Imagen del autor
El Análisis de Datos Exploratorios (o EDA) es una fase central dentro del Proceso de Análisis de Datos, enfatizando una investigación exhaustiva de los detalles y características internos de un conjunto de datos.
Su objetivo principal es descubrir patrones subyacentes, comprender la estructura del conjunto de datos e identificar posibles anomalías o relaciones entre variables.
Al realizar EDA, los profesionales de datos verifican la calidad de los datos. Por lo tanto, garantiza que los análisis posteriores se basen en información precisa y reveladora, reduciendo así la probabilidad de errores en etapas posteriores.
Así que intentemos entender juntos cuáles son los pasos básicos para realizar una buena EDA para nuestro próximo proyecto de Ciencia de Datos.
Estoy bastante seguro de que ya has escuchado la frase:
Basura dentro basura fuera
La calidad de los datos de entrada es siempre el factor más importante para cualquier proyecto de datos exitoso.
Desafortunadamente, la mayoría de los datos al principio son sucios. A través del proceso de Análisis Exploratorio de Datos, un conjunto de datos que es casi utilizable se puede transformar en uno que sea completamente utilizable.
Es importante aclarar que no es una solución mágica para purificar ningún conjunto de datos. No obstante, numerosas estrategias de EDA son eficaces para abordar varios problemas típicos que se encuentran en los conjuntos de datos.
Entonces… aprendamos los pasos más básicos según Ayodele Oluleye en su libro Exploratory Data Analysis with Python Cookbook.
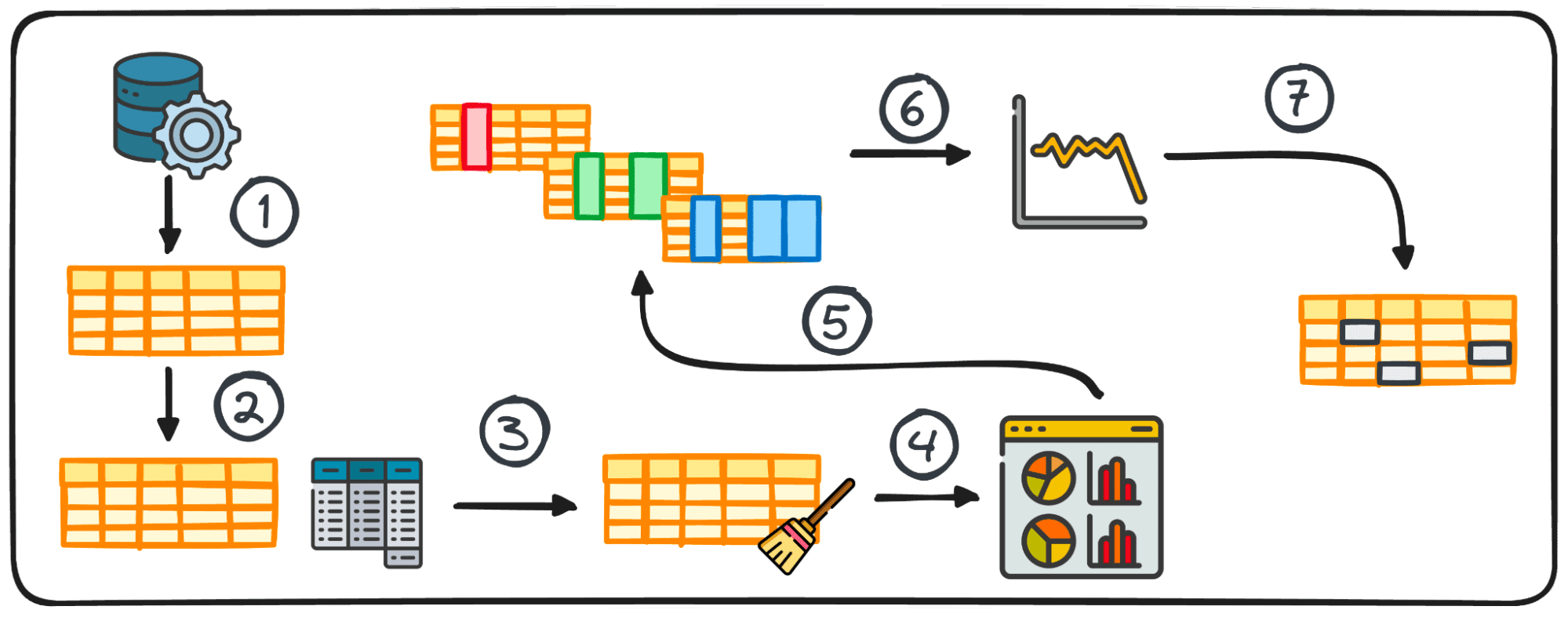
Paso 1: Recopilación de datos
El paso inicial en cualquier proyecto de datos es tener los datos en sí. Este primer paso es donde se recopilan datos de diversas fuentes para su posterior análisis.
