
Imagen del autor
Supervisado es una subcategoría de aprendizaje automático en la que la computadora aprende del conjunto de datos etiquetados que contiene tanto la entrada como la salida correcta. Intenta encontrar la función de mapeo que relaciona la entrada (x) con la salida (y). Puedes considerarlo como enseñarle a tu hermano o hermana menor cómo reconocer diferentes animales. Les mostrarás algunas imágenes (x) y les dirás cómo se llama cada animal (y). Después de un tiempo, aprenderán las diferencias y podrán reconocer correctamente la nueva imagen. Ésta es la intuición básica detrás del aprendizaje supervisado. Antes de seguir adelante, echemos un vistazo más profundo a su funcionamiento.
¿Cómo funciona el aprendizaje supervisado?
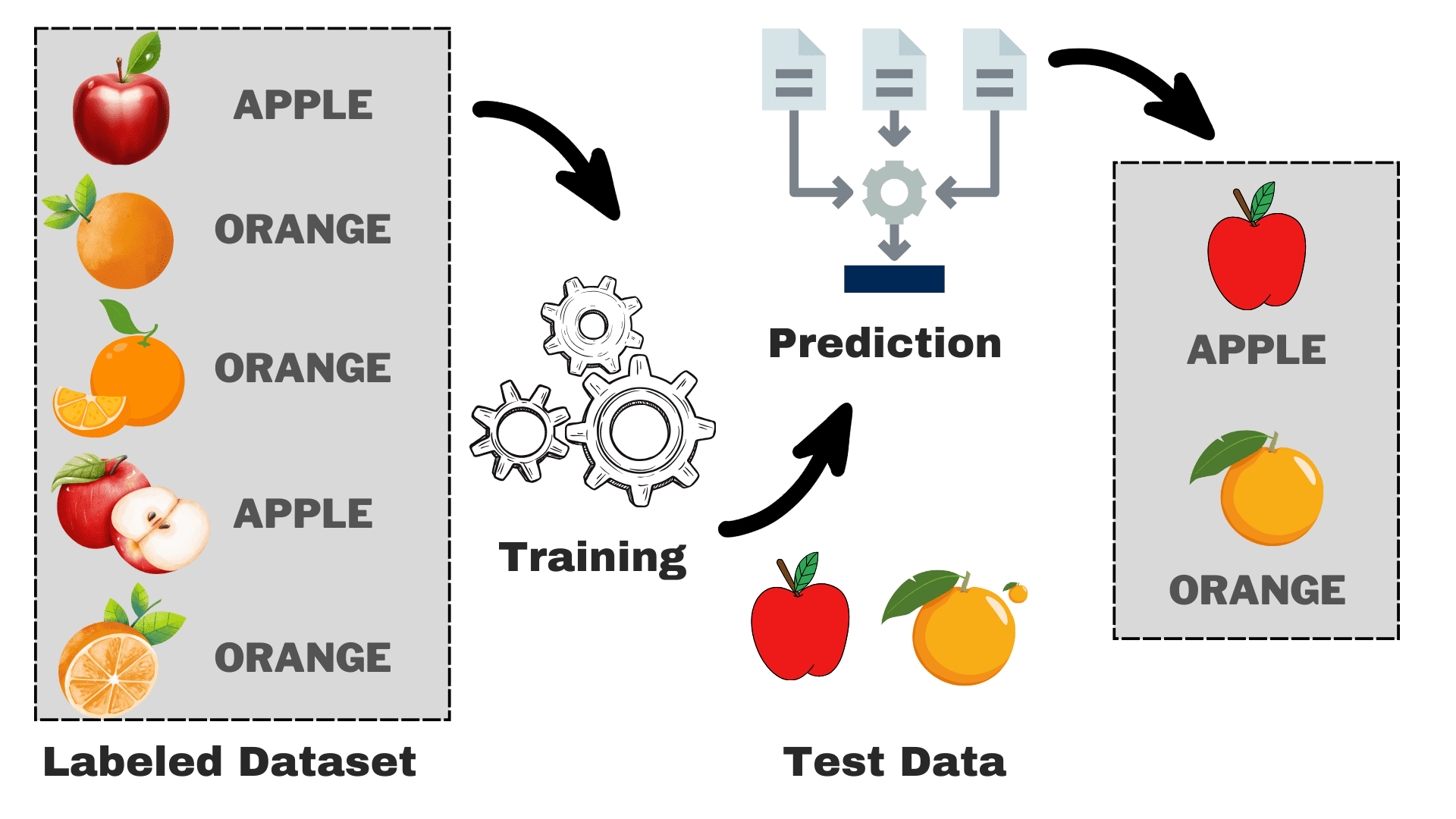
Imagen del autor
Suponga que desea construir un modelo que pueda diferenciar entre manzanas y naranjas según algunas características. Podemos dividir el proceso en las siguientes tareas:
- Recopilación de datos: Reúna un conjunto de datos con imágenes de manzanas y naranjas, y cada imagen esté etiquetada como "manzana" o "naranja".
