En esta publicación, analizamos cómo United Airlines, en colaboración con el Laboratorio de soluciones de aprendizaje automático de Amazon, cree un marco de aprendizaje activo en AWS para automatizar el procesamiento de documentos de pasajeros.
“Para ofrecer la mejor experiencia de vuelo a nuestros pasajeros y hacer que nuestro proceso comercial interno sea lo más eficiente posible, hemos desarrollado un proceso automatizado de documentos basado en aprendizaje automático en AWS. Para impulsar estas aplicaciones, así como aquellas que utilizan otras modalidades de datos como la visión por computadora, necesitamos un flujo de trabajo sólido y eficiente para anotar datos rápidamente, entrenar y evaluar modelos e iterar rápidamente. Durante un par de meses, United se asoció con Amazon Machine Learning Solutions Labs para diseñar y desarrollar un flujo de trabajo de aprendizaje activo reutilizable e independiente de los casos de uso utilizando AWS CDK. Este flujo de trabajo será fundamental para nuestras aplicaciones de aprendizaje automático basadas en datos no estructurados, ya que nos permitirá minimizar el esfuerzo de etiquetado humano, ofrecer un rendimiento sólido del modelo rápidamente y adaptarnos a la deriva de datos”.
– Jon Nelson, director sénior de ciencia de datos y aprendizaje automático de United Airlines.
Problema
El equipo de Tecnología Digital de United está formado por personas globalmente diversas que trabajan juntas con tecnología de vanguardia para impulsar los resultados comerciales y mantener altos los niveles de satisfacción del cliente. Querían aprovechar las técnicas de aprendizaje automático (ML), como la visión por computadora (CV) y el procesamiento del lenguaje natural (NLP), para automatizar los procesos de procesamiento de documentos. Como parte de esta estrategia, desarrollaron un modelo interno de análisis de pasaportes para verificar las identificaciones de los pasajeros. El proceso se basa en anotaciones manuales para entrenar modelos de ML, que son muy costosas.
United quería crear un marco de aprendizaje automático flexible, resistente y rentable para automatizar la verificación de la información de los pasaportes, validar las identidades de los pasajeros y detectar posibles documentos fraudulentos. Contrataron al ML Solutions Lab para ayudar a lograr este objetivo, lo que permite a United continuar brindando un servicio de clase mundial frente al futuro crecimiento de pasajeros.
Resumen de la solución
Nuestro equipo conjunto diseñó y desarrolló un marco de aprendizaje activo impulsado por Kit de desarrollo en la nube de AWS (AWS CDK), que configura y aprovisiona mediante programación todos los servicios de AWS necesarios. El marco utiliza Amazon SageMaker para procesar datos sin etiquetar, crea etiquetas suaves, inicia trabajos de etiquetado manual con Verdad fundamental de Amazon SageMakery entrena un modelo de ML arbitrario con el conjunto de datos resultante. Nosotros usamos Amazon Textil para automatizar la extracción de información de campos de documentos específicos, como nombre y número de pasaporte. En un nivel alto, el enfoque se puede describir con el siguiente diagrama.
