Esta es una publicación de invitado coescrita con Raghu Boppanna de Vanguard.
At Vanguardia, la línea de negocio Enterprise Advice mejora los resultados de los inversores a través del acceso digital a un asesoramiento financiero superior, personalizado y asequible. Lo hicieron posible, en parte, impulsando economías de escala en todo el mundo para inversores con una plataforma técnica altamente resistente y eficiente. Vanguard optó por una arquitectura de múltiples regiones para esta carga de trabajo a fin de ayudar a proteger contra las deficiencias de los servicios regionales. Para fines de alta disponibilidad, es necesario que los datos utilizados por la carga de trabajo estén disponibles no solo en la región principal, sino también en la región secundaria con un retraso de replicación mínimo. En el caso de un deterioro del servicio en la región principal, la solución debería poder conmutar por error a la región secundaria con la menor pérdida de datos posible y la capacidad de reanudar la ingesta de datos.
Vanguard Cloud Technology Office y AWS se asociaron para crear una solución de infraestructura en AWS que cumpliera con sus requisitos de resiliencia. La solución de varias regiones permite un sólido mecanismo de conmutación por error, con capacidad de observación y recuperación integradas. La solución también admite la transmisión de datos desde múltiples fuentes a diferentes flujos de datos de Kinesis. Actualmente, la solución se está implementando en las diferentes líneas de equipos comerciales para mejorar la postura de resiliencia de sus cargas de trabajo.
El caso de uso discutido aquí requiere Change Data Capture (CDC) para transmitir datos desde una fuente de datos remota (mainframe DB2) a Secuencias de datos de Amazon Kinesis, porque la capacidad empresarial depende de estos datos. Kinesis Data Streams es un servicio de transmisión de bajo costo, duradero, de escalabilidad masiva y completamente administrado que puede capturar y transmitir continuamente grandes cantidades de datos de múltiples fuentes y hace que los datos estén disponibles para su consumo en milisegundos. El servicio está diseñado para ser altamente resistente y utiliza múltiples zonas de disponibilidad para procesar y almacenar datos.
La solución discutida en esta publicación explica cómo AWS y Vanguard innovaron para construir una arquitectura resistente para cumplir con sus objetivos de alta disponibilidad.
Resumen de la solución
La solución utiliza AWS Lambda para replicar datos de flujos de datos de Kinesis en la región principal a una región secundaria. En caso de que cualquier deterioro del servicio afecte la canalización de CDC, el proceso de conmutación por error promueve la región secundaria a primaria para los productores y consumidores. Usamos Tablas globales de Amazon DynamoDB para puntos de control de replicación que permite reanudar la transmisión de datos desde el punto de control y también mantiene un indicador de configuración de región principal que evita un ciclo de replicación infinito de los mismos datos de un lado a otro.
La solución también brinda la flexibilidad para que los consumidores de Kinesis Data Streams utilicen la región principal o cualquier región secundaria dentro de la misma cuenta de AWS.
El siguiente diagrama ilustra la arquitectura de referencia.