2. Resumen de estadísticas
En el análisis de datos, el manejo de datos tabulares es bastante común. Durante el análisis de dichos datos, a menudo es necesario obtener información rápida sobre los patrones y la distribución de los datos.
Estos conocimientos iniciales sirven como base para una mayor exploración y análisis en profundidad y se conocen como estadísticas resumidas.
Ofrecen una descripción general concisa de la distribución y los patrones del conjunto de datos, resumidos a través de métricas como media, mediana, moda, varianza, desviación estándar, rango, percentiles y cuartiles.
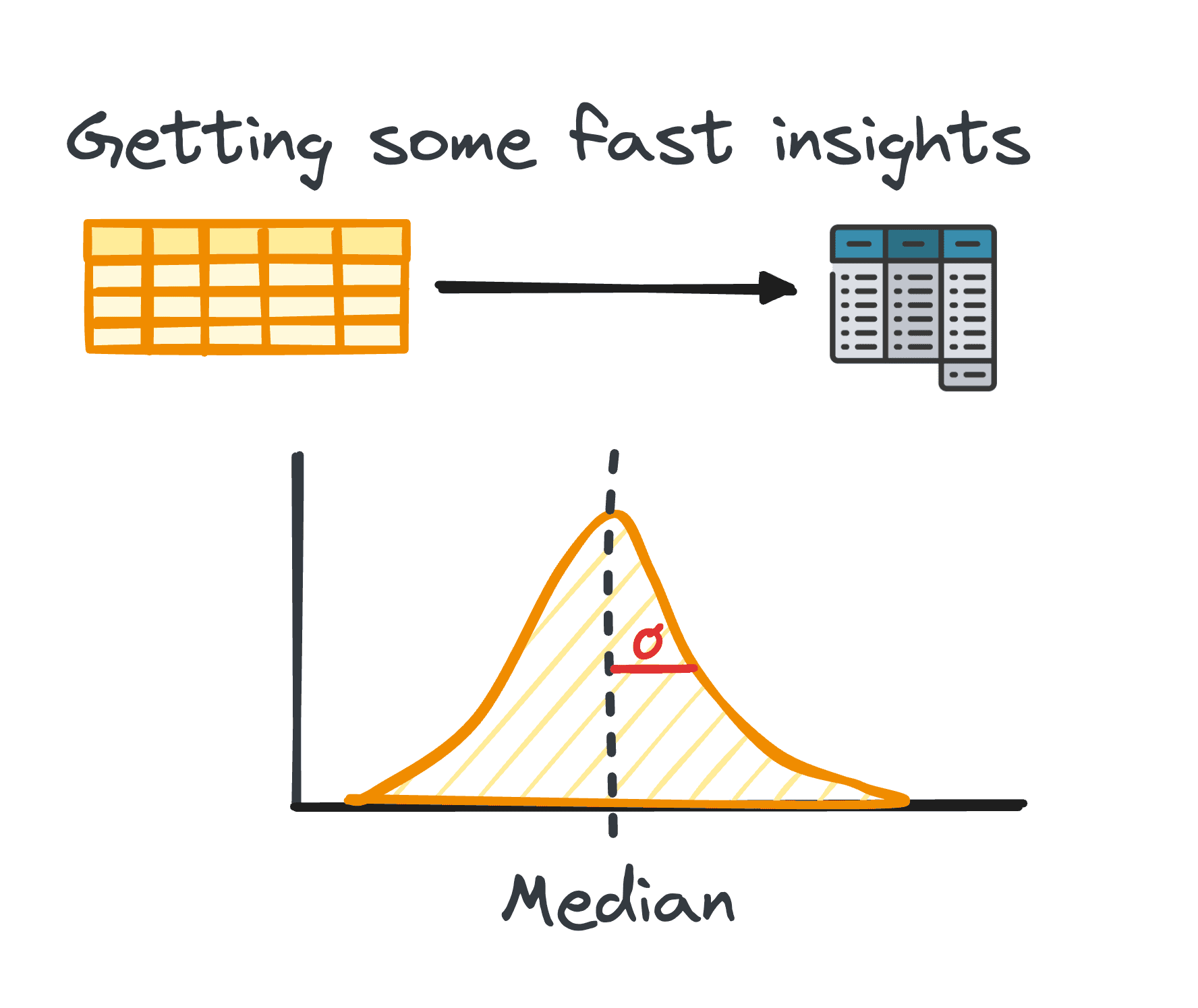
Imagen del autor
3. Preparación de datos para EDA
Antes de comenzar nuestra exploración, normalmente es necesario preparar los datos para un análisis más detallado. La preparación de datos implica transformar, agregar o limpiar datos utilizando la biblioteca pandas de Python para satisfacer las necesidades de su análisis.