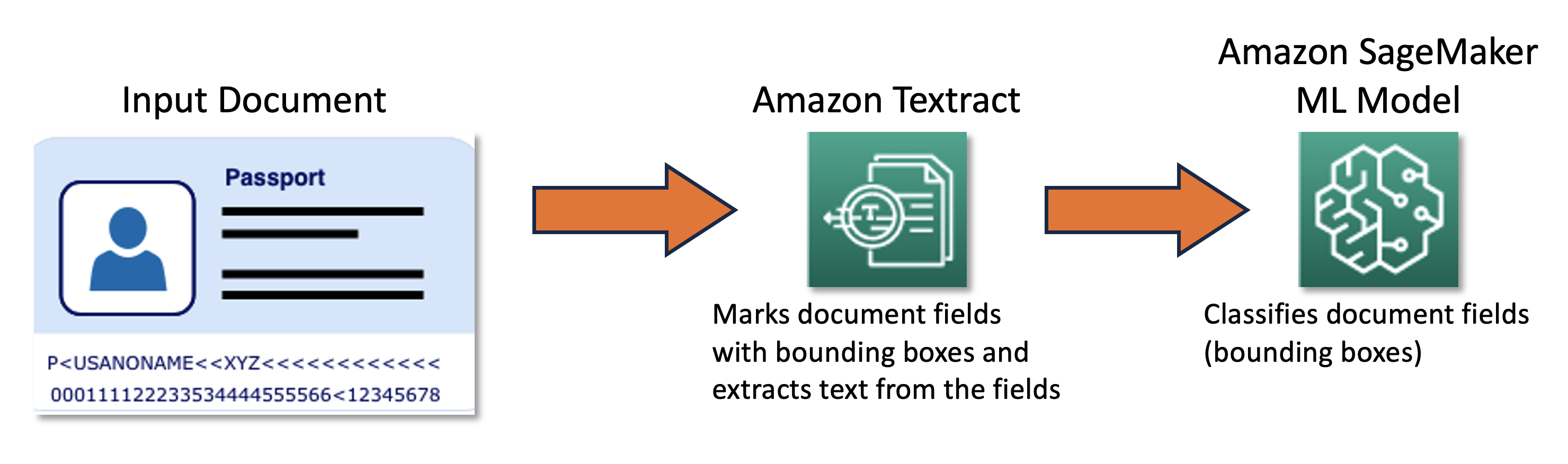
Datos
El conjunto de datos principal para este problema se compone de decenas de miles de imágenes de pasaportes de la página principal de las que se debe extraer información personal (nombre, fecha de nacimiento, número de pasaporte, etc.). El tamaño, el diseño y la estructura de la imagen varían según el país emisor del documento. Normalizamos estas imágenes en un conjunto de miniaturas uniformes, que constituyen la entrada funcional para el proceso de aprendizaje activo (etiquetado automático e inferencia).
El segundo conjunto de datos contiene archivos de manifiesto con formato de línea JSON que relacionan imágenes de pasaporte sin formato, imágenes en miniatura e información de etiquetas, como etiquetas suaves y posiciones de cuadros delimitadores. Los archivos de manifiesto sirven como un conjunto de metadatos que almacena los resultados de varios servicios de AWS en un formato unificado y desacoplan el proceso de aprendizaje activo de los servicios posteriores utilizados por United. El siguiente diagrama ilustra esta arquitectura.
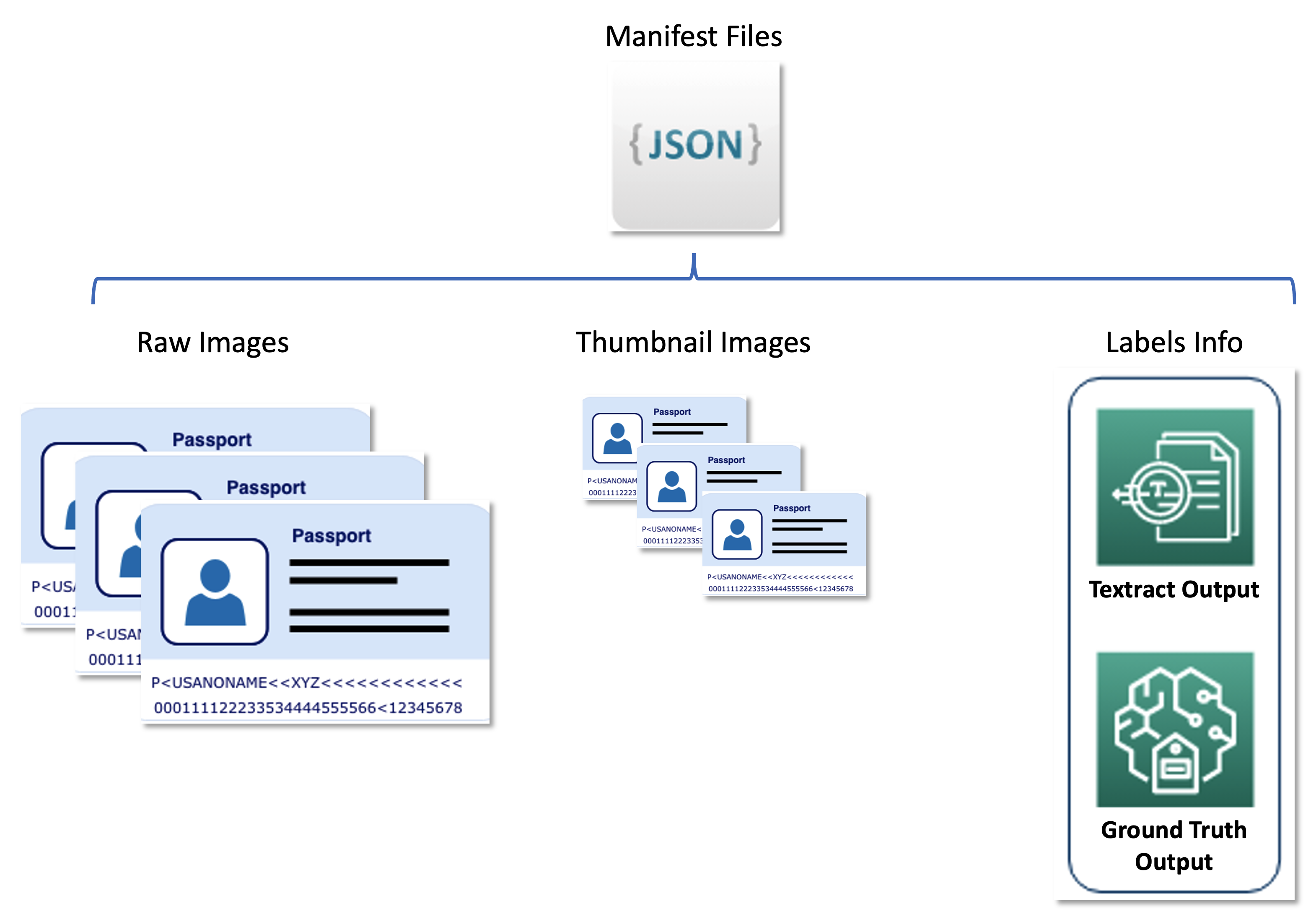
El siguiente código es un archivo de manifiesto de ejemplo:
Componentes de la solución
La solución incluye dos componentes principales:
- Un marco de ML, que se encarga de entrenar el modelo.
- Un proceso de etiquetado automático, que es responsable de mejorar la precisión del modelo entrenado de manera rentable.
