Esta publicación de blog está coescrita con Caroline Chung de Veoneer.
Veoneer es una empresa global de electrónica automotriz y líder mundial en sistemas electrónicos de seguridad para automóviles. Ofrecen los mejores sistemas de control de retención de su clase y han entregado más de mil millones de unidades de control electrónico y sensores de choque a fabricantes de automóviles en todo el mundo. La empresa continúa basándose en una historia de 1 años de desarrollo de la seguridad automotriz, especializándose en hardware y sistemas de vanguardia que previenen incidentes de tráfico y mitigan accidentes.
La detección en cabina (ICS) automotriz es un espacio emergente que utiliza una combinación de varios tipos de sensores, como cámaras y radares, y algoritmos basados en inteligencia artificial (IA) y aprendizaje automático (ML) para mejorar la seguridad y la experiencia de conducción. Construir un sistema de este tipo puede ser una tarea compleja. Los desarrolladores tienen que anotar manualmente grandes volúmenes de imágenes con fines de capacitación y prueba. Esto requiere mucho tiempo y recursos. El plazo para realizar una tarea de este tipo es de varias semanas. Además, las empresas tienen que lidiar con problemas como etiquetas inconsistentes debido a errores humanos.
AWS se centra en ayudarlo a aumentar su velocidad de desarrollo y reducir sus costos de creación de dichos sistemas a través de análisis avanzados como ML. Nuestra visión es utilizar ML para la anotación automatizada, permitiendo el reentrenamiento de modelos de seguridad y garantizando métricas de rendimiento consistentes y confiables. En esta publicación, compartimos cómo, al colaborar con la Organización Mundial de Especialistas de Amazon y la Centro de innovación de IA generativa, desarrollamos un canal de aprendizaje activo para cuadros delimitadores de cabecera de imágenes en cabina y anotaciones de puntos clave. La solución reduce el costo en más del 90 %, acelera el proceso de anotación de semanas a horas en términos de tiempo de respuesta y permite la reutilización para tareas similares de etiquetado de datos de ML.
Resumen de la solución
El aprendizaje activo es un enfoque de ML que implica un proceso iterativo de selección y anotación de los datos más informativos para entrenar un modelo. Dado un pequeño conjunto de datos etiquetados y un gran conjunto de datos sin etiquetar, el aprendizaje activo mejora el rendimiento del modelo, reduce el esfuerzo de etiquetado e integra la experiencia humana para obtener resultados sólidos. En esta publicación, creamos un canal de aprendizaje activo para anotaciones de imágenes con servicios de AWS.
El siguiente diagrama demuestra el marco general de nuestro proceso de aprendizaje activo. El proceso de etiquetado toma imágenes de un Servicio de almacenamiento simple de Amazon (Amazon S3) y genera imágenes anotadas con la cooperación de modelos de aprendizaje automático y experiencia humana. El proceso de capacitación preprocesa los datos y los utiliza para entrenar modelos de ML. El modelo inicial se configura y se entrena con un pequeño conjunto de datos etiquetados manualmente y se utilizará en el proceso de etiquetado. El proceso de etiquetado y el proceso de capacitación se pueden iterar gradualmente con más datos etiquetados para mejorar el rendimiento del modelo.
