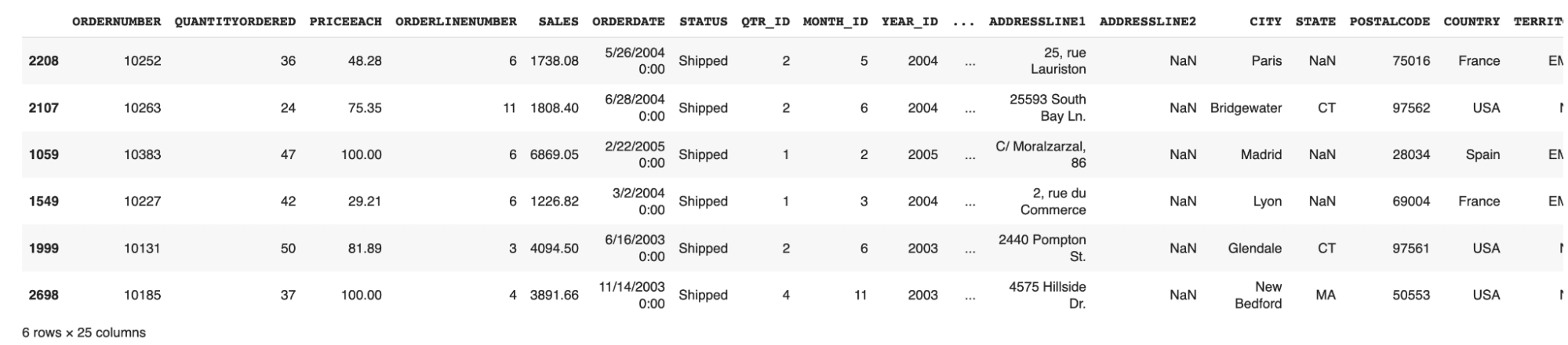
-
df.shape: Muestra las filas y columnas (dimensiones) de los datos de muestra.
(2823, 25)
Significa que nuestro conjunto de datos tiene 2823 filas, cada una de las cuales contiene 25 columnas.
2. Estadística
Esta sección contiene las funciones que le ayudan a realizar estadísticas como promedio, mínimo/máximo y cuartiles en sus datos.
-
df.describe(): Obtenga las estadísticas básicas de cada columna de los datos de muestra