Este paso se adapta a la estructura de los datos y puede incluir agrupar, agregar, fusionar, ordenar, categorizar y tratar duplicados.
En Python, la biblioteca pandas facilita la realización de esta tarea a través de sus diversos módulos.
El proceso de preparación de datos tabulares no sigue un método universal; en cambio, está determinado por las características específicas de nuestros datos, incluidas sus filas, columnas, tipos de datos y los valores que contienen.
4. Visualización de datos
La visualización es un componente central de EDA, lo que hace que las relaciones y tendencias complejas dentro del conjunto de datos sean fácilmente comprensibles.
Usar los gráficos correctos puede ayudarnos a identificar tendencias dentro de un gran conjunto de datos y encontrar patrones ocultos o valores atípicos. Python ofrece diferentes bibliotecas para la visualización de datos, incluidas Matplotlib o Seaborn entre otras.
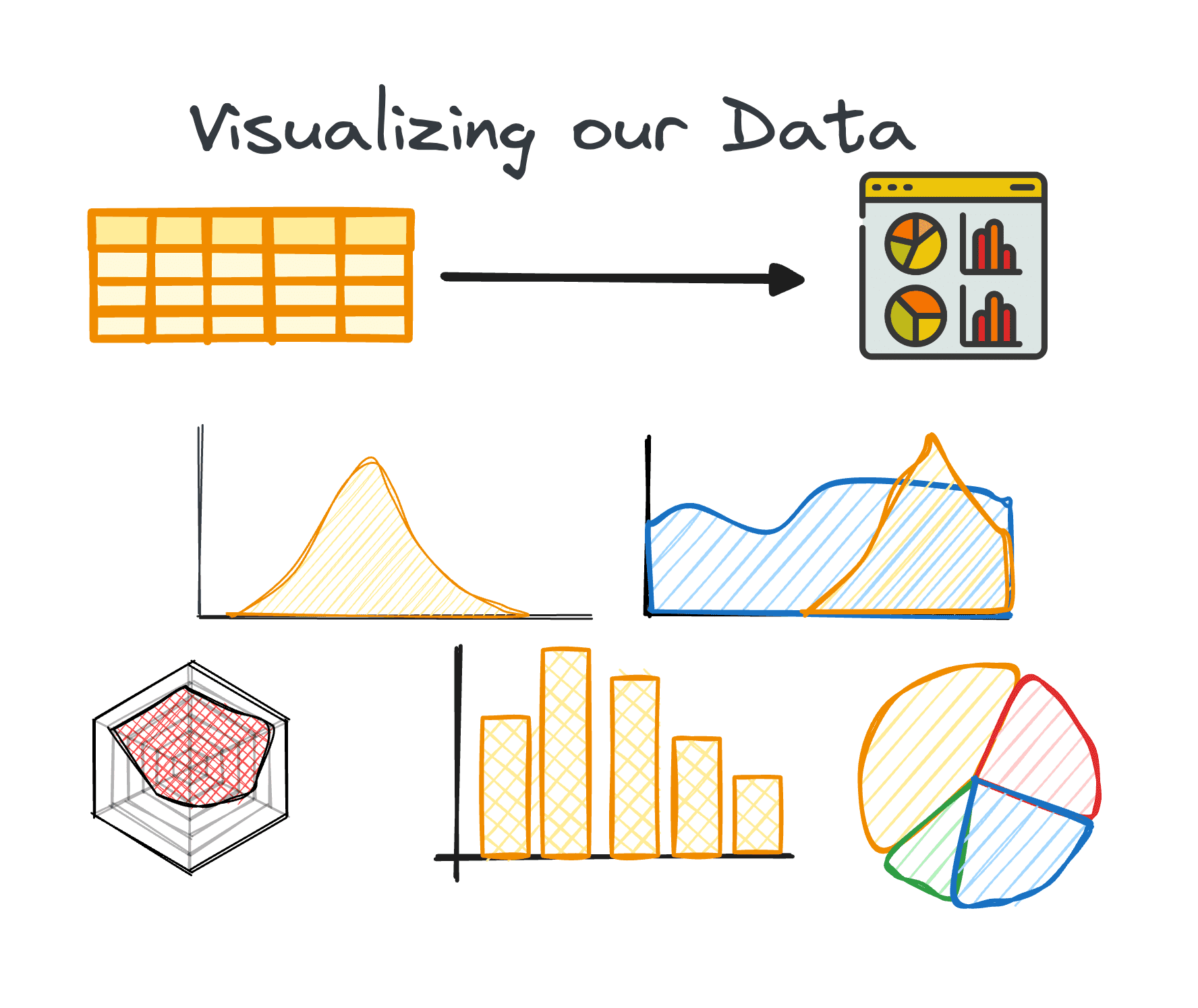
Imagen del autor
5. Realización de análisis de variables:
El análisis de variables puede ser univariado, bivariado o multivariado. Cada uno de ellos proporciona información sobre la distribución y las correlaciones entre las variables del conjunto de datos. Las técnicas varían dependiendo del número de variables analizadas:
Univariante
El objetivo principal del análisis univariado es examinar cada variable dentro de nuestro conjunto de datos por sí sola. Durante este análisis, podemos descubrir información como la mediana, la moda, el máximo, el rango y los valores atípicos.