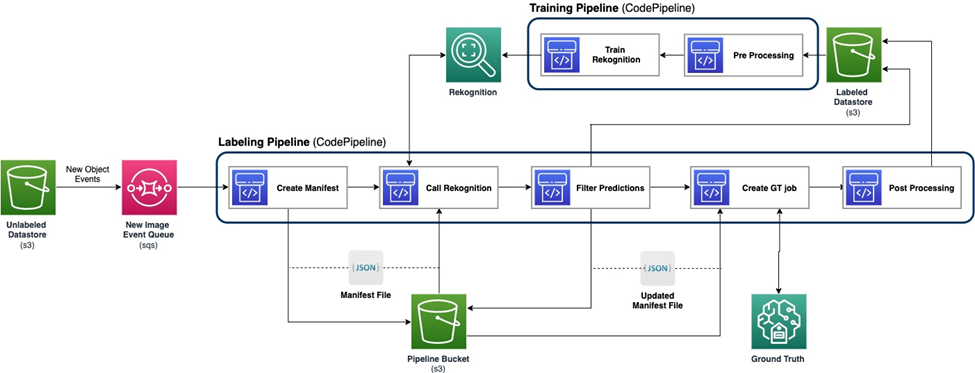
En el proceso de etiquetado, un Notificación de eventos de Amazon S3 se invoca cuando un nuevo lote de imágenes ingresa al depósito Unlabeled Datastore S3, activando la canalización de etiquetado. El modelo produce los resultados de la inferencia sobre las nuevas imágenes. Una función de juicio personalizada selecciona partes de los datos en función de la puntuación de confianza de la inferencia u otras funciones definidas por el usuario. Estos datos, con sus resultados de inferencia, se envían para un trabajo de etiquetado humano en Verdad fundamental de Amazon SageMaker creado por la tubería. El proceso de etiquetado humano ayuda a anotar los datos, y los resultados modificados se combinan con los datos restantes anotados automáticamente, que el proceso de capacitación puede utilizar más adelante.
El reentrenamiento del modelo ocurre en el proceso de entrenamiento, donde utilizamos el conjunto de datos que contiene los datos etiquetados por humanos para reentrenar el modelo. Se genera un archivo de manifiesto para describir dónde se almacenan los archivos y se vuelve a entrenar el mismo modelo inicial con los nuevos datos. Después del reentrenamiento, el nuevo modelo reemplaza al modelo inicial y comienza la siguiente iteración del proceso de aprendizaje activo.
Despliegue del modelo
Tanto el proceso de etiquetado como el proceso de capacitación se implementan en AWS CodePipeline. Construcción de código AWS Se utilizan instancias para la implementación, que es flexible y rápida para una pequeña cantidad de datos. Cuando se necesita velocidad, utilizamos Amazon SageMaker puntos finales basados en la instancia de GPU para asignar más recursos para respaldar y acelerar el proceso.
La canalización de reentrenamiento del modelo se puede invocar cuando hay un nuevo conjunto de datos o cuando es necesario mejorar el rendimiento del modelo. Una tarea crítica en el proceso de reentrenamiento es tener el sistema de control de versiones tanto para los datos de entrenamiento como para el modelo. Aunque los servicios de AWS como Reconocimiento de amazonas tienen la función de control de versiones integrada, lo que hace que la canalización sea sencilla de implementar; los modelos personalizados requieren registro de metadatos o herramientas de control de versiones adicionales.
Todo el flujo de trabajo se implementa utilizando el Kit de desarrollo en la nube de AWS (AWS CDK) para crear los componentes de AWS necesarios, incluidos los siguientes:
- Dos roles para trabajos de CodePipeline y SageMaker
- Dos trabajos de CodePipeline, que organizan el flujo de trabajo
- Dos depósitos de S3 para los artefactos de código de las canalizaciones
- Un depósito de S3 para etiquetar el manifiesto del trabajo, los conjuntos de datos y los modelos
- Preprocesamiento y posprocesamiento AWS Lambda funciones para los trabajos de etiquetado de SageMaker Ground Truth
Las pilas de AWS CDK están altamente modularizadas y son reutilizables en diferentes tareas. La capacitación, el código de inferencia y la plantilla de SageMaker Ground Truth se pueden reemplazar para cualquier escenario de aprendizaje activo similar.
Entrenamiento modelo
La capacitación del modelo incluye dos tareas: anotación del cuadro delimitador principal y anotación de puntos clave humanos. Los presentamos a ambos en esta sección.
Anotación del cuadro delimitador principal
La anotación del cuadro delimitador de la cabeza es una tarea para predecir la ubicación de un cuadro delimitador de la cabeza humana en una imagen. Usamos un Etiquetas personalizadas de Amazon Rekognition modelo para anotaciones del cuadro delimitador principal. La siguiente cuaderno de muestra proporciona un tutorial paso a paso sobre cómo entrenar un modelo de etiquetas personalizadas de Rekognition a través de SageMaker.