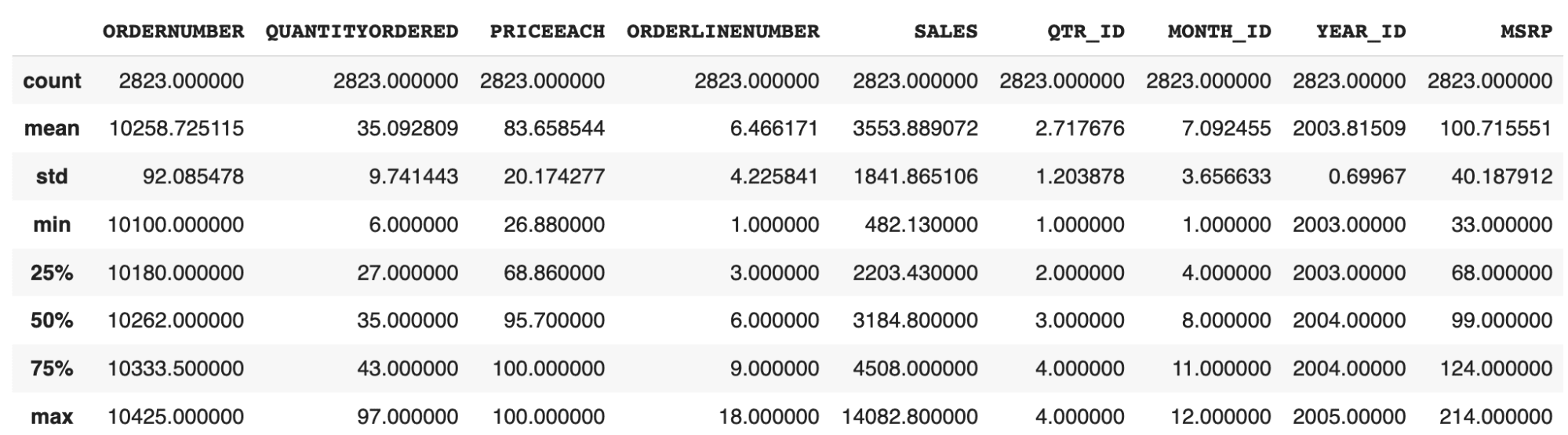
-
df.info(): obtenga información sobre los distintos tipos de datos utilizados y el recuento no nulo de cada columna.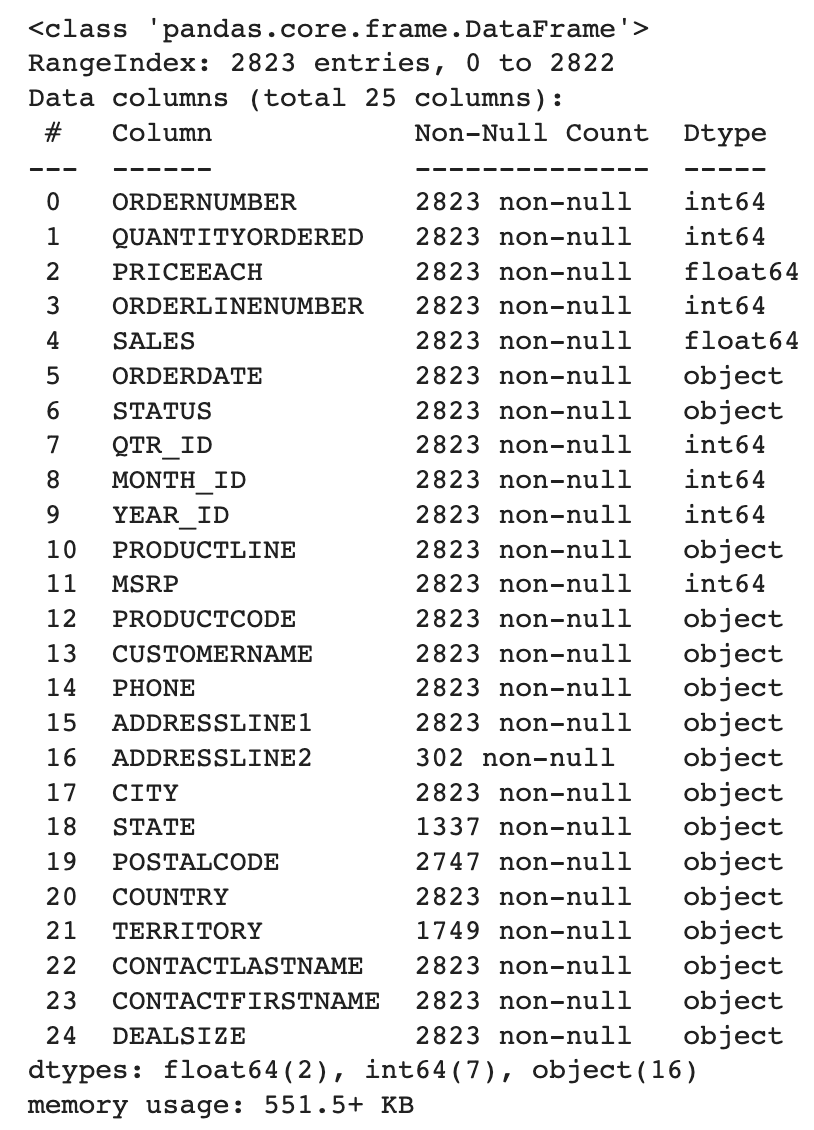
-
df.corr(): Esto puede brindarle la matriz de correlación entre todas las columnas de números enteros en el marco de datos.
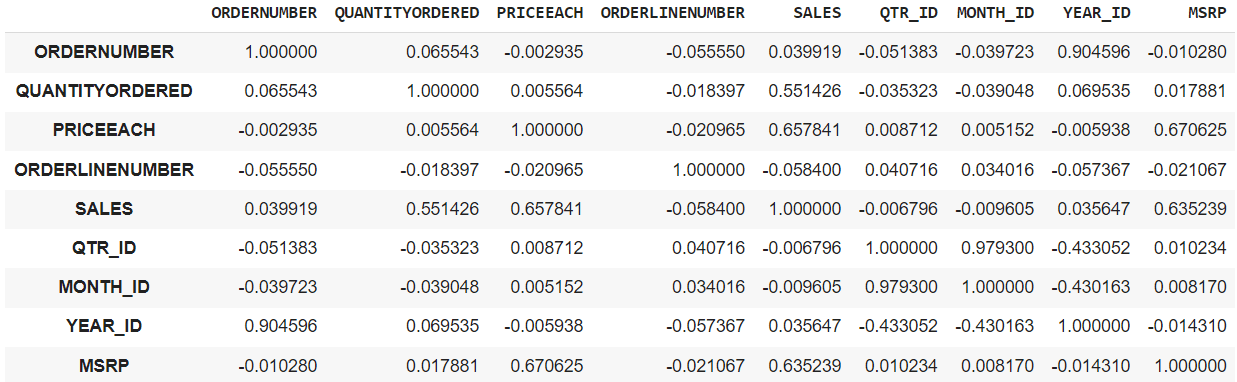
-
df.memory_usage(): Le indicará cuánta memoria consume cada columna.