Este tipo de análisis es aplicable tanto a variables categóricas como numéricas.
Bivariable
El análisis bivariado tiene como objetivo revelar información entre dos variables elegidas y se centra en comprender la distribución y la relación entre estas dos variables.
Como analizamos dos variables al mismo tiempo, este tipo de análisis puede resultar más complicado. Puede abarcar tres pares diferentes de variables: numérica-numérica, numérica-categórica y categórica-categórica.
Multivariable
Un desafío frecuente con grandes conjuntos de datos es el análisis simultáneo de múltiples variables. Aunque los métodos de análisis univariados y bivariados ofrecen información valiosa, normalmente esto no es suficiente para analizar conjuntos de datos que contienen múltiples variables (normalmente más de cinco).
Este problema de la gestión de datos de alta dimensión, habitualmente denominado la maldición de la dimensionalidad, está bien documentado. Tener una gran cantidad de variables puede resultar ventajoso ya que permite extraer más conocimientos. Al mismo tiempo, esta ventaja puede estar en nuestra contra debido al número limitado de técnicas disponibles para analizar o visualizar múltiples variables al mismo tiempo.
6. Análisis de datos de series temporales
Este paso se centra en el examen de los puntos de datos recopilados durante intervalos de tiempo regulares. Los datos de series de tiempo se aplican a datos que cambian con el tiempo. Básicamente, esto significa que nuestro conjunto de datos se compone de un grupo de puntos de datos que se registran en intervalos de tiempo regulares.
Cuando analizamos datos de series temporales, normalmente podemos descubrir patrones o tendencias que se repiten en el tiempo y presentan una estacionalidad temporal. Los componentes clave de los datos de series temporales incluyen tendencias, variaciones estacionales, variaciones cíclicas y variaciones irregulares o ruido.
7. Manejo de valores atípicos y valores perdidos
Los valores atípicos y faltantes pueden distorsionar los resultados del análisis si no se abordan adecuadamente. Por eso siempre debemos considerar una sola fase para abordarlos.
Identificar, eliminar o reemplazar estos puntos de datos es crucial para mantener la integridad del análisis del conjunto de datos. Por ello, es muy importante abordarlos antes de empezar a analizar nuestros datos.
- Los valores atípicos son puntos de datos que presentan una desviación significativa del resto. Suelen presentar valores inusualmente altos o bajos.
- Los valores faltantes son la ausencia de puntos de datos correspondientes a una variable u observación específica.
Un paso inicial fundamental para abordar los valores faltantes y los valores atípicos es comprender por qué están presentes en el conjunto de datos. Esta comprensión suele guiar la selección del método más adecuado para abordarlos. Los factores adicionales a considerar son las características de los datos y el análisis específico que se realizará.
EDA no solo mejora la claridad del conjunto de datos, sino que también permite a los profesionales de datos navegar la maldición de la dimensionalidad al proporcionar estrategias para gestionar conjuntos de datos con numerosas variables.
A través de estos meticulosos pasos, EDA con Python equipa a los analistas con las herramientas necesarias para extraer información significativa de los datos, sentando una base sólida para todos los esfuerzos posteriores de análisis de datos.
Josep Ferrer es un ingeniero analítico de Barcelona. Se graduó en ingeniería física y actualmente trabaja en el campo de la Ciencia de Datos aplicada a la movilidad humana. Es un creador de contenido a tiempo parcial centrado en la ciencia y la tecnología de datos. Puedes contactarlo en Etiqueta LinkedIn, Twitter or Medio.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/7-steps-to-mastering-exploratory-data-analysis?utm_source=rss&utm_medium=rss&utm_campaign=7-steps-to-mastering-exploratory-data-analysis