El marco de ML es responsable de entrenar el modelo de ML e implementarlo como un punto final de SageMaker. El proceso de etiquetado automático se centra en la automatización de los trabajos de SageMaker Ground Truth y en el muestreo de imágenes para etiquetar esos trabajos.
Los dos componentes están desacoplados entre sí y solo interactúan a través del conjunto de imágenes etiquetadas producidas por el proceso de etiquetado automático. Es decir, la canalización de etiquetado crea etiquetas que luego utiliza el marco de ML para entrenar el modelo de ML.
Marco de aprendizaje automático
El equipo de ML Solutions Lab creó el marco de ML utilizando la implementación Hugging Face del modelo LayoutLMV2 de última generación (LayoutLMv2: capacitación previa multimodal para una comprensión de documentos visualmente rica, Yang Xu, et al.). La capacitación se basó en los resultados de Amazon Textract, que sirvió como preprocesador y produjo cuadros delimitadores alrededor del texto de interés. El marco utiliza capacitación distribuida y se ejecuta en un contenedor Docker personalizado basado en la imagen Hugging Face prediseñada de SageMaker con dependencias adicionales (dependencias que faltan en la imagen Docker prediseñada de SageMaker pero que son necesarias para Hugging Face LayoutLMv2).
El modelo ML fue entrenado para clasificar campos de documentos en las siguientes 11 clases:
El proceso de formación se puede resumir en el siguiente diagrama.