3. Selección de datos
También puede seleccionar los datos de cualquier fila, columna específica o incluso de varias columnas.
-
df.iloc[row_num]: Seleccionará una fila particular según su índice
Por ex-,
df.iloc[0]
-
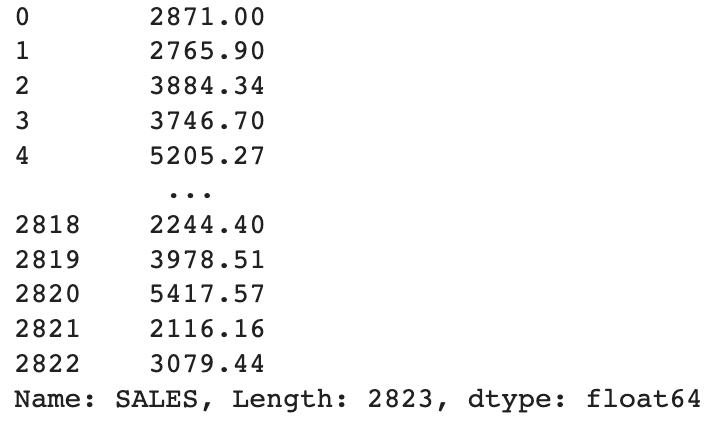
df[col_name]: Seleccionará la columna particular
Por ex-,
df["SALES"]
Salida:
-
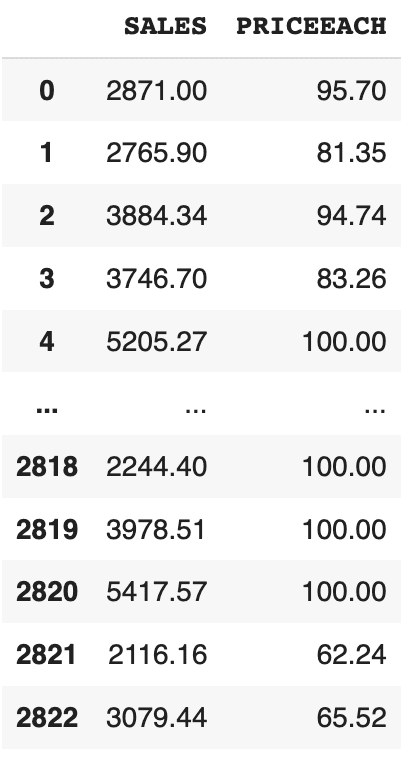
df[[‘col1’, ‘col2’]]: Seleccionará varias columnas dadas
Por ex-,
df[["SALES", "PRICEEACH"]]
Salida:
Estas funciones se utilizan para manejar los datos faltantes. Algunas filas de los datos contienen algunos valores nulos y basura, lo que puede obstaculizar el rendimiento de nuestro modelo entrenado. Por lo tanto, siempre es mejor corregir o eliminar estos valores faltantes.
-
df.isnull(): Esto identificará los valores faltantes en su marco de datos. -
df.dropna(): Esto eliminará las filas que contienen valores faltantes en cualquier columna. -
df.fillna(val): Esto llenará los valores faltantes convaldado en el argumento. -
df[‘col’].astype(new_data_type): Puede convertir el tipo de datos de las columnas seleccionadas a un tipo de datos diferente.
Por ex-,
df["SALES"].astype(int)
Estamos convirtiendo el tipo de datos de la columna VENTAS de float a int.

Aquí, utilizaremos algunas funciones útiles en el análisis de datos, como agrupar, ordenar y filtrar.
- Funciones de agregación:
Puede agrupar una columna por su nombre y luego aplicar algunas funciones de agregación como suma, mínimo/máximo, media, etc.
df.groupby("col_name_1").agg({"col_name_2": "sum"})
Por ex-,
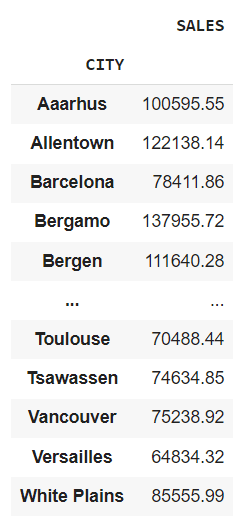
df.groupby("CITY").agg({"SALES": "sum"})
Te dará las ventas totales de cada ciudad.