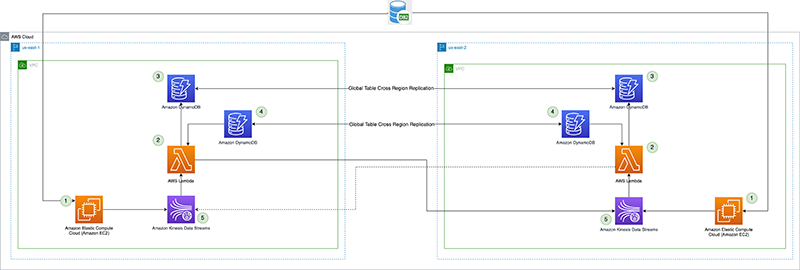
Veamos cada componente en detalle:
- Procesador CDC (productor) – En esta arquitectura de referencia, el productor se implementa en Nube informática elástica de Amazon (Amazon EC2) en las regiones principal y secundaria, y está activo en la región principal y en modo de espera en la región secundaria. Captura datos de CDC de la fuente de datos externa (como una base de datos DB2 como se muestra en la arquitectura anterior) y transmite a Kinesis Data Streams en la región principal. Vanguard usa un 3rd herramienta de fiesta Qlik Replicate como su procesador CDC. Produce una carga útil bien formada que incluye la marca de tiempo de confirmación de DB2 para el flujo de datos de Kinesis, además de los datos de fila reales de la fuente de datos remota. (
example-stream-1en este ejemplo). El siguiente código es una carga útil de muestra que contiene solo la clave principal del registro que cambió y la marca de tiempo de confirmación (para simplificar, el resto de los datos de la fila de la tabla no se muestran a continuación):{ "eventSource": "aws:kinesis", "kinesis": { "ApproximateArrivalTimestamp": "Mon July 18 20:00:00 UTC 2022", "SequenceNumber": "49544985256907370027570885864065577703022652638596431874", "PartitionKey": "12349999", "KinesisSchemaVersion": "1.0", "Data": "eyJLZXkiOiAxMjM0OTk5OSwiQ29tbWl0VGltZXN0YW1wIjogIjIwMjItMDctMThUMjA6MDA6MDAifQ==" }, "eventId": "shardId-000000000000:49629136582982516722891309362785181370337771525377097730", "invokeIdentityArn": "arn:aws:iam::6243876582:role/kds-crr-LambdaRole-1GZWP67437SD", "eventName": "aws:kinesis:record", "eventVersion": "1.0", "eventSourceARN": "arn:aws:kinesis:us-east-1:6243876582:stream/kds-stream-1/consumer/kds-crr:6243876582", "awsRegion": "us-east-1" }El valor decodificado en Base64 de
Dataes como sigue. El registro de Kinesis real contendría todos los datos de la fila de la tabla que cambió, además de la clave principal y la marca de tiempo de confirmación.{"Key": 12349999,"CommitTimestamp": "2022-07-18T20:00:00"}El
CommitTimestampexistentesDataEl campo se utiliza en el punto de control de la replicación y es fundamental para realizar un seguimiento preciso de la cantidad de datos de transmisión que se ha replicado en la región secundaria. El punto de control se puede usar para facilitar una conmutación por error del procesador CDC (productor) y reanudar con precisión la producción de datos desde la marca de tiempo del punto de control de replicación en adelante.La alternativa al uso de una fuente de datos remota
CommitTimestamp(si no está disponible) es usar elApproximateArrivalTimestamp(que es la marca de tiempo cuando el registro se escribe realmente en el flujo de datos). - Función Lambda de replicación entre regiones – La función se implementa en regiones primarias y secundarias. Está configurado con una asignación de fuente de eventos al flujo de datos que contiene datos de CDC. La misma función se puede utilizar para replicar datos de varios flujos. Se invoca con un lote de registros de Kinesis Data Streams y replica el lote en una región de replicación de destino (que se proporciona a través del entorno de configuración de Lambda). Por consideraciones de costos, si los datos de CDC se producen activamente solo en la región principal, la simultaneidad reservada de la función en la región secundaria se puede establecer en cero y modificar durante la conmutación por error regional. La función tiene Gestión de identidades y accesos de AWS (IAM) permisos de rol para hacer lo siguiente:
- Lea y escriba en las tablas globales de DynamoDB utilizadas en esta solución, dentro de la misma cuenta.
- Lea y escriba en Kinesis Data Streams en ambas regiones dentro de la misma cuenta.
- Publicar métricas personalizadas para Reloj en la nube de Amazon en ambas Regiones dentro de la misma cuenta.