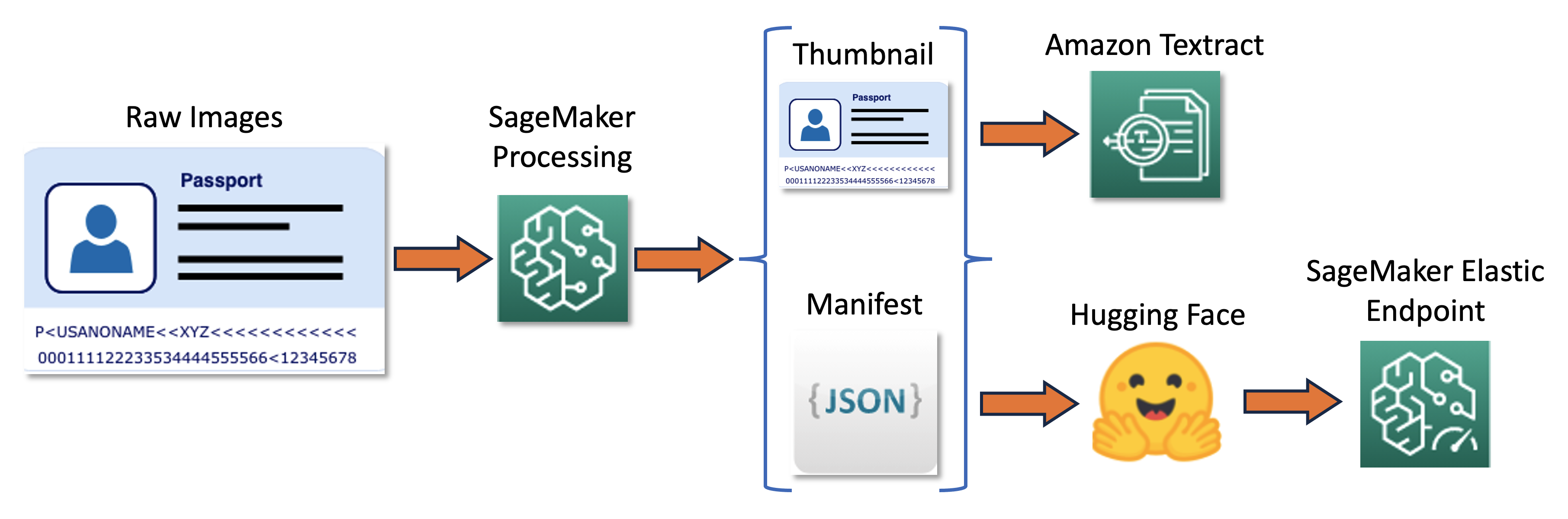
Primero, cambiamos el tamaño y normalizamos un lote de imágenes sin procesar en miniaturas. Al mismo tiempo, se crea un archivo de manifiesto de línea JSON con una línea por imagen con información sobre las imágenes sin formato y en miniatura del lote. A continuación, utilizamos Amazon Textract para extraer cuadros delimitadores de texto en las imágenes en miniatura. Toda la información producida por Amazon Textract se registra en el mismo archivo de manifiesto. Finalmente, utilizamos las imágenes en miniatura y los datos del manifiesto para entrenar un modelo, que luego se implementa como un punto final de SageMaker.
Tubería de etiquetado automático
Desarrollamos un pipeline de autoetiquetado diseñado para realizar las siguientes funciones:
- Ejecute inferencias por lotes periódicas en un conjunto de datos sin etiquetar.
- Filtre los resultados según una estrategia de muestreo de incertidumbre específica.
- Active un trabajo de SageMaker Ground Truth para etiquetar las imágenes de muestra utilizando mano de obra humana.
- Agregue imágenes recién etiquetadas al conjunto de datos de entrenamiento para un posterior refinamiento del modelo.
La estrategia de muestreo de incertidumbre reduce la cantidad de imágenes enviadas al trabajo de etiquetado humano al seleccionar imágenes que probablemente contribuirían más a mejorar la precisión del modelo. Debido a que el etiquetado humano es una tarea costosa, dicho muestreo es una técnica importante de reducción de costos. Admitimos cuatro estrategias de muestreo, que se pueden seleccionar como un parámetro almacenado en Tienda de parámetros, una capacidad de Gerente de sistemas de AWS:
- Menos confianza
- Confianza en el margen
- Ratio de confianza
- Entropía
Todo el flujo de trabajo de etiquetado automático se implementó con Funciones de paso de AWS, que organiza el trabajo de procesamiento (llamado punto final elástico para la inferencia por lotes), el muestreo de incertidumbre y SageMaker Ground Truth. El siguiente diagrama ilustra el flujo de trabajo de Step Functions.