Si desea aplicar varias agregaciones a la vez, puede escribirlas así.
Por ex-,
aggregation = df.agg({"SALES": "sum", "QUANTITYORDERED": "mean"})
Salida:
SALES 1.003263e+07 QUANTITYORDERED 3.509281e+01 dtype: float64
- Filtrado de datos:
Podemos filtrar los datos en filas según un valor o condición específica.
Por ex-,
df[df["SALES"] > 5000]
Muestra las filas donde el valor de las ventas es mayor a 5000
También puede filtrar el marco de datos usando el query() función. También generará un resultado similar al anterior.
Por ex,
df.query("SALES" > 5000)
- Clasificación de datos:
Puede ordenar los datos según una columna específica, ya sea en orden ascendente o descendente.
Por ex-,
df.sort_values("SALES", ascending=False) # Sorts the data in descending order
- Tablas dinamicas:
Podemos crear tablas dinámicas que resuma los datos utilizando columnas específicas. Esto es muy útil para analizar los datos cuando solo desea considerar el efecto de columnas particulares.
Por ex-,
pd.pivot_table(df, values="SALES", index="CITY", columns="YEAR_ID", aggfunc="sum")
Déjame explicarte esto.
-
values: Contiene la columna para la que desea completar las celdas de la tabla. -
index: La columna utilizada en ella se convertirá en el índice de fila de la tabla dinámica, y cada categoría única de esta columna se convertirá en una fila de la tabla dinámica. -
columns: Contiene los encabezados de la tabla dinámica y cada elemento único se convertirá en la columna de la tabla dinámica. -
aggfunc: Esta es la misma función de agregación que discutimos anteriormente.
Salida:
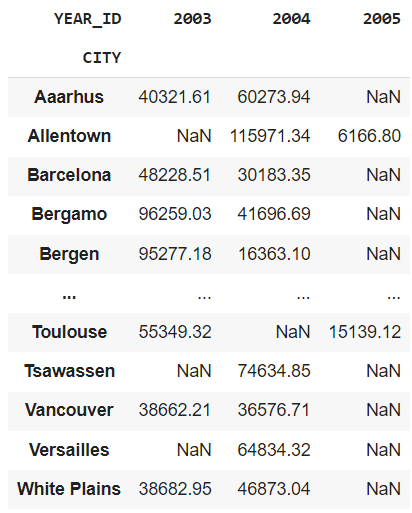
Este resultado muestra un gráfico que muestra las ventas totales en una ciudad en particular durante un año específico.
6. Combinando marcos de datos
Podemos combinar y fusionar varios marcos de datos ya sea horizontal o verticalmente. Concatenará dos marcos de datos y devolverá un único marco de datos combinado.
Por ex-,
combined_df = pd.concat([df1, df2])
Puede fusionar dos marcos de datos en función de una columna común. Es útil cuando desea combinar dos marcos de datos que comparten un identificador común.
Por ex,
merged_df = pd.merge(df1, df2, on="common_col")7. Aplicar funciones personalizadas
Puede aplicar funciones personalizadas según sus necesidades, ya sea en una fila o en una columna.
Por ex-,
def cus_fun(x): return x * 3 df["Sales_Tripled"] = df["SALES"].apply(cus_fun, axis=0)
Hemos escrito una función personalizada que triplicará el valor de ventas de cada fila. axis=0 significa que queremos aplicar la función personalizada en una columna, y axis=1 implica que queremos aplicar la función en una fila.
En el método anterior, debe escribir una función separada y luego llamarla desde el método apply(). La función Lambda le ayuda a utilizar la función personalizada dentro del propio método apply(). Veamos cómo podemos hacer eso.
df["Sales_Tripled"] = df["SALES"].apply(lambda x: x * 3)
Aplicar mapa:
También podemos aplicar una función personalizada a cada elemento del marco de datos en una sola línea de código. Pero un punto a recordar es que es aplicable a todos los elementos del marco de datos.
Por ex-,
df = df.applymap(lambda x: str(x))
Convertirá el tipo de datos en una cadena de todos los elementos del marco de datos.
8. Análisis de series temporales
En matemáticas, el análisis de series de tiempo significa analizar los datos recopilados durante un intervalo de tiempo específico, y los pandas tienen funciones para realizar este tipo de análisis.
Conversión al modelo de objetos DateTime:
Podemos convertir la columna de fecha a un formato de fecha y hora para facilitar la manipulación de datos.