Primero necesitamos preparar los datos para comenzar el entrenamiento. Generamos un archivo de manifiesto para el entrenamiento y un archivo de manifiesto para el conjunto de datos de prueba. Un archivo de manifiesto contiene varios elementos, cada uno de los cuales es para una imagen. El siguiente es un ejemplo del archivo de manifiesto, que incluye la ruta de la imagen, el tamaño y la información de anotación:
Usando los archivos de manifiesto, podemos cargar conjuntos de datos en un modelo de etiquetas personalizadas de Rekognition para entrenamiento y prueba. Repetimos el modelo con diferentes cantidades de datos de entrenamiento y lo probamos en las mismas 239 imágenes no vistas. En esta prueba, el mAP_50 La puntuación aumentó de 0.33 con 114 imágenes de entrenamiento a 0.95 con 957 imágenes de entrenamiento. La siguiente captura de pantalla muestra las métricas de rendimiento del modelo final de etiquetas personalizadas de Rekognition, que produce un gran rendimiento en términos de puntuación F1, precisión y recuperación.

Además, probamos el modelo en un conjunto de datos retenido que tiene 1,128 imágenes. El modelo predice consistentemente predicciones precisas del cuadro delimitador en los datos invisibles, lo que produce un alto mAP_50 del 94.9%. El siguiente ejemplo muestra una imagen con anotaciones automáticas con un cuadro delimitador de encabezado.

Anotación de puntos clave
La anotación de puntos clave produce ubicaciones de puntos clave, incluidos ojos, oídos, nariz, boca, cuello, hombros, codos, muñecas, caderas y tobillos. Además de la predicción de la ubicación, se necesita visibilidad de cada punto para predecir en esta tarea específica, para lo cual diseñamos un método novedoso.
Para la anotación de puntos clave, utilizamos un Modelo Yolo 8 Pose en SageMaker como modelo inicial. Primero preparamos los datos para el entrenamiento, incluida la generación de archivos de etiquetas y un archivo de configuración .yaml siguiendo los requisitos de Yolo. Después de preparar los datos, entrenamos el modelo y guardamos los artefactos, incluido el archivo de pesos del modelo. Con el archivo de pesos del modelo entrenado, podemos anotar las nuevas imágenes.
En la etapa de entrenamiento, todos los puntos etiquetados con ubicaciones, incluidos los puntos visibles y los puntos ocluidos, se utilizan para el entrenamiento. Por lo tanto, este modelo proporciona por defecto la ubicación y la confianza de la predicción. En la siguiente figura, un umbral de confianza grande (umbral principal) cercano a 0.6 es capaz de dividir los puntos que son visibles u ocluidos frente a los puntos que están fuera de los puntos de vista de la cámara. Sin embargo, los puntos ocluidos y los puntos visibles no están separados por la confianza, lo que significa que la confianza prevista no es útil para predecir la visibilidad.

Para obtener la predicción de la visibilidad, introducimos un modelo adicional entrenado en el conjunto de datos que contiene solo puntos visibles, excluyendo tanto los puntos ocluidos como los puntos fuera de los puntos de vista de la cámara. La siguiente figura muestra la distribución de puntos con diferente visibilidad. Los puntos visibles y otros puntos se pueden separar en el modelo adicional. Podemos usar un umbral (umbral adicional) cercano a 0.6 para obtener los puntos visibles. Combinando estos dos modelos, diseñamos un método para predecir la ubicación y la visibilidad.

Primero, el modelo principal predice un punto clave con ubicación y confianza principal, luego obtenemos la predicción de confianza adicional del modelo adicional. Su visibilidad se clasifica entonces de la siguiente manera:
- Visible, si su confianza principal es mayor que su umbral principal y su confianza adicional es mayor que el umbral adicional.
- Ocluido, si su confianza principal es mayor que su umbral principal y su confianza adicional es menor o igual que el umbral adicional.
- Fuera de la revisión de la cámara, de lo contrario
En la siguiente imagen se muestra un ejemplo de anotación de puntos clave, donde las marcas sólidas son puntos visibles y las marcas huecas son puntos ocluidos. Fuera de los puntos de revisión de la cámara no se muestran.