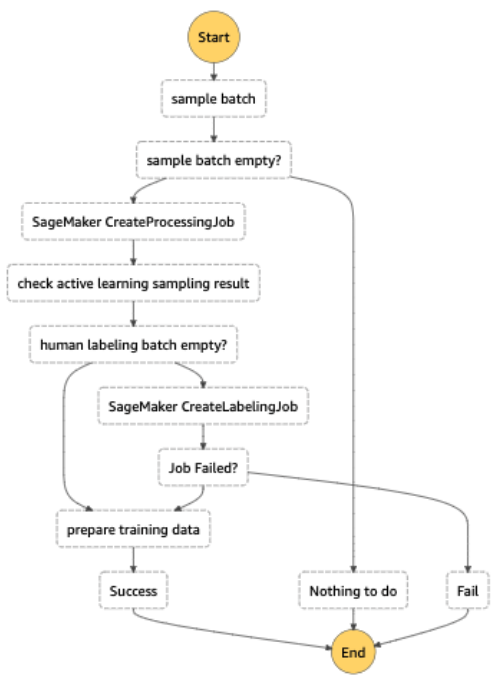
Eficiencia de costo
El principal factor que influye en los costes del etiquetado es la anotación manual. Antes de implementar esta solución, el equipo de United tuvo que utilizar un enfoque basado en reglas, que requería costosas anotaciones manuales de datos y técnicas de OCR de análisis de terceros. Con nuestra solución, United redujo su carga de trabajo de etiquetado manual al etiquetar manualmente solo las imágenes que darían como resultado las mayores mejoras del modelo. Debido a que el marco es independiente del modelo, se puede utilizar en otros escenarios similares, extendiendo su valor más allá de las imágenes de pasaporte a un conjunto mucho más amplio de documentos.
Realizamos un análisis de costos basado en los siguientes supuestos:
- Cada lote contiene 1,000 imágenes.
- La capacitación se realiza utilizando una instancia mlg4dn.16xlarge
- La inferencia se realiza en una instancia mlg4dn.xlarge
- La capacitación se realiza después de cada lote con el 10% de las etiquetas anotadas.
- Cada ronda de entrenamiento da como resultado las siguientes mejoras de precisión:
- 50% después del primer lote
- 25% después del segundo lote
- 10% después del tercer lote
Nuestro análisis muestra que el costo de la capacitación permanece constante y alto sin un aprendizaje activo. La incorporación del aprendizaje activo da como resultado una disminución exponencial de los costos con cada nuevo lote de datos.
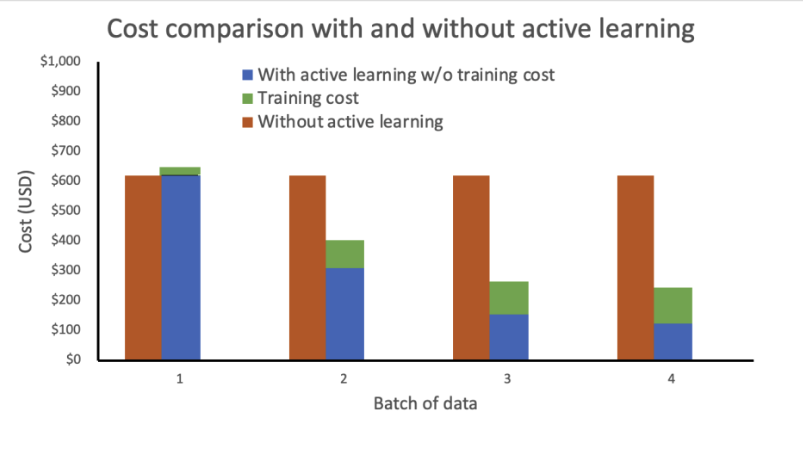
Redujimos aún más los costos al implementar el punto final de inferencia como un punto final elástico agregando una política de escalamiento automático. Los recursos del punto final pueden aumentar o reducirse entre cero y un número máximo configurado de instancias.
Arquitectura de la solución final
Nuestro objetivo era ayudar al equipo de United a cumplir con sus requisitos funcionales mientras creaban una aplicación en la nube escalable y flexible. El equipo de ML Solutions Lab desarrolló la solución completa lista para producción con la ayuda de AWS CDK, automatizando la administración y el aprovisionamiento de todos los recursos y servicios de la nube. La aplicación final en la nube se implementó como una única Formación en la nube de AWS pila con cuatro pilas anidadas, cada una de las cuales representaba un único componente funcional.