- Selección de modelo: Tenemos que elegir el clasificador correcto aquí, a menudo conocido como el algoritmo de aprendizaje automático supervisado adecuado para su tarea. Es como elegir las gafas adecuadas que te ayudarán a ver mejor.
- Entrenamiento del modelo: Ahora, alimenta el algoritmo con imágenes etiquetadas de manzanas y naranjas. El algoritmo observa estas imágenes y aprende a reconocer las diferencias, como el color, la forma y el tamaño de manzanas y naranjas.
- Evaluación y prueba: Para comprobar si su modelo funciona correctamente, le enviaremos algunas imágenes no vistas y compararemos las predicciones con la real.
El aprendizaje supervisado se puede dividir en dos tipos principales:
Clasificación
En las tareas de clasificación, el objetivo principal es asignar puntos de datos a categorías específicas de un conjunto de clases discretas. Cuando sólo hay dos resultados posibles, como “sí” o “no”, “spam” o “no spam”, “aceptado” o “rechazado”, se habla de clasificación binaria. Sin embargo, cuando hay más de dos categorías o clases involucradas, como calificar a los estudiantes según sus calificaciones (por ejemplo, A, B, C, D, F), se convierte en un ejemplo de un problema de clasificación múltiple.
Regresión
Para problemas de regresión, intenta predecir un valor numérico continuo. Por ejemplo, es posible que le interese predecir las puntuaciones de su examen final en función de su desempeño anterior en la clase. Las puntuaciones previstas pueden abarcar cualquier valor dentro de un rango específico, normalmente de 0 a 100 en nuestro caso.
Ahora tenemos una comprensión básica del proceso general. Exploraremos los populares algoritmos de aprendizaje automático supervisado, su uso y cómo funcionan:
1. Regresión lineal
Como sugiere el nombre, se utiliza para tareas de regresión como predecir precios de acciones, pronosticar la temperatura, estimar la probabilidad de progresión de una enfermedad, etc. Intentamos predecir el objetivo (variable dependiente) utilizando el conjunto de etiquetas (variables independientes). Se supone que tenemos una relación lineal entre nuestras características de entrada y la etiqueta. La idea central gira en torno a predecir la línea que mejor se ajusta a nuestros puntos de datos minimizando el error entre nuestros valores reales y predichos. Esta recta está representada por la ecuación:
Dónde,
- Y Salida prevista.
- X = Característica de entrada o matriz de características en regresión lineal múltiple
- b0 = Intersección (donde la línea cruza el eje Y).
- b1 = Pendiente o coeficiente que determina la pendiente de la línea.
Estima la pendiente de la línea (peso) y su intersección (sesgo). Esta línea se puede utilizar más para hacer predicciones. Aunque es el modelo más simple y útil para desarrollar las líneas de base, es muy sensible a los valores atípicos que pueden influir en la posición de la línea.