Por ex-,
df["ORDERDATE"] = pd.to_datetime(df["ORDERDATE"])
Salida:
Calcular el promedio móvil:
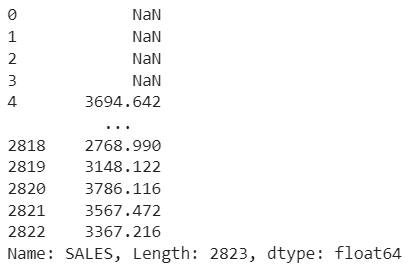
Con este método, podemos crear una ventana móvil para ver los datos. Podemos especificar una ventana móvil de cualquier tamaño. Si el tamaño de la ventana es 5, significa una ventana de datos de 5 días en ese momento. Puede ayudarle a eliminar fluctuaciones en sus datos y a identificar patrones a lo largo del tiempo.
Por ex-
rolling_avg = df["SALES"].rolling(window=5).mean()
Salida:
9. Tabulación cruzada
Podemos realizar tabulaciones cruzadas entre dos columnas de una tabla. Generalmente es una tabla de frecuencia que muestra la frecuencia de aparición de varias categorías. Puede ayudarle a comprender la distribución de categorías en diferentes regiones.
Por ex-,
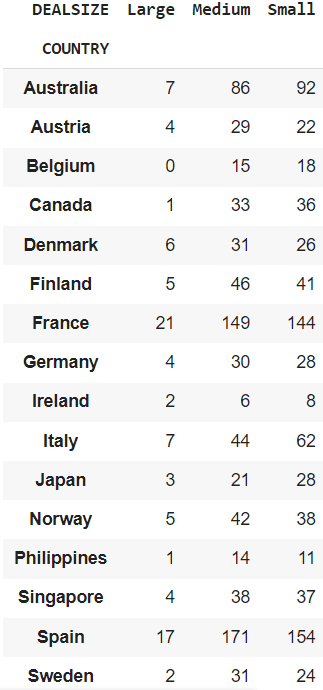
Obtener una tabulación cruzada entre los COUNTRY y DEALSIZE.
cross_tab = pd.crosstab(df["COUNTRY"], df["DEALSIZE"])
Puede mostrarle el tamaño del pedido ("DEALSIZE") ordenado por diferentes países.
10. Manejo de valores atípicos
Los valores atípicos en los datos significan que un punto particular va mucho más allá del rango promedio. Entendámoslo a través de un ejemplo. Supongamos que tiene 5 puntos, digamos 3, 5, 6, 46, 8. Entonces podemos decir claramente que el número 46 es un valor atípico porque está muy por encima del promedio del resto de puntos. Estos valores atípicos pueden dar lugar a estadísticas erróneas y deberían eliminarse del conjunto de datos.
Aquí los pandas acuden al rescate para encontrar estos posibles valores atípicos. Podemos utilizar un método llamado Rango intercuartil (IQR), que es un método común para encontrar y manejar estos valores atípicos. También puedes leer sobre este método si quieres información al respecto. Puedes leer más sobre ellos. esta página.
Veamos cómo podemos hacer eso usando pandas.
Q1 = df["SALES"].quantile(0.25)
Q3 = df["SALES"].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR outliers = df[(df["SALES"] < lower_bound) | (df["SALES"] > upper_bound)]
Q1 es el primer cuartil que representa el percentil 25 de los datos y Q3 es el tercer cuartil que representa el percentil 75 de los datos.
lower_bound La variable almacena el límite inferior que se utiliza para encontrar posibles valores atípicos. Su valor se fija en 1.5 veces el IQR por debajo del Q1. Similarmente, upper_bound calcula el límite superior, 1.5 veces el IQR por encima del Q3.
Después de lo cual, filtra los valores atípicos que son menores que el límite inferior o mayores que el límite superior.
La biblioteca Python pandas nos permite realizar manipulaciones y análisis de datos avanzados. Éstos son sólo algunos de ellos. Puedes encontrar más herramientas en así documentación de pandas. Una cosa importante que debe recordar es que la selección de técnicas puede ser específica y se adapte a sus necesidades y al conjunto de datos que esté utilizando.
Garg ario es un B.Tech. Estudiante de Ingeniería Eléctrica, actualmente en el último año de la carrera. Su interés radica en el campo del Desarrollo Web y el Aprendizaje Automático. Ha perseguido este interés y estoy ansioso por trabajar más en estas direcciones.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/10-essential-pandas-functions-every-data-scientist-should-know?utm_source=rss&utm_medium=rss&utm_campaign=10-essential-pandas-functions-every-data-scientist-should-know