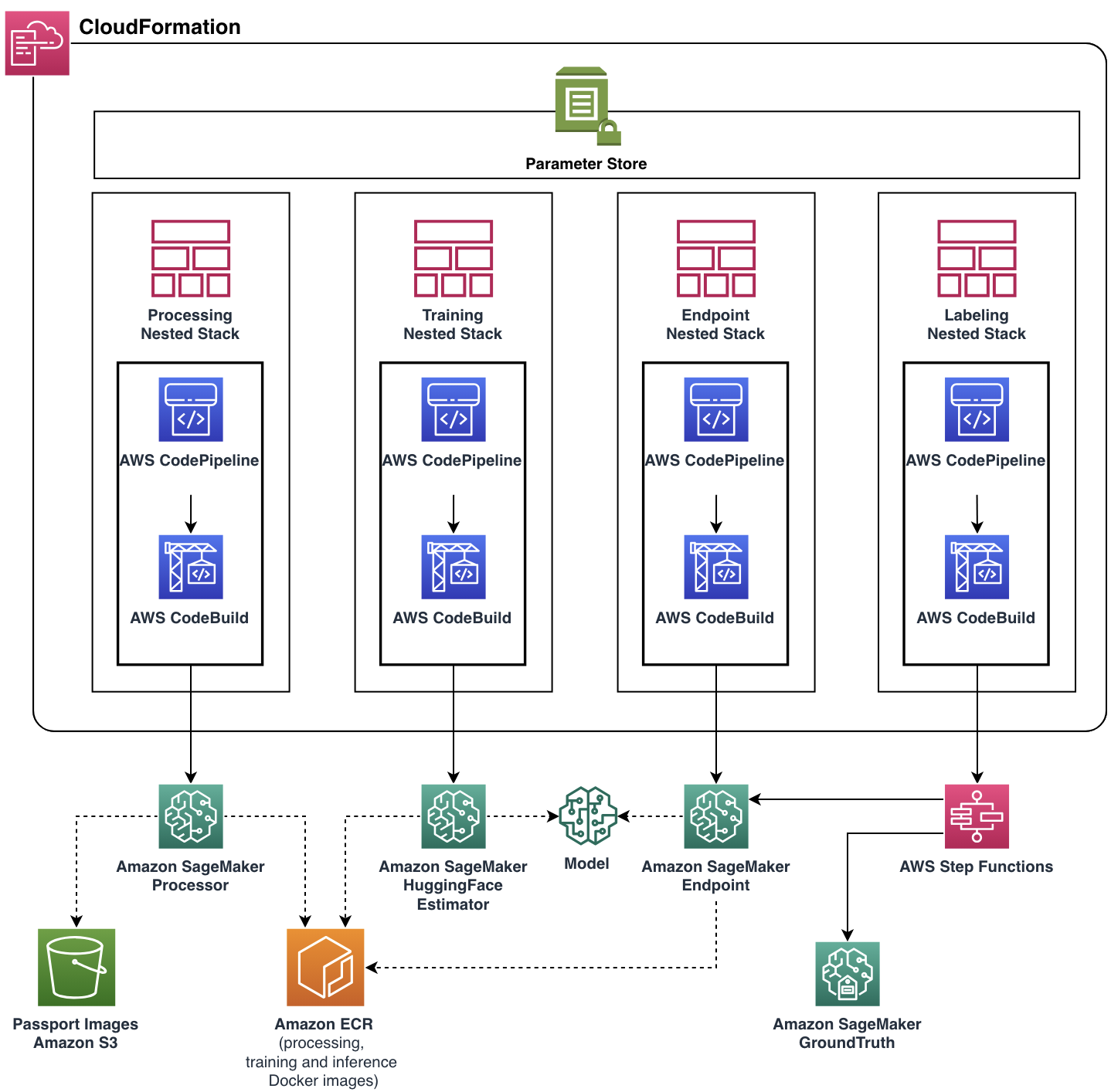
Casi todas las funciones de canalización, incluidas las imágenes de Docker, la política de escalado automático de endpoints y más, se parametrizaron a través de Parameter Store. Con tal flexibilidad, la misma instancia de canalización podría ejecutarse con una amplia gama de configuraciones, agregando la capacidad de experimentar.