- Punto de control de replicación – El punto de control de la replicación usa la tabla global de DynamoDB en las regiones principal y secundaria. Lo utiliza la función Lambda de replicación entre regiones para conservar la marca de tiempo de confirmación del último registro de replicación como el punto de control de replicación para cada transmisión configurada para la replicación. Para esta publicación, creamos y usamos una tabla global llamada
kdsReplicationCheckpoint. - Configuración de la región activa – La región activa utiliza la tabla global de DynamoDB tanto en la región principal como en la secundaria. Utiliza la capacidad de replicación nativa entre regiones de la tabla global para replicar la configuración. Se rellena previamente con datos sobre cuál es la región principal de una secuencia, para evitar que la función Lambda vuelva a replicar a la región principal en la región en espera. Es posible que esta configuración no sea necesaria si la función Lambda en la región en espera tiene una simultaneidad reservada establecida en cero, pero puede servir como control de seguridad para evitar un bucle de replicación infinito de los datos. Para esta publicación, creamos una tabla global llamada
kdsActiveRegionConfigy poner un artículo con los siguientes datos:{ "stream-name": "example-stream-1", "active-region" : "us-east-1" } - Flujos de datos de Kinesis – El flujo en el que el procesador CDC produce los datos. Para esta publicación, usamos una secuencia llamada
example-stream-1en ambas regiones, con la misma configuración de fragmentos y políticas de acceso.
Secuencia de pasos en la replicación entre regiones
Veamos brevemente cómo se ejercita la arquitectura utilizando el siguiente diagrama de secuencia.

La secuencia consta de los siguientes pasos:
- El procesador CDC (en
us-east-1) lee los datos CDC del origen de datos remoto. - El procesador CDC (en
us-east-1) transmite los datos de CDC a Kinesis Data Streams (enus-east-1). - La función Lambda de replicación entre regiones (en us-east-1) consume los datos del flujo de datos (en
us-east-1). Se recomienda el patrón de abanico mejorado para un rendimiento dedicado y aumentado para la replicación entre regiones. - La función replicadora Lambda (en
us-east-1) valida su Región actual con la configuración de Región activa para el flujo que se está consumiendo, con la ayuda delkdsActiveRegionConfigTabla global de DynamoDB El siguiente código de muestra (en Java) puede ayudar a ilustrar la condición que se está evaluando:// Fetch the current AWS Region from the Lambda function’s environment String currentAWSRegion = System.getenv(“AWS_REGION”); // Read the stream name from the first Kinesis Record once for the entire batch being processed. This is done because we are reusing the same Lambda function for replicating multiple streams. String currentStreamNameConsumed = kinesisRecord.getEventSourceARN().split(“:”)[5].split(“/”)[1]; // Build the DynamoDB query condition using the stream name Map<String, Condition> keyConditions = singletonMap(“streamName”, Condition.builder().comparisonOperator(EQ).attributeValueList(AttributeValue.builder().s(currentStreamNameConsumed).build()).build()); // Query the DynamoDB Global Table QueryResponse queryResponse = ddbClient.query(QueryRequest.builder().tableName("kdsActiveRegionConfig").keyConditions(keyConditions).attributesToGet(“ActiveRegion”).build()); - La función evalúa la respuesta de DynamoDB con el siguiente código:
// Evaluate the response if (queryResponse.hasItems()) { AttributeValue activeRegionForStream = queryResponse.items().get(0).get(“ActiveRegion”); return currentAWSRegion.equalsIgnoreCase(activeRegionForStream.s()); } - Dependiendo de la respuesta, la función realiza las siguientes acciones:
- Si la respuesta es
true, la función de replicador produce los registros en Kinesis Data Streams enus-east-2de manera secuencial.- Si hay una falla, se rastrea el número de secuencia del registro y se interrumpe la iteración. La función devuelve la lista de números de secuencia fallidos. Al devolver el número de secuencia fallido, la solución utiliza la característica de Punto de control lambda para poder reanudar el procesamiento de un lote de registros con fallas parciales. Esto es útil cuando se maneja cualquier deterioro del servicio, donde la función intenta replicar los datos entre regiones para garantizar la paridad de flujo y que no haya pérdida de datos.
- Si no hay fallas, se devuelve una lista vacía, lo que indica que el lote fue exitoso.
- Si la respuesta es
false, la función de replicador regresa sin realizar ninguna replicación. Para reducir el costo de las invocaciones de Lambda, puede configurar la simultaneidad reservada de la función en la región DR (us-east-2) a cero. Esto evitará que se invoque la función. Cuando realiza la conmutación por error, puede actualizar este valor a un número apropiado según el rendimiento de CDC y establecer la simultaneidad reservada de la función enus-east-1a cero para evitar que se ejecute innecesariamente.