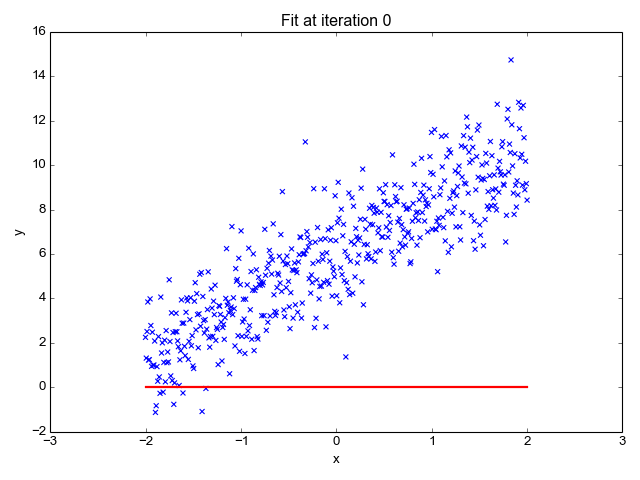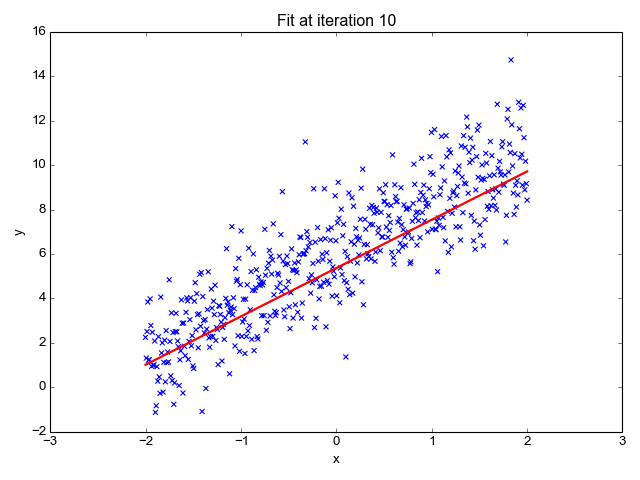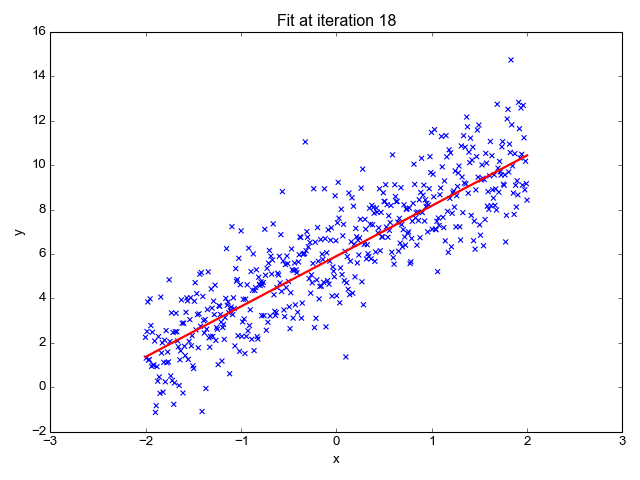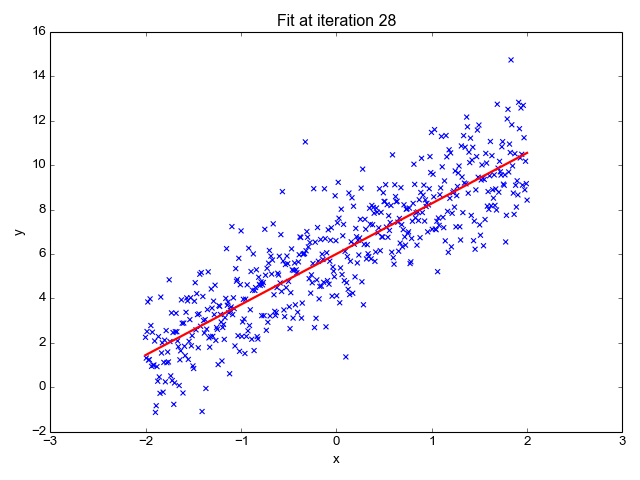
gif en Primo.ai
2. Regresión logística
Aunque tiene regresión en su nombre, se utiliza fundamentalmente para problemas de clasificación binaria. Predice la probabilidad de un resultado positivo (variable dependiente) que se encuentra en el rango de 0 a 1. Al establecer un umbral (normalmente 0.5), clasificamos los puntos de datos: aquellos con una probabilidad mayor que el umbral pertenecen a la clase positiva, y viceversa. La regresión logística calcula esta probabilidad utilizando la función sigmoidea aplicada a la combinación lineal de las características de entrada que se especifica como:
Dónde,
- P(Y=1) = Probabilidad de que el punto de datos pertenezca a la clase positiva
- X1 ,… ,Xn = Características de entrada
- b0,….,bn = Pesos de entrada que el algoritmo aprende durante el entrenamiento
Esta función sigmoidea tiene la forma de una curva tipo S que transforma cualquier punto de datos en una puntuación de probabilidad dentro del rango de 0-1. Puede ver el siguiente gráfico para una mejor comprensión.
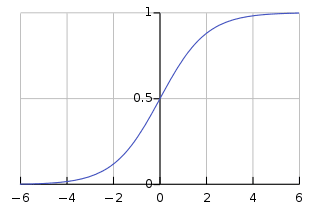
Imagen en Wikipedia
Un valor más cercano a 1 indica una mayor confianza en el modelo en su predicción. Al igual que la regresión lineal, es conocida por su simplicidad, pero no podemos realizar la clasificación de clases múltiples sin modificar el algoritmo original.