Conclusión
En esta publicación, analizamos cómo United Airlines, en colaboración con ML Solutions Lab, creó un marco de aprendizaje activo en AWS para automatizar el procesamiento de documentos de pasajeros. La solución tuvo un gran impacto en dos aspectos importantes de los objetivos de automatización de United:
- Reutilización – Debido al diseño modular y la implementación independiente del modelo, United Airlines puede reutilizar esta solución en casi cualquier otro caso de uso de ML de etiquetado automático.
- Reducción de costos recurrentes – Al combinar de manera inteligente los procesos de etiquetado manual y automático, el equipo de United puede reducir los costos promedio de etiquetado y reemplazar los costosos servicios de etiquetado de terceros.
Si está interesado en implementar una solución similar o desea obtener más información sobre ML Solutions Lab, comuníquese con su administrador de cuentas o visítenos en Laboratorio de soluciones de aprendizaje automático de Amazon.
Acerca de los autores
 Gu Xin es el científico de datos líder: aprendizaje automático en la división de innovación y análisis avanzado de United Airlines. Contribuyó significativamente al diseño de la automatización de la comprensión de documentos asistida por aprendizaje automático y desempeñó un papel clave en la expansión de los flujos de trabajo de aprendizaje activo de anotación de datos en diversas tareas y modelos. Su experiencia radica en elevar la eficacia y eficiencia de la IA, logrando avances notables en el campo de los avances tecnológicos inteligentes en United Airlines.
Gu Xin es el científico de datos líder: aprendizaje automático en la división de innovación y análisis avanzado de United Airlines. Contribuyó significativamente al diseño de la automatización de la comprensión de documentos asistida por aprendizaje automático y desempeñó un papel clave en la expansión de los flujos de trabajo de aprendizaje activo de anotación de datos en diversas tareas y modelos. Su experiencia radica en elevar la eficacia y eficiencia de la IA, logrando avances notables en el campo de los avances tecnológicos inteligentes en United Airlines.
 jon nelson es el Gerente Senior de Ciencia de Datos y Aprendizaje Automático en United Airlines.
jon nelson es el Gerente Senior de Ciencia de Datos y Aprendizaje Automático en United Airlines.
 Alex Goryainov es ingeniero de aprendizaje automático en Amazon AWS. Crea arquitectura e implementa componentes centrales de aprendizaje activo y proceso de etiquetado automático impulsado por AWS CDK. Alex es un experto en MLOps, arquitectura de computación en la nube, análisis de datos estadísticos y procesamiento de datos a gran escala.
Alex Goryainov es ingeniero de aprendizaje automático en Amazon AWS. Crea arquitectura e implementa componentes centrales de aprendizaje activo y proceso de etiquetado automático impulsado por AWS CDK. Alex es un experto en MLOps, arquitectura de computación en la nube, análisis de datos estadísticos y procesamiento de datos a gran escala.
 Vishal Das es científico aplicado en el laboratorio de soluciones de aprendizaje automático de Amazon. Antes de MLSL, Vishal fue arquitecto de soluciones, Energía, AWS. Recibió su doctorado en Geofísica con especialización en Estadística de la Universidad de Stanford. Está comprometido a trabajar con los clientes para ayudarlos a pensar en grande y generar resultados comerciales. Es experto en aprendizaje automático y su aplicación en la resolución de problemas empresariales.
Vishal Das es científico aplicado en el laboratorio de soluciones de aprendizaje automático de Amazon. Antes de MLSL, Vishal fue arquitecto de soluciones, Energía, AWS. Recibió su doctorado en Geofísica con especialización en Estadística de la Universidad de Stanford. Está comprometido a trabajar con los clientes para ayudarlos a pensar en grande y generar resultados comerciales. Es experto en aprendizaje automático y su aplicación en la resolución de problemas empresariales.
 Tianyi Mao es un científico aplicado en AWS con sede en el área de Chicago. Tiene más de cinco años de experiencia en la creación de soluciones de aprendizaje automático y aprendizaje profundo y se centra en la visión por computadora y el aprendizaje por refuerzo con retroalimentación humana. Le gusta trabajar con los clientes para comprender sus desafíos y resolverlos mediante la creación de soluciones innovadoras utilizando los servicios de AWS.