- Si la respuesta es
- Después de que todos los registros se hayan producido en Kinesis Data Streams en
us-east-2, la función del replicador hace puntos de control en elkdsReplicationCheckpointTabla global de DynamoDB (enus-east-1) con los siguientes datos:{ "streamName": "example-stream-1", "lastReplicatedTimestamp": "2022-07-18T20:00:00" } - La función regresa después de procesar con éxito el lote de registros.
Consideraciones de rendimiento
Las expectativas de rendimiento de la solución deben entenderse con respecto a los siguientes factores:
- Selección de región – La latencia de replicación es directamente proporcional a la distancia recorrida por los datos, así que comprenda su selección de Región
- Velocidad – La velocidad de entrada de los datos o el volumen de datos que se replican
- Tamaño de carga útil – El tamaño de la carga útil que se replica
Supervisar la replicación entre regiones
Se recomienda rastrear y observar la replicación a medida que ocurre. Puede adaptar la función de Lambda para publicar métricas personalizadas en CloudWatch con las siguientes métricas al final de cada invocación. La publicación de estas métricas en las regiones primaria y secundaria ayuda a protegerse de las deficiencias que afectan la observabilidad en la región primaria.
- rendimiento – El tamaño actual del lote de invocación de Lambda
- ReplicationLagSecondsReplicationLagSeconds – La diferencia entre la marca de tiempo actual (después de procesar todos los registros) y la
ApproximateArrivalTimestampdel último registro que se replicó
El siguiente gráfico de métricas de ejemplo de CloudWatch muestra que el retraso de replicación promedio fue de 2 segundos con un rendimiento de 100 registros replicados desde us-east-1 a us-east-2.

Estrategia común de conmutación por error
Durante cualquier deterioro que afecte la canalización de CDC en la región principal, la continuidad del negocio o las necesidades de recuperación ante desastres pueden dictar una conmutación por error de la canalización a la región secundaria (en espera). Esto significa que se deben hacer un par de cosas como parte de este proceso de conmutación por error:
- Si es posible, detenga todas las tareas de CDC en la herramienta de procesador de CDC en
us-east-1. - El procesador CDC debe conmutarse por error a la región secundaria, de modo que pueda leer los datos CDC de la fuente de datos remota mientras opera fuera de la región en espera.
- El
kdsActiveRegionConfigLa tabla global de DynamoDB debe actualizarse. Por ejemplo, para la corrienteexample-stream-1utilizado en nuestro ejemplo, la región activa se cambia aus-east-2:
{ "stream-name": "example-stream-1", "active-Region" : "us-east-2"
}- Todos los puntos de control de flujo deben leerse desde el
kdsReplicationCheckpointTabla global de DynamoDB (enus-east-2), y las marcas de tiempo de cada uno de los puntos de control se utilizan para iniciar las tareas de CDC en la herramienta de producción enus-east-2Región. Esto minimiza las posibilidades de pérdida de datos y reanuda con precisión la transmisión de datos de CDC desde la fuente de datos remota desde la marca de tiempo del punto de control en adelante. - Si utiliza simultaneidad reservada para controlar las invocaciones de Lambda, establezca el valor en cero en la región principal (
us-east-1) y a un valor adecuado distinto de cero en la región secundaria (us-east-2).
Estrategia de conmutación por error de varios pasos de Vanguard
Algunas de las herramientas de terceros que utiliza Vanguard tienen un proceso CDC de dos pasos para transmitir datos desde una fuente de datos remota a un destino. La herramienta elegida por Vanguard para su procesador CDC sigue este enfoque de dos pasos:
- El primer paso consiste en configurar una tarea de flujo de registros que lea los datos de la fuente de datos remota y persista en una ubicación provisional.