Basado en el estándar OKS definición en el conjunto de datos MS-COCO, nuestro método puede lograr mAP_50 del 98.4% en el conjunto de datos de prueba invisible. En términos de visibilidad, el método arroja una precisión de clasificación del 79.2% en el mismo conjunto de datos.
Etiquetado humano y reentrenamiento
Aunque los modelos logran un gran rendimiento con datos de prueba, todavía existen posibilidades de cometer errores con nuevos datos del mundo real. El etiquetado humano es el proceso para corregir estos errores para mejorar el rendimiento del modelo mediante el reentrenamiento. Diseñamos una función de juicio que combinaba el valor de confianza generado por los modelos ML para la salida de todos los cuadros delimitadores principales o puntos clave. Usamos la puntuación final para identificar estos errores y las imágenes mal etiquetadas resultantes, que deben enviarse al proceso de etiquetado humano.
Además de las imágenes mal etiquetadas, una pequeña parte de las imágenes se eligen al azar para el etiquetado humano. Estas imágenes etiquetadas por humanos se agregan a la versión actual del conjunto de entrenamiento para volver a entrenarlo, mejorar el rendimiento del modelo y la precisión general de las anotaciones.
En la implementación, utilizamos SageMaker Ground Truth para la etiquetado humano proceso. SageMaker Ground Truth proporciona una interfaz de usuario intuitiva y fácil de usar para el etiquetado de datos. La siguiente captura de pantalla muestra un trabajo de etiquetado de SageMaker Ground Truth para la anotación del cuadro delimitador principal.

La siguiente captura de pantalla muestra un trabajo de etiquetado de SageMaker Ground Truth para la anotación de puntos clave.

Costo, velocidad y reutilización
El costo y la velocidad son las ventajas clave de utilizar nuestra solución en comparación con el etiquetado humano, como se muestra en las siguientes tablas. Usamos estas tablas para representar los ahorros de costos y las aceleraciones de velocidad. Usando la instancia acelerada de GPU SageMaker ml.g4dn.xlarge, el costo de inferencia y entrenamiento de toda la vida en 100,000 imágenes es un 99% menor que el costo del etiquetado humano, mientras que la velocidad es de 10 a 10,000 veces más rápida que el etiquetado humano, dependiendo de tarea.
La primera tabla resume las métricas de desempeño de costos.
| Modelo | mAP_50 basado en 1,128 imágenes de prueba | Costo de capacitación basado en 100,000 imágenes. | Costo de inferencia basado en 100,000 imágenes. | Reducción de costos en comparación con la anotación humana | Tiempo de inferencia basado en 100,000 imágenes. | Aceleración del tiempo en comparación con la anotación humana |
| Cuadro delimitador del cabezal de reconocimiento | 0.949 | $4 | $22 | 99% menos | 5.5 h | Días |
| Puntos clave de Yolo | 0.984 | $27.20 | * $ 10 | 99.9% menos | minutos | Semanas |
La siguiente tabla resume las métricas de rendimiento.
| Tarea de anotación | mapa_50 (%) | Costo de capacitación ($) | Costo de inferencia ($) | Tiempo de inferencia |
| Caja delimitadora de cabeza | 94.9 | 4 | 22 | 5.5 horas |
| Lista de verificación | 98.4 | 27 | 10 | 5 minutos |
Además, nuestra solución proporciona reutilización para tareas similares. Los desarrollos de percepción de cámaras para otros sistemas, como el sistema avanzado de asistencia al conductor (ADAS) y los sistemas en cabina, también pueden adoptar nuestra solución.
Resumen
En esta publicación, mostramos cómo crear un canal de aprendizaje activo para la anotación automática de imágenes en la cabina utilizando los servicios de AWS. Demostramos el poder del ML, que le permite automatizar y acelerar el proceso de anotación, y la flexibilidad del marco que utiliza modelos compatibles con los servicios de AWS o personalizados en SageMaker. Con Amazon S3, SageMaker, Lambda y SageMaker Ground Truth, puede optimizar el almacenamiento, la anotación, la capacitación y la implementación de datos, y lograr la reutilización mientras reduce significativamente los costos. Al implementar esta solución, las empresas automotrices pueden volverse más ágiles y rentables mediante el uso de análisis avanzados basados en ML, como la anotación automatizada de imágenes.