Tianyi Mao es un científico aplicado en AWS con sede en el área de Chicago. Tiene más de cinco años de experiencia en la creación de soluciones de aprendizaje automático y aprendizaje profundo y se centra en la visión por computadora y el aprendizaje por refuerzo con retroalimentación humana. Le gusta trabajar con los clientes para comprender sus desafíos y resolverlos mediante la creación de soluciones innovadoras utilizando los servicios de AWS.
 yunzhi shi es científico aplicado en Amazon ML Solutions Lab, donde trabaja con clientes de diferentes sectores verticales de la industria para ayudarlos a idear, desarrollar e implementar soluciones de IA/ML construidas en los servicios de la nube de AWS para resolver sus desafíos comerciales. Ha trabajado con clientes en los sectores automotriz, geoespacial, transporte y fabricación. Yunzhi obtuvo su doctorado. en Geofísica de la Universidad de Texas en Austin.
yunzhi shi es científico aplicado en Amazon ML Solutions Lab, donde trabaja con clientes de diferentes sectores verticales de la industria para ayudarlos a idear, desarrollar e implementar soluciones de IA/ML construidas en los servicios de la nube de AWS para resolver sus desafíos comerciales. Ha trabajado con clientes en los sectores automotriz, geoespacial, transporte y fabricación. Yunzhi obtuvo su doctorado. en Geofísica de la Universidad de Texas en Austin.
 Diego Socolinsky Es gerente senior de ciencias aplicadas en el Centro de innovación de IA generativa de AWS, donde dirige el equipo de entrega para las regiones del este de EE. UU. y América Latina. Tiene más de veinte años de experiencia en aprendizaje automático y visión por computadora, y tiene un doctorado en matemáticas de la Universidad Johns Hopkins.
Diego Socolinsky Es gerente senior de ciencias aplicadas en el Centro de innovación de IA generativa de AWS, donde dirige el equipo de entrega para las regiones del este de EE. UU. y América Latina. Tiene más de veinte años de experiencia en aprendizaje automático y visión por computadora, y tiene un doctorado en matemáticas de la Universidad Johns Hopkins.
 Xin Chen Actualmente es el Jefe del Laboratorio de Soluciones de Ciencia de las Personas en Amazon People eXperience Technology (PXT, también conocido como HR) Central Science. Dirige un equipo de científicos aplicados para crear soluciones científicas de grado de producción para identificar y lanzar proactivamente mecanismos y mejoras de procesos. Anteriormente, fue jefe de Centro de EE. UU., Región de la Gran China, LATAM y Vertical Automotriz en el Laboratorio de Soluciones de Aprendizaje Automático de AWS. Ayudó a los clientes de AWS a identificar y crear soluciones de aprendizaje automático para abordar las oportunidades de aprendizaje automático con mayor retorno de la inversión de su organización. Xin es profesora adjunta de la Universidad Northwestern y del Instituto de Tecnología de Illinois. Obtuvo su doctorado en Ciencias de la Computación e Ingeniería en la Universidad de Notre Dame.
Xin Chen Actualmente es el Jefe del Laboratorio de Soluciones de Ciencia de las Personas en Amazon People eXperience Technology (PXT, también conocido como HR) Central Science. Dirige un equipo de científicos aplicados para crear soluciones científicas de grado de producción para identificar y lanzar proactivamente mecanismos y mejoras de procesos. Anteriormente, fue jefe de Centro de EE. UU., Región de la Gran China, LATAM y Vertical Automotriz en el Laboratorio de Soluciones de Aprendizaje Automático de AWS. Ayudó a los clientes de AWS a identificar y crear soluciones de aprendizaje automático para abordar las oportunidades de aprendizaje automático con mayor retorno de la inversión de su organización. Xin es profesora adjunta de la Universidad Northwestern y del Instituto de Tecnología de Illinois. Obtuvo su doctorado en Ciencias de la Computación e Ingeniería en la Universidad de Notre Dame.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/how-united-airlines-built-a-cost-efficient-optical-character-recognition-active-learning-pipeline/