3. Árboles de decisión
A diferencia de los dos algoritmos anteriores, los árboles de decisión se pueden utilizar tanto para tareas de clasificación como de regresión. Tiene una estructura jerárquica al igual que los diagramas de flujo. En cada nodo, se toma una decisión sobre la ruta en función de algunos valores de características. El proceso continúa hasta que lleguemos al último nodo que representa la decisión final. A continuación se incluye alguna terminología básica que debe tener en cuenta:
- Nodo raíz: El nodo superior que contiene todo el conjunto de datos se denomina nodo raíz. Luego seleccionamos la mejor característica usando algún algoritmo para dividir el conjunto de datos en 2 o más subárboles.
- Nodos internos: Cada nodo interno representa una característica específica y una regla de decisión para decidir la siguiente dirección posible para un punto de datos.
- Nodos de hoja: Los nodos finales que representan una etiqueta de clase se denominan nodos hoja.
Predice los valores numéricos continuos para las tareas de regresión. A medida que crece el tamaño del conjunto de datos, captura el ruido que conduce al sobreajuste. Esto se puede solucionar podando el árbol de decisión. Eliminamos ramas que no mejoran significativamente la precisión de nuestras decisiones. Esto ayuda a mantener nuestro árbol enfocado en los factores más importantes y evita que se pierda en los detalles.
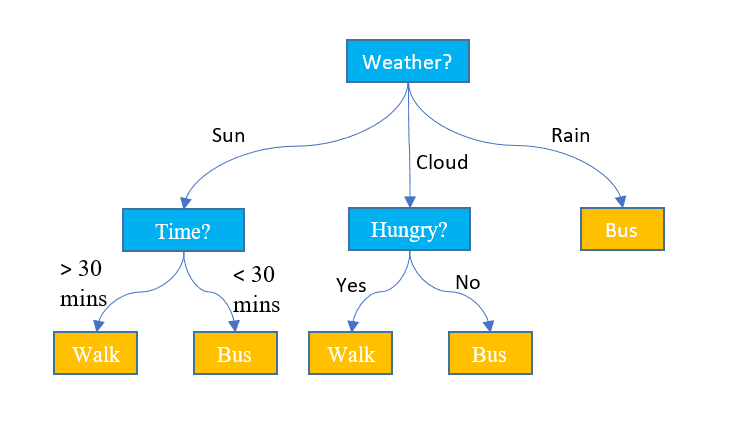
Imagen de Jake Hoare en Displayr
4. Bosque aleatorio
El bosque aleatorio también se puede utilizar para tareas de clasificación y regresión. Es un grupo de árboles de decisión que trabajan juntos para hacer la predicción final. Puedes pensar en ello como un comité de expertos que toma una decisión colectiva. Así es como funciona:
- Muestreo de datos: En lugar de tomar todo el conjunto de datos a la vez, toma muestras aleatorias mediante un proceso llamado bootstrapping o embolsado.
- Selección de características: Para cada árbol de decisión en un bosque aleatorio, solo se considera el subconjunto aleatorio de características para la toma de decisiones en lugar del conjunto completo de características.
- Votación: Para la clasificación, cada árbol de decisión en el bosque aleatorio emite su voto y se selecciona la clase con los votos más altos. Para la regresión, promediamos los valores obtenidos de todos los árboles.
Aunque reduce el efecto del sobreajuste causado por árboles de decisión individuales, es computacionalmente costoso. Una palabra que leerá con frecuencia en la literatura es que el bosque aleatorio es un método de aprendizaje conjunto, lo que significa que combina múltiples modelos para mejorar el rendimiento general.
5. Máquinas de vectores de soporte (SVM)
Se utiliza principalmente para problemas de clasificación, pero también puede manejar tareas de regresión. Intenta encontrar el mejor hiperplano que separe las distintas clases utilizando el enfoque estadístico, a diferencia del enfoque probabilístico de la regresión logística. Podemos utilizar el SVM lineal para los datos linealmente separables. Sin embargo, la mayoría de los datos del mundo real no son lineales y utilizamos los trucos del kernel para separar las clases. Profundicemos en cómo funciona:
- Selección de hiperplano: En la clasificación binaria, SVM encuentra el mejor hiperplano (línea 2-D) para separar las clases mientras maximiza el margen. El margen es la distancia entre el hiperplano y los puntos de datos más cercanos al hiperplano.