- El segundo paso consiste en configurar tareas de consumidores individuales que lean datos de la ubicación de preparación, que podría estar en Sistema de archivos elástico de Amazon (Amazon EFS) o Amazonas FSx, por ejemplo, y transmitirlo al destino. La flexibilidad aquí es que cada una de estas tareas del consumidor se puede activar para transmitir desde diferentes marcas de tiempo de confirmación. La tarea de flujo de registro generalmente comienza a leer datos desde el mínimo de todas las marcas de tiempo de confirmación utilizadas por las tareas del consumidor.
Veamos un ejemplo para explicar el escenario:
- La tarea A del consumidor está transmitiendo datos desde una marca de tiempo de confirmación 2022-07-19T20:00:00 en adelante para
example-stream-1. - La tarea B del consumidor está transmitiendo datos desde una marca de tiempo de confirmación 2022-07-19T21:00:00 en adelante para
example-stream-2. - En esta situación, el flujo de registro debe leer datos del origen de datos remoto desde el mínimo de las marcas de tiempo utilizadas por las tareas del consumidor, que es 2022-07-19T20:00:00.
El siguiente diagrama de secuencia muestra los pasos exactos que se deben ejecutar durante una conmutación por error para us-east-2 (la región en espera).

Los pasos son los siguientes:
- El proceso de conmutación por error se activa en la región en espera (
us-east-2en este ejemplo) cuando sea necesario. Tenga en cuenta que el activador se puede automatizar mediante comprobaciones de estado integrales de la canalización en la región principal. - El proceso de conmutación por error actualiza la tabla global kdsActiveRegionConfig DynamoDB con el nuevo valor para la región como
us-east-2para todos los nombres de flujo. - El siguiente paso es obtener todos los puntos de control de flujo del
kdsReplicationCheckpointTabla global de DynamoDB (enus-east-2). - Después de leer la información del punto de control, el proceso de conmutación por error encuentra el mínimo de todos los
lastReplicatedTimestamp. - La tarea de flujo de registro en la herramienta del procesador CDC se inicia en
us-east-2con la marca de tiempo que se encuentra en el paso 4. Comienza a leer los datos de CDC de la fuente de datos remota a partir de esta marca de tiempo y los conserva en la ubicación de ensayo en AWS. - El siguiente paso es iniciar todas las tareas del consumidor para leer datos desde la ubicación de preparación y transmitirlos al flujo de datos de destino. Aquí es donde cada tarea del consumidor recibe la marca de tiempo apropiada del
kdsReplicationCheckpointtabla de acuerdo a lastreamNameal que la tarea transmite los datos.
Una vez que se inician todas las tareas del consumidor, los datos se generan en los flujos de datos de Kinesis en us-east-2. A partir de ahí, el proceso de replicación entre regiones es el mismo que se describió anteriormente: la función Lambda de replicación en us-east-2 comienza a replicar datos en el flujo de datos en us-east-1.
Se espera que las aplicaciones de consumo que leen datos de los flujos sean idempotentes para poder manejar duplicados. Se pueden introducir duplicados en la secuencia debido a muchas razones, algunas de las cuales se mencionan a continuación.
- El productor o el procesador de CDC introduce duplicados en la secuencia mientras reproduce los datos de CDC durante una conmutación por error.
- La tabla global de DynamoDB utiliza la replicación asíncrona de datos entre regiones y si el
kdsReplicationCheckpointlos datos de la tabla tienen un retraso de replicación, el proceso de conmutación por error puede potencialmente usar una marca de tiempo de punto de control más antigua para reproducir los datos de CDC.
Además, las aplicaciones del consumidor deben verificar el CommitTimestamp del último registro que se consumió. Esto es para facilitar un mejor seguimiento y recuperación.
Camino a la madurez: Recuperación automatizada
El estado ideal es automatizar por completo el proceso de conmutación por error, reduciendo el tiempo de recuperación y cumpliendo el objetivo de nivel de servicio (SLO) de resiliencia. Sin embargo, en la mayoría de las organizaciones, la decisión de conmutación por error, conmutación por recuperación y activación de la conmutación por error requiere una intervención manual para evaluar la situación y decidir el resultado. La creación de automatización con secuencias de comandos para realizar la conmutación por error que puede ejecutar un ser humano es un buen lugar para comenzar.