Comience hoy y libere el poder de Servicios de AWS y aprendizaje automático para sus casos de uso de detección en cabina de automóviles.
Acerca de los autores
 Yanxiang Yu es científico aplicado en el Centro de Innovación de IA Generativa de Amazon. Con más de 9 años de experiencia en la creación de soluciones de inteligencia artificial y aprendizaje automático para aplicaciones industriales, se especializa en inteligencia artificial generativa, visión por computadora y modelado de series temporales.
Yanxiang Yu es científico aplicado en el Centro de Innovación de IA Generativa de Amazon. Con más de 9 años de experiencia en la creación de soluciones de inteligencia artificial y aprendizaje automático para aplicaciones industriales, se especializa en inteligencia artificial generativa, visión por computadora y modelado de series temporales.
 Tianyi Mao es un científico aplicado en AWS con sede en el área de Chicago. Tiene más de cinco años de experiencia en la creación de soluciones de aprendizaje automático y aprendizaje profundo y se centra en la visión por computadora y el aprendizaje por refuerzo con retroalimentación humana. Le gusta trabajar con los clientes para comprender sus desafíos y resolverlos mediante la creación de soluciones innovadoras utilizando los servicios de AWS.
Tianyi Mao es un científico aplicado en AWS con sede en el área de Chicago. Tiene más de cinco años de experiencia en la creación de soluciones de aprendizaje automático y aprendizaje profundo y se centra en la visión por computadora y el aprendizaje por refuerzo con retroalimentación humana. Le gusta trabajar con los clientes para comprender sus desafíos y resolverlos mediante la creación de soluciones innovadoras utilizando los servicios de AWS.
 Yanru Xiao es científico aplicado en el Centro de innovación de IA generativa de Amazon, donde crea soluciones de IA/ML para los problemas comerciales del mundo real de los clientes. Ha trabajado en varios campos, incluidos la manufactura, la energía y la agricultura. Yanru obtuvo su doctorado. en Ciencias de la Computación de la Universidad Old Dominion.
Yanru Xiao es científico aplicado en el Centro de innovación de IA generativa de Amazon, donde crea soluciones de IA/ML para los problemas comerciales del mundo real de los clientes. Ha trabajado en varios campos, incluidos la manufactura, la energía y la agricultura. Yanru obtuvo su doctorado. en Ciencias de la Computación de la Universidad Old Dominion.
 Paul George es un destacado líder de productos con más de 15 años de experiencia en tecnologías automotrices. Es experto en liderar equipos de gestión de productos, estrategia, comercialización e ingeniería de sistemas. Ha incubado y lanzado varios productos nuevos de detección y percepción a nivel mundial. En AWS, lidera la estrategia y la comercialización de cargas de trabajo de vehículos autónomos.
Paul George es un destacado líder de productos con más de 15 años de experiencia en tecnologías automotrices. Es experto en liderar equipos de gestión de productos, estrategia, comercialización e ingeniería de sistemas. Ha incubado y lanzado varios productos nuevos de detección y percepción a nivel mundial. En AWS, lidera la estrategia y la comercialización de cargas de trabajo de vehículos autónomos.
 Carolina Chung es gerente de ingeniería en Veoneer (adquirida por Magna International), tiene más de 14 años de experiencia desarrollando sistemas de detección y percepción. Actualmente dirige programas de predesarrollo de detección de interiores en Magna International y gestiona un equipo de ingenieros de visión computacional y científicos de datos.
Carolina Chung es gerente de ingeniería en Veoneer (adquirida por Magna International), tiene más de 14 años de experiencia desarrollando sistemas de detección y percepción. Actualmente dirige programas de predesarrollo de detección de interiores en Magna International y gestiona un equipo de ingenieros de visión computacional y científicos de datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