- Truco del núcleo: Para datos linealmente inseparables, empleamos un truco del núcleo que asigna el espacio de datos original a un espacio de alta dimensión donde se pueden separar linealmente. Los núcleos comunes incluyen núcleos lineales, polinomiales, de función de base radial (RBF) y sigmoideos.
- Maximización de márgenes: SVM también intenta mejorar la generalización del modelo aumentando el margen de maximización.
- Clasificación: Una vez entrenado el modelo, las predicciones se pueden hacer en función de su posición relativa al hiperplano.
SVM también tiene un parámetro llamado C que controla el equilibrio entre maximizar el margen y mantener el error de clasificación al mínimo. Aunque pueden manejar bien datos no lineales y de alta dimensión, elegir el kernel y el hiperparámetro correctos no es tan fácil como parece.
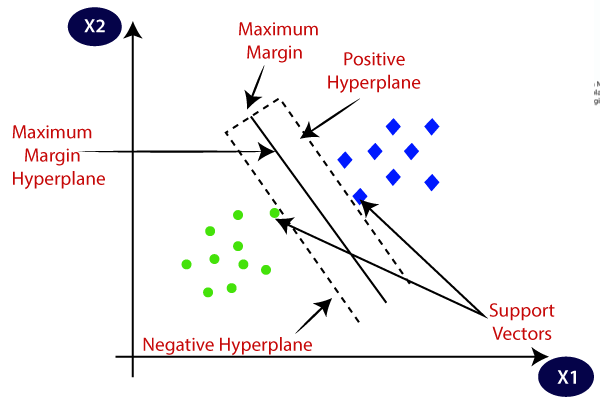
Imagen en Punto Java
6. k-vecinos más cercanos (k-NN)
K-NN es el algoritmo de aprendizaje supervisado más simple que se utiliza principalmente para tareas de clasificación. No hace ninguna suposición sobre los datos y asigna al nuevo punto de datos una categoría en función de su similitud con los existentes. Durante la fase de entrenamiento, mantiene todo el conjunto de datos como punto de referencia. Luego calcula la distancia entre el nuevo punto de datos y todos los puntos existentes utilizando una métrica de distancia (por ejemplo, distancia de Eucilinedain). En función de estas distancias, identifica los K vecinos más cercanos a estos puntos de datos. Luego contamos la aparición de cada clase en los K vecinos más cercanos y asignamos la clase que aparece con más frecuencia como predicción final.
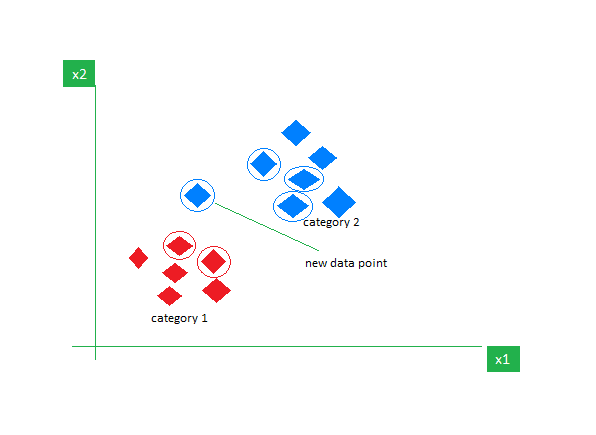
Imagen en Geeksparageeks
Elegir el valor correcto de K requiere experimentación. Aunque es robusto a datos ruidosos, no es adecuado para conjuntos de datos de grandes dimensiones y tiene un alto costo asociado debido al cálculo de la distancia desde todos los puntos de datos.
Al concluir este artículo, animaría a los lectores a explorar más algoritmos e intentar implementarlos desde cero. Esto fortalecerá su comprensión de cómo funcionan las cosas bajo el capó. Aquí hay algunos recursos adicionales para ayudarlo a comenzar:
Kanwal Mehreen es un aspirante a desarrollador de software con un gran interés en la ciencia de datos y las aplicaciones de IA en medicina. Kanwal fue seleccionado como Google Generation Scholar 2022 para la región APAC. A Kanwal le encanta compartir conocimientos técnicos escribiendo artículos sobre temas de actualidad y le apasiona mejorar la representación de las mujeres en la industria tecnológica.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.kdnuggets.com/understanding-supervised-learning-theory-and-overview?utm_source=rss&utm_medium=rss&utm_campaign=understanding-supervised-learning-theory-and-overview