Vanguard ha automatizado todos los pasos de la conmutación por error, pero aun así los humanos toman la decisión sobre cuándo invocarla. Puede personalizar la solución para satisfacer sus necesidades y según la herramienta de procesador CDC que utilice en su entorno.
Conclusión
En esta publicación, describimos cómo Vanguard innovó y creó una solución para replicar datos entre regiones en Kinesis Data Streams para que los datos estén altamente disponibles. También demostramos una sólida estrategia de punto de control para facilitar una conmutación por error regional del proceso de replicación cuando sea necesario. La solución también ilustró cómo usar las tablas globales de DynamoDB para realizar un seguimiento de los puntos de control y la configuración de la replicación. Con esta arquitectura, Vanguard pudo implementar cargas de trabajo en función de los datos de CDC en varias regiones para satisfacer las necesidades comerciales de alta disponibilidad frente a las deficiencias del servicio que afectan las canalizaciones de CDC en la región principal.
Si tiene algún comentario, deje un comentario en la sección Comentarios a continuación.
Sobre los autores
 Raghu Boppanna trabaja como Arquitecto Empresarial en la Oficina Principal de Tecnología de Vanguard. Raghu se especializa en análisis de datos, migración/replicación de datos, incluidas canalizaciones de CDC, recuperación ante desastres y bases de datos. Ha obtenido varias certificaciones de AWS, incluida la seguridad certificada por AWS: especialidad y el análisis de datos certificado por AWS: especialidad.
Raghu Boppanna trabaja como Arquitecto Empresarial en la Oficina Principal de Tecnología de Vanguard. Raghu se especializa en análisis de datos, migración/replicación de datos, incluidas canalizaciones de CDC, recuperación ante desastres y bases de datos. Ha obtenido varias certificaciones de AWS, incluida la seguridad certificada por AWS: especialidad y el análisis de datos certificado por AWS: especialidad.
 Parameswaran V Vaidyanathan es un arquitecto sénior de resiliencia en la nube con Amazon Web Services. Ayuda a las grandes empresas a alcanzar los objetivos comerciales mediante la arquitectura y la creación de soluciones escalables y resistentes en la nube de AWS.
Parameswaran V Vaidyanathan es un arquitecto sénior de resiliencia en la nube con Amazon Web Services. Ayuda a las grandes empresas a alcanzar los objetivos comerciales mediante la arquitectura y la creación de soluciones escalables y resistentes en la nube de AWS.
 Richa Kaul es un líder sénior en soluciones para clientes que atiende a clientes de servicios financieros. Tiene su sede en Nueva York. Tiene una amplia experiencia en la transformación de la nube a gran escala, la excelencia de los empleados y las soluciones digitales de próxima generación. Ella y su equipo se centran en optimizar el valor de la nube mediante la creación de soluciones eficaces, resistentes y ágiles. Richa disfruta de múltiples deportes como triatlones, música y aprender sobre nuevas tecnologías.
Richa Kaul es un líder sénior en soluciones para clientes que atiende a clientes de servicios financieros. Tiene su sede en Nueva York. Tiene una amplia experiencia en la transformación de la nube a gran escala, la excelencia de los empleados y las soluciones digitales de próxima generación. Ella y su equipo se centran en optimizar el valor de la nube mediante la creación de soluciones eficaces, resistentes y ágiles. Richa disfruta de múltiples deportes como triatlones, música y aprender sobre nuevas tecnologías.
 Mithil Prasad es Gerente Principal de Soluciones para Clientes en Amazon Web Services. En su función, Mithil trabaja con los Clientes para impulsar la realización del valor de la nube y brindar liderazgo intelectual para ayudar a las empresas a lograr velocidad, agilidad e innovación.
Mithil Prasad es Gerente Principal de Soluciones para Clientes en Amazon Web Services. En su función, Mithil trabaja con los Clientes para impulsar la realización del valor de la nube y brindar liderazgo intelectual para ayudar a las empresas a lograr velocidad, agilidad e innovación.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/how-vanguard-made-their-technology-platform-resilient-and-efficient-by-building-cross-region-replication-for-amazon-kinesis-data-streams/

